
- 1123_hih123、pw
- 2Redis常用数据结构及应用场景_redis数据结构及应用场景
- 3UML中活动图、状态图、流程图的区别_uml状态图和流程图的区别
- 4iOS开发进阶(二十):Xcode 断点调试详解
- 5ZeroTier创建虚拟网络连通共享公网内网计算机_zeroriter做公网
- 6python方法定义的第一个参数是this_Python函数中如何定义参数
- 7Docker consul 容器服务更新与发现_consul 来记录docker 的容器状态
- 8GitHub从注册到上传静态网页(保姆级教程手把手教你上载自己的静态网页)_github 静态网页
- 92021 年云原生技术发展现状及未来趋势
- 10Spring boot使用一个接口实现任意一张表的增删改查
基于支持向量机(SVM)的数据分类预测_基于svm的数据分类预测
赞
踩
基于支持向量机(Support Vector Machine,SVM)的数据分类预测是另一种常见的机器学习方法。SVM 是一种监督学习算法,通过在数据空间中构建超平面(或者高维空间中的超平面)来进行分类。
SVM 的目的是在不同类别的数据之间寻找一个最优的超平面,使得不同类别的数据点在该超平面上的投影距离最大化。这个超平面可以将数据空间分为两个不同的区域,从而实现对数据的分类。支持向量是离超平面最近的训练样本点,它们对超平面的位置和划分起到关键作用。
SVM 的分类过程可以分为以下几个步骤:
1. 数据预处理:与其他机器学习方法一样,数据预处理也是 SVM 中的重要步骤。可以对数据进行缺失值处理、特征选择、数据标准化等。
2. 特征向量表示:将每个样本表示为一个特征向量。特征向量的选择根据具体问题,可以是原始数据的数值特征、文本数据的词袋模型等。
3. 训练过程:在 SVM 中,目标是找到一个最优的超平面来最大化不同类别之间的边界间隔。通过优化目标函数来确定最优的超平面参数,并使用优化算法如序列最小最优化(SMO)等对参数进行迭代优化。
4. 决策边界和预测:使用训练得到的超平面参数来构建决策边界,并用其对新的未知样本进行分类预测。边界内的样本被分类为一类,边界外的样本被分类为另一类。
需要注意的是,SVM 的性能和预测准确度依赖于多个因素,如核函数的选择、正则化参数的设置等。核函数可以将数据映射到高维空间,以便在低维度下进行非线性分类。常用的核函数有线性核、多项式核和高斯径向基核等。合适的核函数选择和参数调整可以提高 SVM 的分类性能。
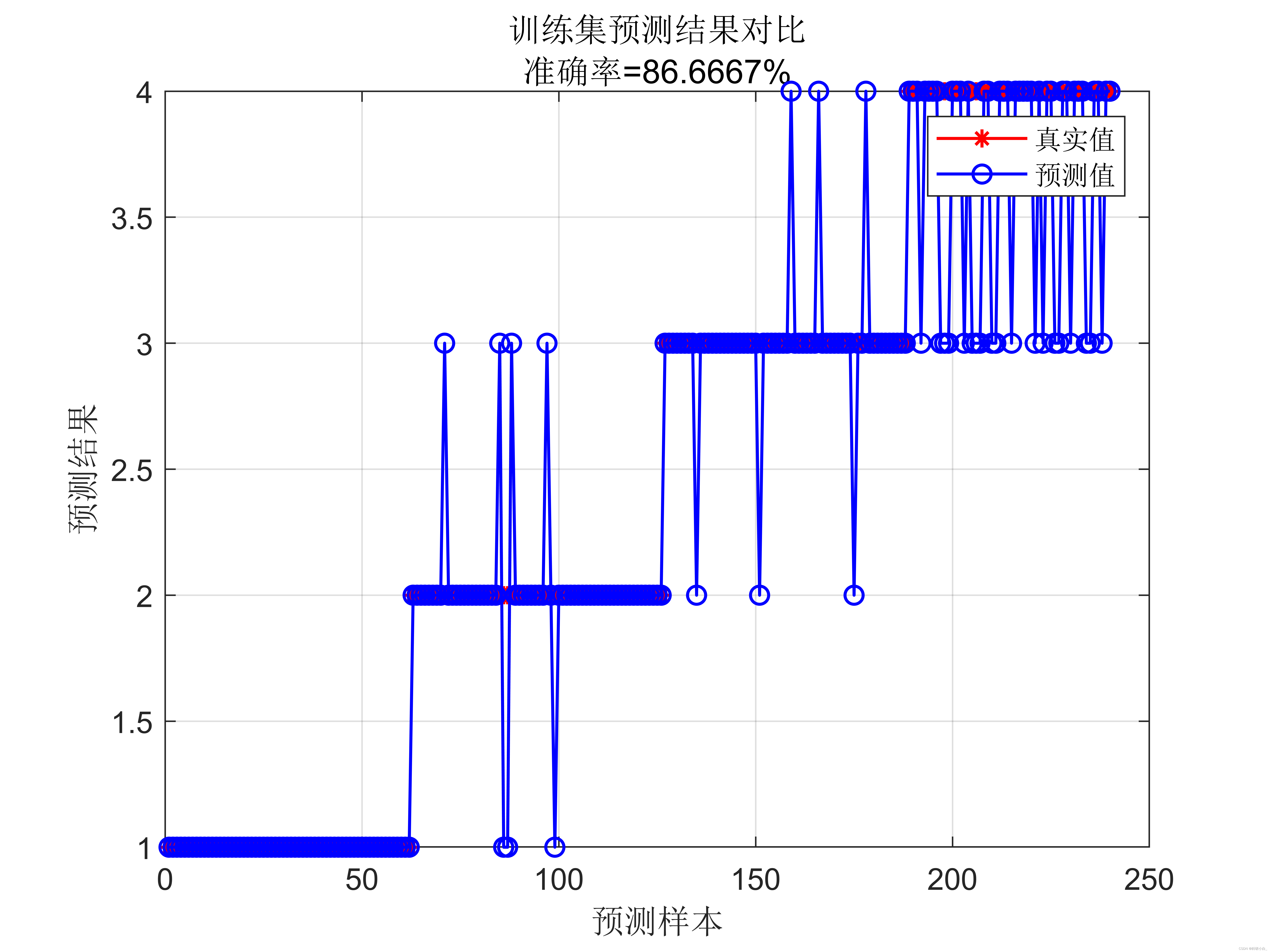
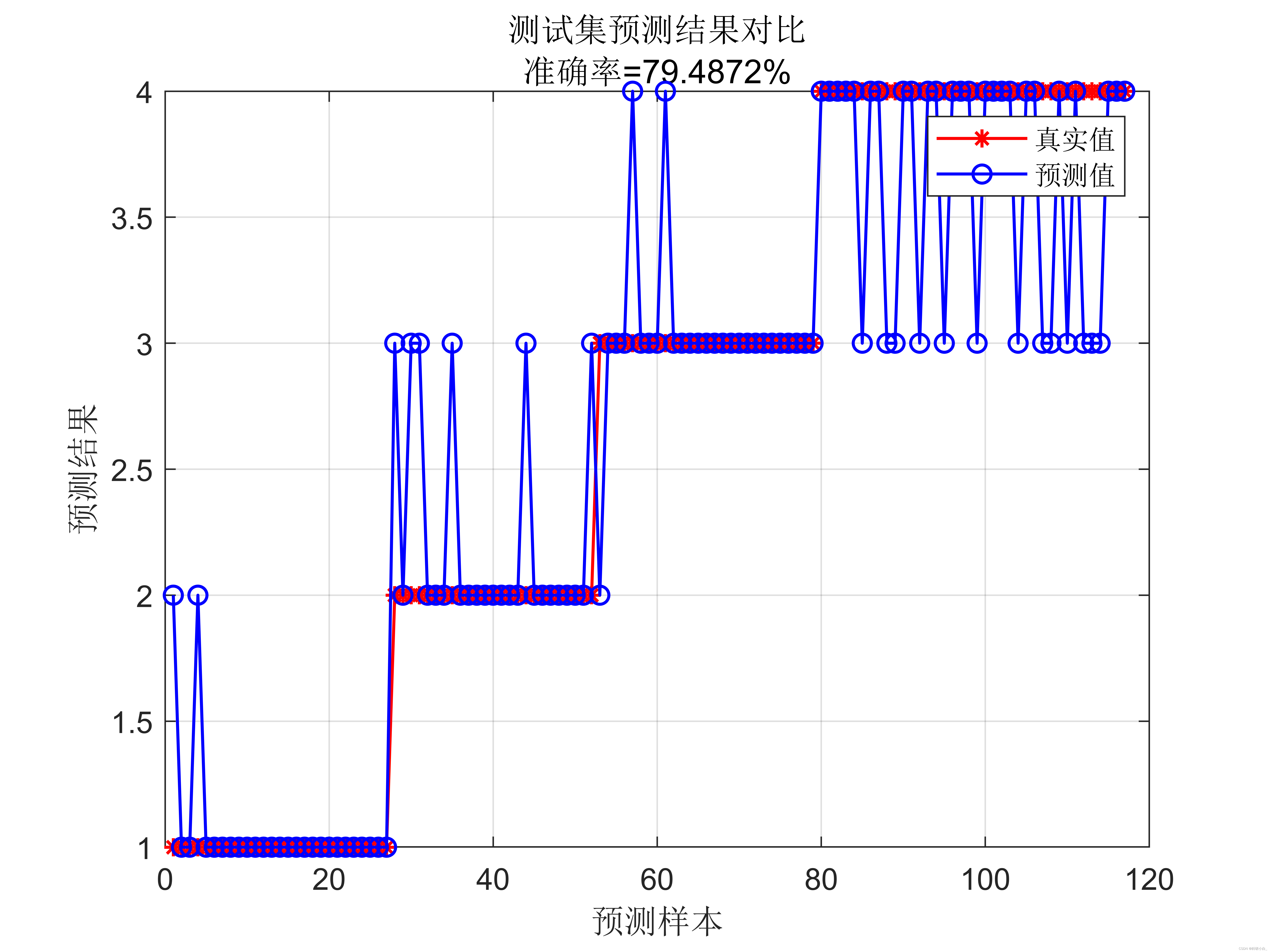
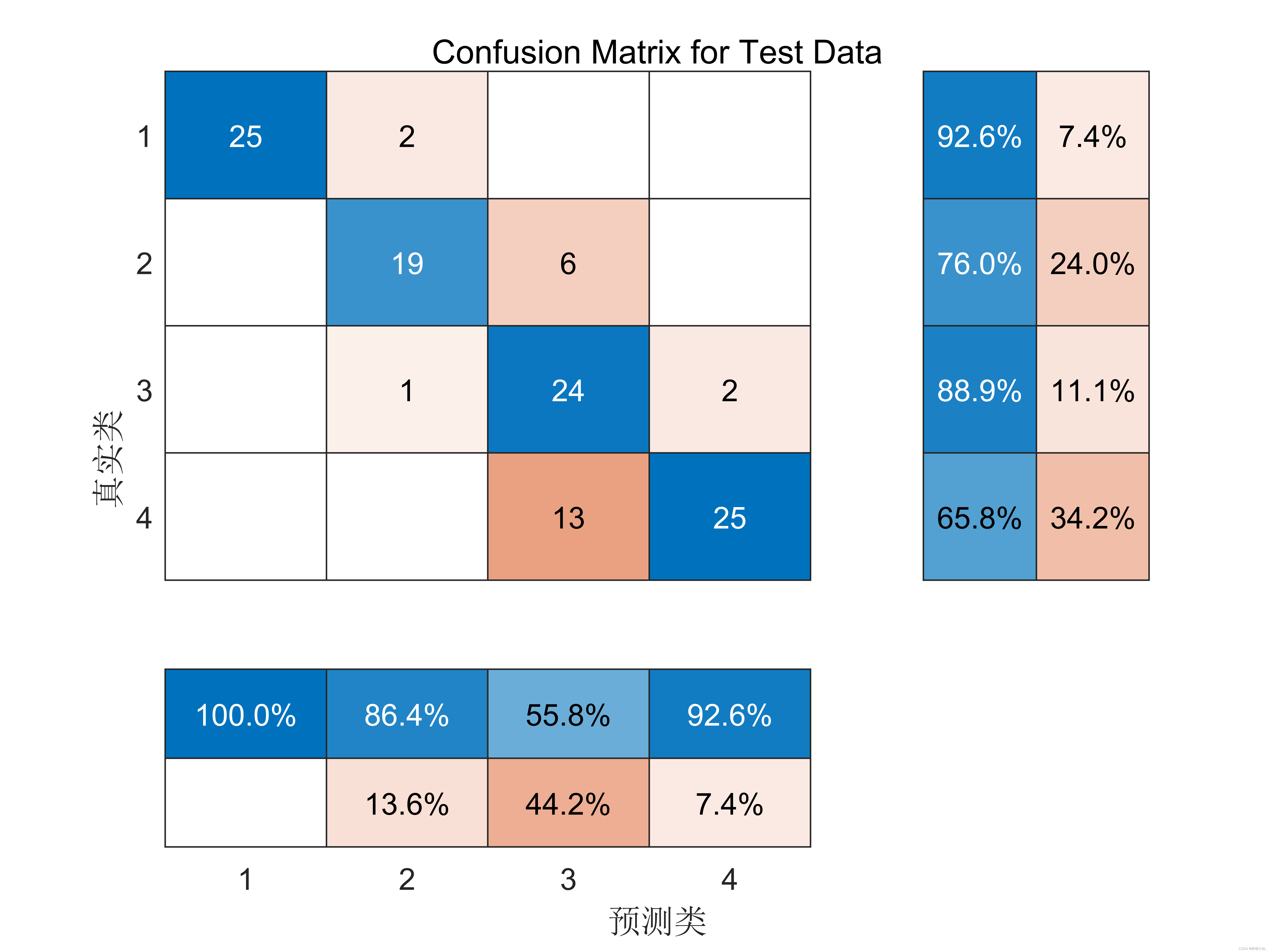
在使用 SVM 进行数据分类预测时,同样需要进行训练集和测试集的划分,并使用适当的评估指标来评估分类结果的准确度和性能。常见的评估指标包括准确度、精确度、召回率、F1 值等。
综上所述,基于支持向量机的数据分类预测是一种有效的机器学习方法,通过寻找最优的超平面来实现分类任务。它在处理高维数据和非线性分类问题上具有良好的性能。

更多联系方式如下:获取代码请关注MATLAB科研小白的个人公众号(即文章下方二维码),公众号致力于解决找代码难,写代码怵。各位有什么急需的代码,欢迎后台留言~不定时更新科研技巧类推文,可以一起探讨科研,写作,文献,代码等诸多学术问题,我们一起进步。

