
- 1搭建FISCO BCOS区块链平台_第1题:基于提供的开发环境,使用离线安装包搭建区块链网络平台,含 fisco bcos 区
- 2Text to Image综述阅读(1.1):介绍与基本原理 Adversarial Text-to-Image Synthesis: A Review(基于GAN的文本生成图像)_text to image 原理
- 3DRL(自用)_基于模型的 drl 算法
- 4鸿蒙开发3-1 基本组件+通用属性+通用事件_鸿蒙系统通过实现图片、按钮、输入框、滑动条之间进行连接,实现互相影响
- 5子查询
- 6git推送本地分支到远程分支
- 7打死都不要进外包,看看我在阿里外包的2年...
- 8FPGA之道(24)VHDL数据类型
- 9SQLite数据库的性能问题并不是单纯地由数据量的大小决定的,而是受到多种因素的综合影响。以下是一些可能导致SQLite性能问题的因素_sqllite 性能
- 10找工作,内推完胜自己投简历吗?
基于hadoop的邮政数据分析系统 毕业设计 附源码46670_邮局系统源码
赞
踩
Hadoop 基于hadoop的邮政数据分析系统
摘要
为促进邮政业务的发展,充分、合理、高效的使用邮政的各类资源,有效的开展邮政数据分析系统,指导本省业务、管理及营销工作,邮政将邮政业务、速递物流业务、金融业务的数据进行整合,通过利用计算机网络、大型数据库等先进技术建立了邮政数据分析系统,实现了对邮政资源的统一管理和对业务数据的全方位多角度分析;同时通过对邮政资源的整体综合管理,为各项资源的优化和整合提供依据。
关键词:邮政数据分析系统 python MySQL
Abstract
In order to promote the development of postal services, fully, reasonably, and efficiently utilize various postal resources, effectively carry out postal data analysis, and guide the business, management, and marketing work of the province, postal services have integrated data from postal services, express logistics services, and financial services, and established a postal data analysis system through the use of advanced technologies such as computer networks and large databases, Realized unified management of postal resources and comprehensive and multi-dimensional analysis of business data; At the same time, through the overall comprehensive management of postal resources, it provides a basis for the optimization and integration of various resources.
Keywords: Postal Data Analysis System Python MySQL
目 录
1.1系统的建设背景
随着中国邮政改革的继续深化,2010 年邮务、速递物流和金融保险三大板块各项业务蓬勃发展,取得了可喜的成绩。今年是“十二五”规划的开局之年,在新形势、新局面下,传统邮政、速递物流、金融三大板块板块内的整合、板块间的融合趋势愈来愈突显。
经过10多年的邮政信息化建设,中国邮政已经积累了覆盖三大板块的各类海量生产经营数据。同时,名址、量收、速递平台和金融客管等数据仓库系统的建设也为板块之间的数据融合和数据分析工作打下了坚实的基础。
为了不断满足板块内各业务系统间对于数据融合的需要,满足省内对经营管理方面的个性化需求,以及满足板块内各业务间对于数据整合的需求等各层面的需求,实现数据的充分共享和集中处理、应用和发布,有必要进一步实现数据的整合,为深入开展数据分析,促进和引领邮政企业协同发展奠定基础。
1.2 系统的建设目标
整合邮政三大板块业务数据及相关资源,通过统一的数据分析平台进行数据展现及管理。满足邮政经营管理、业务、营销等各种角色、各种层次人员对数据多角度的需求。
通过数据分析平台将业务需求固化成应用,方便业务部门随时使用。
实现了数据分析方法和模型的快捷复制。
提供任意条件组合统计分析功能,方便业务人员探索分析需求。支持二次开发功能,实现一般技术人员与原始数据的安全隔离。
支持数据分析模型、工具的嵌入功能,业务人员和一般技术人员可直接通过系统使用模型和工具进行复杂分析。
在数据管理方面,实现时间、机构、业务指标、客户等多维度的数据分析和应用。
1.3Hadoop框架介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
1.4B/S体系工作原理
B/S架构采取浏览器请求,服务器响应的工作模式。
用户可以通过浏览器去访问Internet上由Web服务器产生的文本、数据、图片、动画、视频点播和声音等信息;
而每一个Web服务器又可以通过各种方式与数据库服务器连接,大量的数据实际存放在数据库服务器中;
从Web服务器上下载程序到本地来执行,在下载过程中若遇到与数据库有关的指令,由Web服务器交给数据库服务器来解释执行,并返回给Web服务器,Web服务器又返回给用户。在这种结构中,将许许多多的网连接到一块,形成一个巨大的网,即全球网。而各个企业可以在此结构的基础上建立自己的Internet。
在 B/S 模式中,用户是通过浏览器针对许多分布于网络上的服务器进行请求访问的,浏览器的请求通过服务器进行处理,并将处理结果以及相应的信息返回给浏览器,其他的数据加工、请求全部都是由Web Server完成的。通过该框架结构以及植入于操作系统内部的浏览器,该结构已经成为了当今软件应用的主流结构模式。

Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理 PB 级数据。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中 。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++ 。
Hadoop大数据处理的意义
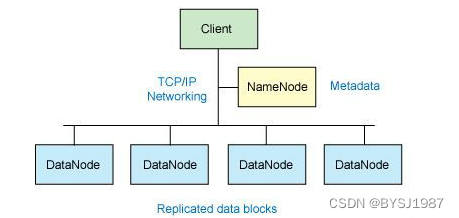
Hadoop架构图
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
1.6爬虫技术
网络为搜索引擎从万维网下载网页。一般分为传统爬虫和聚焦爬虫。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。通俗的讲,也就是通过源码解析来获得想要的内容。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
2 邮政数据分析系统的需求分析
邮政数据分析系统在数据的存储上使用的MYSQL数据库,在邮政数据分析系统开发中使用了了pycharm、Vs Code、HbuildX这些开发工具的使用,能够给我们的编写工作带来许多的便利。系统使用B/S模式进行开发,使系统的可扩展性和维护性更佳,减少系统配置代码,简化编程代码,目前B/S模式是目前最受欢迎的一种模式。
在开发邮政数据分析系统中所使用的开发软件像pycharm开发工具、tomcat服务器、Hadoop开发框架、MySQL5.7数据库、Photoshop图片处理软件等,这些环境从网上就能免费下载,而且网上都有安装的教程,根据教程一步一步的操作,就可以安装成功,不需要花任何费用,并且邮政数据分析系统是自己设计并编码实现的,数据库是使用流行mysql进行数据的存储,开源的mysql等技术的使用,减少系统开发费用。
2.1.3操作可行性分析
此次项目设计的时候我参考了很多类似系统的成功案例,对它们的操作界面以及功能都进行了系统的分析,将众多案例结合在一起,突出以人为本简化操作,所以具有基本计算机知识的人都会操作本项目。因此操作可行性也没有问题。
业务流程是用一些特定的符合和线条来进行演示用户在使用系统时的过程,在进行系统分析的时候,业务流程可以帮助开发人员更好的理解业务,发现错误,完善系统。
用户成功登入系统后就能够实现增加数据的操作,增加数据的编号是特定的,系统生成,用户不能随意填写,除了编号以外,其他增加信息用户自己填写,填写后的信息经过系统验证,验证合法通过就显示增加数据成功了,相反的话,就没有增加成功,图2-1显示的就是在增加数据时的流程。
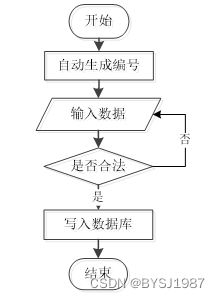
图2-1 数据增加流程图
数据修改时的流程和上面介绍的数据增加时的流程差不多,如图2-2所示。

图2-2 数据修改流程图
如果系统里面存在一些没有用的数据的话,相关的管理人员还可以对这些数据进行删除,图2-3就是数据删除时的流程图。
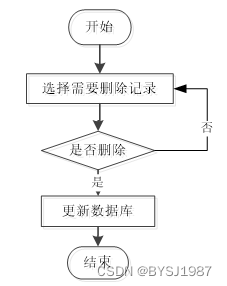
图2-3 数据删除流程图
邮政数据分析系统划分为了管理员模块这一大部分。
管理员:
(1)登录:管理员在后台可以通过账号和密码进行登录,管理员的账号和密码是在数据库中直接设定的,如果忘记密码可以点击“忘记密码”进行密码找回;
(2)个人信息:管理员点击“个人信息”按钮,可以对个人的头像、昵称、手机号码等信息进行更新。
(3)修改密码:管理员点击“修改密码”按钮,可以对登录密码进行更改,首先输入原密码,然后再输入新密码和确认密码,当原密码正确,输入两次新密码一致,则修改成功,否则给出错误提示信息。
(4)系统用户:管理员点击“系统用户”这一菜单会显示管理员这个子菜单,管理员可以对这一个角色的信息进行增删改查操作;
(5)当前物流:管理员点击“当前物流”会显示出所有的当前物流信息,支持通过物流状态或者输入物流数量对当前物流信息进行查询,如果想要添加新的当前物流信息,点击“添加”按钮,输入相关信息,点击“提交”按钮就可以添加了,同时可以选择某一条当前物流信息,点击“删除”进行删除。
(6)每日揽件:管理员点击“每日揽件”会显示出所有的每日揽件信息,支持通过状态名称或者记录日期对每日揽件信息进行查询,如果想要添加新的每日揽件信息,点击“添加”按钮,输入相关信息,点击“提交”按钮就可以添加了,同时可以选择某一条每日揽件信息,点击“删除”进行删除。
(7)每日派送:管理员点击“每日派送”会显示出所有的每日派送信息,支持通过状态名称或者记录日期对每日派送信息进行查询,如果想要添加新的每日派送信息,点击“添加”按钮,输入相关信息,点击“提交”按钮就可以添加了,同时可以选择某一条每日派送信息,点击“删除”进行删除。
2.3.2非功能性需求分析
邮政数据分析系统的非功能性需求比如邮政数据分析系统的安全性怎么样,可靠性怎么样,性能怎么样,可拓展性怎么样等。具体可以表示在如下2.1表格中:
表2.1 邮政数据分析系统非功能需求表
| 安全性 | 主要指邮政数据分析系统数据库的安装,数据库的使用和密码的设定必须合乎规范。 |
| 可靠性 | 可靠性是指邮政数据分析系统能够安装用户的指示进行操作,经过测试,可靠性90%以上。 |
| 性能 | 性能是影响邮政数据分析系统占据市场的必要条件,所以性能最好要佳才好。 |
| 可扩展性 | 比如数据库预留多个属性,比如接口的使用等确保了系统的非功能性需求。 |
| 易用性 | 用户只要跟着邮政数据分析系统的页面展示内容进行操作,就可以了。 |
| 可维护性 | 邮政数据分析系统开发的可维护性是非常重要的,经过测试,可维护性没有问题 |
邮政数据分析系统中管理员角色用例图如图2.1所示:
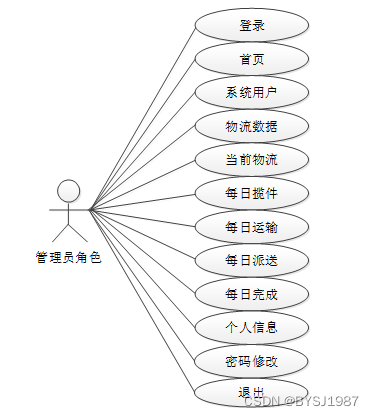
图2.1管理员角色用例图
本章主要讨论的内容包括邮政数据分析系统的功能模块设计、数据库系统设计。
3.1 系统架构设计
本邮政数据分析系统从架构上分为三层:表现层(UI)、业务逻辑层(BLL)以及数据层(DL)。
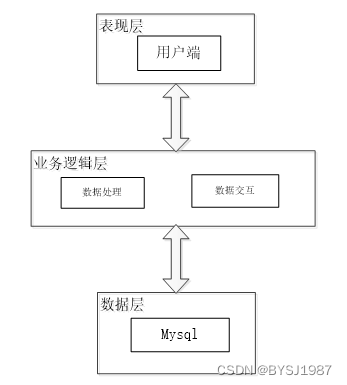
图3-1邮政数据分析系统架构设计图
表现层(UI):又称UI层,主要完成本邮政数据分析系统的UI交互功能,一个良好的UI可以打打提高用户的用户体验,增强用户使用本邮政数据分析系统时的舒适度。UI的界面设计也要适应不同版本的邮政数据分析系统以及不同尺寸的分辨率,以做到良好的兼容性。UI交互功能要求合理,用户进行交互操作时必须要得到与之相符的交互结果,这就要求表现层要与业务逻辑层进行良好的对接。
业务逻辑层(BLL):主要完成本邮政数据分析系统的数据处理功能。用户从表现层传输过来的数据经过业务逻辑层进行处理交付给数据层,系统从数据层读取的数据经过业务逻辑层进行处理交付给表现层。
数据层(DL):由于本邮政数据分析系统的数据是放在服务端的mysql数据库中,因此本属于服务层的部分可以直接整合在业务逻辑层中,所以数据层中只有数据库,其主要完成本邮政数据分析系统的数据存储和管理功能。
3.2系统顺序图设计
3.2.1登录模块顺序图
登录模块主要满足了管理员以及用户的权限登录,登录模块顺序图如图3-2所示。
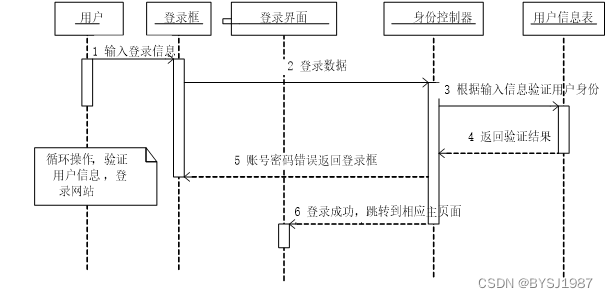
图3.2登录顺序图
管理员以及用户登录后均可进行添加信息操作,添加信息模块顺序图如图4-4所示。
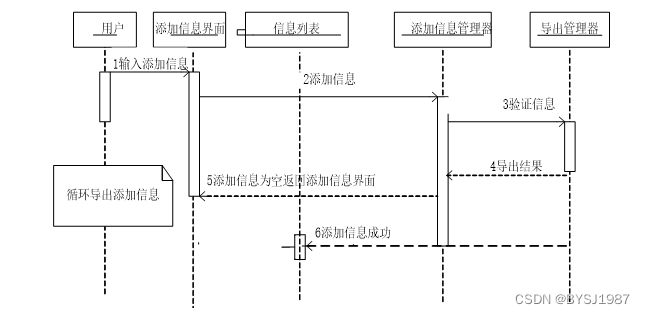
图3.3 添加信息顺序图
3.3系统功能模块设计
邮政数据分析系统整体的功能模块包括管理员这个模块,实现了对邮政数据相关信息的查询管理,系统功能模块如图所示。
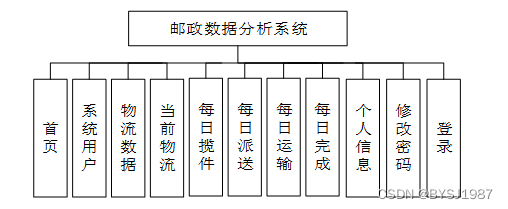
图3.4邮政数据分析系统功能模块图
3.4数据库设计
数据库设计一般包括需求分析、概念模型设计、数据库表建立三大过程,其中需求分析前面章节已经阐述,概念模型设计有概念模型和逻辑结构设计两部分。
3.4.1 数据库概念结构设计
下面是整个邮政数据分析系统中主要的数据库表总E-R实体关系图。
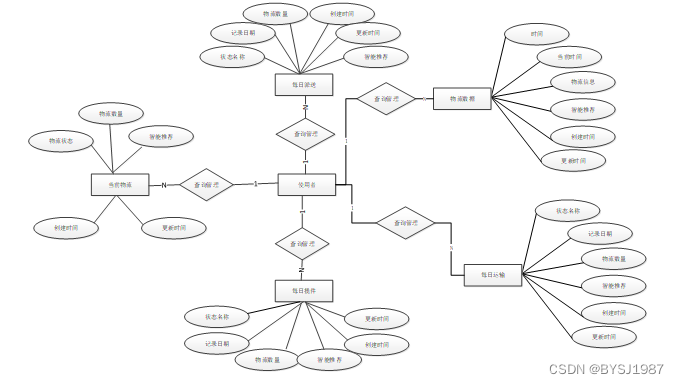
图3-3 邮政数据分析系统总E-R关系图
通过上一小节中邮政数据分析系统中总E-R关系图上得出一共需要创建很多个数据表。在此我主要罗列几个主要的数据库表结构设计。
表access_token (登陆访问时长)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | token_id | int | 10 | 0 | N | Y | 临时访问牌ID | |
| 2 | token | varchar | 64 | 0 | Y | N | 临时访问牌 | |
| 3 | info | text | 65535 | 0 | Y | N | ||
| 4 | maxage | int | 10 | 0 | N | N | 2 | 最大寿命:默认2小时 |
| 5 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 6 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 7 | user_id | int | 10 | 0 | N | N | 0 | 用户编号: |
表auth (用户权限管理)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | auth_id | int | 10 | 0 | N | Y | 授权ID: | |
| 2 | user_group | varchar | 64 | 0 | Y | N | 用户组: | |
| 3 | mod_name | varchar | 64 | 0 | Y | N | 模块名: | |
| 4 | table_name | varchar | 64 | 0 | Y | N | 表名: | |
| 5 | page_title | varchar | 255 | 0 | Y | N | 页面标题: | |
| 6 | path | varchar | 255 | 0 | Y | N | 路由路径: | |
| 7 | position | varchar | 32 | 0 | Y | N | 位置: | |
| 8 | mode | varchar | 32 | 0 | N | N | _blank | 跳转方式: |
| 9 | add | tinyint | 3 | 0 | N | N | 1 | 是否可增加: |
| 10 | del | tinyint | 3 | 0 | N | N | 1 | 是否可删除: |
| 11 | set | tinyint | 3 | 0 | N | N | 1 | 是否可修改: |
| 12 | get | tinyint | 3 | 0 | N | N | 1 | 是否可查看: |
| 13 | field_add | text | 65535 | 0 | Y | N | 添加字段: | |
| 14 | field_set | text | 65535 | 0 | Y | N | 修改字段: | |
| 15 | field_get | text | 65535 | 0 | Y | N | 查询字段: | |
| 16 | table_nav_name | varchar | 500 | 0 | Y | N | 跨表导航名称: | |
| 17 | table_nav | varchar | 500 | 0 | Y | N | 跨表导航: | |
| 18 | option | text | 65535 | 0 | Y | N | 配置: | |
| 19 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 20 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
表current_logistics (当前物流)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | current_logistics_id | int | 10 | 0 | N | Y | 当前物流ID | |
| 2 | logistics_status | varchar | 64 | 0 | Y | N | 物流状态 | |
| 3 | logistics_quantity | int | 10 | 0 | Y | N | 0 | 物流数量 |
| 4 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 5 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 6 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表daily_completion (每日完成)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | daily_completion_id | int | 10 | 0 | N | Y | 每日完成ID | |
| 2 | status_name | varchar | 64 | 0 | Y | N | 状态名称 | |
| 3 | record_date | date | 10 | 0 | Y | N | 记录日期 | |
| 4 | logistics_quantity | int | 10 | 0 | Y | N | 0 | 物流数量 |
| 5 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 6 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 7 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表daily_delivery (每日派送)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | daily_delivery_id | int | 10 | 0 | N | Y | 每日派送ID | |
| 2 | status_name | varchar | 64 | 0 | Y | N | 状态名称 | |
| 3 | record_date | date | 10 | 0 | Y | N | 记录日期 | |
| 4 | logistics_quantity | int | 10 | 0 | Y | N | 0 | 物流数量 |
| 5 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 6 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 7 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表daily_pickup (每日揽件)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | daily_pickup_id | int | 10 | 0 | N | Y | 每日揽件ID | |
| 2 | status_name | varchar | 64 | 0 | Y | N | 状态名称 | |
| 3 | record_date | date | 10 | 0 | Y | N | 记录日期 | |
| 4 | logistics_quantity | int | 10 | 0 | Y | N | 0 | 物流数量 |
| 5 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 6 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 7 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表daily_transportation (每日运输)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | daily_transportation_id | int | 10 | 0 | N | Y | 每日运输ID | |
| 2 | status_name | varchar | 64 | 0 | Y | N | 状态名称 | |
| 3 | record_date | date | 10 | 0 | Y | N | 记录日期 | |
| 4 | logistics_quantity | int | 10 | 0 | Y | N | 0 | 物流数量 |
| 5 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 6 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 7 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表hits (用户点击)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | hits_id | int | 10 | 0 | N | Y | 点赞ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 点赞人: |
| 3 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 4 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
表logistics_data (物流数据)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | logistics_data_id | int | 10 | 0 | N | Y | 物流数据ID | |
| 2 | time | varchar | 64 | 0 | Y | N | 时间 | |
| 3 | current_time | varchar | 64 | 0 | Y | N | 当前时间 | |
| 4 | logistics_information | text | 65535 | 0 | Y | N | 物流信息 | |
| 5 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 6 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 7 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表upload (文件上传)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | upload_id | int | 10 | 0 | N | Y | 上传ID | |
| 2 | name | varchar | 64 | 0 | Y | N | 文件名 | |
| 3 | path | varchar | 255 | 0 | Y | N | 访问路径 | |
| 4 | file | varchar | 255 | 0 | Y | N | 文件路径 | |
| 5 | display | varchar | 255 | 0 | Y | N | 显示顺序 | |
| 6 | father_id | int | 10 | 0 | Y | N | 0 | 父级ID |
| 7 | dir | varchar | 255 | 0 | Y | N | 文件夹 | |
| 8 | type | varchar | 32 | 0 | Y | N | 文件类型 |
表user (用户账户:用于保存用户登录信息)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | user_id | mediumint | 8 | 0 | N | Y | 用户ID:[0,8388607]用户获取其他与用户相关的数据 | |
| 2 | state | smallint | 5 | 0 | N | N | 1 | 账户状态:[0,10](1可用|2异常|3已冻结|4已注销) |
| 3 | user_group | varchar | 32 | 0 | Y | N | 所在用户组:[0,32767]决定用户身份和权限 | |
| 4 | login_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 上次登录时间: |
| 5 | phone | varchar | 11 | 0 | Y | N | 手机号码:[0,11]用户的手机号码,用于找回密码时或登录时 | |
| 6 | phone_state | smallint | 5 | 0 | N | N | 0 | 手机认证:[0,1](0未认证|1审核中|2已认证) |
| 7 | username | varchar | 16 | 0 | N | N | 用户名:[0,16]用户登录时所用的账户名称 | |
| 8 | nickname | varchar | 16 | 0 | Y | N | 昵称:[0,16] | |
| 9 | password | varchar | 64 | 0 | N | N | 密码:[0,32]用户登录所需的密码,由6-16位数字或英文组成 | |
| 10 | | varchar | 64 | 0 | Y | N | 邮箱:[0,64]用户的邮箱,用于找回密码时或登录时 | |
| 11 | email_state | smallint | 5 | 0 | N | N | 0 | 邮箱认证:[0,1](0未认证|1审核中|2已认证) |
| 12 | avatar | varchar | 255 | 0 | Y | N | 头像地址:[0,255] | |
| 13 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
表user_group (用户组:用于用户前端身份和鉴权)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | group_id | mediumint | 8 | 0 | N | Y | 用户组ID:[0,8388607] | |
| 2 | display | smallint | 5 | 0 | N | N | 100 | 显示顺序:[0,1000] |
| 3 | name | varchar | 16 | 0 | N | N | 名称:[0,16] | |
| 4 | description | varchar | 255 | 0 | Y | N | 描述:[0,255]描述该用户组的特点或权限范围 | |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 8 | register | smallint | 5 | 0 | Y | N | 0 | 注册位置: |
| 9 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 10 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
4 系统的实现
4.1登录模块
管理员在登录界面输入账号+密码,点击“登录”按钮,系统在用户数据库表中会对管理员、教师和学生的账号进行匹配,账号+密码正确的话,就会登录到系统中各个用户的主管理界面,否则提示对应的信息,返回到登录的界面,其主界面展示如下图4.1所示。

图4.1 登录界面图
4.2系统用户管理模块
管理员可以对系统中所有的用户角色进行管控,包含了管理员这一种角色,如果需要添加新的用户,点击页面中的“添加”按钮根据提示输入上用户信息,点击“提交”以后在对应的用户界面就可以查看到了,可以点击用户后面的“删除”按钮直接删除某一用户,这里以管理员用户为例。界面如下图4.2所示。

图4.2 系统用户管理模块图
4.3当前物流模块
管理员点击“当前物流”这个按钮可以查看到系统中的当前物流信息,支持通过物流状态或者物流数量进行查询当前物流信息,如果想要添加新的当前物流信息,点击“添加”按钮然后根据提示输入当前物流信息,点击“提交”后,在当前物流界面就会显示新增的当前物流信息,可以点击某一当前物流信息查看当前物流信息的详情,也可以直接点击“删除”进行删除当前物流。界面如下图4.3所示。
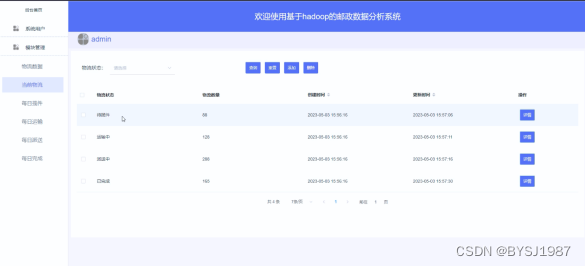
图4.3当前物流界面图
4.4每日揽件模块
管理员点击“每日揽件”这个按钮可以查看到系统中的每日揽件信息,支持通过状态名称或者记录日期进行查询每日揽件信息,如果想要添加新的每日揽件信息,点击“添加”按钮然后根据提示输入每日揽件信息,点击“提交”后,在每日揽件界面就会显示新增的每日揽件信息,可以点击某一每日揽件信息查看每日揽件信息的详情,也可以直接点击“删除”进行删除每日揽件。界面如下图4.4所示。

图4.4 每日揽件界面图
4.5echars技术
ECharts是一款基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。ECharts最初由百度团队开源,并于2018年初捐赠给Apache基金会,成为ASF孵化级项目。
2021年1月26日晚,Apache基金会官方宣布ECharts项目正式毕业。1月28日,ECharts 5线上发布会举行。界面如下图4.5所示。
图4.5 echars技术
4.6每日派送模块
管理员点击“每日派送”这个按钮可以查看到系统中的每日派送信息,支持通过状态名称或者记录日期进行查询每日派送信息,如果想要添加新的每日派送信息,点击“添加”按钮然后根据提示输入每日派送信息,点击“提交”后,在每日派送界面就会显示新增的每日派送信息,可以点击某一每日派送信息查看每日派送信息的详情,也可以直接点击“删除”进行删除每日派送。界面如下图4.6所示。
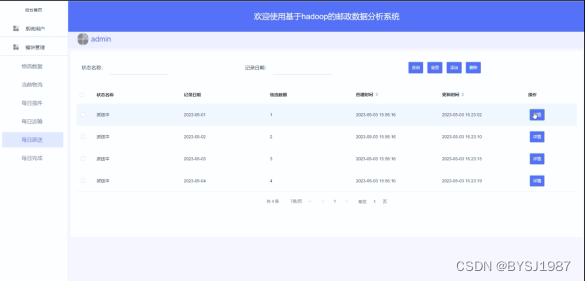
图4.6 每日派送界面图
4.7每日完成模块
管理员点击“每日完成”这个按钮可以查看到系统中的每日完成信息,支持通过状态名称或者记录日期或者物流数量进行查询每日完成信息,如果想要添加新的每日完成信息,点击“添加”按钮然后根据提示输入每日完成信息,点击“提交”后,在每日完成界面就会显示新增的每日完成信息,可以点击某一每日完成信息查看每日完成信息的详情,也可以直接点击“删除”进行删除每日完成。界面如下图4.7所示。
图4.7 每日完成界面图
5 系统测试与结果分析
系统开发到了最后一个阶段那就是系统测试,系统测试对软件的开发其实是非常有必要的。因为没什么系统一经开发出来就可能会尽善尽美,再厉害的系统开发工程师也会在系统开发的时候出现纰漏,系统测试能够较好的改正一些bug,为后期系统的维护性提供很好的支持。通过系统测试,开发人员也可以建立自己对系统的信心,为后期的系统版本的跟新提供支持。
表5.1 用户登录功能测试表
| 测试名称 | 测试功能 | 操作过程 | 预期结果 | 测试结果 |
| 用户登录模块测试 | 用户登录成功的情况 | 点击前登录界面输入账号和密码分别输入admin和admin后点击“登录”按钮。 | 登录成功并调整到用户界面 | 正确 |
物流数据信息添加功能测试:
表5.2 物流数据信息添加功能测试表
| 测试名称 | 测试功能 | 操作过程 | 预期结果 | 测试结果 |
| 物流数据添加模块测试 | 物流数据添加成功的情况 | 在物流数据的页面中将点击添加,输入物流数据相关信息,输入正确的信息后然后点击“提交”按钮。 | 提示添加成功 | 正确 |
| 物流数据添加模块测试 | 物流数据添加失败的情况 | 在物流数据页面中不填写的时间、当前时间、物流信息,其他信息正常输入“提交”按钮。 | 提示“添加失败,信息不能为空” | 正确 |
查询每日运输信息功能模块测试:
表5.3 查询每日运输信息功能测试表
| 测试名称 | 测试功能 | 操作过程 | 预期结果 | 测试结果 |
| 查询每日运输信息功能测试 | 查询成功的情况 | 在每日运输界面输入状态名称或者物流数量进行查询 | 查询成功 | 正确 |
每日揽件信息添加功能测试:
表5.4 每日揽件添加功能测试表
| 测试名称 | 测试功能 | 操作过程 | 预期结果 | 测试结果 |
| 每日揽件添加模块测试 | 每日揽件添加成功的情况 | 在每日揽件的页面中将点击添加,输入每日揽件相关信息,输入正确的信息后然后点击“提交”按钮。 | 提示添加成功 | 正确 |
| 每日揽件添加模块测试 | 每日揽件添加失败的情况 | 在每日揽件页面中不填写的记录日期、物流数量,其他信息正常输入“提交”按钮。 | 提示“添加失败,信息不能为空” | 正确 |
5.3 系统测试结果
通过编写邮政数据分析系统的测试用例,已经检测完毕用户的登录模块、物流数据信息添加模块、查询每日运输模块、每日揽件添加模块的功能测试,在对以上功能得测试过程中,发现了系统中的很多漏送并进行了完善,经过多人在线进行测试,系统完全可以正常运行,当然在后期的维护中系统将不断完善。
6 结论
在开发本邮政数据分析系统之前我胸有成竹,觉得很简单,但在实际的开发中我发现了自身的很多问题,许多编程思想和方法都还没有掌握牢靠,比如Hadoop、pycharm、HbuildX等许多python Web开发技术,通过开发这个邮政数据分析系统我成长了很多,懂得了做什么事情都要脚踏实地,不能眼高手低,在本次邮政数据分析系统的开发中我逐渐掌握逐渐熟悉的技术。
本次邮政数据分析系统的开发中我还学会了很多,例如良好的编程思想和完善的规划思想。在着手编程之前需要罗列出程序框架的大概,脑海中构建出程序的主题框架。做好这一步我们才能胸有成竹的经行开发项目。当设计框架了熟于心之后,需要思考本次编程所需的主要知识点和技术点,并充分学习。如此一来项目的开发才能循序渐进、如丝般顺滑,长久以往就能养成良好的开发习惯。一个程序好不好还要看出的bug多不多,如果在项目完成前做好bug的查验与预防可能发生的事故才能保证程序的稳定长久性运行。如果项目在完工后出现各种问题自己,那么在进入社会后,不仅会给公司团队带来麻烦和增加不必要的工作,还会导致客户流失,公司对自己的评价下降。
在本次项目中我也暴露了诸多问题。对于python的编程知识有所欠缺,环境配置和算法上出现诸多问题,时常导致项目运行出错,或者目标的实现有问题。或者实现想法时算法未优化,使得代码冗长,程序运行不顺畅。
[1]沈健,罗强.数据治理下的区域教育质量监测数据分析系统探究[J].中国教育信息化,2023,29(04):77-85.
[2]王珅,周斌,范保杰,彭建祥,王彦,谢志春,刘长友,时会影,沈颖超,耿立格,王冰冰,田静.食用豆种质资源表型数据分析系统的设计与构建[J/OL].西北农林科技大学学报(自然科学版),2023(10):1-8[2023-05-04].DOI:10.13207/j.cnki.jnwafu.2023.10.007.
[3]孟切.基于数据仓库的公共财政数据分析系统设计[J].数字技术与应用,2023,41(03):187-189.DOI:10.19695/j.cnki.cn12-1369.2023.03.54.
[4]农佳明.基于Hadoop的电商数据分析系统设计与实现[J].电子技术,2023,52(03):67-69.
[5]罗帅,陈恭宇,甘林宁.综合停电与数据分析系统的设计与应用[J].机电信息,2023(05):34-38.DOI:10.19514/j.cnki.cn32-1628/tm.2023.05.010.
[6]丁然.基于Python爬虫技术的高校网络舆情数据分析研究——以“安徽审计职业学院百度贴吧”为例[J].现代信息科技,2023,7(05):106-108+112.DOI:10.19850/j.cnki.2096-4706.2023.05.025.
[7]杨易达,朱文超. 智能家居大数据分析系统设计[C]//中国家用电器协会.2022年中国家用电器技术大会论文集.2022年中国家用电器技术大会论文集,2023:834-846.DOI:10.26914/c.cnkihy.2023.002645.
[8]徐瀚杰.基于AWS微服务架构的车联网大数据分析系统的设计[J].电子技术与软件工程,2023(03):212-215.
[9]Banasode Praveen S.,Padmannavar Sunita S.,Tsihrintzis George A.,Virvou Maria,Saruwatari Takuya. Hadoop framework integrated hybrid optimization algorithm for privacy preserved clustering mechanism[J]. Intelligent Decision Technologies,2022,16(4).
[10]花维.基于Hadoop框架与用户行为特征感知的智能图书推荐系统设计[J].电子设计工程,2022,30(24):24-27+32.DOI:10.14022/j.issn1674-6236.2022.24.006.
[11]洪丽华,黄琼慧.基于Python爬虫技术的研究[J].价值工程,2022,41(34):154-156.
[12]王文选.依托Python爬虫技术和数据处理分析能力提升履职能力的探索[J].金融科技时代,2022,30(11):62-64+77.
[13]宿敬肖,张宾,张巧.基于Python技术的视觉采摘机器人作业优化[J].农机化研究,2023,45(08):206-210.DOI:10.13427/j.cnki.njyi.2023.08.004.
[14]宫瑞哲. 涤纶长丝丝锭质量数据分析系统设计与实现[D].机械科学研究总院,2022.DOI:10.27161/d.cnki.gshcs.2022.000016.
[15]Di Modica Giuseppe,Tomarchio Orazio. A Hierarchical Hadoop Framework to Process Geo-Distributed Big Data[J]. Big Data and Cognitive Computing,2022,6(1).
[16]Li Mingzheng,Lv Xiaojuan,Liu Ye,Wang Lin,Song Jianqiang. TCM Constitution Analysis Method Based on Parallel FP-Growth Algorithm in Hadoop Framework.[J]. Journal of healthcare engineering,2022,2022.
[17]张艳琴,张占领,郭怀宫.基于Hadoop框架的镁合金航空零件压铸模快速设计[J].铸造,2021,70(06):664-669.
[18]张国华,叶苗,王自然,周婷婷.大数据Hadoop框架核心技术对比与实现[J].实验室研究与探索,2021,40(02):145-148+176.DOI:10.19927/j.cnki.syyt.2021.02.028.
[19]王珈珞,曹前.基于Hadoop框架下高职微课程的研究与分析[J].现代信息科技,2020,4(18):140-143.DOI:10.19850/j.cnki.2096-4706.2020.18.039.
[20]唐华,何太能,傅国庆.邮政省级数据平台系统规划与建设[J].邮政研究,2017,33(04):9-12.DOI:10.13955/j.cnki.yzyj.2017.04.003.
[21]王卫锋,杨林.基于Hadoop的邮政寄递大数据分析系统设计与实现[J].中国科学院大学学报,2017,34(03):395-400.
[22]吴筱菁. 龙岩市邮政速递公司邮政速递时限监控系统的研究与分析[D].云南大学,2015.
致谢
到此,整个邮政数据分析系统就算完成了,虽然过程十分艰难,但是等到都完成的时候,我感觉无比的自豪,虽然设计的系统还存在许多的纰漏,但是我已经拼劲全力,给自己的大学四年画上了一个圆满的句号。
在这里我首先要感谢的就是大学四年来所有教导我的老师,是他们教会了我许多的专业知识以及做人的道理,从一进校门对对开发系统一窍不通到现在能自主开发一个管理系统,里面包含了前台框架、后台框架、业务流程、数据结构、操作系统等各种知识,只有把他们统一运用好,才能够完成整个系统,这都是老师的功劳;其次我要感谢我的指导老师,在开发这个系统的时候,我遇到了无数的问题,经常通过线上、线下的方式去请教导师,每次去请教导师,他从来没有不耐烦,都是细心的引导,告诉我怎么样实现这个功能,怎么样才能使得系统更加完善,然后通过自己查询相关资料解决问题,提高了自己自主解决问题的能力,授人以鱼不如授人以渔,指导老师的这种工作态度受益终生,我也会向老师不断靠拢,向他学习,在此我只想说一句:“老师,谢谢您,您辛苦了”!最后我还要感谢我的室友、同学,在一起学习这四年,他们不但学习上给了我很多建议,在生活上更加给了我帮助,正是有他们的帮助,我的大学生涯才如此完美。
最后,希望自己在未来的道路上能够越走越远,不辜负在大学的学习以及老师们的细致的教导,追风赶月莫停留,平荒尽处是春山。
请关注点赞+私信博主,免费领取项目源码

