
- 1Logistic回归的基本原理(简单介绍)_logistic回归模型的理论基础
- 2PCB板上可以走100A的电流吗?大电流路径设置技巧_pcb焊盘十字连接过电流能力
- 3机器人运动学参数辨识(DH参数误差标定)_机器人运动学参数辨识方法
- 4 区块链共识机制简述
- 5Android SELinux开发入门指南之SELinux基础知识_selinux书
- 6Linux关于MySQL的卸载与安装详细教程(通过yum安装)_linux操作系统安装mysql5.7.44
- 7算法与数据结构 — 散列表_散列表装填因子计算
- 8BeanUtils源码解析
- 9Microsoft Visual C++ Runtime Library Runtime Error的解决的方法
- 10无人机超远距离WiFi传输,CV5200无线通信模组,无线音视频传输方案_无人机实时视频传输
AI绘画stability工具大全_stabilityai/stable-diffusion-2-inpainting
赞
踩
Stability AI 公司的关于AI绘画工具集合,这家公司从Stable Diffusion商业出来,具有能浓厚社区文化,凡事研究AI绘画都会关注这家公司!
Stability AI 的使命是让AI对所有人开放和有益。
本文基于Stable Diffusion 变体讲解,前情提要回顾:
AI绘画Stable Diffusion关键技术解析
SD(Stable Diffusion) 图像变体
您提供的图像作为输入,通过CLIP模型的图像编码器提取出图像的语义表征。这一表征充分捕捉了图像的语义信息,将其输入图像解码器,可以生成语义上相似的图像变体。
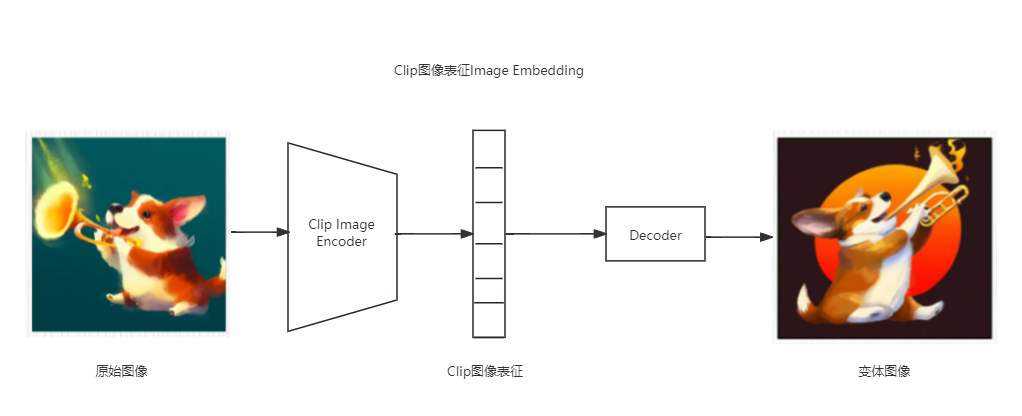
图像变体技术与Stable Diffusion模型的图生图模式在原理和效果上有显著不同。
Stable Diffusion的图生图是通过添加噪音扰动原图像,然后基于文本提示进行去噪重构。得到与原图轮廓相似、但内容和风格更符合文本的新图像。
而图像变体技术生成的图像,在色调、构图、人物形象等方面与输入图像高度相似,是输入图像的不同变体。
两者的关键区别在于:
- 图生图保持原图像轮廓,变化内容和风格;
- 图像变体保持原图像整体风格,进行微小变化。
通过对比效果可以明确看出:
- 图生图输出与原图在轮廓上高度相似;
- 图像变体输出在色调、构图等方面与原图类似。

图生图本质是依赖于 prompt 来引导相似轮廓下的内容变化;图像变体则以输入图像为基础,生成具有相似内容但不同样式的图像,过程不需要描述语句的引导。
SDXL Turbo
https://huggingface.co/stabilityai/sdxl-turbo
https://clipdrop.co/stable-diffusion-turbo

SDXL Turbo是一个新的基于文本到图像的模型。该模型的主要特点如下:
-
SDXL Turbo使用了一种新的蒸馏技术Adversarial Diffusion Distillation (ADD),可以在单步生成高质量的图像,大大减少了需要的步数(从50步减少到1步)。
-
与其他蒸馏方法相比,ADD可以避免图像中常见的模糊和伪影。SDXL Turbo的研究论文(https://stability.ai/research/adversarial-diffusion-distillation)详细介绍了这种新的蒸馏技术。
-
与其他diffusion模型相比,SDXL Turbo在保持图像质量的同时,极大地提升了推理速度。在A100上,生成一张512x512的图像只需要207ms。
-
在Stability AI的图像编辑平台Clipdrop上,可以体验SDXL Turbo的实时文本到图像生成功能。
-
SDXL Turbo的模型权重和代码在Hugging Face上开源,目前以非商业研究许可发布。
-
如果要将该模型用于商业用途,需要联系Stability AI获取授权。
A poetic winter scene where autumn meets winter. Snow gently falls onto a shallow autumn stream, creating a serene and almost melancholic atmosphere. The forest around is quiet and empty, with only the sound of the wind rustling the remaining leaves on the trees. The scene captures the transition from autumn to winter, with the snow softly covering the autumnal landscape, and the last leaves whispering in the cold breeze.
- 1

Stable Diffusion XL
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
https://github.com/Stability-AI/generative-models

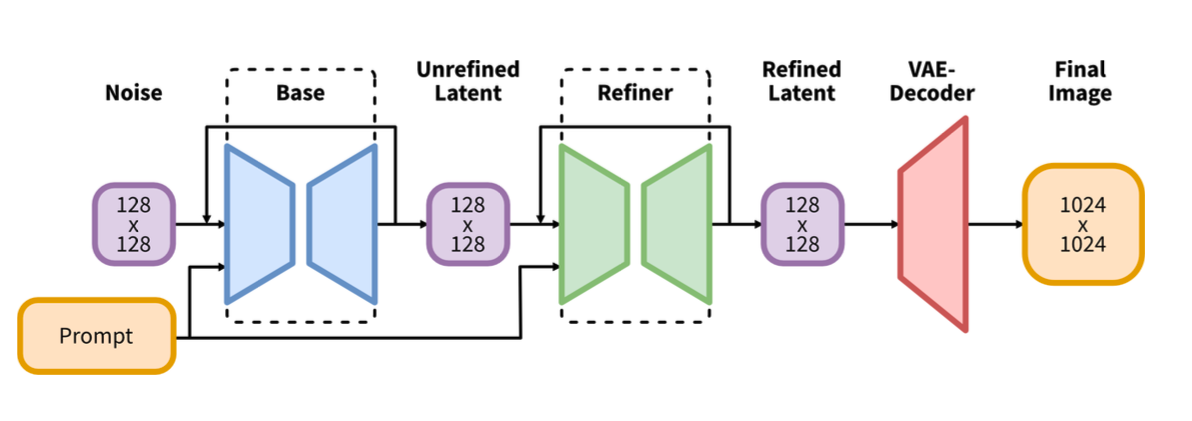
Base模型可以看作是一个文生图的过程,而Refiner模型则是图生图的过程。Refiner模型相比于Base模型的生成效果有一定提升,但这里的评估其实比较主观,论文中也是通过user study来统计的。
究其原因,Base模型在所有数据上训练,偶尔会生成低质量人类、粗糙背景等,所以引入Refiner模型,原论文中说的是使用high-quality, high resolution数据训练,因此Refiner模型的作用类似于使用图生图来修复细节。
评估
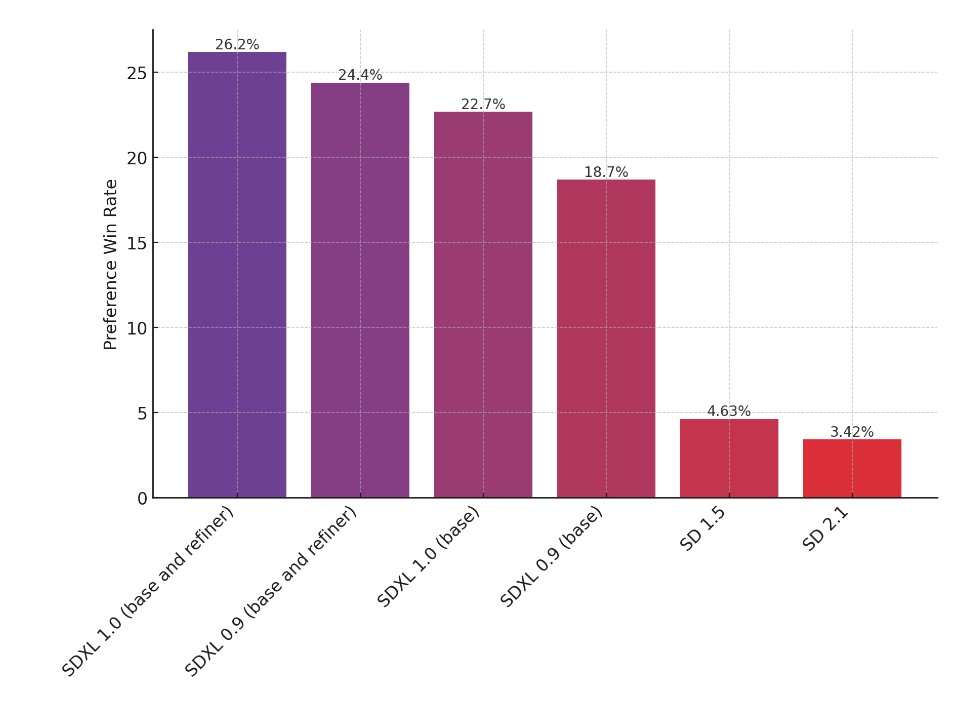
上图评估了用户对 SDXL(有或没有细化)相对于 SDXL 0.9 以及稳定扩散 1.5 和 2.1 的偏好。SDXL基础模型的性能明显优于之前的变体,并且与细化模块相结合的模型实现了最佳的整体性能。
Cleanup
https://huggingface.co/stabilityai/stable-diffusion-2-inpainting
Clipdrop Cleanup是一个基于AI的图片编辑工具,可以在几秒内从图片中移除不需要的对象、人物、文字或缺陷。
这个模型的特色在于它使用了一个固定的、预先训练好的文本编码器(OpenCLIP-ViT/H)来处理文本提示。它可以生成高分辨率的图像,甚至可以根据文本提示进行图像修改。


image-upscaler
ClipDrop image-upscaler 是一个基于 AI 的图像上采样工具,可以将低分辨率的图像上采样到高分辨率,使图像质量得到显著提升。
stable-diffusion x4 (https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler)放大器是一种基于文本指导的潜在上采样扩散模型。此模型经过1.25M步的训练,使用了LAION数据集中大于2048x2048像素的图像的10M子集。它在512x512像素的裁剪图像上进行训练,并且除了文本输入外,还接受作为输入参数的噪声级别,这可以根据预定义的扩散时间表向低分辨率输入添加噪声。
Stable Diffusion x2 Latent Upscaler (https://huggingface.co/stabilityai/sd-x2-latent-upscaler) 由Katherine Crowson与Stability AI合作开发的一种基于潜在扩散的放大器。这个模型是在LAION-2B数据集的高分辨率子集上训练的。它是一个扩散模型,操作在与稳定扩散模型相同的潜在空间中,这个空间被解码成全分辨率图像。

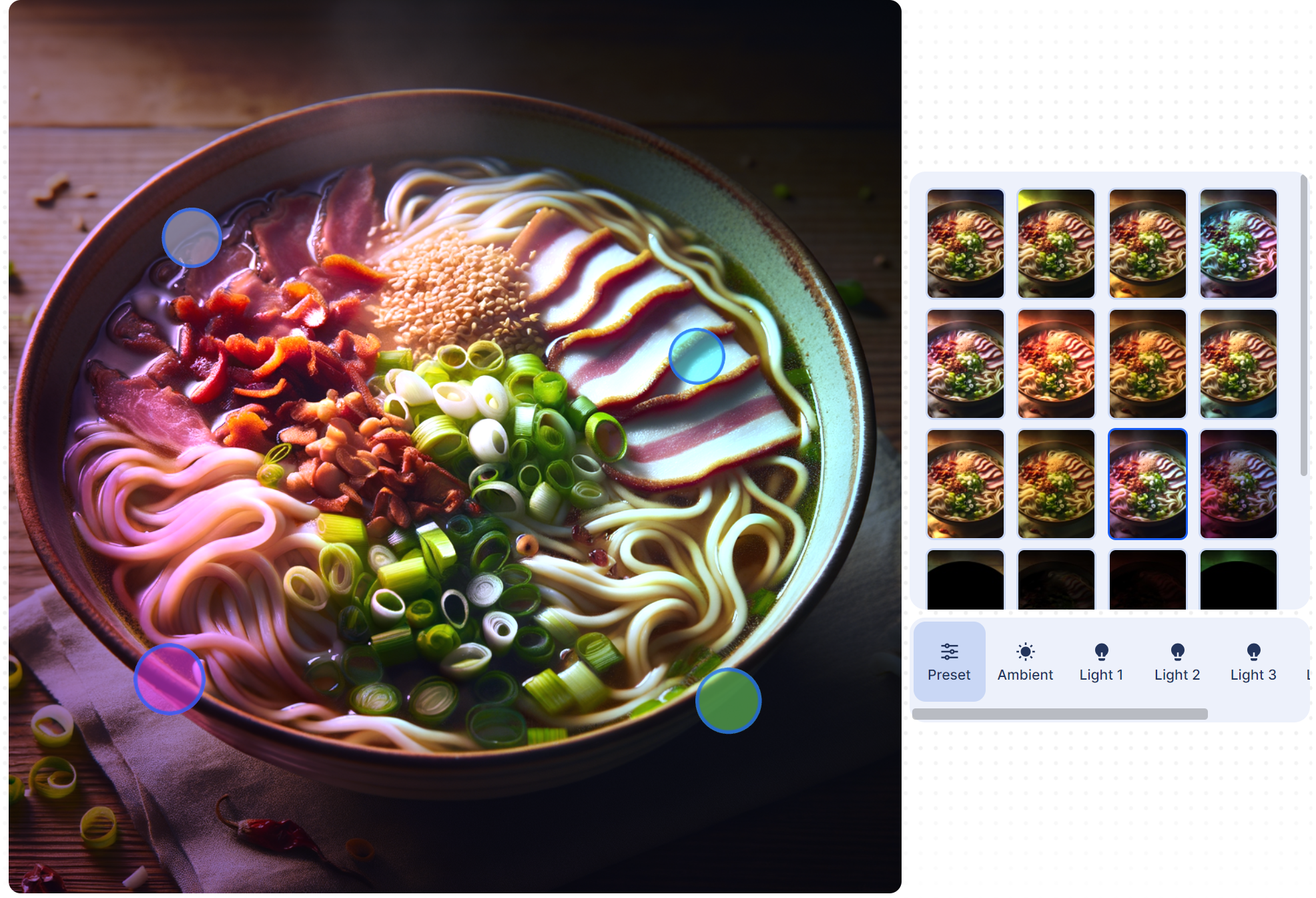
Relight
ClipDrop Relight 是一个使用人工智能技术的图片编辑工具,旨在为已拍摄的照片或绘图重新设置光线。这个工具可以简化传统的照片编辑过程,提供一种快速、专业的方式来改善照片的光照效果。
重新照明:利用人工智能,ClipDrop Relight 能够在照片拍摄后添加光源,改善照片的光照效果。这种能力超出了传统照片编辑软件的基本光照调整功能(如亮度和对比度调整)。
背景移除: 除了重新照明功能外,ClipDrop Relight 还可以用于移除照片的背景。用户只需上传照片,工具便会自动移除背景,并允许下载高清图片。
对象移除:这个工具还能用于从照片中移除特定的对象或人物。
图片放大: ClipDrop 提供了一个图像放大器,能够放大、增强或去噪照片。
为绘画添加阴影和高光:对于绘画作品,Relight 工具能够添加高光和阴影,使画作更加生动。
绘制阴影: 对于绘画创作,Relight 允许用户直接应用光源到绘画中,自动完成阴影的添加,这使得绘制阴影变得简单易行。


remove-background
ClipDrop Background Removal 是一个适合所有需要快速、高效移除图片背景的用户的工具,尤其适用于那些寻求创造性和专业外观照片的用户。

replace-background
ClipDrop Background Replacement 是一个利用人工智能技术来更换图片背景的工具。这个工具的主要目标是让用户能够轻松地将任何物体“传送”到任何地方。



stable-diffusion-reimagine
https://clipdrop.co/stable-diffusion-reimagine
https://stability.ai/news/stable-diffusion-reimagine
https://github.com/Stability-AI/stablediffusion/

Stable Diffusion Reimagine的新工具,它允许用户无限制地根据一个图像生成多个变体。
该工具的主要功能包括:
- 用户只需上传一张图像到算法中,就可以生成尽可能多的变体图像。不需要复杂的提示语。
- 它可以轻松改变卧室、时尚服饰等的风格和设计。文章给出了一些示例图像。
- 它还具有上缩放功能,可以上传小图片并生成细节水平至少加倍的图片。
- 该工具不会完全重建原图像,而是基于原图产生新图像。结果可能基于某些图片非常惊艳,对其他图片效果不佳。
- 它内置了过滤器来屏蔽不当请求,但可能还存在一定的错误分类情况。
- 该工具基于Stability AI新开发的算法,将文本编码器替换为图像编码器,从图像而不是文本生成图像。


swap
ClipDrop Swap 是一个能够在任何图片中交换人物的工具。
人物交换: ClipDrop Swap 允许用户在任何图片中交换人物,无论是画像、群体照片还是特殊场合的照片。
简单易用: 用户可以通过点击、粘贴或拖放文件来开始使用工具,操作简单直观。
多种应用场景: 这个工具适用于多种场景,包括画作、人像、团体照片、特殊主题和复古风格照片等。
创意和娱乐: ClipDrop Swap 提供了一个有趣的方式来创造新的图片,通过交换人物来创造有趣的或令人惊讶的视觉效果。
其他相关工具: ClipDrop 还提供了其他相关工具,如背景替换、背景移除、图片清理、图片放大等。


stable-doodle
ClipDrop Stable Doodle 是一个将涂鸦转换成真实图像的工具,它能够在几秒钟内将简单的绘画变成引人注目的图像。
涂鸦转换: 无论用户的绘画技巧如何,Stable Doodle 都能将涂鸦转换成令人惊叹的图像,例如风景插画。
快速转换: 该工具能够在几秒钟内完成涂鸦到真实图像的转换,非常适合快速创造视觉效果。
适用于多种风格: 不仅限于风景,还可以将涂鸦转换成动物、家具、3D图像和像素艺术等多种风格的图像。
简单易用: 用户只需上传涂鸦,选择风格,Stable Doodle 将自动处理并生成结果。
创意和娱乐: 这个工具提供了一个有趣的方式来将简单的涂鸦转化为具有吸引力的细节和色彩的场景。

text-remover
这是一个文本去除工具,可以从任何图片中去除文本。用户可以点击、粘贴或拖放最多10个文件开始使用。它可以自动检测并去除图片中的文本,无需手动选择就可以在几秒内完成。
该工具是免费的,对于小于1024大小的图片可以免费使用。更大的图片会被调整为1024大小。用户也可以订阅Clipdrop高级版来获取更高质量的文本去除服务。

uncrop
Uncrop的主要功能是编辑图片的长宽比。用户可以上传要调整的图片,选择新的长宽比,Uncrop将生成匹配新长宽比的图片。

结语
算法的创新在于发现,创意的精髓在于把握。
欢迎留言交流!
我是李孟聊AI,独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!
https://www.zhihu.com/people/dlimeng

