
- 1推荐使用:Home Assistant 操作系统
- 2【调试工具】UDP/TCP网络调试助手 NetAssist_udp调试助手
- 3一键换脸Roop与InstantID插件深入分析_ip-adapter.bin放置文件
- 4Kafka-日志收集分析平台搭建
- 5如何使用Python的Open3D开源库进行三维数据处理
- 6【C语言】常见的几种排序方式_c语言排序
- 7Python 实现将 Excel 数据绘制成精美图像_python读取excel画训练准确率变化图 美观
- 8Python爬虫入门 | 2 爬取豆瓣电影信息_考例题,在例题的基础上,创建一个爬虫程序,从虚拟电影网站爬取单张电影的图片,图片
- 9python基础之函数嵌套定义_python函数里面嵌套定义函数
- 10python编程求闰年_python打印2023年以后到2100年的所有闰年
文生图的基石CLIP模型的发展综述
赞
踩
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。
Open AI在2021年1月份发布的DALL-E和CLIP,这两个都属于结合图像和文本的多模态模型,其中DALL-E是基于文本来生成模型的模型,而CLIP是用文本作为监督信号来训练可迁移的视觉模型。
而Stable Diffusion模型中将CLIP文本编码器提取的文本特征通过cross attention嵌入扩散模型的UNet中,具体来说,文本特征作为attention的key和value,而UNet的特征作为query。也就是说CLIP其实是连接Stable Diffusion模型中文字和图片之间的桥梁。
CLIP
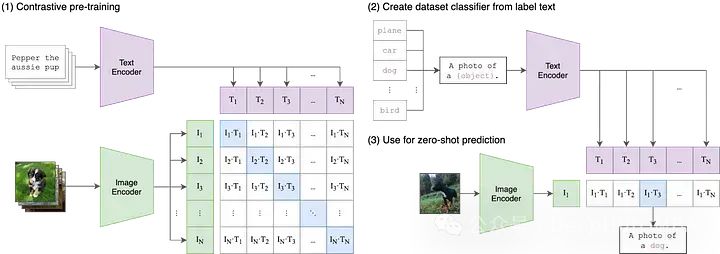
这是OpenAI在21年最早发布的论文,要想理解CLIP,我们需要将缩略词解构为三个组成部分:(1)Contrastive ,(2)Language-Image,(3)Pre-training。
我们先从Language-Image开始。
传统上,机器学习模型的架构是接受来自单一模式的输入数据:文本、图像、表格数据或音频。如果你想使用不同的模态来生成预测,则需要训练一个不同的模型。CLIP中的“Language-Image”指的是CLIP模型接受两种类型的输入:文本(语言)或图像。
CLIP通过两个编码器处理这些不同的输入-一个文本编码器和一个图像编码器。这些编码器将数据投影到较低维的潜在空间中,为每个输入生成嵌入向量。一个关键的细节是,图像和文本编码器都将数据嵌入到相同的空间中在原始的CLIP是一个512维向量空间。
Contrastive
在同一向量空间中嵌入文本和图像数据是一个开始,但就其本身而言,它并不能保证模型对文本和图像的表示可以进行有意义的比较。例如,在“狗”或“一张狗的照片”的文本嵌入与狗的图像嵌入之间建立一些合理且可解释的关系是有用的。但是我们需要一种方法来弥合这两种模式之间的差距。
在多模态机器学习中,有各种各样的技术来对齐两个模态,但目前最流行的方法是对比。对比技术从两种模式中获取成对的输入:比如一张图像和它的标题并训练模型的两个编码器尽可能接近地表示这些输入的数据对。与此同时,该模型被激励去接受不配对的输入(如狗的图像和“汽车的照片”的文本),并尽可能远地表示它们。CLIP并不是第一个图像和文本的对比学习技术,但它的简单性和有效性使其成为多模式应用的支柱。
Pre-training
虽然CLIP本身对于诸如零样本分类、语义搜索和无监督数据探索等应用程序很有用,但CLIP也被用作大量多模式应用程序的构建块,从Stable Diffusion和DALL-E到StyleCLIP和OWL-ViT。对于大多数这些下游应用程序,初始CLIP模型被视为“预训练”的起点,并且整个模型针对其新用例进行微调。
虽然OpenAI从未明确指定或共享用于训练原始CLIP模型的数据,但CLIP论文提到该模型是在从互联网收集的4亿对图像-文本上进行训练的。
https://arxiv.org/abs/2103.00020
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision

使用CLIP, OpenAI使用了4亿对图像-文本,因为没有提供细节,所以我们不可能确切地知道如何构建数据集。但是在描述新的数据集时,他们参考了谷歌的Google’s Conceptual Captions 作为灵感——一个相对较小的数据集(330万图像描述对,这个数据集使用了昂贵的过滤和后处理技术,虽然这些技术很强大,但不是特别可扩展)。
所以高质量的数据集就成为了研究的方向,在CLIP之后不久,ALIGN通过规模过滤来解决这个问题。ALIGN不依赖于小的、精心标注的、精心策划的图像字幕数据集,而是利用了18亿对图像和替代文本。
虽然这些替代文本描述平均而言比标题噪音大得多,但数据集的绝对规模足以弥补这一点。作者使用基本的过滤来去除重复的,有1000多个相关的替代文本的图像,以及没有信息的替代文本(要么太常见,要么包含罕见的标记)。通过这些简单的步骤,ALIGN在各种零样本和微调任务上达到或超过了当时最先进的水平。
https://arxiv.org/abs/2102.05918
K-LITE: Learning Transferable Visual Models with External Knowledge

与ALIGN一样,K-LITE也在解决用于对比预训练的高质量图像-文本对数量有限的问题。
K-LITE专注于解释概念,即将定义或描述作为上下文以及未知概念可以帮助发展广义理解。一个通俗的解释就是人们第一次介绍专业术语和不常用词汇时,他们通常会简单地定义它们!或者使用一个大家都知道的事物作为类比。
为了实现这种方法,微软和加州大学伯克利分校的研究人员使用WordNet和维基词典来增强图像-文本对中的文本。对于一些孤立的概念,例如ImageNet中的类标签,概念本身被增强,而对于标题(例如来自GCC),最不常见的名词短语被增强。通过这些额外的结构化知识,对比预训练模型在迁移学习任务上表现出实质性的改进。
https://arxiv.org/abs/2204.09222
OpenCLIP: Reproducible scaling laws for contrastive language-image learning
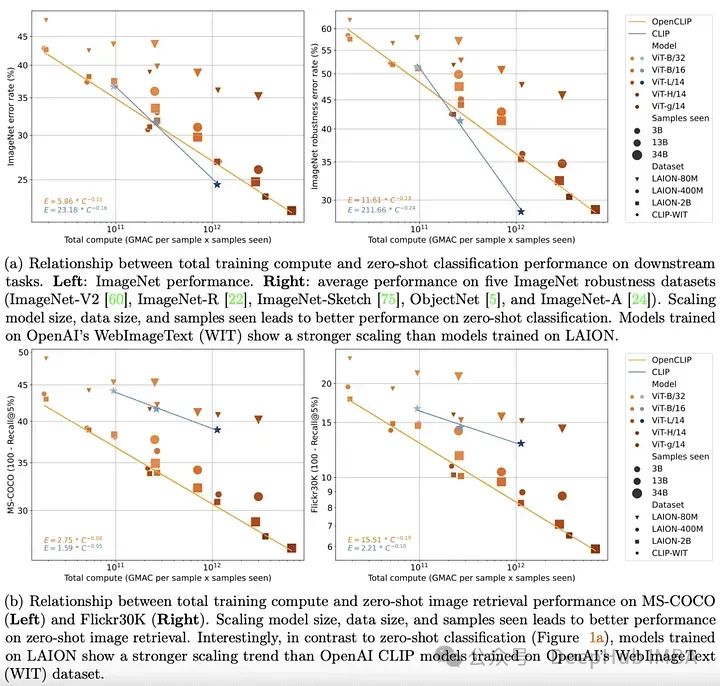
到2022年底,transformer 模型已经在文本和视觉领域建立起来。在这两个领域的开创性经验工作也清楚地表明,transformer 模型在单峰任务上的性能可以通过简单的缩放定律来很好地描述。也就是说随着训练数据量、训练时间或模型大小的增加,人们可以相当准确地预测模型的性能。
OpenCLIP通过使用迄今为止发布的最大的开源图像-文本对数据集(5B)将上面的理论扩展到多模式场景,系统地研究了训练数据对模型在零样本和微调任务中的性能的影响。与单模态情况一样,该研究揭示了模型在多模态任务上的性能在计算、所见样本和模型参数数量方面按幂律缩放。
比幂律的存在更有趣的是幂律缩放和预训练数据之间的关系。保留OpenAI的CLIP模型架构和训练方法,OpenCLIP模型在样本图像检索任务上表现出更强的缩放能力。对于ImageNet上的零样本图像分类,OpenAI的模型(在其专有数据集上训练)表现出更强的缩放能力。这些发现突出了数据收集和过滤程序对下游性能的重要性。
https://arxiv.org/abs/2212.07143
但是在OpenCLIP发布不久,LAION数据集因包含非法图像已从互联网上被下架了。
MetaCLIP: Demystifying CLIP Data
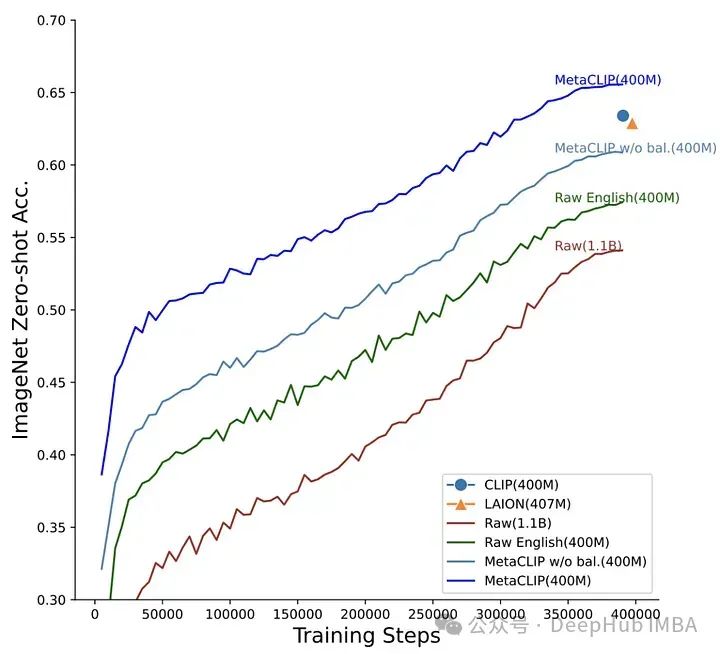
OpenCLIP试图理解下游任务的性能如何随数据量、计算量和模型参数数量的变化而变化,而MetaCLIP关注的是如何选择数据。正如作者所说,“我们认为CLIP成功的主要因素是它的数据,而不是模型架构或预训练目标。”
为了验证这一假设,作者固定了模型架构和训练步骤并进行了实验。MetaCLIP团队测试了与子字符串匹配、过滤和平衡数据分布相关的多种策略,发现当每个文本在训练数据集中最多出现20,000次时,可以实现最佳性能,为了验证这个理论他们甚至将在初始数据池中出现5400万次的单词 “photo”在训练数据中也被限制为20,000对图像-文本。使用这种策略,MetaCLIP在来自Common Crawl数据集的400M图像-文本对上进行了训练,在各种基准测试中表现优于OpenAI的CLIP模型。
https://arxiv.org/abs/2309.16671
DFN: Data Filtering Networks
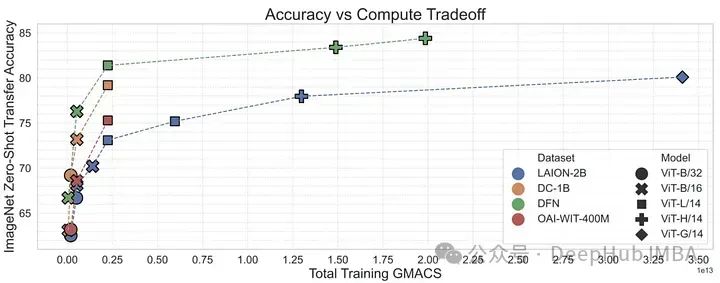
有了MetaCLIP的研究,可以说明数据管理可能是训练高性能多模态模型(如CLIP)的最重要因素。MetaCLIP的过滤策略非常成功,但它也主要基于启发式的方法。研究人员又将研究目标变为是否可以训练一个模型来更有效地进行这种过滤。
为了验证这一点,作者使用来自概念性12M的高质量数据来训练CLIP模型,从低质量数据中过滤高质量数据。这个数据过滤网络(DFN)被用来构建一个更大的高质量数据集,方法是只从一个未经管理的数据集(在本例中是Common Crawl)中选择高质量数据。在过滤后的数据上训练的CLIP模型优于仅在初始高质量数据上训练的模型和在大量未过滤数据上训练的模型。
https://arxiv.org/abs/2309.17425
总结
OpenAI的CLIP模型显著地改变了我们处理多模态数据的方式。但是CLIP只是一个开始。从预训练数据到训练方法和对比损失函数的细节,CLIP家族在过去几年中取得了令人难以置信的进步。ALIGN缩放噪声文本,K-LITE增强外部知识,OpenCLIP研究缩放定律,MetaCLIP优化数据管理,DFN增强数据质量。这些模型加深了我们对CLIP在多模态人工智能发展中的作用的理解,展示了在连接图像和文本方面的进步。
https://avoid.overfit.cn/post/c98007d44f244cb6b875df25d759065d
作者:Jacob Marks, Ph.D

