- 1IDEA 常用快捷键 Windows 版_idea alt+左键
- 2linux下安装mysql-5.7.25详细步骤_mysql5.7.25-2.4.1-7.4.tar.gz
- 3如何实现两个电脑之间通过以太网(网线)实现文件互传_以太网台式电脑之间怎么快速传文件
- 4微信公众号-图片裁剪并实现上传
- 5Sora背后团队名单曝光,简直降维打击
- 6二级c语言2013年真题,2013年3月全国计算机二级c语言真题
- 7CMDB 定位:从应用本质启动CMDB项目_itil 对cmdb的定义
- 8Android Studio中开发java工程_android studiojava开发
- 9Kubernetes v1.20.0-添加pvc后无法动态创建pv解决方法_- --feature-gates=removeselflink=false
- 10mysql中xs表示什么_xs代表什么意思
分布式与一致性协议之Raft算法与一致哈希算法(一)
赞
踩
Raft算法
Raft与一致性
有很多人把Raft算法当成一致性算法,其实它不是一致性算法而是共识算法,是一个Multi-Paxos算法,实现的是如何就一系列值达成共识。并且,Raft算法能容忍少数节点的故障。虽然Raft算法能实现强一致性,也就是线性一致性(Linearizability),但需要客户端协议的配合。在实际场景中,我们一般需要根据场景特点,在一致性强度和实现复杂度之间进行权衡。比如Consul实现了3种一致性模型。
- 1.default:客户端访问领导者节点执行读操作,领导者确认自己处于稳定状态时(在leader leasing时间内),返回本地数据给客户端,否则返回错误给客户端。
在这种情况下,客户端是可能读到旧数据的,比如此时发生了网络分区,新领导者已经更新过数据,但因为网络故障,旧领导者未更新数据也未退位,仍处于稳定状态。 - 2.consistent:客户端访问领导者节点执行读操作,领导者在大多数节点确认自己仍是领导者之后返回本地数据给客户端,否则返回错误给客户端。在这种情况下,客户端读到的都是最新数据。
- 3.stale:从任意节点读数据,不局限于领导者节点,客户端可能会读到旧数据。
一般而言,在实际工程种,使用Consul的consistent旧可以了,不用线性一致性,只要能保证写操作完成后,每次读都能读到最新值即可。比如为了实现幂等操作,我们使用一个编号(ID)来唯一标记一个操作,并使用一个状态字段(nil/done)来标记操作是否已经执行,那么只要我们能保证设置了ID对应状态值为done后,能立即和一直读到最新状态值,旧可以防止操作的重复执行,实现幂等性。 - 总的来说,Raft算法能很好地处理绝大部分场景地一致性问题,推荐在设计分布式系统时,优先考虑Raft算法,当Raft算法不能满足现有场景需求时,再去调研其他共识算法。比如QQ后台地海量分布式系统,其中配置中心、名字服务以及时序数据库地META节点,采用Raft算法。在设计时序数据库的DATA节点一致性时,基于水平扩展、性能和数据完整性等考虑,就没采用Raft算法,而是采用了Quorum NWR、失败重传、反熵等机制。这样安排的好处是,不仅满足了业务的需求,还通过尽可能采用最终一致性方案的方式,实现系统的高性能,降低了成本。
注意。
Raft算法和兰伯特的Mutli-Paxos的不同之处有两点:
- 1.首先,在Raft算法中,不是所有节点都能当领导者,只有日志较完整地节点(也就是日志完整度不比半数节点低的节点)才能当选领导者
- 2.其次,在Raft算法中,日志必须是连续的
思维拓展
Raft算法实现了"一切以我为准"的强领导者模型,那么这个设计有什么限制和局限呢?
领导者接收到大多数的"复制成功"响应后,就会将日志应用到自己的状态机,然后返回"成功"给客户端。如果此时有一个节点不在"大多数"中,也就是说它接收日志项失败,那么Raft算法会如何实现日志的一致呢?
对于接收日志项失败的节点,Raft算法采用了以下机制来确保日志的一致性:
- 1.日志追赶(Log Compaction):如果某个节点因为某些原因(如网络分区、节点故障等)没有接收到最新的日志项,当该节点重新加入集群并成为跟随者后,它会向领导者请求复制缺失的日志项。领导者会将缺失的日志项发送给该节点,使其能够追赶上最新的日志状态。
- 2.安全性检查:在复制缺失的日志项之前,领导者会首先检查该节点的日志是否与自己保持一致。如果发现不一致(例如该节点包含了一些领导者没有的日志项),领导者会拒绝复制请求,并告知该节点回滚到某个一致的日志位置后再重新请求复制。这样可以确保在复制过程中不会出现日志不一致的情况。
- 3.安全性保证:Raft算法通过保证“已提交的日志项不会被覆盖或删除”来确保日志的一致性。具体来说,如果一条日志项已经被标记为已提交,那么领导者在后续的日志复制过程中,就不会再覆盖或删除这条已提交的日志项。即使领导者节点出现故障并被新的领导者替换,新的领导者也会继续复制和提交之前的已提交日志项,以确保所有节点的日志保持一致
重点总结
在了解了Raft算法的特点、领导者选举、什么是日志、如何复制日志以及如何处理不一致日志,还有成员变更的问题和单节点变更的方法等。希望大家能明确以下几个重点:
- 1.本质上,Raft算法以领导者为中心,选举出的领导者以"一切以我为准"的方式,达成值的共识和实现各节点日志的一直。
- 2.在Raft算法中,副本数据是以日志的形式存在的,其中日志项中的指令表示用户指定的数据。在Raft算法中日志必须是连续的,而兰伯特的Multi-Paxos不要求日志是连续的,而且在Raft算法中,日志不仅是数据的载体,日志的完整性还影响着领导者选举的结果。也就是说,日志完整性最高的节点才能当选领导者
- 3.单节点变更是利用"一次变更一个节点,不会同时存在旧配置和新配置两个’大多数’"的特性,实现成员变更。
在了解完Raft算法后,有人可能会有这样的疑问:强领导者模型会限制集群的写性能,有什么办法能突破Raft集群的写性能瓶颈呢?可以通过一致哈希算法来实现分集群。
一致哈希算法
概述
有些人可能有这样的疑问:如果我们通过Raft算法实现了KV存储,虽然领导者模型简化了算法实现和共识协商,但写请求只能限制在领导者节点上处理,导致集群的接入性能约等于单机,随着业务发展,集群的性能可能就扛不住了,造成系统过载和服务不可用,这时该怎么办呢?
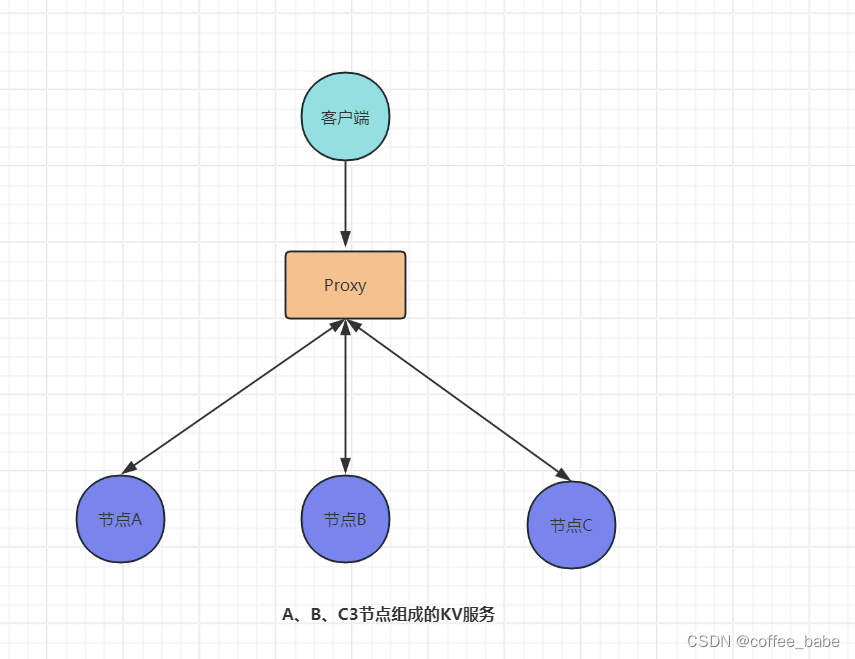
其实这是一个非常常见的问题。在我看来,这时我们就要通过分集群突破单集群的性能限制了。有人可能会说,分集群还不简单吗? 在模型中加入一个Proxyc层,由Proxy层处理来自客户端的读写请求,在接收到读写请求后,通过对Key做哈希找到对应的集群就可以了.
哈希算法的确是个办法,但它有个明显的缺点:当需要变更集群数时(比如从两个集群扩展为三个集群),大部分的数据都需要迁移,重新映射,而数据的迁移成本是非常高的,那么如何解决哈希算法数据迁移成本高的通电呢?答案就是使用一致哈希(Consistent Hashing)算法。
为了更好地理解如何通过哈希寻址实现KV存储地分集群,除了分析哈希算法寻址问题的本质之外,还会分析一致哈希是如何解决哈希算法数据迁移成本高这个痛点,以及如何实现数据访问的冷热相对均匀。你不仅能理解一致性哈希算法的原理,还能掌握通过一致哈希算法实现数访问冷热均匀的实战能力。
我们先来看一个思考题。
假设我们有一个由A、B、C3个节点组成(为了方便演示,使用节点来替代集群)的KV服务,每个节点存放不同的KV数据,如图所示