
- 1eNSP——vpn技术-gre与mgre_ensp路由器gre
- 2uniapp制作简单的tab切换_uniapp tab
- 3Python爬取网页数据并导入表格_python shtml 抓取
- 4RAL 2023开源 | 第一个基于NeRF的实时LiDAR SLAM!_nerf 2023
- 5解决办法:E: 仓库 “......” 没有 Release 文件_仓库没有release文件,无法使用该源进行更新
- 6NzN的数据结构--复杂度分析
- 7hbase 的Rowkey设计方案_hbase rowkey生成
- 8毕设选题 单片机51单片机智能药盒控制系统设计_基于51的智能药箱系统设计与实现
- 9Maven快速构建flink项目骨架(一、cmd方式)_archetyp flink
- 10Android单元测试全解_android 单元测试
毕业设计——基于网络爬虫的电影数据可视化分析系统的设计与实现(综述+爬虫源码+web可视化展示源码)_基于python爬虫网站数据分析系统设计与实现
赞
踩
整个系统包括两大部分,如需要完整源码,可私信博主
一部分是使用python构建的爬虫,可爬取豆瓣电影数据并将爬取的数据存储在csv中,同时写入MySQL数据库。第二部分是针对爬取的数据进行多维数据清晰和分析,采用Flask框架进行前端的可视化呈现。
爬虫部分的基本原理:
豆瓣电影信息的url格式为:https://movie.douban.com/subject/id。例如:https://movie.douban.com/subject/26683290/
豆瓣是从2005年创办的,2005年以前的电影信息id很可能是最早的id。
搜索1999,得到一个1998年的电影。https://movie.douban.com/subject/1303954/。 id编号是七位的数字:1303954。搜索2016,得到最新的电影。https://movie.douban.com/subject/26928204/。 id编号是八位的数字:26928204。
由此猜测,目前(2016年)豆瓣电影的id大致是1300000到27000000。
由于反爬虫的设计,id是不连续的。为了提高命中率,需要对id的分布规律进行分析。
根据关键词种子,遍历搜索结果
豆瓣电影提供了搜索接口。通过关键词搜索得到相关记录的链接。
比如按年份获取,关键词可为:2005,2006,…2016。
比如分分类获取,关键词可为:动作,冒险,爱情,记录…。
基于网络爬虫的电影数据可视化分析系统的设计与实现综述
一、引言
随着信息技术的飞速发展,网络爬虫和数据可视化技术已经成为大数据分析领域的重要工具。在电影行业,通过爬取电影网站的数据,并结合机器学习算法进行分析,可以实现多维度的电影信息可视化,为观众、制片方和发行方提供有价值的参考信息。本文旨在综述基于网络爬虫的电影数据可视化分析系统的设计与实现过程,重点介绍如何使用Python实现爬虫,采用机器学习算法进行数据分析,并通过Flask框架和VUE技术实现前端可视化。
二、网络爬虫的设计与实现
网络爬虫是一种自动化程序,能够模拟人类浏览网页的行为,自动抓取网页上的数据。在本系统中,我们采用Python语言编写爬虫程序,利用requests库发送HTTP请求,获取豆瓣电影网站的数据。为了提高爬虫的效率和稳定性,我们采用了多线程、异步IO等技术,并设置了合理的请求间隔和重试机制,以避免对目标网站造成过大的访问压力。
在爬虫的设计过程中,我们还需要考虑数据的清洗和预处理。由于网页数据的格式和结构复杂多样,我们需要通过正则表达式、XPath等技术提取出有用的信息,并进行去重、去噪、格式化等操作,以便后续的数据分析。
三、基于机器学习算法的数据分析
数据分析是电影数据可视化分析系统的核心环节。在本系统中,我们采用机器学习算法对爬取到的电影数据进行处理和分析。具体来说,我们可以利用文本挖掘技术提取电影标题、简介、评论等文本信息中的关键词和主题,通过聚类算法将相似的电影进行分组;同时,我们还可以利用分类算法预测电影的类型、风格等属性;此外,我们还可以利用关联规则挖掘技术发现电影之间的关联关系,如导演与演员的合作关系、类型相似的电影等。
四、基于Flask框架和VUE技术的前端可视化
前端可视化是将数据分析结果以直观、易懂的方式呈现给用户的关键环节。在本系统中,我们采用Flask框架和VUE技术实现前端可视化。Flask是一个轻量级的Web框架,能够快速构建Web应用程序;VUE则是一个流行的前端框架,具有丰富的组件库和灵活的数据绑定机制,能够实现复杂的前端交互效果。
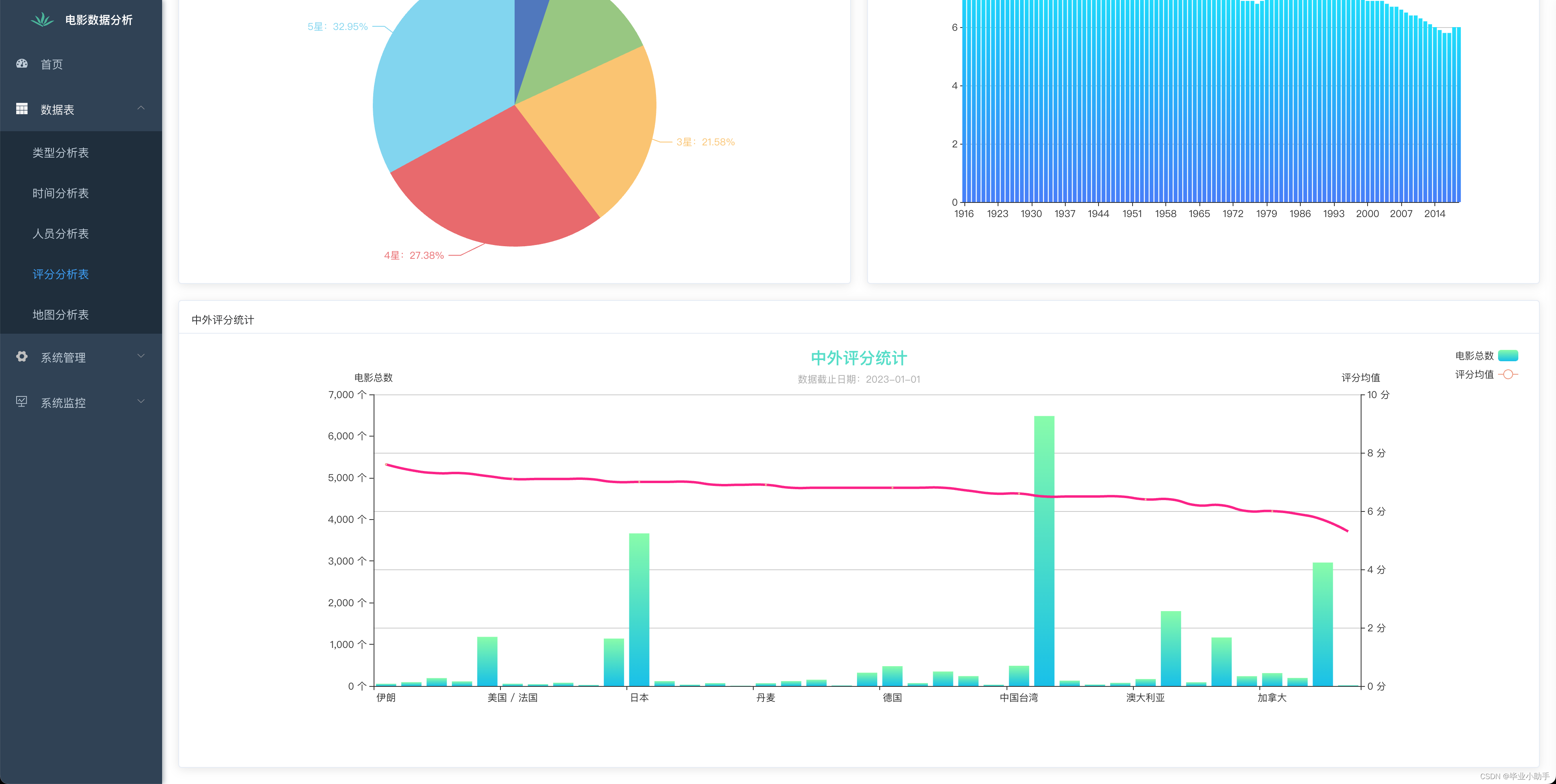
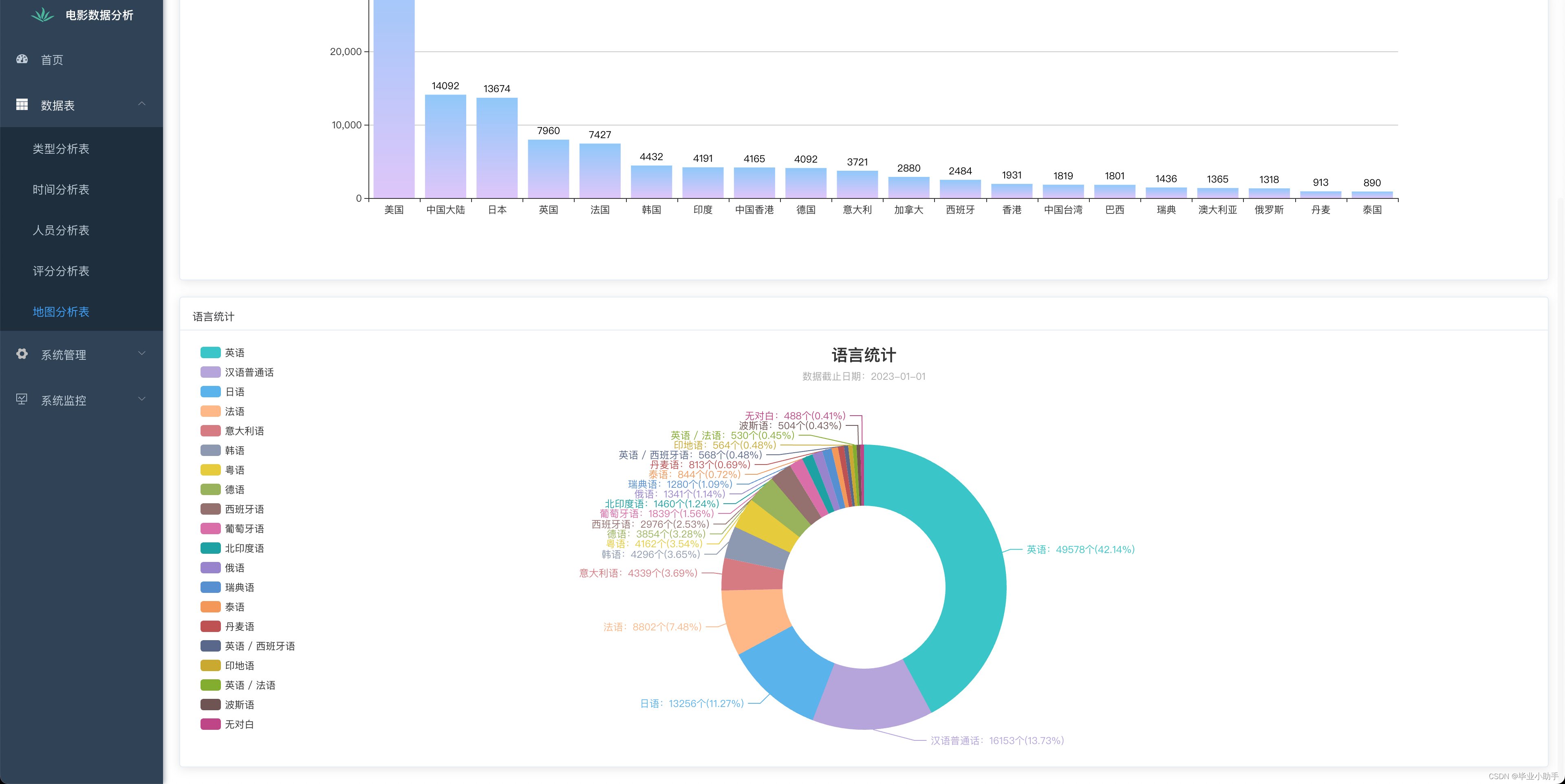
通过Flask框架,我们搭建了一个Web服务器,用于处理前端发送的请求,并返回相应的数据或页面。在前端,我们使用VUE框架构建用户界面,并通过Ajax等技术与后端进行通信,实现数据的动态加载和展示。我们利用图表库(如ECharts)将数据分析结果以图表的形式展示给用户,如柱状图、饼图、散点图等,使用户能够直观地了解电影数据的分布情况和关联关系。
五、结论与展望
本文综述了基于网络爬虫的电影数据可视化分析系统的设计与实现过程。通过Python实现爬虫,采用机器学习算法进行数据分析,以及利用Flask框架和VUE技术实现前端可视化,我们构建了一个功能强大、易于使用的电影数据可视化分析系统。该系统能够为观众提供丰富的电影信息,为制片方和发行方提供市场分析和决策支持。
未来,我们可以进一步优化爬虫算法,提高数据的准确性和完整性;同时,我们可以探索更多的机器学习算法和可视化技术,以实现对电影数据的更深入分析和更丰富的展示方式。此外,我们还可以考虑将系统与其他数据源进行整合,以获取更全面的电影信息,为用户提供更优质的服务。
效果展示:
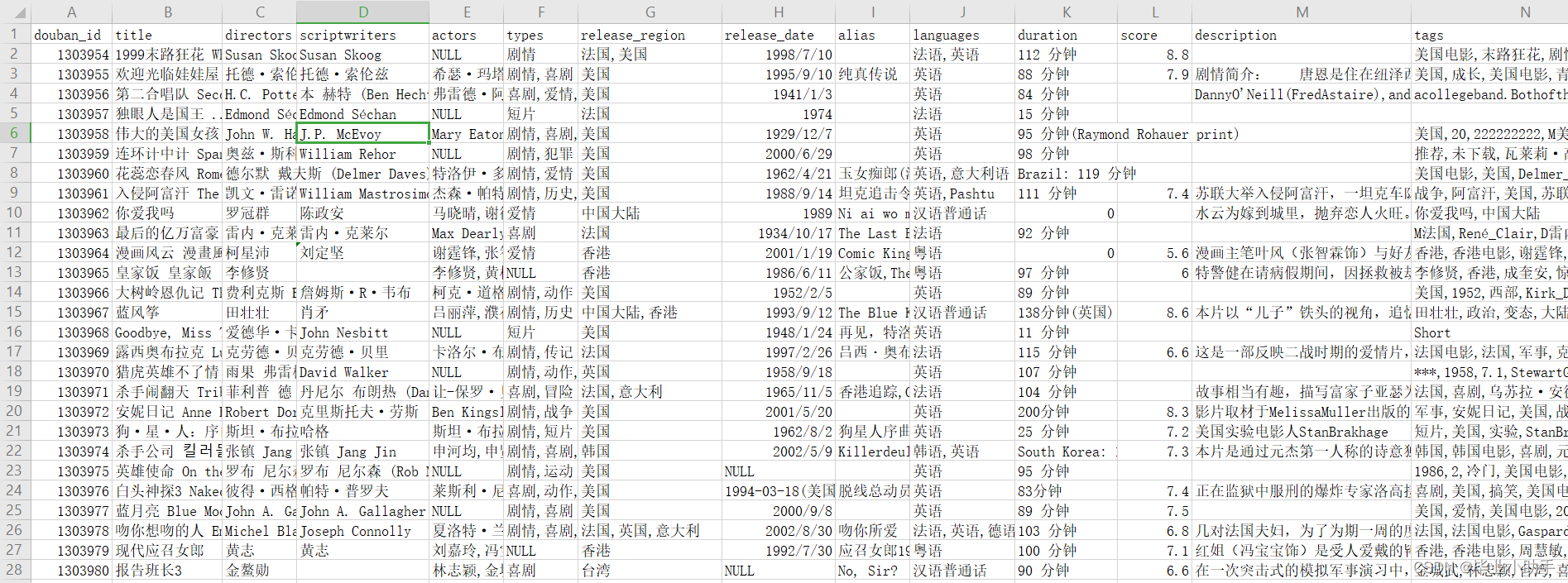
爬取后的电影信息数据
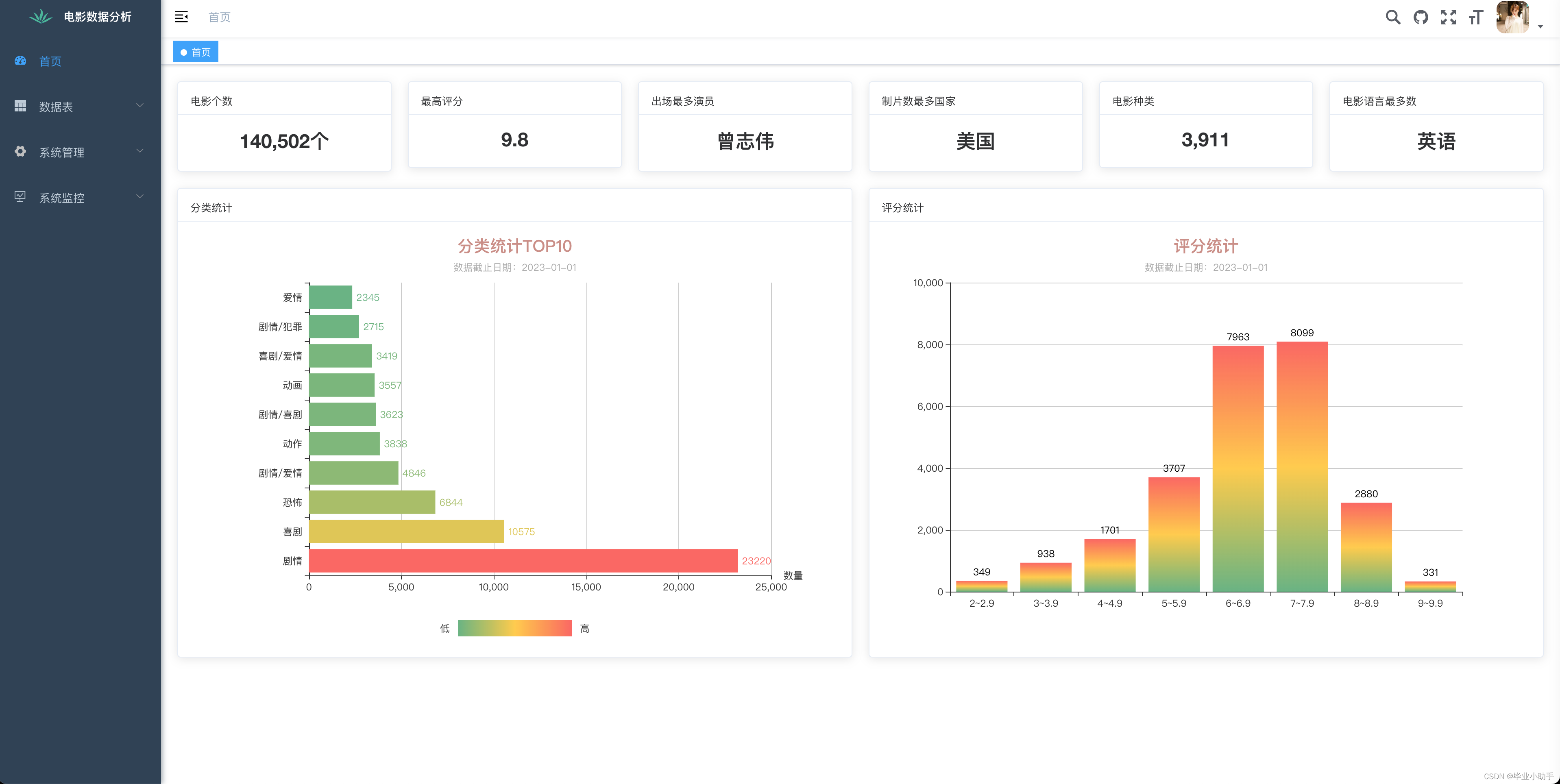
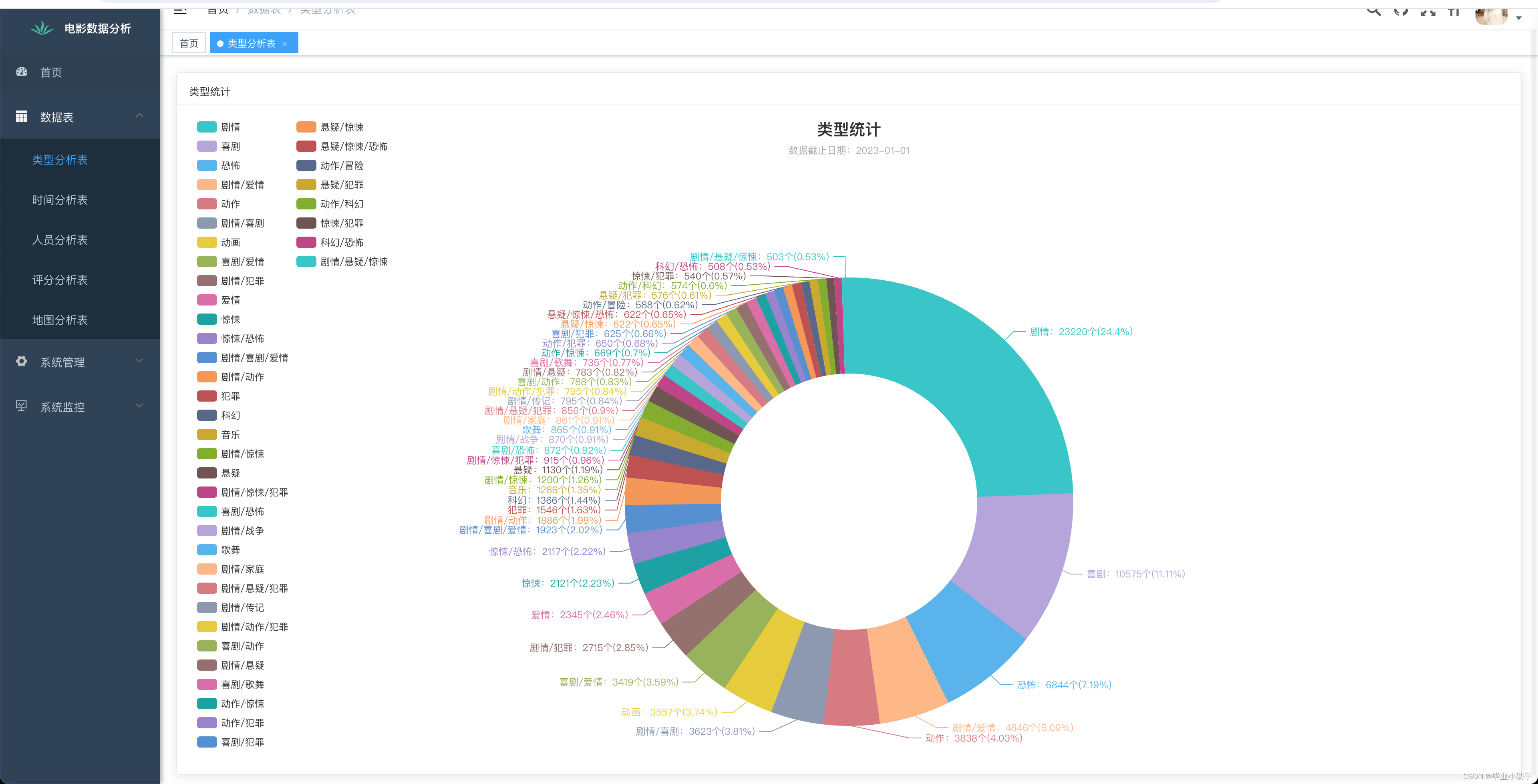
前端可视化呈现效果
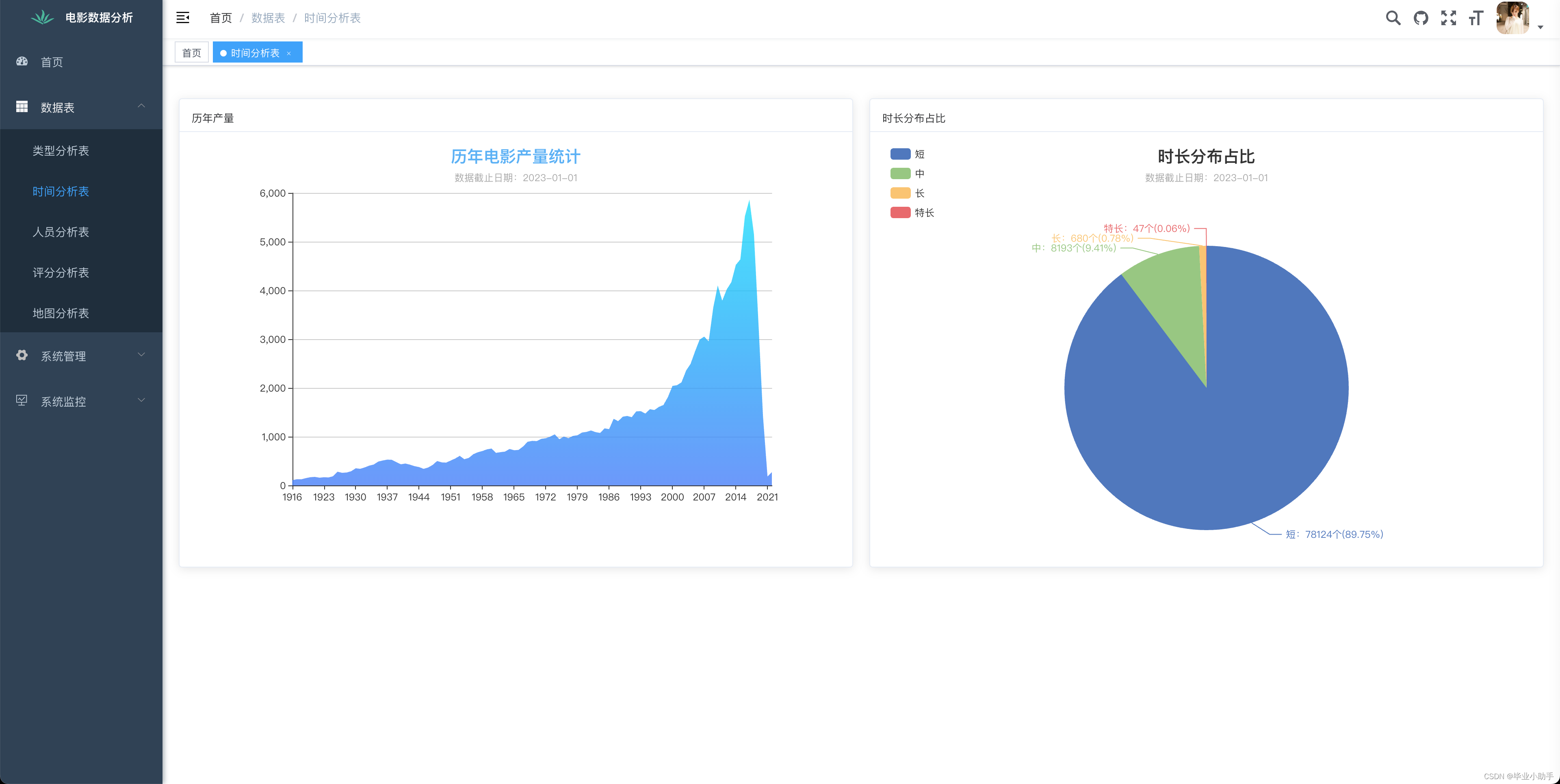
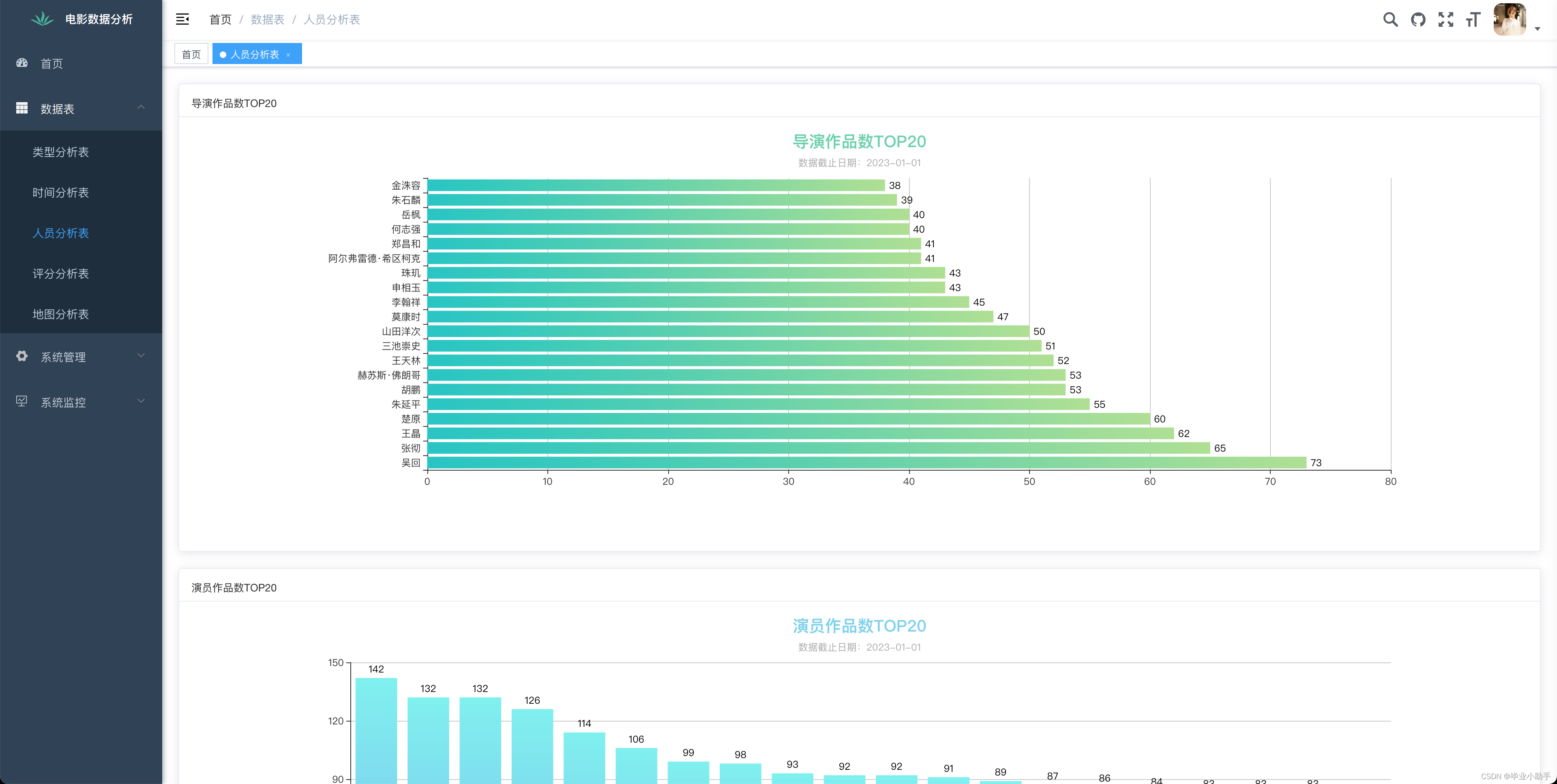
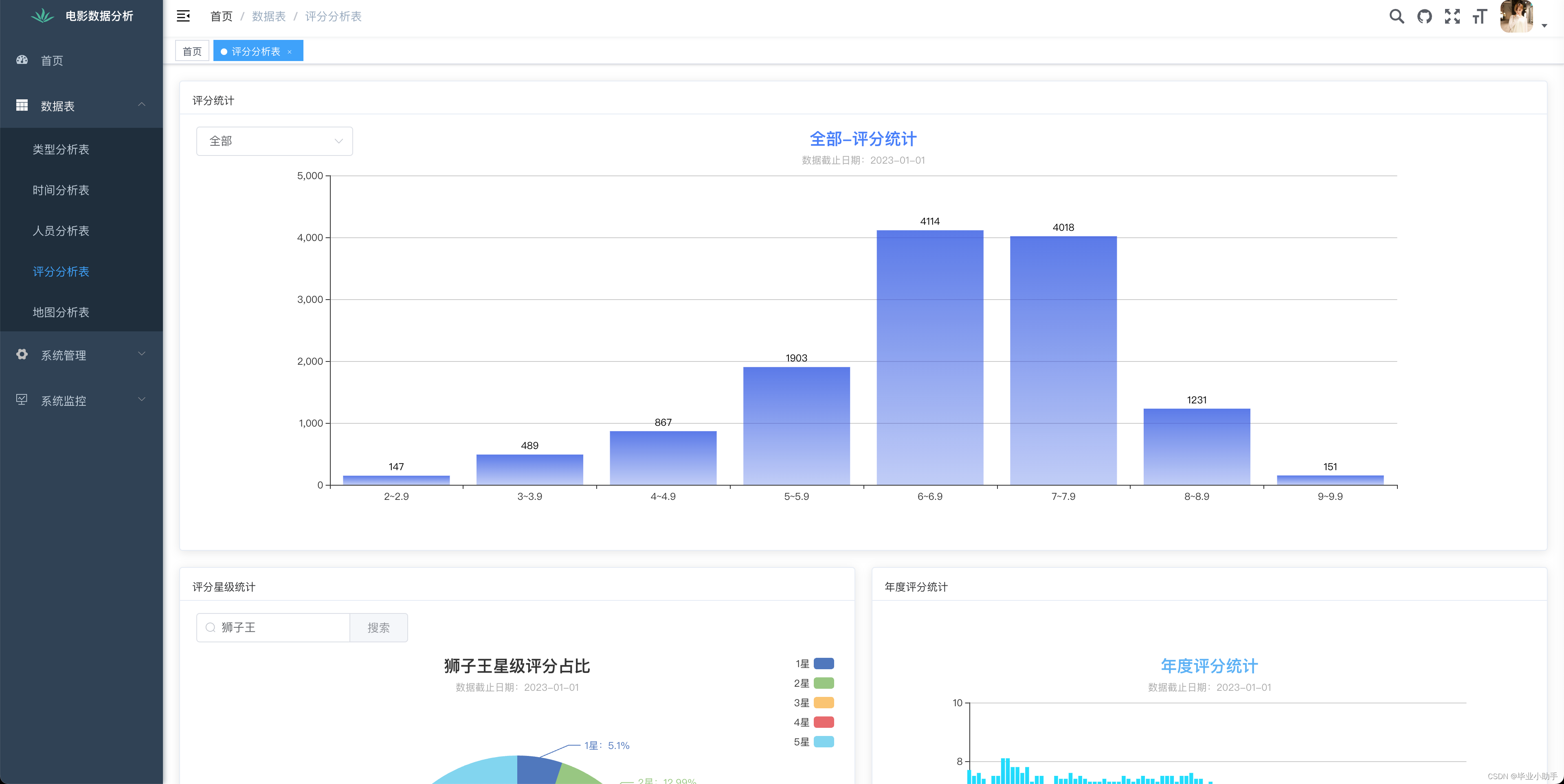
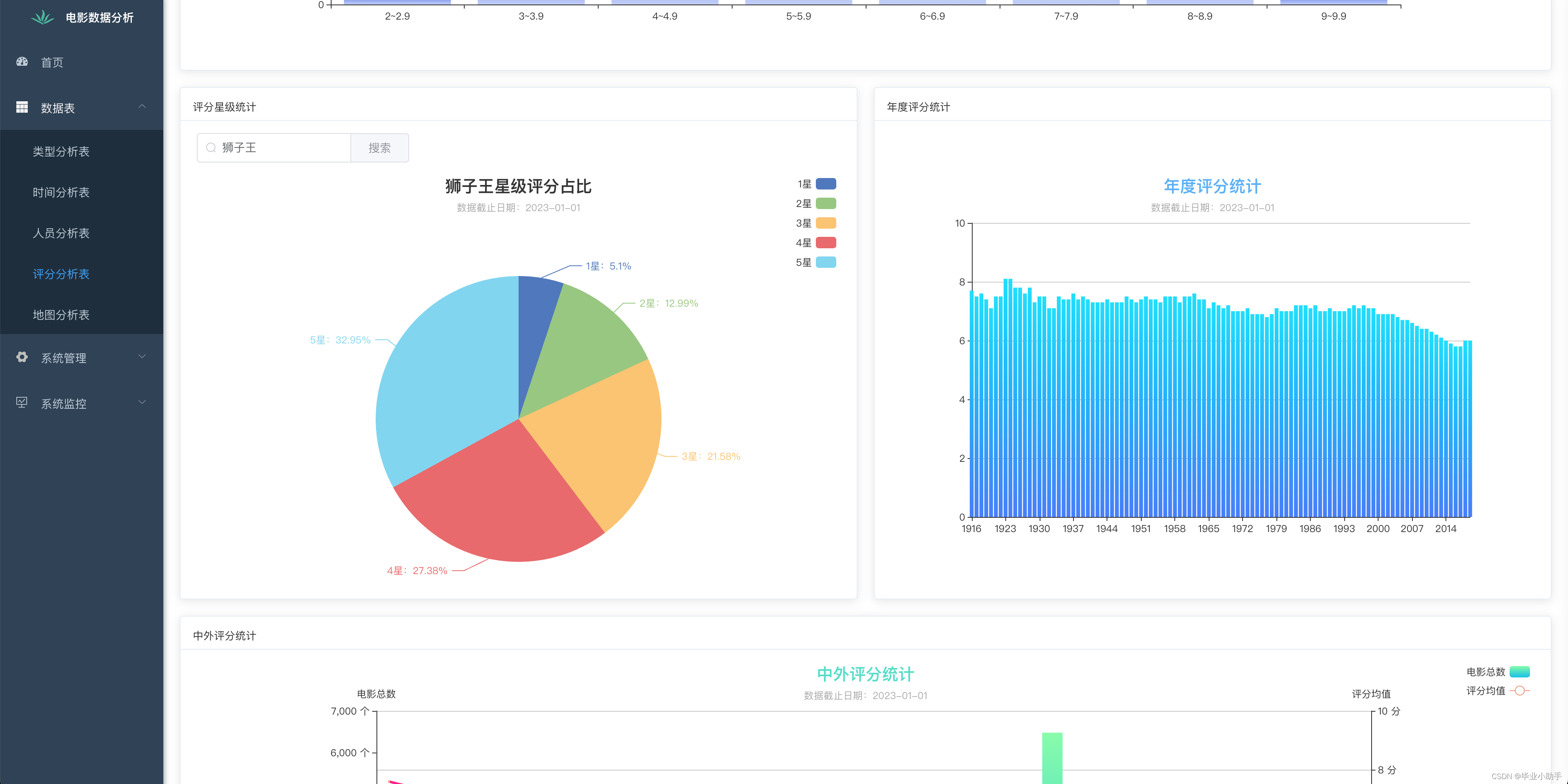
部分源码:
SQL部分
drop database if exists douban; create database douban default charset utf8mb4; use douban; drop table if exists movie; create table movie ( `douban_id` varchar(16) not null primary key comment '豆瓣的标记id当主键,顺便用来去重', `title` varchar(1024) not null default '' comment '标题', `directors` text comment '导演', `scriptwriters` text comment '编剧', `actors` text comment '演员', `types` text comment '类别', `release_region` text comment '上映地区', `release_date` text comment '上映日期', `alias` text comment '别名', `languages` text comment '语言', `duration` text comment '播放时长', `score` text comment '评分', `description` text comment '描述', `tags` text comment '标签', `create_at` timestamp not null default current_timestamp ) engine=innodb default charset=utf8mb4; /* type说明: 1表示剧照, 2表示海报, 3表示壁纸 完整的图片url为: https://movie.douban.com/photos/photo/photo_id example: https://movie.douban.com/photos/photo/2285200316/ */ drop table if exists photo; create table photo ( `id` int not null auto_increment, `douban_id` varchar(16), `type` tinyint, `photo_id` varchar(16), primary key(`id`) ) charset=utf8;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
爬虫主程序:
# coding=utf-8 import random import requests import configparser import constants from login import CookiesHelper from page_parser import MovieParser from utils import Utils from storage import DbHelper def init(): config = configparser.ConfigParser() config.read('config.ini') user = config['douban']['user'], password = config['douban']['password'] cookie_helper = CookiesHelper.CookiesHelper( user, password ) cookies = cookie_helper.get_cookies() print(cookies) # 读取抓取配置 start_id = int(config['common']['start_id']) end_id = int(config['common']['end_id']) # 读取配置文件信息 user = config['douban']['user'], password = config['douban']['password'] return cookies, start_id, end_id, user, password def run(): cookies, start_id, end_id, user, password = init() # 获取模拟登录后的cookies cookie_helper = CookiesHelper.CookiesHelper( user, password ) cookies = cookie_helper.get_cookies() print(cookies) # 实例化爬虫类和数据库连接工具类 movie_parser = MovieParser.MovieParser() db_helper = DbHelper.DbHelper() # 通过ID进行遍历 for i in range(start_id, end_id): headers = {'User-Agent': random.choice(constants.USER_AGENT)} # 获取豆瓣页面(API)数据 r = requests.get( constants.URL_PREFIX + str(i), headers=headers, cookies=cookies ) r.encoding = 'utf-8' # 提示当前到达的id(log) print('id: ' + str(i)) # 提取豆瓣数据 movie_parser.set_html_doc(r.text) movie = movie_parser.extract_movie_info() # 如果获取的数据为空,延时以减轻对目标服务器的压力,并跳过。 if not movie: Utils.Utils.delay(constants.DELAY_MIN_SECOND, constants.DELAY_MAX_SECOND) continue # 豆瓣数据有效,写入数据库 movie['douban_id'] = str(i) if movie: db_helper.insert_movie(movie) Utils.Utils.delay(constants.DELAY_MIN_SECOND, constants.DELAY_MAX_SECOND) # 释放资源 db_helper.close_db() if __name__ == '__main__': print("开始抓取\n") init() run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91


