
- 1web前端工资一般多少?在北京前端工程师多少钱一个月?_北京前端开发工资一般多少
- 2微信小程序 form-data传参_微信小程序formdata传参
- 3“\u0001”(十六进制值 0x01)是无效的字符
- 4java joda 获取utc时间_[原创]Java项目统一UTC时间方案
- 5Hive数据倾斜解决方案_hive2.1.1 group by spark引擎 防止倾斜
- 6在linux系统上运行Stable Diffusion web UI_linux运行stable diff
- 7XcodeiOS模拟器安装相关
- 8蚁群 算法_蚁群算法
- 9java中final修饰类、变量、方法
- 10终于解决了安装torch的同时cuda版本_install torch cuda
k8s实践(14)--scheduler调度器和pod调度策略_scheduling te pod
赞
踩
一、scheduler调度器
1、kube-scheduler简介
k8s实践(10) -- Kubernetes集群运行原理详解 介绍过kube-scheduler。
kube-scheduler是运行在master节点上,其主要作用是负责资源的调度(Pod调度),通过API Server的Watch接口监听新建Pod副本信息, 按照预定的调度策略将Pod调度到相应的Node节点上;
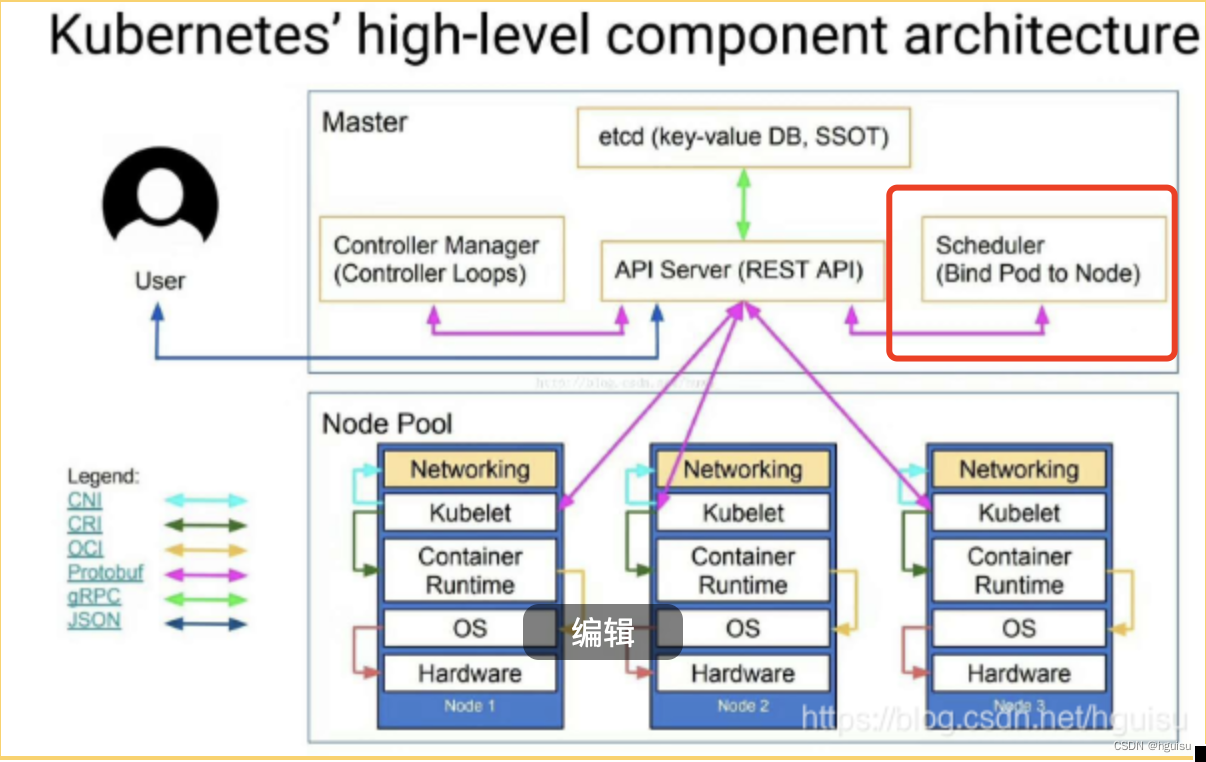
创建Pod的整个流程,时序图如下:

1. 用户提交pod资源请求:用户提交创建Pod的请求,可以通过API Server的REST API ,也可用Kubectl命令行工具,支持Json和Yaml两种格式;
2. API Server 处理请求:API Server 处理用户请求,存储Pod数据到Etcd;
3. Schedule调度pod:Schedule通过和 API Server的watch机制,实时查看到新的pod,按照预定的调度策略将Pod调度到相应的Node节点上;
一旦 Etcd 存储 Pod 信息成功便会立即通知APIServer,APIServer会立即把Pod创建的消息通知Scheduler,Scheduler发现 Pod 的属性中 Dest Node 为空时(Dest Node=””)便会立即触发调度流程进行调度。
在调度的过程当中有3个阶段:节点预选、节点优选、节点选定,从而筛选出最佳的节点:
1)过滤主机(节点预选):调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机从而完成节点的预选;
2)主机打分(节点优选):对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等;对预选出的节点进行优先级排序,以便选出最合适运行Pod对象的节点.
3)选择主机(节点选定):选择打分最高的主机,进行binding操作,结果存储到Etcd中;
4. kubelet创建pod: kubelet根据Schedule调度结果执行Pod创建操作: 调度成功后,会启动container, docker run, scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器。
2、Scheduler原理分析
k8s Scheduler的作用是将待调度的Pod(API新创建的Pod、Controller Manager为补足副本而创建的Pod等)按照特定的调度算法和调度策略绑定到集群中的某个合适的Node上,并将绑定信息写入etcd中。
在整个调度过程中涉及三个对象,分别是:待调度Pod列表、可用Node列表,以及调度算法和策略。
随后,目标节点上的kubelet通过API Server监听到k8s Scheduler产生的Pod绑定事件,然后获取对应的Pod清单,下载Image镜像,并启动容器。
完整的流程如下所示:
k8s Scheduler当前提供的默认调度流程分为以下两步:
1)预选调度过程,即遍历所有目标Node,筛选出符合要求的候选节点,kubernetes内置了多种预选策略(xxx Predicates)供用户选择。
2)确定最优节点,在第一步的基础上采用优选策略(xxx Priority)计算出每个候选节点的积分,最高积分者胜出。
k8s Scheduler的调度流程是通过插件方式加载的“调度算法提供者”(AlgorithmProvider)具体实现的。一个AlgorithmProvider其实就是包括了一组预选策略与一组优选策略的结构体。
注册AlgorithmProvider的函数如下:
func RegisterAlgorithmProvider(name string, predicateKeys, priorityKeys util.StringSet)
它包含三个参数:
name.string,算法名;
predicateKeys,为算法用到的预选策略集合;
priorityKeys,为算法用到的优选策略的集合;
Scheduler中可用的预选策略包含:NoDiskConflict, PodFitsResources, PodSelectorMatches, PodFirstHost, CheckNodeLabelPresence, CheckServiceAffinity和PodFitsPorts策略等。
其默认的AlgorithmProvider加载的预选策略Predicates包括:PodFitsPorts, PodFitsResources, NoDiskConflict, MatchNodeSelector(PodSelectorMatches) 和 HostName(PodFitsHost),即每个节点只有通过前面提及的5个默认预选策略后,才能初步被选中,进入下一个流程。
常用的预选策略:
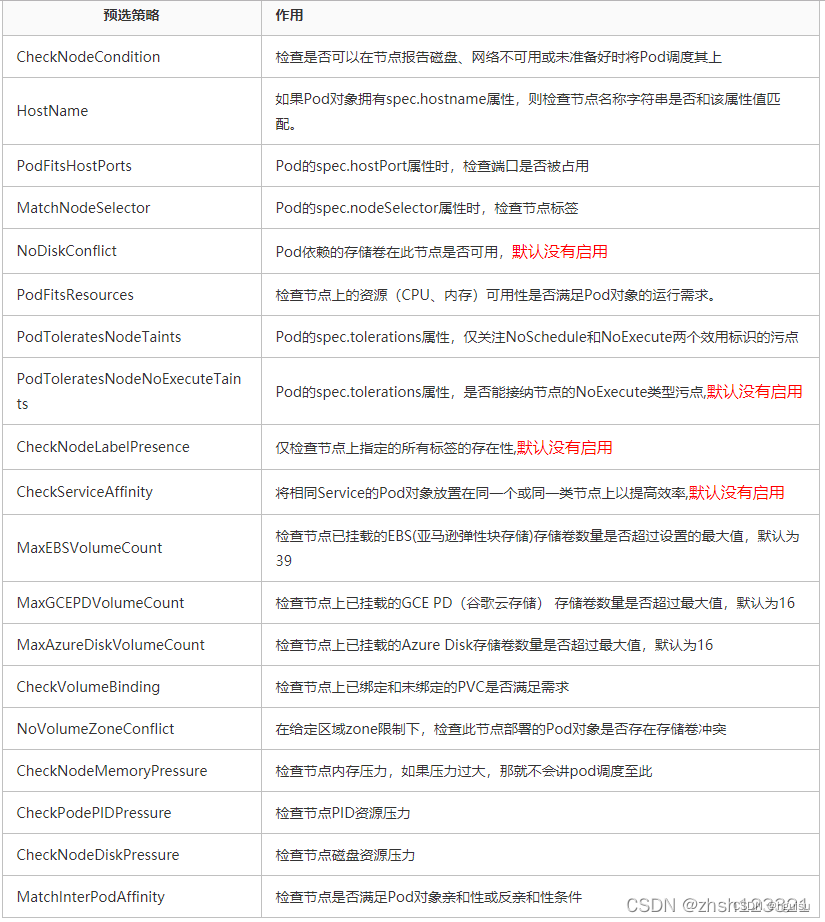
1)NoDiskConflict :pod依赖的存储卷在此节点是否可用,默认不开启
判断备选Pod的gcePersistentDisk或AWSElasticBlockStore和备选的节点中已存在的Pod是否存在冲突。检测过程如下:
首先,读取备选Pod的所有Volume的信息(即pod.Spec.Volumes),对每个Volume执行以下步骤进行冲突检测。
如果该Volume是gcePersistentDisk,则将Volume和备选节点上的所有Pod的每个Volume进行比较,如果发现相同的gcePersistentDisk,则返回false,表明存在磁盘冲突,检查结束,反馈给调度器该备选节点不适合作为备选Pod;如果该Volume是AWSElasticBlockStore,则将Volume和备选节点上的所有Pod的每个Volume进行比较,如果发现相同的AWSElasticBlockStore,则返回false,表明存在磁盘冲突,检查结束,反馈给调度器该备选节点不适合备选Pod。
如果检查完备选Pod的所有Volume均未发现冲突,则返回true,表明不存在磁盘冲突,反馈给调度器该备选节点适合备选Pod。
2)PodFitsResources :选择节点上资源(内存和CPU)是否满足pod运行需求
判断备选节点的资源是否满足备选Pod的需求,检测过程如下:
计算备选Pod和节点中已存在Pod的所有容器的需求资源(内存和CPU)的总和。
获得备选节点的状态信息,其中包含节点的资源信息。
如果备选Pod和节点中已存在Pod的所有容器的需求资源(内存和CPU)的总和,超出了备选节点拥有的资源,则返回false,表明备选节点不适合备选Pod,否则返回true,表明备选节点适合备选Pod。
3)PodSelectorMatches: 当pod存在spec.nodeSelector标签选择器,检查节点标签。
判断备选节点是否包含备选Pod的标签选择器指定的标签。
如果Pod没有指定spec.nodeSelector标签选择器,则返回true。
否则,获得备选节点的标签信息,判断节点是否包含备选Pod的标签选择器(spec.nodeSelector)所指定的标签,如果包含,则返回true,否则返回false。
4)PodFitsHost:如果Pod存在spec.nodeName属性
判断备选Pod的spec.nodeName域所指定的节点名称和备选节点的名称是否一致,如果一致,则返回true,否则返回false。
5)CheckNodeLabelPresence
如果用户在配置文件中指定了该策略,则Scheduler会通过RegisterCustomFitPredicate方法注册该策略。该策略用于判断策略列出的标签在备选节点中存在时,是否选择该备选节点。
读取备选节点的标签列表信息。
如果策略配置的标签列表存在于备选节点的标签列表中,且策略配置的presence值为false,则返回false,否则返回true;如果策略配置的标签列表不存在于备选节点的标签列表中,且策略配置的presence为true,则返回false,否则返回true。
6)CheckServiceAffinity
如果用户在配置文件中指定了该策略,则Scheduler会通过RegisterCustomFitPredicate方法注册该策略。该策略用于判断备选节点是否包含策略指定的标签,或包含和备选Pod在相同Service和Namespace下的Pod所在节点的标签列表。如果存在,则返回true,否则返回false。
7)PodFitsPorts
判断备选Pod所用的端口列表中的端口是否在备选节点中已被占用,如果被占用,则返回false,否则返回true。
Scheduler中的优选策略
Scheduler中的优选策略包含:LeastRequestedPriority、CalculateNodeLabelPriority和BalancedResourceAllocation等。
每个节点通过优选策略时都会算出一个得分,计算各项得分,最终选出得分值最大的节点作为优选的结果(也是调度算法的结果)。
下面是对优选策略的详细说明:
1) LeastRequestedPriority
优先从备选节点列表中选择资源消耗最小的节点(CPU+内存)。
2) CalculateNodeLabelPriority
如果用户在配置文件中指定了该策略,则scheduler会通过RegisterCustomPriorityFunction方法注册该策略。该策略用于判断策略列出的标签在备选节点中存在时,是否选择该备选节点。
如果备选节点的标签在优先策略的标签列表中且优选策略的presence为true,或者备选节点的标签不在优选策略的标签列表中且优选策略的presence值为false,则备选节点score=10,否则备选节点score=0。
3) BalancedResourceAllocation
优先从备选节点列表中选择各项资源使用率最均衡的节点。
二、Pod调度
在Kubernetes系统中,Pod在大部分场景下都只是容器的载体而已,通常需要通过RC、Deployment、DaemonSet、Job等对象来完成Pod的调度和自动控制功能。
k8s提供了常用的4大调度规则,如下:
- 自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出;
- 定向调度:NodeName、NodeSelector;
- 亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity;
- 污点(容忍)调度:Taints、Toleration;
三、RC、Deployment的pod调度
RC的主要功能之一就是自动部署容器应用的多份副本,以及持续监控副本的数量,在集群内始终维护用户指定的副本数量。
在调度策略上,除了使用系统内置的调度算法选择合适的Node进行调度,也可以在Pod的定义中使用NodeName、NodeSelector或NodeAffinity来指定满足条件的Node进行调度。
1、基于NodeName定向调度
Pod.spec.nodeName用于强制约束将Pod调度到指定的Node节点上,这里说是“调度”,但其实指定了nodeName的Pod会直接跳过Scheduler的调度逻辑,直接写入PodList列表,该匹配规则是强制匹配。
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- labels:
- app: springbootweb
- name: springbootweb-deployment
- spec:
- replicas: 1
- selector:
- matchLabels:
- app: springbootweb
- template:
- metadata:
- labels:
- app: springbootweb
- spec:
- nodeName: node23.turing.com
- containers:
- - image: registry.tuling123.com/springboot:latest
- imagePullPolicy: IfNotPresent
- name: springbootweb
- ports:
- - containerPort: 9081
- hostPort: 9981
- imagePullSecrets:
- - name: registry-key-secret

2、基于NodeSelector:定向调度
Kubernetes Master上的scheduler服务(kube-Scheduler进程)负责实现Pod的调度,整个过程通过一系列复杂的算法,最终为每个Pod计算出一个最佳的目标节点,通常我们无法知道Pod最终会被调度到哪个节点上。实际情况中,我们需要将Pod调度到我们指定的节点上,可以通过Node的标签和pod的nodeSelector属性相匹配来达到目的。
其核心思想是,为工作节点(node)打上标签,比如地区、机房、CPU密集、IO密集等。然后在创建pod的描述文件时指定对应标签,调度器就会将pod调度到符合标签选择器规则的工作节点上。
NodeSelector(Pod.spec.nodeSelector)是通过kubernetes的label-selector机制进行节点选择,由scheduler调度策略MatchNodeSelector调度策略进行label匹配,调度pod到目标节点,该匹配规则是强制约束。
启用节点选择器的步骤为:
(1)首先通过kubectl label命令给目标Node打上标签
kubectl label nodes <node-name> <label-key>=<label-value>
例:#kubectllabel nodes k8s-node-1 zonenorth
(2)然后在Pod定义中加上nodeSelector的设置,例:
- apiVersion:v1
- kind: Pod
- metadata:
- name: redis-master
- label:
- name: redis-master
- spec:
- replicas: 1
- selector:
- name: redis-master
- template:
- metadata:
- labels:
- name: redis-master
- spec:
- containers:
- - name: redis-master
- images: kubeguide/redis-master
- ports:
- - containerPort: 6379
- nodeSelector:
- zone: north
运行kubectl create -f命令创建Pod,scheduler就会将该Pod调度到拥有zone=north标签的Node上。 如果多个Node拥有该标签,则会根据调度算法在该组Node上选一个可用的进行Pod调度。
需要注意的是:如果集群中没有拥有该标签的Node,则这个Pod也无法被成功调度。
3、Affinity:亲和性调度
Affinity主要分为三类:
nodeAffinity(node亲和性): 以node为目标,解决pod可以调度到哪些node的问题;podAffinity(pod亲和性) : 以pod为目标,解决pod可以和哪些已存在的pod部署在同一个拓扑域中的问题;podAntiAffinity(pod反亲和性) : 以pod为目标,解决pod不能和哪些已存在pod部署在同一个拓扑域中的问题;
关于亲和性(反亲和性)使用场景的说明:
亲和性
如果两个应用频繁交互,那就有必要利用亲和性让两个应用的尽可能的靠近,这样可以减少因网络通信而带来的性能损耗。
反亲和性
当应用的采用多副本部署时,有必要采用反亲和性让各个应用实例打散分布在各个node上,这样可以提高服务的高可用性。
4、NodeAffinity亲和性
4、NodeAffinity亲和性该调度策略是将来替换NodeSelector的新一代调度策略。由于NodeSelector通过Node的Label进行精确匹配,所有NodeAffinity增加了In、NotIn、Exists、DoesNotexist、Gt、Lt等操作符来选择Node。调度侧露更加灵活。
1)、NodeAffinity 的亲和性表达
目前有以下几种亲和性表达。
硬限制:RequiredDuringSchedulingIgnoredDuringExecution
必须满足指定的规则才可以调度 Pod 到 Node 上,相当于 硬限制。
软限制:PreferredDuringSchedulingIgnoredDuringExecution
强调优先满足指定规则,调度器会尝试调度 Pod 到 Node 上,但并不强求,相当于 软限制。
多个优先级规则还可以设置权重(weight)值,以此来定义执行的先后顺序。
节点亲和性权重
我们可以为 PreferredDuringSchedulingIgnoredDuringExecution 亲和性类别的每个实例设置 weight 字段,取值范围是 1 ~ 100。当调度器找到能够满足 Pod 的其他调度请求的节点时,调度器会比那里节点满足的所有的偏好性规则,并将对应表达式的 weight 值加和。最终的加和值会添加到该节点的其他优先级函数的评分之上。在调度器为 Pod 做出调度决定时,总分最高的节点的优先级也最高。
IgnoredDuringExecution
如果一个 Pod 所在的节点在 Pod 运行期间标签发生了变更,不再符合该 Pod的节点亲和性需求,则系统将忽略 Node 上 label 的变化,该 Pod 能继续在该节点运行。
2)、NodeAffinity 的语法规则
NodeAffinity 语法支持的操作符包括In,NotIn,Exists,DoesNotExist,Gt,Lt。虽然没有节点排斥功能,但是用 NotIn 和 DoesNotExist 就可以实现排斥的功能了。
In:label的值在某个列表中
NotIn:label的值不在某个列表中
Gt:label的值大于某个值
Lt:label的值小于某个值
Exists:某个label存在
DoesNotExist:某个label不存在
关系符使用说明:
- matchExpressions:
- key: nodeenv # 匹配存在标签的key为nodeenv的节点
operator: Exists
- key: nodeenv # 匹配标签的key为nodeenv,且value是"xxx"或"yyy"的节点
operator: In
values: ["xxx","yyy"]
- key: nodeenv # 匹配标签的key为nodeenv,且value大于"xxx"的节点
operator: Gt
values: "xxx"
3)、NodeAffinity 的注意事项
如果同时定义了 nodeSelector 和 nodeAffinity,那么必须两个条件都得到满足,Pod 才能最终运行到指定的 Node 上。
如果 nodeAffinity 指定了多个 nodeSelectorTerms,那么其中一个能够匹配成功即可。
如果在 nodeSelectorTerms 中有多个 matchExpressions,则一个节点必须满足所有matchExpressions 才能运行该 Pod。
4、案例
通过配置 NodeAffinity 的 PreferredDuringSchedulingIgnoredDuringExecution 来实现,优先将 Pod 投递到 32G 内存的节点,其次 16G 内存节点,最后 8G 内存节点。
- spec:
- containers:
- - name: xxxxx
- image: xxxxx
- affinity:
- nodeAffinity:
- preferredDuringSchedulingIgnoredDuringExecution:
- - weight: 20
- preference:
- matchExpressions:
- - key: mem
- operator: In
- values:
- - memory32
- - weight: 10
- preference:
- matchExpressions:
- - key: mem
- operator: In
- values:
- - memory16
- - weight: 1
- preference:
- matchExpressions:
- - key: mem
- operator: In
- values:
- - memory8
5、Taints和Tolerations(污点和容忍)
NodeAffinity 节点亲和性,是在 Pod 上添加属性,使得 Pod 能够被调度到指定 Node 上运行(优先选择或强制要求)。Taint 则正好相反,它让 Node 拒绝 Pod 的运行。就是从Node的角度上,通过在Node上添加污点属性,来决定是否允许Pod调度过来。这种调度策略即所谓的污点。
Taint 需要和 Toleration 配合使用,让 Pod 避开那些不合适的 Node。在 Node 上设置一个或多个 Taint 之后,除非 Pod 明确声明能够容忍这些污点,否则无法在这些 Node 上运行。Toleration 是 Pod 的属性,让 Pod 能够(注意,只是能够,而非必须)运行在标注了 Taint 的 Node 上。
1)、污点格式
1)、污点格式
key=value:effect, key和value是污点的标签,effect描述污点的作用
其支持如下三个选项
PreferNoSchedule:kubernetes将尽量避免把Pod调度到具有该污点的Node上,除非没有其他节点可调度;NoSchedule):kubernetes将不会把Pod调度到具有该污点的Node上,但不会影响当前Node上已存在的Pod;NoExecute):kubernetes将不会把Pod调度到具有该污点的Node上,同时也会将Node上已存在的Pod驱离;
2)、节点设置污点taint
可以用 kubectl taint 命令为 Node 设置 Taint 信息:
$ kubectl taint nodes node1 key=value:NoSchedule
这个设置为 node1 加上了一个 Taint,该 Taint 的键为 key,值为 value,Taint 的效果是 NoSchedule。这意味着除非 Pod 明确声明可以容忍这个 Taint,否则就不会被调度到 node1 上。
3)、 Pod 声明 Toleration
需要在 Pod 上声明 Toleration。下面的两个 Toleration 都被设置为可以容忍(Tolerate)具有该 Taint 的Node,使得 Pod 能够被调度到 node1 上。
- tolerations:
- - key: "key"
- operator: "Equal"
- value: "value"
- effect: "NoSchedule"
-
- --或:
-
- tolerations:
- - key: "key"
- operator: "Exists"
- effect: "NoSchedule"
Pod的 Toleration 声明中的 key 和 effect 需要与 Taint 的设置保持一致,并且满足以下条件之一。
operator 的值是 Exists(无须指定value)。
operator 的值是 Equal 并且 value 相等。
如果不指定 operator,则默认值为 Equal。
另外,有如下两个特例。
空的 key 配合 Exists 操作符能够匹配所有的键和值。
空的 effect 匹配所有的 effect。
4)、调度器处理多个Taint 和 Toleration 的逻辑顺序
系统允许在同一个 Node 上设置多个 Taint,也可以在 Pod 上设置多个 Toleration。Kubernetes 调度器处理多个Taint 和 Toleration 的逻辑顺序为:首先列出节点中所有的 Taint,然后忽略 Pod 的 Toleration 能够匹配的部分,剩下的没有忽略的 Taint 就是对 Pod 的效果了。
下面是几种特殊情况。
- 如果在剩余的 Taint 中存在 effect=NoSchedule,则调度器不会把该 Pod 调度到这一节点上。
- 如果在剩余的 Taint 中没有 NoSchedule 效果,但是有 PreferNoSchedule 效果,则调度器会尝试不把这个Pod 指派给这个节点。
- 如果在剩余的 Taint 中有 NoExecute 效果,并且这个 Pod 已经在该节点上运行,则会被驱逐;如果没有在该节点上运行,则也不会再被调度到该节点上。
例如,我们这样对一个节点进行 Taint 设置:
$ kubectl taint nodes slave1 key1=value1:NoSchedule
$ kubectl taint nodes slave1 key1=value1:NoExecute
$ kubectl taint nodes slave1 key2=value2:NoSchedule
然后在 Pod 上设置两个 Toleration:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
这样的结果是该 Pod 无法被调度到 slave1 上,这是因为第3个 Taint 没有匹配的 Toleration。但是如果该 Pod 已经在 node1 上运行了,那么在运行时设置第3个 Taint,它还能继续在 node1 上运行,这是因为 Pod 可以容忍前两个 Taint。
一般来说,如果给 Node 加上 effect=NoExecute 的 Taint,那么在该 Node 上正在运行的所有无对应 Toleration的 Pod 都会被立刻驱逐,而具有相应 Toleration 的 Pod 永远不会被驱逐。不过,系统允许给具有 NoExecute 效果的 Toleration 加入一个可选的 tolerationSeconds 字段,这个设置表明 Pod 可以在 Taint 添加到 Node 之后还能在这个 Node 上运行多久(单位为s):
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
上述定义的意思是,如果 Pod 正在运行,所在节点都被加入一个匹配的 Taint,则这个 Pod 会持续在这个节点上存活 3600s 后被逐出。如果在这个宽限期内 Taint 被移除,则不会触发驱逐事件。
5)、污点常见的应用场景
Taint 和 Toleration 是一种处理节点并且让 Pod 进行规避或者驱逐 Pod 的弹性处理方式,下面列举一些常见的场景:
a、独占节点
如果想要拿出一部分节点专门给一些特定应用使用,则可以为节点添加这样的 Taint:
$ kubectl taint nodes nodename dedicated=groupName:NoSchedule
然后给这些应用的 Pod 加入对应的 Toleration。这样带有合适 Toleration 的 Pod 就会被允许同使用其他节点一样使用有 Taint 的节点。
通过自定义 Admission Controller 也可以实现这一目标。如果希望让这些应用独占一批节点,并且确保它们只能使用这些节点,则还可以给这些 Taint 节点加入类似的标dedicated=groupName,然后 Admission Controller需要加入节点亲和性设置,要求 Pod 只会被调度到具有这一标签的节点上。
b、具有特殊硬件设备的节点(GPU卡)
在集群里可能有一小部分节点安装了特殊的硬件设备(如GPU芯片),用户自然会希望把不需要占用这类硬件的 Pod排除在外,以确保对这类硬件有需求的 Pod 能够被顺利调度到这些节点。
可以用下面的命令为节点设置 Taint:
kubectl taint nodes nodename special=true:NoSchedule
kubectl taint nodes nodename special=true:PreferNoSchedule
然后在 Pod 中利用对应的 Toleration 来保障特定的 Pod 能够使用特定的硬件。
和上面的独占节点的示例类似,使用 Admission Controller 来完成这一任务会更方便。例如Admission Controller 使用 Pod 的一些特征来判断这些 Pod,如果可以使用这些硬件,就添加 Toleration 来完成这一工作。
要保障需要使用特殊硬件的 Pod 只被调度到安装这些硬件的节点上,则还需要一些额外的工作,比如将这些特殊资源使用 opaque-int-resource 的方式对自定义资源进行量化,然后在 PodSpec 中进行请求;也可以使用标签的方式来标注这些安装有特别硬件的节点,然后在 Pod 中定义节点亲和性来实现这个目标。
c、定义Pod驱逐行为,以应对节点故障(为Alpha版本的功能)
前面提到的 NoExecute 这个 Taint 效果对节点上正在运行的 Pod 有以下影响。
- 没有设置 Toleration 的 Pod 会被立刻驱逐。
- 配置了对应 Toleration 的 Pod,如果没有为 tolerationSeconds 赋值,则会一直留在这一节点中。
- 配置了对应 Toleration 的 Pod 且指定了 tolerationSeconds 值,则会在指定时间后驱逐。
Kubernetes从1.6 版本开始引入一个 Alpha 版本的功能,即把节点故障标记为 Taint(目前只针对 node unreachable 及 node not ready,相应的 NodeCondition Ready 的值分别为 Unknown 和 False)。激活TaintBasedEvictions 功能后(在 --feature-gates 参数中加入 TaintBasedEvictions=true),NodeController 会自动为 Node 设置 Taint,而在状态为 Ready 的 Node 上,之前设置过的普通驱逐逻辑将会被禁用。
注意:
在节点故障的情况下,为了保持现存的 Pod 驱逐的限速(rate-limiting)设置,系统将会以限速的模式逐步给Node 设置 Taint,这就能避免在一些特定情况下(比如 Master 暂时失联)大量的 Pod 被驱逐。这一功能兼容于tolerationSeconds,允许 Pod 定义节点故障时持续多久才被逐出。
例如,一个包含很多本地状态的应用可能需要在网络发生故障时,还能持续在节点上运行,期望网络能够快速恢复,从而避免被从这个节点上驱逐。
四、DaemonSet:特定场景调度
1、DaemonSet简介
DaemonSet用于管理集群中每个Node上仅运行一份Pod的副本实例,如图:
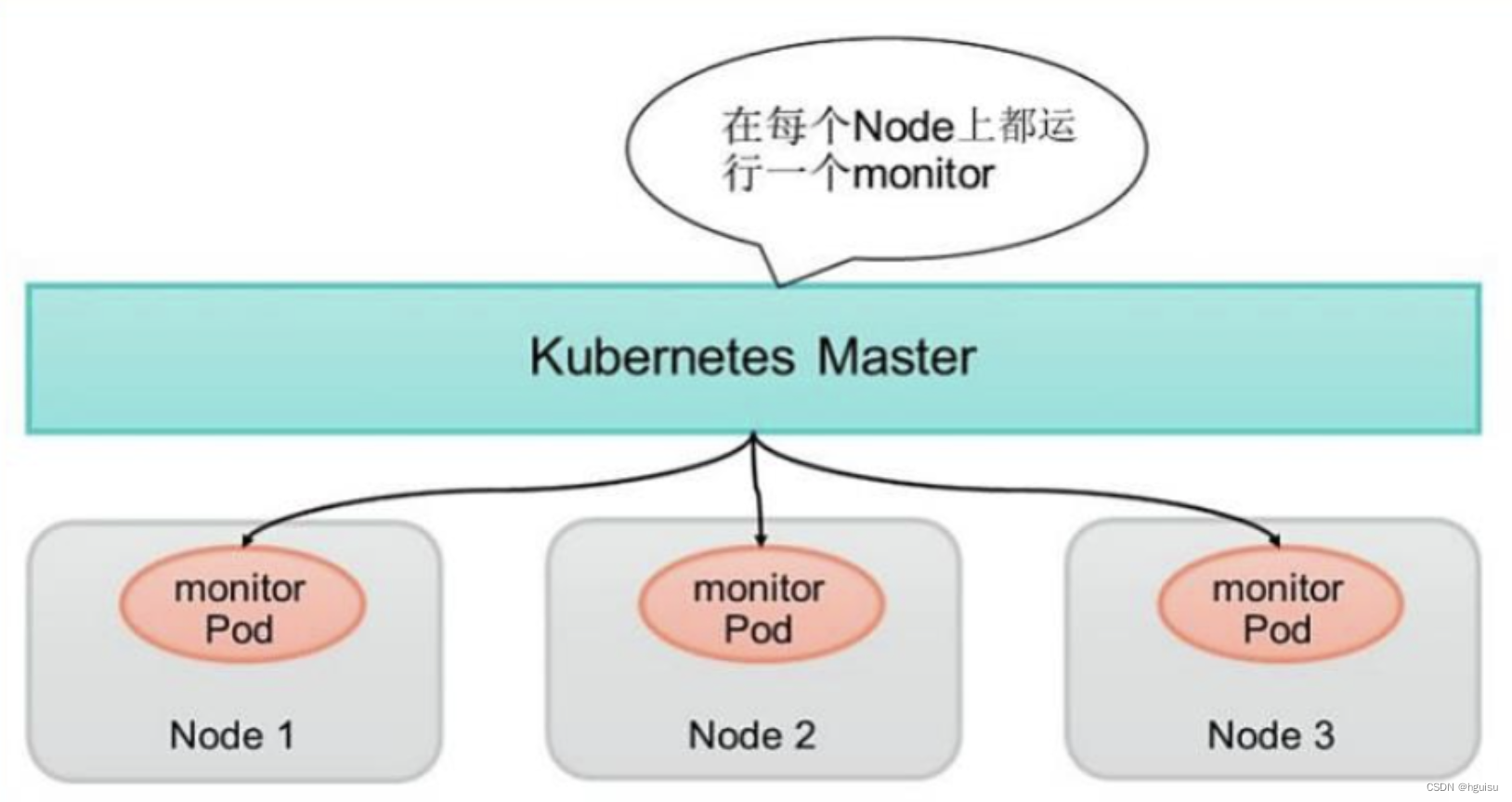
这种用法适合一些有下列需求的应用:
在每个Node上运行个以GlusterFS存储或者ceph存储的daemon进程
在每个Node上运行一个日志采集程序,例如fluentd或者logstach
在每个Node上运行一个健康程序,采集Node的性能数据。
DaemonSet的Pod调度策略类似于RC,除了使用系统内置的算法在每台Node上进行调度,也可以在Pod的定义中使用NodeSelector或NodeAffinity来指定满足条件的Node范围来进行调度。
2、调度例子:
例子定义了为在每个Node上都启动一个fluentd容器,配置文件 fluentd-ds.yaml的内容如下 (其中挂载了物理机的两个目录"/var/log"和 “/var/lib/docker/containers”):
Fluentd是一个用于统一日志层的开源数据收集器。Fluentd允许您统一数据收集和使用,以便更好地使用和理解数据。
- apiVersion: apps/v1
- kind: DaemonSet
- metadata:
- name: fluentd-cloud-logging
- namespace: kube-system
- labels:
- k8s-app: fluentd-cloud-logging
- spec:
- template:
- metadata:
- namespace: kube-system
- labels:
- k8s-app: fluentd-cloud-logging
- spec:
- containers:
- - name: fluentd-cloud-logging
- image: gcr.io/google containers/fluentd-elasticsearch:1.17
- resources:
- limits:
- cpu: 1000m
- memory: 2000Mi
- env:
- - name: FLUENTD ARGS
- value: -q
- volumeMounts
- - name: varlog
- mountPath: /var/log
- readOnly: false
- - name: containers
- mountPath: /var/lib/docker/containers
- readonly: false
- volumes:
- - name: containers
- hostPath:
- path: /var/lib/docker/containers
- - name: varlog
- hostPath:
- path: /var/log
使用kubectl create命令创建该DaemonSet:
kubectl create -f fluentd-ds.yaml 查看创建好的DaemonSet和Pod,可以看到在每个Node上都创建了一个。
kubectl get daemontset -n kube-system
3、DaemonSet 也能执行滚动升级
在 Kubernetes 1.6 以后的版本中,DaemonSet 也能执行滚动升级了,即在更新一个 DaemonSet 模板的时候,旧的 Pod 副本会被自动删除,同时新的 Pod 副本会被自动创建,此时 DaemonSet 的更新策略(updateStrategy)为 RollingUpdate,如下所示:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: goldpinger
spec:
updateStrategy:
type: RollingUpdate
updateStrategy 的另外一个值是 OnDelete,即只有手工删除了 DaemonSet 创建的 Pod 副本,新的 Pod 副本才会被创建出来。如果不设置 updateStrategy 的值,则在 Kubernetes 1.6 之后的版本中会被默认设置为RollingUpdate。
4、注意事项
DaemonSet调度不同于普通的Pod调度,所以没有用默认的Kubernetes Scheduler进行调度,而是通过专有的DaemonSet Controller进行调度。但是随着Kubernetes版本的改进和调度特性不断丰富,产生了一些难以解决的矛盾,最主要的两个矛盾如下:
普通的Pod是在Pending状态触发调度并被实例化的,DaemonSet Controller并不是在这个状态调度Pod的,这种不一致容易误导和迷惑用户;
Pod优先级调度是被Kubernetes Scheduler执行的,而DaemonSetController并没有考虑到Pod优先级调度的问题,也产生了不一致的结果。
从Kubernetes 1.8开始,DaemonSet的调度默认切换到Kubernetes Scheduler进行,从而一劳永逸地解决了以上问题及未来可能的新问题,因为默认切换到了Kubernetes Scheduler统一调度Pod,因此DaemonSet也能正确处理Taints和Tolerations的问题。
五、Job批处理调度
Kubernetes 从 1.2 版本开始支持批处理类型的应用,我们可以通过 Kubernetes Job 资源对象来定义并启动一个批处理任务。批处理任务通常并行(或者串行)启动多个计算进程去处理一批工作项(work item),处理完成后,整个批处理任务结束。
1、批处理任务模式
按照批处理任务实现方式的不同,批处理任务可以分为如下的几种模式:

Job Template Expansion 模式:
一个 Job 对象对应一个待处理的 Work item,有几个 Work item 就产生几个独立的 Job,通常适合 Work item 数量少、每个 Work item 要处理的数据量比较大的场景,比如有一个100GB 的文件作为一个 Work item,总共有 10 个文件需要处理。
Queue with Pod Per Work Item 模式:
采用一个任务队列存放 Work item,一个 Job 对象作为消费者去完成这些 Work item,在这种模式下,Job 会启动N个 Pod,每个 Pod 都对应一个 Work item。
Queue with Variable Pod Count 模式:
也是采用一个任务队列存放 Work item,一个 Job 对象作为消费者去完成这些 Work item,但与上面的模式不同,Job 启动的 Pod 数量是可变的。
有一种被称为 Single Job with Static Work Assignment 的模式,也是一个 Job 产生多个 Pod,但它采用程序静
态方式分配任务项,而不是采用队列模式进行动态分配,如下表所示是这几种模式的一个对比。

2、批处理类型
考虑到批处理的并行问题,Kubernetes 将 Job 分以下三种类型。
1)、Non-parallel Jobs
通常一个 Job 只启动一个 Pod,除非 Pod 异常,才会重启该 Pod,一旦此 Pod 正常结束,Job 将结束。
2)、Parallel Jobs with a fixed completion count
并行 Job 会启动多个 Pod,此时需要设定 Job 的 .spec.completions 参数为一个正数,当正常结束的 Pod 数量达至此参数设定的值后,Job 结束。此外,Job 的 .spec.parallelism 参数用来控制并行度,即同时启动几个 Job 来处理 Work Item。
3)、Parallel Jobs with a work queue
任务队列方式的并行 Job 需要一个独立的 Queue,Work item 都在一个 Queue 中存放,不能设置 Job的.spec.completions 参数,此时 Job 有以下特性。
- 每个Pod都能独立判断和决定是否还有任务项需要处理。
- 如果某个Pod正常结束,则Job不会再启动新的Pod。
- 如果一个Pod成功结束,则此时应该不存在其他Pod还在工作的情况,它们应该都处于即将结束、退出的状 态。
如果所有Pod都结束了,且至少有一个Pod成功结束,则整个Job成功结束。
3、批处理模型应用例子
下面分别讲解常见的三种批处理模型在 Kubernetes 中的应用例子。
首先是 Job Template Expansion 模式,由于在这种模式下每个 Work item 对应一个 Job 实例,所以这种模式首先定义一个 Job 模板,模板里的主要参数是 Work item 的标识,因为每个 Job 都处理不同的 Work item。如下所示的 Job 模板(文件名为 job.yaml )中的 $ITEM 可以作为任务项的标识:
apiVersion: batch/v1
kind: Job
metadata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox
command: ["sh", "-c", "echo Processing item $ITEM && sleep 5"]
restartPolicy: Never
通过下面的操作,生成了 3 个对应的 Job 定义文件并创建 Job:
[root@master cha3]# mkdir jobs
# job-execute.sh
#!/bin/bash
for i in apple banana cherry
do
cat job.yaml | sed "s/\$ITEM/$i/" > ./jobs/job-$i.yaml
done
[root@master cha3]# ./job-execute.sh
[root@master cha3]# ls jobs/
job-apple.yaml job-banana.yaml job-cherry.yaml
[root@master cha3]# kubectl create -f jobs
job.batch/process-item-apple created
job.batch/process-item-banana created
job.batch/process-item-cherry created
首先,观察Job的运行情况:
[root@master cha3]# kubectl get jobs -l jobgroup=jobexample
NAME COMPLETIONS DURATION AGE
process-item-apple 1/1 35s 46s
process-item-banana 1/1 8s 46s
process-item-cherry 1/1 38s 46s
[root@master cha3]# kubectl get pods
NAME READY STATUS RESTARTS AGE
process-item-apple-v4v9l 0/1 Completed 0 103s
process-item-banana-2bdfm 0/1 Completed 0 103s
process-item-cherry-z8ctp 0/1 Completed 0 103s
其次,我们看看Queue with Pod Per Work Item模式,在这种模式下需要一个任务队列存放Work item,比如RabbitMQ,客户端程序先把要处理的任务变成Work item放入任务队列,然后编写Worker程序、打包镜像并定义成为Job中的Work Pod。Worker程序的实现逻辑是从任务队列中拉取一个Work item并处理,在处理完成后即结
束进程。并行度为2的Demo示意图如图所示。

最后,我们看看Queue with Variable Pod Count模式,如图所示。

由于这种模式下,Worker程序需要知道队列中是否还有等待处理的Work item,如果有就取出来处理,否则就认为所有工作完成并结束进程,所以任务队列通常要采用Redis或者数据库来实现。
六、Cronjob:定时任务
Kubernetes 从 1.5 版本开始增加了一种新类型的 Job,即类似 Linux Cron 的定时任务 Cron Job,下
1、定义定时Cronjob。
首先,确保 Kubernetes 的版本为 1.8 及以上。
其次,需要掌握 Cron Job 的定时表达式,它基本上照搬了 Linux Cron 的表达式,区别是第1位是分钟而不是秒,
格式如下:
Minutes Hours DayofMonth Month DayofWeek Year
其中每个域都可出现的字符如下。
Minutes:可出现,、-、*、/ 这4个字符,有效范围为0~59的整数。
Hours:可出现,、-、*、/ 这4个字符,有效范围为0~23的整数。
DayofMonth:可出现,、-、*、/、?、L、W、C 这8个字符,有效范围为0~31的整数。
Month:可出现,、-、*、/ 这4个字符,有效范围为1~12的整数或JAN~DEC。
DayofWeek:可出现,、-、*、/、?、L、C、# 这8个字符,有效范围为1~7的整数或SUN~SAT。1
表示星期天,2表示星期一,以此类推。
表达式中的特殊字符*与/的含义如下。
*:表示匹配该域的任意值,假如在Minutes域使用*,则表示每分钟都会触发事件。
/:表示从起始时间开始触发,然后每隔固定时间触发一次,例如在Minutes域设置为5/20,则意味着第1次
触发在第5min时,接下来每20min触发一次,将在第25min、第45min等时刻分别触发。
比如,我们要每隔1min执行一次任务,则Cron表达式如下:
*/1 * * * *
2、Cron Job 的配置例子:
配置文件 032-cron.yaml 的内容为:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
该例子定义了一个名为 hello 的 Cron Job,任务每隔 1min 执行一次,运行的镜像是 busybox,执行的命令是Shell 脚本,脚本执行时会在控制台输出当前时间和字符串 Hello from the Kubernetes cluster。
直观地了解 Cron Job 定期触发任务执行的历史和现状:
kubectl get jobs --watch在 Kubernetes 1.9 版本后,kubectrl 命令增加了别名 cj 来表示 cronjob,同时 kubectl set image/env 命令也可以作用在 CronJob 对象上了。
七、自定义调度器
如果 Kubernetes 调度器的众多特性还无法满足我们的独特调度需求,则还可以用自己开发的调度器进行调度。从1.6 版本开始,Kubernetes 的多调度器特性也进入了快速发展阶段。
一般情况下,每个新 Pod 都会由默认的调度器进行调度。但是如果在 Pod 中提供了自定义的调度器名称,那么默认的调度器会忽略该 Pod,转由指定的调度器完成 Pod 的调度。
1、创建自定义的调度器
下面看看如何创建一个自定义的调度器。
可以用任何语言来实现简单或复杂的自定义调度器。下面的简单例子使用Bash脚本进行实现,调度策略为随机选择一个Node(注意,这个调度器需要通过kubectl proxy来运行):
# my-scheduler.sh
- #!/bin/bash
- SERVER='localhost:8001'
- while true;
- do
- for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName == "my-scheduler") | select(.spec.nodeName == null) | .metadata.name' | tr -d '"');
- do
- NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"'))
- NUMNODES=${#NODES[@]}
- CHOSEN=${NODES[$[ $RANDOM % $NUMNODES ]]}
- curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind": "Binding", "metadata": {"name": "'$PODNAME'"}, "target": {"apiVersion": "v1", "kind": "Node", "name":"'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
- echo "Assigned $PODNAME to $CHOSEN"
- done
- sleep 1
- done
[root@master ~]# kubectl proxy
Starting to serve on 127.0.0.1:8001
[root@master cha3]# ./my-scheduler.sh
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Success",
"code": 201
}Assigned nginx to slave2
2、pod指定调度器
在下面的例子中为 Pod 指定了一个名为 my-scheduler 的自定义调度器。
- apiVersion: v1
- kind: Pod
- metadata:
- name: nginx
- labels:
- app: nginx
- spec:
- schedulerName: my-scheduler
- containers:
- - name: nginx
- image: nginx
如果自定义的调度器还未在系统中部署,则默认的调度器会忽略这个 Pod,这个Pod 将会永远处于 Pending 状态。
[root@master cha3]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 44s
一旦这个自定义调度器成功启动,前面的 Pod 就会被正确调度到某个 Node 上。

