
总结一下JDK1.6,说是总结,其实也就是把别人总结的东西再复述一遍,当做自己的东西,留以学习备忘。
新特性:
Desktop类和SystemTray类
Compiler API
Console开发控制台程序
脚本语言的支持
GUI(程序启动画面,JTable的排序、高亮显示和过滤)
插入式注解处理API(Pluggable Annotation Processing API)
WEBSERVICE相关(Web服务元数据,Common Annotations,JAXB2,StAX,JAX-WS2.0)
DB相关(嵌入式数据库 Derby,JDBC4.0)
监视和管理
安全性
Instrumentation
JMX与系统管理
HTML相关(NTML认证,轻量级Http Server API,Cookie管理特性,NetworkInterface的增强,域名的国际化)
1. Desktop类和SystemTray类
在JDK6中 ,AWT新增加了两个类:Desktop和SystemTray,前者可以用来打开系统默认浏览器浏览指定的URL,打开系统默认邮件客户端给指定的邮箱发邮件,用默认应用程序打开或编辑文件(比如,用记事本打开以txt为后缀名的文件),用系统默认的打印机打印文档;后者可以用来在系统托盘区创建一个托盘程序。
下面代码演示了Desktop和SystemTray的用法。
public class DesktopTray { private static Desktop desktop; private static SystemTray st; private static PopupMenu pm; public static void main(String[] args) { if(Desktop.isDesktopSupported()){//判断当前平台是否支持Desktop类 desktop = Desktop.getDesktop(); } if(SystemTray.isSupported()){//判断当前平台是否支持系统托盘 st = SystemTray.getSystemTray(); Image image = Toolkit.getDefaultToolkit().getImage("netbeans.png");//定义托盘图标的图片 createPopupMenu();//创建托盘图标右键弹出式菜单 TrayIcon ti = new TrayIcon(image, "Desktop Demo Tray", pm);//创建托盘图标 try { st.add(ti);//将图标加入托盘 } catch (AWTException ex) { ex.printStackTrace(); } } } public static void sendMail(String mail){ if(desktop!=null && desktop.isSupported(Desktop.Action.MAIL)){//判断是否支持 try { desktop.mail(new URI(mail));//调用本地邮箱客户端 } catch (IOException ex) { ex.printStackTrace(); } catch (URISyntaxException ex) { ex.printStackTrace(); } } } public static void openBrowser(String url){ if(desktop!=null && desktop.isSupported(Desktop.Action.BROWSE)){//判断是否支持 try { desktop.browse(new URI(url));//调用本地浏览器 } catch (IOException ex) { ex.printStackTrace(); } catch (URISyntaxException ex) { ex.printStackTrace(); } } } public static void edit(){ if(desktop!=null && desktop.isSupported(Desktop.Action.EDIT)){//判断是否支持 try { File txtFile = new File("test.txt"); if(!txtFile.exists()){ txtFile.createNewFile(); } desktop.edit(txtFile);//调用本地编辑器 } catch (IOException ex) { ex.printStackTrace(); } } } public static void createPopupMenu(){ pm = new PopupMenu(); MenuItem openBrowser = new MenuItem("Open My Blog"); openBrowser.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e) { openBrowser("http://blog.csdn.net/chinajash"); } }); MenuItem sendMail = new MenuItem("Send Mail to me"); sendMail.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e) { sendMail("mailto:chinajash@yahoo.com.cn"); } }); MenuItem edit = new MenuItem("Edit Text File"); sendMail.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e) { edit(); } }); MenuItem exitMenu = new MenuItem("&Exit"); exitMenu.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e) { System.exit(0); } }); pm.add(openBrowser); pm.add(sendMail); pm.add(edit); pm.addSeparator(); pm.add(exitMenu); } }
2. Compiler API
摘自https://www.ibm.com/developerworks/cn/java/j-lo-jse64/
新 API 功能简介
JDK 6 提供了在运行时调用编译器的 API,后面我们将假设把此 API 应用在 JSP 技术中。在传统的 JSP 技术中,服务器处理 JSP 通常需要进行下面 6 个步骤:
- 分析 JSP 代码;
- 生成 Java 代码;
- 将 Java 代码写入存储器;
- 启动另外一个进程并运行编译器编译 Java 代码;
- 将类文件写入存储器;
- 服务器读入类文件并运行;
但如果采用运行时编译,可以同时简化步骤 4 和 5,节约新进程的开销和写入存储器的输出开销,提高系统效率。实际上,在 JDK 5 中,Sun 也提供了调用编译器的编程接口。然而不同的是,老版本的编程接口并不是标准 API 的一部分,而是作为 Sun 的专有实现提供的,而新版则带来了标准化的优点。
新 API 的第二个新特性是可以编译抽象文件,理论上是任何形式的对象 —— 只要该对象实现了特定的接口。有了这个特性,上述例子中的步骤 3 也可以省略。整个 JSP 的编译运行在一个进程中完成,同时消除额外的输入输出操作。
第三个新特性是可以收集编译时的诊断信息。作为对前两个新特性的补充,它可以使开发人员轻松的输出必要的编译错误或者是警告信息,从而省去了很多重定向的麻烦。
运行时编译 Java 文件
在 JDK 6 中,类库通过 javax.tools 包提供了程序运行时调用编译器的 API。从这个包的名字 tools 可以看出,这个开发包提供的功能并不仅仅限于编译器。工具还包括 javah、jar、pack200 等,它们都是 JDK 提供的命令行工具。这个开发包希望通过实现一个统一的接口,可以在运行时调用这些工具。在 JDK 6 中,编译器被给予了特别的重视。针对编译器,JDK 设计了两个接口,分别是 JavaCompiler 和JavaCompiler.CompilationTask。
下面给出一个例子,展示如何在运行时调用编译器。
- 指定编译文件名称(该文件必须在 CLASSPATH 中可以找到):
String fullQuanlifiedFileName = "compile" + java.io.File.separator +"Target.java";
- 获得编译器对象:
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
通过调用 ToolProvider 的 getSystemJavaCompiler 方法,JDK 提供了将当前平台的编译器映射到内存中的一个对象。这样使用者可以在运行时操纵编译器。JavaCompiler 是一个接口,它继承了javax.tools.Tool 接口。因此,第三方实现的编译器,只要符合规范就能通过统一的接口调用。同时,tools 开发包希望对所有的工具提供统一的运行时调用接口。相信将来,ToolProvider 类将会为更多地工具提供 getSystemXXXTool 方法。tools 开发包实际为多种不同工具、不同实现的共存提供了框架。
- 编译文件:
int result = compiler.run(null, null, null, fileToCompile);
获得编译器对象之后,可以调用 Tool.run 方法对源文件进行编译。Run 方法的前三个参数,分别可以用来重定向标准输入、标准输出和标准错误输出,null 值表示使用默认值。清单 1 给出了一个完整的例子:
清单 1. 程序运行时编译文件
package compile; import java.util.Date; public class Target { public void doSomething(){ Date date = new Date(10, 3, 3); // 这个构造函数被标记为deprecated, 编译时会 // 向错误输出输出信息。 System.out.println("Doing..."); } } package compile; import javax.tools.*; import java.io.FileOutputStream; public class Compiler { public static void main(String[] args) throws Exception{ String fullQuanlifiedFileName = "compile" + java.io.File.separator + "Target.java"; JavaCompiler compiler = ToolProvider.getSystemJavaCompiler(); FileOutputStream err = new FileOutputStream("err.txt"); int compilationResult = compiler.run(null, null, err, fullQuanlifiedFileName); if(compilationResult == 0){ System.out.println("Done"); } else { System.out.println("Fail"); } } }
首先运行 <JDK60_INSTALLATION_DIR>\bin\javac Compiler.java,然后运行 <JDK60_INSTALLATION_DIR>\jdk1.6.0\bin\java compile.Compiler。屏幕上将输出 Done ,并会在当前目录生成一个 err.txt 文件,文件内容如下:
Note: compile/Target.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
run 方法,可以发现最后一个参数是
String...arguments,是一个变长的字符串数组。它的实际作用是接受传递给 javac 的参数。假设要编译 Target.java 文件,并显示编译过程中的详细信息。命令行为:
javac Target.java -verbose。相应的可以将 17 句改为:
int compilationResult = compiler.run(null, null, err, “-verbose”,fullQuanlifiedFileName);
编译非文本形式的文件
JDK 6 的编译器 API 的另外一个强大之处在于,它可以编译的源文件的形式并不局限于文本文件。JavaCompiler 类依靠文件管理服务可以编译多种形式的源文件。比如直接由内存中的字符串构造的文件,或者是从数据库中取出的文件。这种服务是由 JavaFileManager 类提供的。通常的编译过程分为以下几个步骤:
- 解析 javac 的参数;
- 在 source path 和/或 CLASSPATH 中查找源文件或者 jar 包;
- 处理输入,输出文件;
在这个过程中,JavaFileManager 类可以起到创建输出文件,读入并缓存输出文件的作用。由于它可以读入并缓存输入文件,这就使得读入各种形式的输入文件成为可能。JDK 提供的命令行工具,处理机制也大致相似,在未来的版本中,其它的工具处理各种形式的源文件也成为可能。为此,新的 JDK 定义了javax.tools.FileObject 和 javax.tools.JavaFileObject 接口。任何类,只要实现了这个接口,就可以被 JavaFileManager 识别。
如果要使用 JavaFileManager,就必须构造 CompilationTask。JDK 6 提供了JavaCompiler.CompilationTask 类来封装一个编译操作。这个类可以通过:
JavaCompiler.getTask ( Writer out, JavaFileManager fileManager, DiagnosticListener<? super JavaFileObject> diagnosticListener, Iterable<String> options, Iterable<String> classes, Iterable<? extends JavaFileObject> compilationUnits )
方法得到。关于每个参数的含义,请参见 JDK 文档。传递不同的参数,会得到不同的CompilationTask。通过构造这个类,一个编译过程可以被分成多步。进一步,CompilationTask 提供了 setProcessors(Iterable<? extends Processor>processors) 方法,用户可以制定处理 annotation 的处理器。图 1 展示了通过 CompilationTask 进行编译的过程:
图 1. 使用 CompilationTask 进行编译

下面的例子通过构造 CompilationTask 分多步编译一组 Java 源文件。
清单 2. 构造 CompilationTask 进行编译
package math; public class Calculator { public int multiply(int multiplicand, int multiplier) { return multiplicand * multiplier; } } package compile; import javax.tools.*; import java.io.FileOutputStream; import java.util.Arrays; public class Compiler { public static void main(String[] args) throws Exception{ String fullQuanlifiedFileName = "math" + java.io.File.separator +"Calculator.java"; JavaCompiler compiler = ToolProvider.getSystemJavaCompiler(); StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null); Iterable<? extends JavaFileObject> files = fileManager.getJavaFileObjectsFromStrings( Arrays.asList(fullQuanlifiedFileName)); JavaCompiler.CompilationTask task = compiler.getTask( null, fileManager, null, null, null, files); Boolean result = task.call(); if( result == true ) { System.out.println("Succeeded"); } } }
以上是第一步,通过构造一个 CompilationTask 编译了一个 Java 文件。14-17 行实现了主要逻辑。第 14 行,首先取得一个编译器对象。由于仅仅需要编译普通文件,因此第 15 行中通过编译器对象取得了一个标准文件管理器。16 行,将需要编译的文件构造成了一个 Iterable 对象。最后将文件管理器和Iterable 对象传递给 JavaCompiler 的 getTask 方法,取得了 JavaCompiler.CompilationTask 对象。
接下来第二步,开发者希望生成 Calculator 的一个测试类,而不是手工编写。使用 compiler API,可以将内存中的一段字符串,编译成一个 CLASS 文件。
清单 3. 定制 JavaFileObject 对象
package math; import java.net.URI; public class StringObject extends SimpleJavaFileObject{ private String contents = null; public StringObject(String className, String contents) throws Exception{ super(new URI(className), Kind.SOURCE); this.contents = contents; } public CharSequence getCharContent(boolean ignoreEncodingErrors) throws IOException { return contents; } }
SimpleJavaFileObject 是 JavaFileObject 的子类,它提供了默认的实现。继承 SimpleJavaObject 之后,只需要实现 getCharContent 方法。如 清单 3 中的 9-11 行所示。接下来,在内存中构造Calculator 的测试类 CalculatorTest,并将代表该类的字符串放置到 StringObject 中,传递给JavaCompiler 的 getTask 方法。清单 4 展现了这些步骤。
清单 4. 编译非文本形式的源文件
package math; import javax.tools.*; import java.io.FileOutputStream; import java.util.Arrays; public class AdvancedCompiler { public static void main(String[] args) throws Exception{ // Steps used to compile Calculator // Steps used to compile StringObject // construct CalculatorTest in memory JavaCompiler compiler = ToolProvider.getSystemJavaCompiler(); StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null); JavaFileObject file = constructTestor(); Iterable<? extends JavaFileObject> files = Arrays.asList(file); JavaCompiler.CompilationTask task = compiler.getTask ( null, fileManager, null, null, null, files); Boolean result = task.call(); if( result == true ) { System.out.println("Succeeded"); } } private static SimpleJavaFileObject constructTestor() { StringBuilder contents = new StringBuilder( "package math;" + "class CalculatorTest {\n" + " public void testMultiply() {\n" + " Calculator c = new Calculator();\n" + " System.out.println(c.multiply(2, 4));\n" + " }\n" + " public static void main(String[] args) {\n" + " CalculatorTest ct = new CalculatorTest();\n" + " ct.testMultiply();\n" + " }\n" + "}\n"); StringObject so = null; try { so = new StringObject("math.CalculatorTest", contents.toString()); } catch(Exception exception) { exception.printStackTrace(); } return so; } }
实现逻辑和 清单 2 相似。不同的是在 20-30 行,程序在内存中构造了 CalculatorTest 类,并且通过StringObject 的构造函数,将内存中的字符串,转换成了 JavaFileObject 对象。
采集编译器的诊断信息
第三个新增加的功能,是收集编译过程中的诊断信息。诊断信息,通常指错误、警告或是编译过程中的详尽输出。JDK 6 通过 Listener 机制,获取这些信息。如果要注册一个 DiagnosticListener,必须使用 CompilationTask 来进行编译,因为 Tool 的 run 方法没有办法注册 Listener。步骤很简单,先构造一个 Listener,然后传递给 JavaFileManager 的构造函数。清单 5 对 清单 2 进行了改动,展示了如何注册一个 DiagnosticListener。
清单 5. 注册一个 DiagnosticListener 收集编译信息
package math; public class Calculator { public int multiply(int multiplicand, int multiplier) { return multiplicand * multiplier // deliberately omit semicolon, ADiagnosticListener // will take effect } } package compile; import javax.tools.*; import java.io.FileOutputStream; import java.util.Arrays; public class CompilerWithListener { public static void main(String[] args) throws Exception{ String fullQuanlifiedFileName = "math" + java.io.File.separator +"Calculator.java"; JavaCompiler compiler = ToolProvider.getSystemJavaCompiler(); StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null); Iterable<? extends JavaFileObject> files = fileManager.getJavaFileObjectsFromStrings( Arrays.asList(fullQuanlifiedFileName)); DiagnosticCollector<JavaFileObject> collector = new DiagnosticCollector<JavaFileObject>(); JavaCompiler.CompilationTask task = compiler.getTask(null, fileManager, collector, null, null, files); Boolean result = task.call(); List<Diagnostic<? extends JavaFileObject>> diagnostics = collector.getDiagnostics(); for(Diagnostic<? extends JavaFileObject> d : diagnostics){ System.out.println("Line Number->" + d.getLineNumber()); System.out.println("Message->"+ d.getMessage(Locale.ENGLISH)); System.out.println("Source" + d.getCode()); System.out.println("\n"); } if( result == true ) { System.out.println("Succeeded"); } } }
在 17 行,构造了一个 DiagnosticCollector 对象,这个对象由 JDK 提供,它实现了DiagnosticListener 接口。18 行将它注册到 CompilationTask 中去。一个编译过程可能有多个诊断信息。每一个诊断信息,被抽象为一个 Diagnostic。20-26 行,将所有的诊断信息逐个输出。编译并运行 Compiler,得到以下输出:
清单 6. DiagnosticCollector 收集的编译信息
Line Number->5
Message->math/Calculator.java:5: ';' expected
Source->compiler.err.expected
实际上,也可以由用户自己定制。清单 7 给出了一个定制的 Listener。
清单 7. 自定义的 DiagnosticListener
class ADiagnosticListener implements DiagnosticListener<JavaFileObject>{ public void report(Diagnostic<? extends JavaFileObject> diagnostic) { System.out.println("Line Number->" + diagnostic.getLineNumber()); System.out.println("Message->"+ diagnostic.getMessage(Locale.ENGLISH)); System.out.println("Source" + diagnostic.getCode()); System.out.println("\n"); } }
总结
JDK 6 的编译器新特性,使得开发者可以更自如的控制编译的过程,这给了工具开发者更加灵活的自由度。通过 API 的调用完成编译操作的特性,使得开发者可以更方便、高效地将编译变为软件系统运行时的服务。而编译更广泛形式的源代码,则为整合更多的数据源及功能提供了强大的支持。相信随着 JDK 的不断完善,更多的工具将具有 API 支持,我们拭目以待。
3. Console开发控制台程序
摘自http://blog.csdn.net/tangyu477/article/details/40503255
JDK6 中提供了java.io.Console 类专用来访问基于字符的控制台设备. 你的程序如果要与Windows 下的cmd 或者Linux 下的Terminal交互,就可以用Console类代劳. 但我们不总是能得到可用的Console, 一个JVM是否有可用的Console依赖于底层平台和JVM如何被调用. 如果JVM是在交互式命令行(比如Windows的cmd)中启动的,并且输入输出没有重定向到另外的地方,那么就可以得到一个可用的Console实例。
import java.io.Console; public class ConsoleTest { public static void main(String[] args) { Console console = System.console(); if(console != null){ String username = console.readLine("Enter username:"); String password = new String(console.readPassword("Enter password:")); System.out.println("Username is:" + username); System.out.println("Password is:" + password); } else { System.out.println("Console 不可用!"); } } }
如果这个程序在eclipse里面直接运行,那么得到的结果是Console不可用,示Console 不可获得,那是因为JVM 不是在命令行中被调用的或者输入输出
被重定向了. 但是如果我们在命令行中运行上面程序(java ConsoleTest),程序能够获得Console实例,并执行如下:
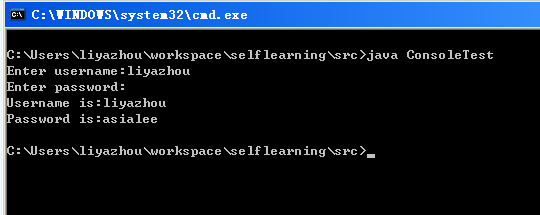
这个里面的最大的功能就是密码能够实现不回显,记得以前要实现这个功能,还得去使用JNI来实现,这下就方便多了。
4. 脚本语言的支持
摘自http://blog.csdn.net/zmken497300/article/details/51817869
Java 脚本 API 概述
Java SE 6 引入了对 Java Specification Request(JSR)223 的支持,JSR 223 旨在定义一个统一的规范,使得
Java 应用程序可以通过一套固定的接口与各种脚本引擎交互,从而达到在 Java 平台上调用各种脚本语言的目的。javax.script
包定义了这些接口,即 Java 脚本编程 API。Java 脚本 API 的目标与 Apache 项目 Bean Script Framework(BSF)类
似,通过它 Java 应用程序就能通过虚拟机调用各种脚本,同时,脚本语言也能访问应用程序中的 Java 对象和方法。Java 脚本
API 是连通 Java 平台和脚本语言的桥梁。首先,通过它为数众多的现有 Java 库就能被各种脚本语言所利用,节省了开发成
本缩短了开发周期;其次,可以把一些复杂异变的业务逻辑交给脚本语言处理,这又大大提高了开发效率。
在 javax.script 包中定义的实现类并不多,主要是一些接口和对应的抽象类,图 1 显示了其中包含的各个接口和类。
这个包的具体实现类少的根本原因是这个包只是定义了一个编程接口的框架规范,至于对如何解析运行具体的脚本语言,还需要由第三方提供实现。
虽然这些脚本引擎的实现各不相同,但是对于 Java 脚本 API 的使用者来说,这些具体的实现被很好的隔离隐藏了。Java 脚本 API 为开发者提供了如下功能:
- 获取脚本程序输入,通过脚本引擎运行脚本并返回运行结果,这是最核心的接口。
- 发现脚本引擎,查询脚本引擎信息。
- 通过脚本引擎的运行上下文在脚本和 Java 平台间交换数据。
- 通过 Java 应用程序调用脚本函数。
在详细介绍这四个功能之前,我们先通过一个简单的例子来展示如何通过 Java 语言来运行脚本程序,这里仍然以经典的“Hello World”开始。
清单 1. Hello World
import javax.script.*; public class HelloWorld { public static void main(String[] args) throws ScriptException { ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("JavaScript"); engine.eval("print ('Hello World')"); } }
这个例子非常直观,只要通过 ScriptEngineManager 和 ScriptEngine 这两个类就可以完成最简单的调用。首先,ScriptEngineManager 实例创建一个
ScriptEngine 实例,然后返回的 ScriptEngine 实例解析 JavaScript 脚本,输出运行结果。运行这段程序,终端上会输出“Hello World“。在执行
eval 函数的过程中可能会有 ScriptEngine 异常抛出,引发这个异常被抛出的原因一般是由脚本输入语法有误造成的。在对整个 API 有了大致的概念之
后,我们就可以开始介绍各个具体的功能了。
使用脚本引擎运行脚本
Java 脚本 API 通过脚本引擎来运行脚本,整个包的目的就在于统一 Java 平台与各种脚本引擎的交互方式,制定一个标准,Java 应用程序依照这种标
准就能自由的调用各种脚本引擎,而脚本引擎按照这种标准实现,就能被 Java 平台支持。每一个脚本引擎就是一个脚本解释器,负责运行脚本,获取运行
结果。ScriptEngine 接口是脚本引擎在 Java 平台上的抽象,Java 应用程序通过这个接口调用脚本引擎运行脚本程序,并将运行结果返回给虚拟机。
ScriptEngine 接口提供了许多 eval 函数的变体用来运行脚本,这个函数的功能就是获取脚本输入,运行脚本,最后返回输出。清单 1 的例子中直接通过字
符串作为 eval 函数的参数读入脚本程序。除此之外,ScriptEngine 还提供了以一个 java.io.Reader 作为输入参数的 eval 函数。脚本程序实质上是一些
可以用脚本引擎执行的字节流,通过一个 Reader 对象,eval 函数就能从不同的数据源中读取字节流来运行,这个数据源可以来自内存、文件,甚至直接来自
网络。这样 Java 应用程序就能直接利用项目原有的脚本资源,无需以 Java 语言对其进行重写,达到脚本程序与 Java 平台无缝集成的目的。清单 2 即
展示了如何从一个文件中读取脚本程序并运行,其中如何通过 ScriptEngineManager 获取 ScriptEngine 实例的细节会在后面详细介绍。
清单 2. Run Script
public class RunScript { public static void main(String[] args) throws Exception { String script = args[0]; String file = args[1]; FileReader scriptReader = new FileReader(new File(file)); ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName(script); engine.eval(scriptReader); } }
清单 2 代码,从命令行分别获取脚本名称和脚本文件名,程序通过脚本名称创建对应的脚本引擎实例,通过脚本名称指定的脚本文件名读入脚本程序运行。
运行下面这个命令,就能在 Java 平台上运行所有的 JavaScript 脚本。
java RunScript javascript run.js
通过这种方式,Java 应用程序可以把一些复杂易变的逻辑过程,用更加灵活的弱类型的脚本语言来实现,然后通过 javax.Script 包提供的 API 获取运
行结果,当脚本改变时,只需替换对应的脚本文件,而无需重新编译构建项目,好处是显而易见的,即节省了开发时间又提高了开发效率。
EngineScript 接口分别针对 String 输入和 Reader 输入提供了三个不同形态的 eval 函数,用于运行脚本:
表 1. ScriptEngine 的 eval 函数
| 函数 | 描述 |
|---|---|
Object eval(Reader reader) | 从一个 Reader 读取脚本程序并运行 |
Object eval(Reader reader, Bindings n) | 以 n 作为脚本级别的绑定,从一个 Reader 读取脚本程序并运行 |
Object eval(Reader reader, ScriptContext context) | 在 context 指定的上下文环境下,从一个 Reader读取脚本程序并运行 |
Object eval(String script) | 运行字符串表示的脚本 |
Object eval(String script, Bindings n) | 以 n 作为脚本级别的绑定,运行字符串表示的脚本 |
Object eval(String script, ScriptContext context) | 在 context 指定的上下文环境下,运行字符串表示的脚本 |
Java 脚本 API 还为 ScriptEngine 接口提供了一个抽象类 —— AbstractScriptEngine,这个类提供了其中四个 eval 函数的默认实现,它们分别通过调
用 eval(Reader,ScriptContext) 或 eval(String, ScriptContext) 来实现。这样脚本引擎提供者,只需继承这个抽象类并提供这两个函数实现即可。
AbstractScriptEngine 有一个保护域 context 用于保存默认上下文的引用,SimpleScriptContext 类被作为 AbstractScriptEngine 的默认上下文。关于上
下文环境,将在后面进行详细介绍。
发现和创建脚本引擎
在前面的两个例子中,ScriptEngine 实例都是通过调用 ScriptEngineManager 实例的方法返回的,而不是常见的直接通过 new 操作新建一个实例。JSR 223
中引入 ScriptEngineManager 类的意义就在于,将 ScriptEngine 的寻找和创建任务委托给 ScriptEngineManager 实例处理,达到对 API 使用者隐藏这个
过程的目的,使 Java 应用程序在无需重新编译的情况下,支持脚本引擎的动态替换。通过 ScriptEngineManager 类和 ScriptEngineFactory 接口即可完成
脚本引擎的发现和创建:
ScriptEngineManager类:自动寻找ScriptEngineFactory接口的实现类ScriptEngineFactory接口:创建合适的脚本引擎实例
ScriptEngineManager 类本身并不知道如何创建一个具体的脚本引擎实例,它会依照 Jar 规约中定义的服务发现机制,查找并创建一个合适的
ScriptEngineFactory 实例,并通过这个工厂类来创建返回实际的脚本引擎。首先,ScriptEngineManager 实例会在当前 classpath 中搜索所有可见的 Jar 包;
然后,它会查看每个 Jar 包中的 META -INF/services/ 目录下的是否包含 javax.script.ScriptEngineFactory 文件,脚本引擎的开发者会提供在 Jar 包
中包含一个 ScriptEngineFactory 接口的实现类,这个文件内容即是这个实现类的完整名字;ScriptEngineManager 会根据这个类名,创建一个
ScriptEngineFactory 接口的实例;最后,通过这个工厂类来实例化需要的脚本引擎,返回给用户。举例来说,第三方的引擎提供者可能升级更新了新版的脚本引
擎实现,通过 ScriptEngineManager 来管理脚本引擎,无需修改一行 Java 代码就能替换更新脚本引擎。用户只需在 classpath 中加入新的脚本引擎实现
(Jar 包的形式),ScriptEngineManager 就能通过 Service Provider 机制来自动查找到新版本实现,创建并返回对应的脚本引擎实例供调用。
ScriptEngineFactory 接口的实现类被用来描述和实例化 ScriptEngine 接口,每一个实现 ScriptEngine 接口的类会有一个对应的工厂类来描述其元数据
(meta data),ScriptEngineFactory 接口定义了许多函数供 ScriptEngineManager 查询这些元数据,ScriptEngineManager 会根据这些元数据查找需要的脚本
引擎,表 2 列出了可供使用的函数:
表 2. ScriptEngineFactory 提供的查询函数
| 函数 | 描述 |
|---|---|
String getEngineName() | 返回脚本引擎的全称 |
String getEngineVersion() | 返回脚本引擎的版本信息 |
String getLanguageName() | 返回脚本引擎所支持的脚本语言的名称 |
String getLanguageVersion() | 返回脚本引擎所支持的脚本语言的版本信息 |
List<String> getExtensions() | 返回一个脚本文件扩展名组成的 List,当前脚本引擎支持解析这些扩展名对应的脚本文件 |
List<String> getMimeTypes() | 返回一个与当前引擎关联的所有 mimetype 组成的 List |
List<String> getNames() | 返回一个当前引擎所有名称的 List,ScriptEngineManager 可以根据这些名字确定对应的脚本引擎 |
通过 getEngineFactories() 函数,ScriptEngineManager 会返回一个包含当前环境中被发现的所有实现 ScriptEngineFactory 接口的具体类,通过这些工厂类
中保存的脚本引擎信息检索需要的脚本引擎。第三方提供的脚本引擎实现的 Jar 包中除了包含 ScriptEngine 接口的实现类之外,还需要提供 ScriptEngineFactory
接口的实现类,以及一个 javax.script.ScriptEngineFactory 文件用于指明这个工厂类。这样,Java 平台就能通过 ScriptEngineManager 寻找到这个工厂类,
并通过这个工厂类为用户提供一个脚本引擎实例。Java SE 6 默认提供了 JavaScirpt 脚本引擎的实现,如果需要支持其他脚本引擎,需要将它们对应的 Jar
包包含在 classpath 中,比如对于前面 清单 2 中的代码,只需在运行程序前将 Groovy 的脚本引擎添加到 classpath 中,然后运行:
java RunScript groovy run.groovy
无需修改一行 Java 代码就能以 Groovy 脚本引擎来运行 Groovy 脚本。在 这里 为 Java SE 6 提供了许多著名脚本语言的脚本引擎对 JSR 223 的支持,
这些 Jar 必须和脚本引擎配合使用,使得这些脚本语言能被 Java 平台支持。到目前为止,它提供了至少 25 种脚本语言的支持,其中包括了 Groovy、Ruby、
Python 等当前非常流行的脚本语言。这里需要再次强调的是,负责创建 ScriptEngine 实例的 ScriptEngineFactory实现类对于用户来说是不可见的,
ScriptEngingeManager 实现负责与其交互,通过它创建脚本引擎。
脚本引擎的运行上下文
如果仅仅是通过脚本引擎运行脚本的话,还无法体现出 Java 脚本 API 的优点,在 JSR 223 中,还为所有的脚本引擎定义了一个简洁的执行环境。我们都知道,
在 Linux 操作系统中可以维护许多环境变量比如 classpath、path 等,不同的 shell 在运行时可以直接使用这些环境变量,它们构成了 shell 脚本的执行
环境。在 javax.script 支持的每个脚本引擎也有各自对应的执行的环境,脚本引擎可以共享同样的环境,也可以有各自不同的上下文。通过脚本运行时的上下文,
脚本程序就能自由的和 Java 平台交互,并充分利用已有的众多 Java API,真正的站在“巨人”的肩膀上。javax.script.ScriptContext 接口和
javax.script.Bindings 接口定义了脚本引擎的上下文。
- Bindings 接口:
继承自 Map,定义了对这些“键-值”对的查询、添加、删除等 Map 典型操作。
Bingdings接口实际上是一个存放数据的容器,它的实现类会维护许多“键-值”
对,它们都通过字符串表示。Java 应用程序和脚本程序通过这些“键-值”对交换数据。只要脚本引擎支持,用户还能直接在 Bindings 中放置 Java 对象,
脚本引擎通过 Bindings 不仅可以存取对象的属性,还能调用 Java 对象的方法,这种双向自由的沟通使得二者真正的结合在了一起。
- ScriptContext 接口:
将
Bindings和ScriptEngine联系在了一起,每一个ScriptEngine都有一个对应的ScriptContext,前面提到过通过ScriptEnginFactory创建脚本引擎
除了达到隐藏实现的目的外,还负责为脚本引擎设置合适的上下文。ScriptEngine 通过 ScriptContext 实例就能从其内部的 Bindings 中获得需要的属性值。
ScriptContext 接口默认包含了两个级别的 Bindings 实例的引用,分别是全局级别和引擎级别,可以通过 GLOBAL_SCOPE 和 ENGINE_SCOPE 这两个类常量来界定区
分这两个 Bindings 实例,其中 GLOBAL_SCOPE 从创建它的 ScriptEngineManager 获得。顾名思义,全局级别指的是 Bindings 里的属性都是“全局变量”,只要是同
一个 ScriptEngineMananger 返回的脚本引擎都可以共享这些属性;对应的,引擎级别的 Bindings 里的属性则是“局部变量”,它们只对同一个引擎实例可见,从而能
为不同的引擎设置独特的环境,通过同一个脚本引擎运行的脚本运行时能共享这些属性。
ScriptContext 接口定义了下面这些函数来存取数据:
表 3. ScriptContext 存取属性函数
| 函数 | 描述 |
|---|---|
Object removeAttribute(String name, int scope) | 从指定的范围里删除一个属性 |
void setAttribute(String name, Object value, int scope) | 在指定的范围里设置一个属性的值 |
Object getAttribute(String name) | 从上下文的所有范围内获取优先级最高的属性的值 |
Object getAttribute(String name, int scope) | 从指定的范围里获取属性值 |
ScriptEngineManager 拥有一个全局性的 Bindings 实例,在通过 ScriptEngineFactory 实例创建 ScriptEngine 后,它把自己的这个 Bindings 传递给所有它创
建的 ScriptEngine 实例,作为 GLOBAL_SCOPE。同时,每一个 ScriptEngine 实例都对应一个 ScriptContext 实例,这个 ScriptContext 除了从
ScriptEngineManager 那获得的 GLOBAL_SCOPE,自己也维护一个 ENGINE_SCOPE 的 Bindings 实例,所有通过这个脚本引擎运行的脚本,都能存取其中的属性。除了
ScriptContext 可以设置属性,改变内部的 Bindings,Java 脚本 API 为 ScriptEngineManager 和 ScriptEngine 也提供了类似的设置属性和 Bindings的
API。
从 图 3 中可以看到,共有三个级别的地方可以存取属性,分别是 ScriptEngineManager 中的 Bindings,ScriptEngine 实例对应的 ScriptContext 中含有的
Bindings,以及调用 eval 函数时传入的 Bingdings。离函数调用越近,其作用域越小,优先级越高,相当于编程语言中的变量的可见域,即
Object getAttribute(String name) 中提到的优先级。从 清单 3 这个例子中可以看出各个属性的存取优先级:
清单 3. 上下文属性的作用域
import javax.script.*; public class ScopeTest { public static void main(String[] args) throws Exception { String script=" println(greeting) "; ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("javascript"); //Attribute from ScriptEngineManager manager.put("greeting", "Hello from ScriptEngineManager"); engine.eval(script); //Attribute from ScriptEngine engine.put("greeting", "Hello from ScriptEngine"); engine.eval(script); //Attribute from eval method ScriptContext context = new SimpleScriptContext(); context.setAttribute("greeting", "Hello from eval method",ScriptContext.ENGINE_SCOPE); engine.eval(script,context); } }
JavaScript 脚本 println(greeting) 在这个程序中被重复调用了三次,由于三次调用的环境不一样,导致输出也不一样,greeting 变量每一次都被优先级
更高的也就是距离函数调用越近的值覆盖。从这个例子同时也演示了如何使用 ScriptContext 和 Bindings 这两个接口,在例子脚本中并没有定义 greeting
这个变量,但是脚本通过 Java 脚本 API 能方便的存取 Java 应用程序中的对象,输出 greeting 相应的值。运行这个程序后,能看到输出为:
除了能在 Java 平台与脚本程序之间的提供共享属性之外,ScriptContext 还允许用户重定向引擎执行时的输入输出流:
表 4. ScriptContext 输入输出重定向
| 函数 | 描述 |
|---|---|
void setErrorWriter(Writer writer) | 重定向错误输出,默认是标准错误输出 |
void setReader(Reader reader) | 重定向输入,默认是标准输入 |
void setWriter(Writer writer) | 重定向输出,默认是标准输出 |
Writer getErrorWriter() | 获取当前错误输出字节流 |
Reader getReader() | 获取当前输入流 |
Writer getWriter() | 获取当前输出流 |
清单 4 展示了如何通过 ScriptContext 将其对应的 ScriptEngine 标准输出重定向到一个 PrintWriter 中,用户可以通过与这个 PrintWriter 连通的
PrintReader 读取实际的输出,使 Java 应用程序能获取脚本运行输出,满足更加多样的应用需求。
清单 4. 重定向脚本输出
import java.io.*; import javax.script.*; public class Redirectory { public static void main(String[] args) throws Exception { ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("javascript"); PipedReader pr = new PipedReader(); PipedWriter pw = new PipedWriter(pr); PrintWriter writer = new PrintWriter(pw); engine.getContext().setWriter(writer); String script = "println('Hello from JavaScript')"; engine.eval(script); BufferedReader br =new BufferedReader(pr); System.out.println(br.readLine()); } }
Java 脚本 API 分别为这两个接口提供了一个简单的实现供用户使用。SimpleBindings 通过组合模式实现 Map 接口,它提供了两个构造函数。无参构造函数在内部
构造一个 HashMap 实例来实现 Map 接口要求的功能;同时,SimpleBindings 也提供了一个以 Map 接口作为参数的构造函数,允许任何实现 Map 接口的类
作为其组合的实例,以满足不同的要求。SimpleScriptContext 提供了 ScriptContext 简单实现。默认情况下,它使用了标准输入、标准输出和标准错误输出,
同时维护一个 SimpleBindings 作为其引擎级别的 Bindings,它的默认全局级别 Bindings 为空。
脚本引擎可选的接口
在 Java 脚本 API 中还有两个脚本引擎可以选择是否实现的接口,这个两个接口不是强制要求实现的,即并非所有的脚本引擎都能支持这两个函数,不过
Java SE 6 自带的 JavaScript 引擎支持这两个接口。无论如何,这两个接口提供了非常实用的功能,它们分别是:
- Invocable 接口:允许 Java 平台调用脚本程序中的函数或方法。
- Compilable 接口:允许 Java 平台编译脚本程序,供多次调用。
Invocable 接口
有时候,用户可能并不需要运行已有的整个脚本程序,而仅仅需要调用其中的一个过程,或者其中某个对象的方法,这个时候 Invocable 接口就能发挥作用。它提
供了两个函数 invokeFunction 和 invokeMethod,分别允许 Java 应用程序直接调用脚本中的一个全局性的过程以及对象中的方法,调用后者时,除了指定函数名
字和参数外,还需要传入要调用的对象引用,当然这需要脚本引擎的支持。不仅如此,Invocable 接口还允许 Java 应用程序从这些函数中直接返回一个接口,通
过这个接口实例来调用脚本中的函数或方法,从而我们可以从脚本中动态的生成 Java 应用中需要的接口对象。清单 5 演示了如何使用一个 Invocable 接口:
清单 5. 调用脚本中的函数
import javax.script.*; public class CompilableTest { public static void main(String[] args) throws ScriptException, NoSuchMethodException { String script = " function greeting(message){println (message);}"; ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("javascript"); engine.eval(script); if (engine instanceof Invocable) { Invocable invocable = (Invocable) engine; invocable.invokeFunction("greeting", "hi"); // It may through NoSuchMethodException try { invocable.invokeFunction("nogreeing"); } catch (NoSuchMethodException e) { // expected } } } }
在调用函数前,可以先通过 instanceof 操作判断脚本引擎是否支持编译操作,防止类型转换时抛出运行时异常,需要特别注意的时,如果调用了脚本程序中
不存在的函数时,运行时会抛出一个 NoSuchMethodException 的异常,实际开发中应该注意处理这种特殊情况。
Compilable 接口
一般来说,脚本语言都是解释型的,这也是脚本语言区别与编译语言的一个特点,解释性意味着脚本随时可以被运行,开发者可以边开发边查看接口,从而省去
了编译这个环节,提供了开发效率。但是这也是一把双刃剑,当脚本规模变大,重复解释一段稳定的代码又会带来运行时的开销。有些脚本引擎支持将脚本运行
编译成某种中间形式,这取决与脚本语言的性质以及脚本引擎的实现,可以是一些操作码,甚至是 Java 字节码文件。实现了这个接口的脚本引擎能把输入的
脚本预编译并缓存,从而提高多次运行相同脚本的效率。
Java 脚本 API 还为这个中间形式提供了一个专门的类,每次调用 Compilable 接口的编译函数都会返回一个 CompiledScript 实例。CompiledScript 类被用
来保存编译的结果,从而能重复调用脚本而没有重复解释的开销,实际效率提高的多少取决于中间形式的彻底程度,其中间形式越接近低级语言,提高的效率就越
高。每一个 CompiledScript 实例对应于一个脚本引擎实例,一个脚本引擎实例可以含有多个 CompiledScript(这很容易理解),调用 CompiledScript 的 eval
函数会传递给这个关联的 ScriptEngine 的 eval 函数。关于 CompiledScript 类需要注意的是,它运行时对与之对应的 ScriptEngine 状态的改变可能会
传递给下一次调用,造成运行结果的不一致。清单 6 演示了如何使用 Compiable 接口来调用脚本:
清单 6. 编译脚本
import javax.script.*; public class CompilableTest { public static void main(String[] args) throws ScriptException { String script = " println (greeting); greeting= 'Good Afternoon!' "; ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("javascript"); engine.put("greeting", "Good Morning!"); if (engine instanceof Compilable) { Compilable compilable = (Compilable) engine; CompiledScript compiledScript = compilable.compile(script); compiledScript.eval(); compiledScript.eval(); } } }
与 InovcableTest 类似,也应该先通过 instanceof 操作判断脚本引擎是否支持编译操作,防止预料外的异常抛出。并且我们可以发现同一段编译过的脚本,
在第二次运行时 greeting 变量的内容被上一次的运行改变了,导致输出不一致:
jrunscript 工具
Java SE 6 还为运行脚本添加了一个专门的工具 —— jrunscript。jrunscript 支持两种运行方式:一种是交互式,即边读取边解析运行,这种方式使得用
户可以方便调试脚本程序,马上获取预期结果;还有一种就是批处理式,即读取并运行整个脚本文件。用户可以把它想象成一个万能脚本解释器,即它可以运行任
意脚本程序,而且它还是跨平台的,当然所有这一切都有一个前提,那就是必须告诉它相应的脚本引擎的位置。默认即支持的脚本是 JavaScript,这意味着用
户可以无需任何设置,通过 jrunscript 在任何支持 Java 的平台上运行任何 JavaScript 脚本;如果想运行其他脚本,可以通过 -l 指定以何种脚本引擎
运行脚本。不过这个工具仍是实验性质的,不一定会包含在 Java 的后续版本中,无论如何,它仍是一个非常有用的工具。
结束语
在 Java 平台上使用脚本语言编程非常方便,因为 Java 脚本 API 相对其他包要小很多。通过 javax.script包提供的接口和类我们可以很方便为我们的 Java
应用程序添加对脚本语言的支持。开发者只要遵照 Java 脚本 API 开发应用程序,开发中就无需关注具体的脚本语言细节,应用程序就可以动态支持任何符合
JSR 223 标准的脚本语言,不仅如此,只要按照 JSR 223 标准开发,用户甚至还能为 Java 平台提供一个自定义脚本语言的解释器。在 Java 平台上运行自己
的脚本语言,这对于众多开发者来说都是非常有诱惑力的。


