- 1Java编码技巧:验证码_{"status":"ok","text":" ##x5dgdqxiut6d1ph##1:/$wik
- 2IT行业工作单位分析(zz)
- 3C++高精度求平均数_利用c++输入1到100之间所有数的平均值
- 4Git+TortoiseGit 版本管理 详解_tortoisegit创建版本库
- 5【Echarts】自定义提示框tooltip样式,结合vue在自定义提示框中实现选择器和按钮事件
- 6电子模块|压力传感器模块HX711---硬件介绍_hx711称重传感器
- 7Hibernate分页+自定义标签
- 8微信小程序利用Echarts组件实现实时动态曲线_echarts动态曲线
- 9JDK1.8新特性(一) ----Lambda表达式、Stream API、函数式接口、方法引用_lambda表达式、函数式接口、stream api、新时间日期api、*方法引用和构造器调用、
- 10Debian常用命令
A Survey on Automatic Text Summarization
赞
踩
A Survey on Automatic Text Summarization
1.自动文本摘要的定义
Text summarization is compress the source text into a diminished version conserving its information content and overall meaning
1.1自动摘要的分类
单文档摘要和多文档摘要single , mul-summarization
1.2自动摘要方法类别
Extractive and abstactive summarization
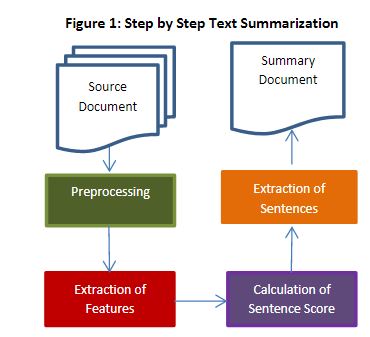
2.自动摘要处理过程及EXTRACTION FEATURES
The most of the current automated text summarization systems use extradiction methods. Extractive summarization process can be divided into three phases.
First phase is Pre-Processing, second phase isProcessing.
2.1预处理常见方法
(1)Part of Speech(POS) Tagging 词性标注
(2)Stop Word Filtering 停用词过滤
a, an, in, by can be considered as a stop words and filtered from plain text
(3)Stemming 抓出词干
removing from –ed or –ing from verbs, using singular instead of plural noun, etc.
(4)Feature Calculation
2.1.1.Title Similarity:

2.1.2.Sentence Position:

2.1.3.Term Weight(Term frequency)
The total term weight is calculated by computing tf and idf for document.
Here idf refers to inverse document frequency which simply tells about whether the term is common or rare across all documents.
The score of important score wi of word i can be calculated by the traditional tf.idf methods.

2.1.4.Sentence Length
This feature is suitable when eliminating the sentences which are too short such as datelines or author names
适合日期,作者名字比较短的句子
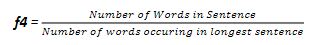
2.1.5.Thematic Word 主题词
This feature is related with domain specific words which occur frequently in a document are probably related topic
经常出现的特殊词往往与话题有关
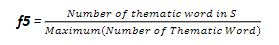
2.1.6.Proper Nouns 专有名词

2.1.7.Sentence to Sentence Similarity
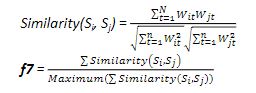
2.4.8.Numerical Data

3. SUMMARIZATION METHODS
3.1.Query Based and Generic Summarization
在基于查询的文本摘要中,给定文档的句子的评分是基于单词或短语的频率计数。 包含查询短语的句子的分数较高,而单个查询词的分数较高。

3.1.1. Bayesian Classifier
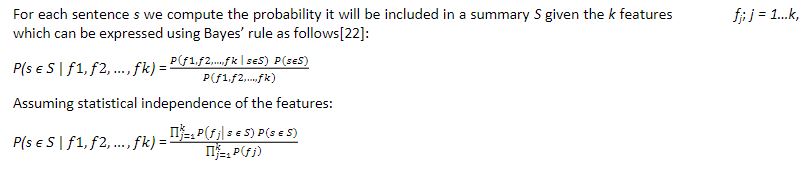
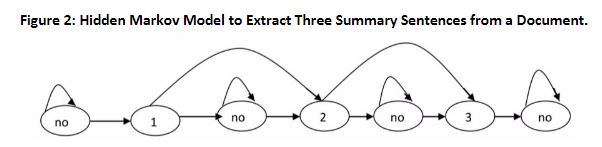
3.1.2. Hidden Markov Model
the HMM does not assume that the probability that sentence i is in the summary is independent of whether sentence i-1 is in the summary
The main idea is using a sequential model to account for local dependencies between sentences. In HMM Model, three features were used:
position of the sentence in the document,
number of terms in the sentence,
likeliness of the sentence terms given the document terms.
obtained the maximum-likelihood estimate for each transition probability,forming the transition matrix estimate
3.1.3. Neural Networks Based Text Summarization
f1 = Paragraph follows title (Paragraph Position)
f2 = Paragraph location in document
f3 = Sentence location paragraph
f4 = First sentence in paragraph
f5 = Sentence Length
f6 = Number of thematic words in sentence
f7 = Number of title words in sentence
Text Summarization process consists of three phases: training, feature fusion and sentence selection
3.1.4. Fuzzy Logic Based Text Summarization
模糊逻辑方法使用模糊规则和三角形隶属函数。模糊规则是IF-THEN的形式。三角形隶属函数将每个得分模糊为3个值中的一个,即LOW,MEDIUM和HIGH
4.EVALUATION