
- 1Linux基础知识 | 文件与目录大全讲解_linux 文件目录
- 2国科大 计算机学院 雁栖湖校区(研一上)_王偉強 ucas
- 3使用Pytorch从零实现Transformer模型_pytorch transformer
- 4立项管理-PMP_pmp立项
- 5【自然语言处理】基于 NLP 的电影评论情感分析模型比较_基于nlp的电影评论情感分析ppt
- 6博客目录管理 :机器学习 深度学习 nlp
- 7Docker - Android源码编译与烧写_docker编译android源码
- 8k8s的核心组件etcd功能详解【含etcd各类参数详细说明】
- 9git Your branch and xxx have diverged_your branch and have diverged
- 10通过鸿蒙开发者高级认证_应用包名不能包含一些保留字段以下哪个字段符合规范
基于深度神经网络的社交媒体用户级心理压力检测_基于深度学习的心理健康风险检测与分析
赞
踩
User-Level Psychological Stress Detection from Social Media Using Deep Neural Network
基于深度神经网络的社交媒体用户级心理压力检测
ABSTRACT
It is of significant importance to detect and manage stress before it turns into severe problems. However, existing stress detection methods usually rely on psychological scales or physiological devices, making the detection complicated and costly. In this paper, we explore to automatically detect individuals’ psychological stress via social media. Employing real online micro-blog data, we first investigate the correlations between users’ stress and their tweeting content, social engagement and behavior patterns. Then we define two types of stress-related attributes: 1) low-level content attributes from a single tweet, including text, images and social interactions; 2) user-scope statistical attributes through their weekly micro-blog postings, leveraging information of tweeting time, tweeting types and linguistic styles. To combine content attributes with statistical attributes, we further design a convolutional neural network (CNN) with cross autoencoders to generate user-scope content attributes from low-level content attributes. Finally, we propose a deep neural network (DNN) model to incorporate the two types of userscope attributes to detect users’ psychological stress. We test the trained model on four different datasets from major micro-blog platforms including Sina Weibo, Tencent Weibo and Twitter. Experimental results show that the proposed model is effective and efficient on detecting psychological stress from micro-blog data. We believe our model would be useful in developing stress detection tools for mental health agencies and individuals.
在压力变成严重问题之前,检测和管理压力具有重要意义。然而,现有的压力检测方法通常依赖于心理量表或生理装置,使得检测复杂且成本高昂。在本文中,我们探索通过社交媒体自动检测个人的心理压力。利用真实的在线微博数据,我们首先调查了用户压力与其推特内容、社交参与度和行为模式之间的相关性。然后,我们定义了两种与压力相关的属性:1)来自单个推特的低级内容属性,包括文本、图像和社交互动;2) 用户范围统计属性通过他们每周的微博帖子,利用推特时间、推特类型和语言风格的信息。为了将内容属性与统计属性相结合,我们进一步设计了一个带有交叉自动编码器的卷积神经网络(CNN),以从低级内容属性生成用户范围的内容属性。最后,我们提出了一个深度神经网络(DNN)模型,将两种类型的用户范围属性结合起来,以检测用户的心理压力。我们在新浪微博、腾讯微博和推特等主要微博平台的四个不同数据集上测试了训练后的模型。实验结果表明,该模型能够有效地检测微博数据中的心理压力。我们相信,我们的模型将有助于为心理健康机构和个人开发压力检测工具。
Keywords
Stress detection; convolutional neural network; cross auto encoders; deep learning; micro-blog; social media
应力检测;卷积神经网络;交叉自动编码器;深度学习;微博;社会化媒体
- INTRODUCTION
1.1 Motivation
Psychological stress is the root cause to many health problems and mental diseases. Chronic stress increases the risk of developing health problems such as insomnia, obesity, heart diseases, cancer etc. [1]. Many studies have revealed a link between stress and mental diseases like anxiety disorders, depression etc. [2]. Stress has been a threat to human health for a long time. Time magazine’s June 6, 1983 cover story called stress “The Epidemic of the Eighties” and referred to it as our leading health problem (http://www.stress.org/americas-1-healthproblem/). Meanwhile, stress has been progressively worsened and spread recent years. With the rapid development of modern society, many people feel increasingly stressed under the rapid pace of life. Numerous surveys have confirmed that adult Americans are feeling under much more stress than a decade or two ago. A 1996 Prevention magazine survey found that almost 75% feel they have “great stress” one day a week and with more than 30% indicating they feel this way more than twice a week, which is 55% compared to the same survey conducted in 1983 (http://www.anxietycentre.com/stress.shtml). In a word, the rapid increase of stress has become a great challenge to human health and life quality.
Psychological stress detection remains a large problem at the present stage. Detecting and managing stress before it turns into severe problems is of significant importance. Recent decades, many efforts have been devoted to stress detection by researchers from diverse areas. They have developed many methods to measure psychological stress, including psychological questionnaire based interviews [3, 4] and physiological signal based measures [5, 6]. However, these methods have their limitations in many aspects. Psychological questionnaires often contain a range of questions designed by psychologists. People are usually unwilling to do these questionnaires unless they have to. Physiological methods usually require professional devices to measure users’ physiological and biochemical properties and need specialists to analyze the acquired data. Thus, it is very important and useful to find a way to detect user’s stress state reliably, automatically and non-invasively.
With the fast development of social networks, people are widely using social media platforms to share their thoughts and feelings. A statistic report from statisticbrain.com (http://www.statisticbrain.com/twitter-statistics/) shows that by 2014.1.1, the total number of active registered users on Twitter has reached more than 645 million, with an average 58 million tweets posted per day. As for Sina weibo (the largest micro-blog platform in China), the number of weibo users has reached more than 600 million (http://www.comsoc.org/blog?page=3). People post tweets containing text and images on micro-blog platforms to share opinions, express emotions, record daily routines and communicate with friends. We can obtain linguistic and visual content that may indicate stress related symptoms. This makes the detection of users’ psychological stress through their tweets and posting patterns from micro-blog feasible.
1、引言
1.1动机
心理压力是许多健康问题和精神疾病的根源。慢性压力会增加患失眠、肥胖、心脏病、癌症等健康问题的风险[1]。许多研究揭示了压力与焦虑症、抑郁症等精神疾病之间的联系[2]。长期以来,压力一直威胁着人类健康。《时代》杂志1983年6月6日的封面故事将压力称为“80年代的流行病”,并将其称为我们的主要健康问题(http://www.stress.org/americas-1-health问题/)。与此同时,近年来压力逐渐恶化和蔓延。随着现代社会的快速发展,许多人在快速的生活节奏下感到越来越紧张。许多调查证实,美国成年人的压力比十年或二十年前大得多。1996年《预防》杂志的一项调查发现,近75%的人每周有一天感到“压力很大”,超过30%的人表示他们每周有两次以上有这种感觉,与1983年的调查相比,这一数字为55%(http://www.anxietycentre.com/stress.shtml). 总之,压力的快速增加已经成为对人类健康和生活质量的巨大挑战。
心理压力检测在现阶段仍然是一个大问题。在压力演变为严重问题之前检测和管理压力具有重要意义。近几十年来,来自不同领域的研究人员致力于压力检测。他们开发了许多测量心理压力的方法,包括基于心理问卷的访谈[3,4]和基于生理信号的测量[5,6]。然而,这些方法在许多方面都有其局限性。心理问卷通常包含心理学家设计的一系列问题。除非必须,否则人们通常不愿意做这些问卷调查。生理学方法通常需要专业设备来测量用户的生理和生化特性,并需要专家来分析获得的数据。因此,寻找一种可靠、自动和非侵入性地检测用户压力状态的方法是非常重要和有用的。
随着社交网络的快速发展,人们广泛使用社交媒体平台来分享自己的想法和感受。来自statisticbrain的统计报告(http://www.statisticbrain.com/twitter-statistics/)数据显示,截至2014年1月1日,推特上的活跃注册用户总数已超过6.45亿,平均每天发布5800万条推特。至于新浪微博(中国最大的微博平台),微博用户已经超过6亿(http://www.comsoc.org/blog?page=3). 人们在微博平台上发布包含文字和图像的推特,以分享意见、表达情感、记录日常生活并与朋友交流。我们可以获得可能指示压力相关症状的语言和视觉内容。这使得通过用户的推特和微博发布模式检测用户的心理压力成为可能。
1.2 Related Work
Existing methods for stress detection. Many efforts have been devoted to developing convenient tools for individual stress detection recent years. Researchers are trying to leverage pervasive devices like personal computers and mobile phones for routine stress detection. Hong L. etc. [7] proposed StressSense to unobtrusively recognize stress from human voice using smartphones. Paredes, P. etc. [8] investigated the initial lab evidence of the use of a computer mouse in the detection of stress. However, such applications rely on collecting one’s real-life data, which is easy to trigger antipathy. It makes stress detection invasive to normal life, and can’t be used widely in more people.
Researches on using social media for healthcare. With the rapid spread of social networks, researches on using social media data for physical and mental healthcare are also increasingly growing. Sadilek et al. [9] leverage Tweeter postings to identify the spread of flu symptoms. Paul M.J. etc. [10] apply the Ailment Topic Aspect Model to over 1.5 million health related tweets and discover correlations between behavioral risk factors and aliments. Munmun etc. [11] leverage behavioral cues indicated from Twitter postings to predict depression before it is reported. These studies show the feasibility of harnessing social media data for developing healthcare tools. However, they mainly leverage the textual content in the social media data, while other equally important content, like images and social behavior are ignored.
Deep learning approaches for cross-media data modeling. Micro-blog data is typical cross-media data. Items may come from diverse sources and modalities. It is difficult to handle the heterogeneous cross-media data. Recent years, extensive researches on deep learning show superior ability of deep neural networks (DNN) in learning features from large scale unlabeled data [12-14]. [15, 16] further extend the deep models for multimodal learning. [17] design a cross-media learning method based on DNN, and leverage the model for detecting psychological states and corresponding categories from a single tweet. However, stress is a continuous state compared to instant emotions, indicating that the stressed stated can last for several days in psychology [3]. It remains a challenge to make use of aggregated cross-media data for user-level modeling.
1.2相关工作
现有的应力检测方法。近年来,人们致力于开发方便的个人应力检测工具。研究人员正试图利用个人电脑和手机等普及设备进行日常压力检测。Hong L.等[7]提出了压力感知(StressSense),即使用智能手机从人声中隐秘地识别压力。Paredes,P.等[8]研究了使用电脑鼠标检测压力的初步实验室证据。然而,这些应用程序依赖于收集真实生活中的数据,这很容易引发反感。它使压力检测侵入了正常生活,无法在更多人中广泛应用。
利用社交媒体进行医疗保健的研究。随着社交网络的迅速普及,利用社交媒体数据进行身心健康的研究也越来越多。Sadilek等人[9]利用推特帖子识别流感症状的传播。Paul M.J.等[10]将疾病主题方面模型应用于150多万条健康相关推文,并发现行为风险因素与营养之间的相关性。Munmun等人[11]利用推特帖子中显示的行为线索,在抑郁症被报道之前预测它。这些研究表明了利用社交媒体数据开发医疗工具的可行性。然而,他们主要利用社交媒体数据中的文本内容,而忽略了其他同样重要的内容,如图像和社交行为。
跨媒体数据建模的深度学习方法。微博数据是典型的跨媒体数据。项目可能来自不同的来源和方式。异构跨媒体数据的处理比较困难。近年来,对深度学习的广泛研究表明,深度神经网络(DNN)在从大规模未标记数据中学习特征方面具有优越的能力[12-14]。[15,16]进一步扩展了多模式学习的深度模型。[17] 设计了一种基于DNN的跨媒体学习方法,并利用该模型从单个推文中检测心理状态和相应类别。然而,与即时情绪相比,压力是一种持续状态,这表明在心理学中,压力状态可以持续几天[3]。利用聚合的跨媒体数据进行用户级建模仍然是一个挑战。
1.3 Our Work
In this paper, we explore the potential to use social media to detect psychological stress for individuals. Micro-blog is one of the most popular social media that can be publicly accessed. People can post text with no more than 140 words, upload images or have social interactions with others. Employing real online micro-blog data, we first investigate the correlations between users’ stress and their tweeting content, behavior patterns and social engagement. Then we define two types of stress-related attributes: 1) low-level content attributes from a single tweet, including text, images and social interactions like comments, retweets and favorites; 2) userscope statistical attributes through their weekly micro-blog postings, leveraging information of tweeting time, tweeting types, linguistic styles, and social engagement with friends indicated from the @-mentions and @-replies, etc. To combine low-level content attributes with user-scope statistical attributes, we further design a convolutional neural network (CNN) with cross autoencoders to learn the latent high-level attributes on crossmodal units [17][18]. Finally, we propose a deep neural network (DNN) model to incorporate the two types of user-scope attributes to detect users’ psychological stress. The experimental results on four datasets from different Micro-blog platforms indicate the effectiveness and efficiency of the proposed method.
We have to face several challenges in this work. And the corresponding contributions are:
1)Challenge 1: Micro-blog platforms contain massive data. It is infeasible to manually label the data. How to find effective methods to automatically label the ground truth remains a challenge.
Our solution: Inspired by previous research [19], we have built a stressed-twitter-posting database using the “I feel stressed” sentence pattern as the ground-truth label for detecting stress from micro-blog data. With a small set of psychological stress scale score labeled dataset as test, it is proved that our ground truth labeling method is reliable;
2 ) Challenge 2: Attributes in a tweet come with multiple modalities and the components are often incomplete, which is a typical problem in cross-media. Numbers of tweets in a certain period of time also differ from person to person and from week to week. Traditional models have limited abilities to extract modality-invariant attributes from such data.
Our solution: We design a convolutional neural network with cross autoencoders to aggregate low-level content attributes and generate modality-invariant user-scope attributes which support user-level stress detection;
3)Challenge 3: Modeling stress in user-level is more difficult than in discrete tweet-level, since both the overview and detailed attributes should be concerned about.
Our solution: We propose a stress detection model based on DNN to incorporate content attributes and statistical attributes together. The DNN model along with CNN forms a unified integral deep network which can extract attributes from single tweets and detect user-level continuous psychological stress.
在本文中,我们探讨了使用社交媒体来检测个人心理压力的可能性。微博是最受欢迎的社交媒体之一,可以公开访问。人们可以发布不超过140个单词的文本,上传图像或与他人进行社交互动。利用真实的在线微博数据,我们首先调查了用户压力与其推特内容、行为模式和社交参与度之间的相关性。然后,我们定义了两种与压力相关的属性:1)来自单个推特的低级内容属性,包括文本、图像和社交互动,如评论、转发和收藏夹;2) 用户范围统计属性通过其每周的微博帖子,利用推特时间、推特类型、语言风格以及@提及和@回复中指示的朋友社交参与度等信息,将低级内容属性与用户范围统计属性相结合,我们进一步设计了一个带有交叉自动编码器的卷积神经网络(CNN),以学习交叉模态单元上的潜在高级属性[17][18]。最后,我们提出了一个深度神经网络(DNN)模型,将两种类型的用户范围属性结合起来,以检测用户的心理压力。在来自不同微博平台的四个数据集上的实验结果表明了该方法的有效性和效率。
在这项工作中,我们必须面对几个挑战。相应的贡献是:
1) 挑战1:微博平台包含大量数据。手动标记数据是不可行的。如何找到有效的方法来自动标记地面真相仍然是一个挑战。
我们的解决方案:受之前研究[19]的启发,我们建立了一个压力推特帖子数据库,使用“我觉得有压力”句型作为基本事实标签,从微博数据中检测压力。以一小部分心理应激量表分数标记数据集作为测试,证明了我们的地面真实值标记方法是可靠的;
2)挑战2:推文中的属性具有多种形式,并且组件通常不完整,这是跨媒体中的一个典型问题。在一段时间内,推特的数量也因人而异,也因周而异。传统模型从此类数据中提取模态不变属性的能力有限。
我们的解决方案是:我们设计了一个带有交叉自动编码器的卷积神经网络来聚合低级内容属性,并生成支持用户级压力检测的模态不变用户范围属性;
3) 挑战3:在用户级建模压力比在离散推特级建模压力更困难,因为应该关注概述和详细属性。
我们的解决方案:我们提出了一种基于DNN的压力检测模型,将内容属性和统计属性结合在一起。DNN模型与CNN一起形成了一个统一的整体深度网络,可以从单个推文中提取属性,并检测用户级的持续心理压力。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- DATA OBSERVATION
2.1 Observation dataset
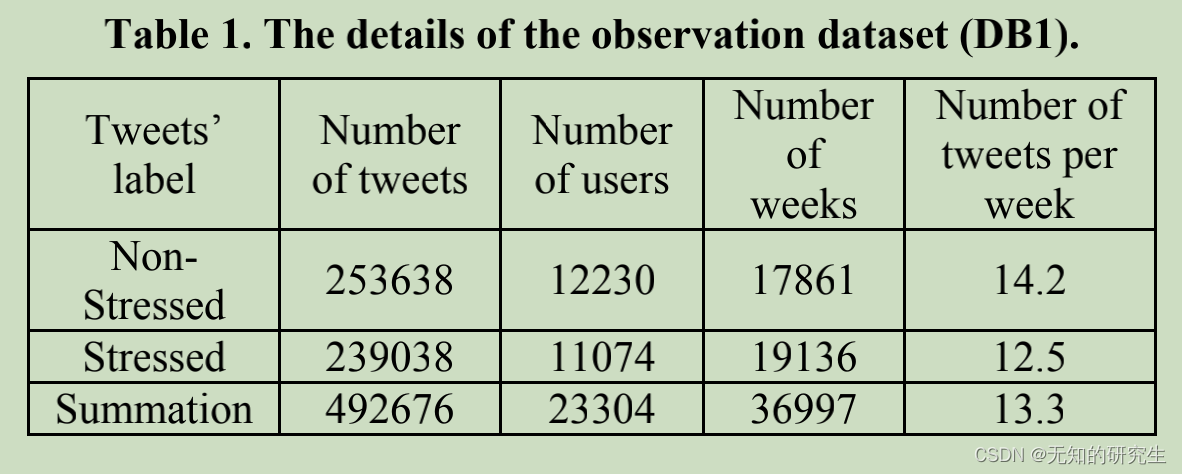
We first crawl 350 million tweets data via Sina Weibo’s streaming APIs from 2009.10 to 2012.10. Then we collect tweets containing sentence patterns like“I feel stressed this week” and “I feel stressed so much this week” as the weekly stressed state label, and tweets containing “I feel relaxed” and “I feel non-stressed” as the non-stressed state label. The “I feel” pattern has been proved to be effective as ground truth data labels in emotion analysis in [19]. In this way, we collect over 19000 weeks of users’ tweets that are labeled as stressed, and over 17000 weeks of non-stressed users’ tweets. There are 492,676 tweets from 23304 users in total. We take this dataset for observation and further experiments, which is represented by DB1 in this paper. The details of the dataset are shown in Table 1.
2、数据观察
2.1 观察数据集
从2009.10到2012.10,我们首先通过新浪微博的流媒体API抓取3.5亿条推文数据。然后,我们收集包含句型的推文,如“我本周感到有压力”和“我本周感到压力很大”作为每周压力状态标签,以及包含“我感觉放松”和“我感觉没有压力”作为非压力状态标签的推文。在[19]中,“我感觉”模式已被证明是情感分析中有效的基础真相数据标签。通过这种方式,我们收集了超过19000周的用户推文,这些推文被标记为有压力的推文,以及超过17000周的无压力用户推文。共有来自23304名用户的492676条推文。我们使用这个数据集进行观察和进一步的实验,在本文中用DB1表示。数据集的详细信息如表1所示。
2.2 Observation and analysis
We first conduct a series of analyses on the DB1 and present some patterns related to individuals’ psychological stress reflected by tweets. In the analysis, we randomly pick 1000 weeks of stressed and non-stressed tweets from the DB1 and focus on the following aspects:
Content correlation: the difference of stressed and nonstressed tweets in tweets’ content, including text and images;
Social engagement correlation: the difference between stressed and non-stressed weekly tweets on users’ social interactions with friends via @-mentions, @-replies and tweets’ comments, retweets and likes;
Behavioral correlation: the difference of stressed and nonstressed tweeting behavior in tweeting frequency, tweeting types and tweeting time.
2.2观察和分析
我们首先对DB1进行了一系列分析,并提出了一些与推特反映的个人心理压力相关的模式。在分析中,我们从DB1中随机选取1000周的有压力和无压力推文,重点关注以下方面:
内容相关性:强调和非强调推文在推文内容上的差异,包括文本和图像;
社交参与相关性:在用户通过@提及、@-回复和推特的评论、转发和喜欢与朋友的社交互动上,每周有压力和无压力的推特之间的差异;
行为相关性:压力和非压力推特行为在推特频率、推特类型和推特时间上的差异。
2.2.1 Observations on content correlation
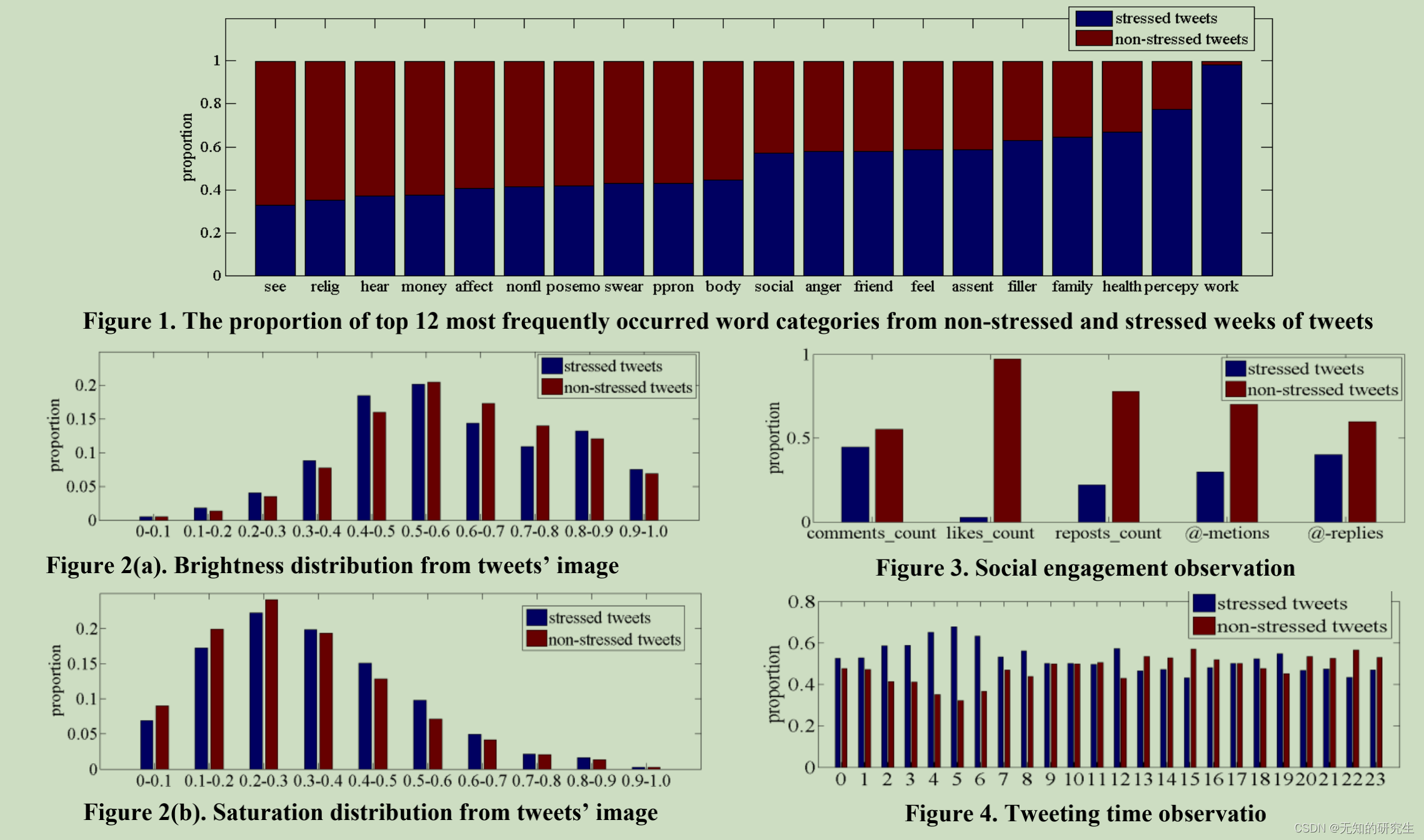
Tweets on micro-blog mainly consist of text and images. We leverage a widely used psychological dictionary LIWC [20] to measure the most frequently occurred words in stressed and nonstressed tweets text content. The results are shown in Figure 1. From the figure, we observe that there is evident difference in text content between the stressed and non-stressed tweets. For the stressed tweets, there are more words categories from negative emotions, social, friends and family etc. While for the nonstressed tweets, there exist more word categories from positive emotions, work, health and anxiety etc.
As for the image content of tweets, we consider brightness and saturation as observed visual features. The results are shown in Figure 2(a) and Figure 2(b). From Figure 2(a), we can observe that the presence of images with low brightness (<0.3) from stressed class is obviously higher than that from non-stressed class, indicating that stressed users are more likely to post images with lower brightness.
As for the saturation distribution in Figure 2(b), we observe that the saturation of non-stressed users’ images are more likely to be lower (<0.5), while the stressed class is more likely to be in the higher range (>0.5).
微博上的推文主要由文字和图片组成。我们利用广泛使用的心理词典LIWC[20]来测量重音和非重音推文文本内容中出现频率最高的单词。结果如图1所示。从图中,我们观察到重音推文和非重音推文之间的文本内容存在明显差异。对于有压力的推文,有更多来自负面情绪、社交、朋友和家人等的词类。而对于无压力的推文,有更多来自正面情绪、工作、健康和焦虑等的词类。
对于推文的图像内容,我们将亮度和饱和度视为观察到的视觉特征。结果如图2(a)和图2(b)所示。从图2(a)中,我们可以观察到,来自压力等级的低亮度图像(<0.3)明显高于来自非压力等级的图像,这表明压力用户更可能发布亮度较低的图像。
至于图2(b)中的饱和度分布,我们观察到,非压力用户图像的饱和度更可能较低(<0.5),而压力类别更可能处于较高范围(>0.5)。
2.2.2 Observations on social engagement correlation
Micro-blog is an important platform for users to share information and interact with friends. The social interactions on micro-blog usually consist of @-mentions, @-replies, retweets, comments and likes etc. We analyze the correlation between social interactions and users’ stress states.
Figure 3 shows the social interaction patterns from tweets of users in stressed and non-stressed states. The patterns are measured as the proportion of the numbers of comments, likes, retweets, @-mentions and @-replies in users’ weekly tweets.
From the figure, we observe that for the non-stressed class, users’ tweets get more comments, likes and retweets from friends, indicating that people are generally more likely to interact with the followed users when they are at a non-stressed state. Meanwhile, compared to non-stressed weeks, the stressed weeks have less @-mentions and @-replies of friends. This also proves that stressed users are less social active than non-stressed users.
2.2.2社会参与相关性观察
微博是用户分享信息、与朋友互动的重要平台。微博上的社交互动通常包括@提及、@-回复、转发、评论和喜欢等。我们分析了社交互动与用户压力状态之间的相关性。
图3显示了在压力和非压力状态下用户推特的社交互动模式。这些模式以用户每周推文中评论、赞、转发、提及和回复的数量所占的比例来衡量。
从图中,我们观察到,对于没有压力的类,用户的推文从朋友那里获得了更多的评论、赞和转发,这表明当用户处于没有压力的状态时,人们通常更容易与关注的用户进行互动。同时,与没有压力的一周相比,有压力的一周对朋友的提及和回复更少。这也证明了有压力的用户比没有压力的用户社交活跃度低。
2.2.3 Observations on Behavioral Correlation
As revealed by psychology theories [1], there are many common symptoms may be related to stress, including insomnia, social withdrawal .etc. These symptoms can also be reflected by tweeting behavior changes on micro-blog. We observe tweeting time distributions to measure users’ tweeting behavior.
Figure 4 shows the results of tweeting time distribution of users from the two classes. Tweeting time distribution is measured in tweet postings in hours of a day. From the result, we observe that there are more stressed postings during 0 to 6 in the morning, revealing that stressed users are more likely to be insomnia.
Summary To very briefly summarize, we have the following intuitions which will be further leveraged and incorporated in our method design:
The different content of a single tweet including text, image and social interactions are all related to different one’s stress state at some point.
One’s stress state can be related to the social engagement with friends in weekly unit.
One’s stress state can also be related to the tweeting behavior on micro-blog.
2.2.3行为相关性观察
心理学理论[1]揭示,有许多常见症状可能与压力有关,包括失眠、社交退缩等。这些症状也可以通过微博上的推特行为变化来反映。我们观察推特时间分布来衡量用户的推特行为。
图4显示了这两个类用户的推特时间分布结果。推特时间分布以每天的小时数在推特帖子中测量。从结果中,我们观察到,在早上0到点,有更多压力的帖子,表明有压力的用户更有可能失眠。
概括地说,我们有以下直觉,这些直觉将被进一步利用并纳入我们的方法设计中:
一条推文的不同内容,包括文本、图像和社交互动,在某些方面都与一个人的压力状态有关。
一个人的压力状态可能与每周与朋友的社交活动有关。
一个人的压力状态也可能与微博上的推特行为有关。
- ATTRIBUTES DEFINITION
The micro-blog data is a typical type of cross-media data, containing text, emoticons, images and social interactions. Besides, the patterns of micro-blog usage behavior in a period such as one week unit also contain useful information for stress detection. To leverage both content information contained in single cross-media micro-blog tweet and the micro-blog usage behavior in weekly tweets, guided by psychological theories, we define two sets of attributes to measure the differences of the stressed and non-stressed users on micro-blog: 1) content attributes from the content of a single tweet; 2) statistical attributes from the users’ behavior of weekly tweet postings.
3、属性定义
微博数据是一种典型的跨媒体数据,包含文本、表情、图像和社交互动。此外,微博使用行为在一周等时间段内的模式也包含了有用的压力检测信息。为了利用单个跨媒体微博推文中包含的内容信息和每周推文中的微博使用行为,在心理学理论的指导下,我们定义了两组属性来衡量压力和非压力用户在微博上的差异:1)来自单个推文内容的内容属性;2) 来自用户每周发布推文行为的统计属性。
3.1 Content Attributes
The content of a tweet from micro-blog usually consists of text, image and social interaction. We define linguistic, visual and social attributes from each part of a tweet respectively as follows:
- Linguistic Attributes:
As users usually express their emotions using tweets, we measure the emotions in a single tweet using linguistic attributes. To describe the linguistic attributes, we leverage a psychological dictionary named “Language Inquiry and Word Count Dictionary” [20]. The simplified Chinese LIWC dictionary [21] is developed by Chinese psychologists and linguists, based on the psycholinguistic dictionary LIWC (http://www.liwc.net), which has been proved to be effective on determining affect in Twitter. It is composed of almost 4500 words and categorized into over 60 categories [20].
Based on the dictionary, we define the text content related features as the tweet’s linguistic attributes:
Positive and Negative Emotion Words (2 dimension). Measured by the number of positive and negative emotion words in the tweet’s text, indicating how positive or negative emotions are expressed in the tweet.
Positive and Negative Emoticons (2 dimensions). Measured by the number of positive and negative emotions. Emoticons are widely used in micro-blog platforms to express users’ emotional states. We manually categorize the 129 emoticons provided by Sina Weibo platform into positive and negative categories.
Punctuation Marks and Associated Emotion Words (4 dimensions). We use this attribute to signify the intensity of emotion in a tweet, either positive or negative according to the associated emotional words. Four typical punctuation marks (exclamation mark, question mark, dot mark and the Chinese full stop mark “。”) are considered.
Degree Adverbs and Associated Emotion Words (2 dimensions). Degree adverbs are also used to express the degree of emotions. For example, “I feel a little bit sad” and “I feel terribly sad” express different level of negative feelings. We use a number range of 1-3 to represent neural, moderate and severe degrees of positive expression and the minus to represent the negative ones.
Thus, we get 10-dimensional vector to denote the linguistic attributes from a tweet’s text content.
- Visual Attributes:
Based on previous work on affective image classification [22] and color psychology theories [23], we combine the following features as the visual middle-level representation:
Five-color theme (15 dimensions): a combination of five dominant in the HSV color space, representing the main color distribution of an image. It has been revealed to have important impact on human emotions according to psychology and art theories [22].
Saturation (2 dimensions): the mean value of saturation and its contrast.
Brightness (2 dimensions): the mean value of brightness and its contrast.
Warm or cool color (1 dimension): ratio of cool colors with hue ([0-360]) in the HSV space between 30 and 110.
Clear or dull color (1 dimension): ratio of colors with brightness ([0-1]) and saturation less than 0.6.
Thus, based on the psychological studies and color theories, we finally get a 21 dimensional attributes from the tweet’s image content.
- Social Attributes:
Besides the text content and image content of a tweet, some additional features like comments, retweets and likes indicate the tweet’s social attention from one’s friends. They can also imply one’s stress state to some degree. We use the number of comments, retweets and likes of a tweet to measure the tweet’s social attention degree into social attributes. Thus, we get a 3-dimensional vector to represent the social attributes of a tweet.
3.1内容属性
微博推文的内容通常包括文本、图像和社交互动。我们分别从推特的每个部分定义语言、视觉和社会属性,如下所示:
1) 语言属性:
由于用户通常使用推文表达情感,我们使用语言属性测量单个推文中的情感。为了描述语言属性,我们利用了一个名为“语言查询和字数词典”[20]的心理词典。简体中文LIWC词典[21]是由中国心理学家和语言学家在心理语言学词典LIWC的基础上开发的(http://www.liwc.net)这已经被证明是有效的确定影响在推特。它由近4500个单词组成,分为60多个类别[20]。
基于字典,我们将文本内容相关特征定义为推特的语言属性:
积极和消极情绪词(2维)。通过推文文本中积极和消极情绪词的数量来衡量,表明积极或消极情绪在推文中的表达方式。
正面和负面表情(2个维度)。通过积极和消极情绪的数量来衡量。表情符号广泛应用于微博平台,表达用户的情感状态。我们手动将新浪微博平台提供的129个表情符号分为正面和负面两类。
标点符号和相关情感词(4个维度)。我们使用这个属性来表示推特中的情绪强度,根据相关的情绪词,可以是积极的,也可以是消极的。四种典型的标点符号(感叹号、问号、点号和中文句号)被考虑在内。
程度副词和相关情感词(2个维度)。程度副词也用来表达情绪的程度。例如,“我感到有点难过”和“我感到非常难过”表达了不同程度的消极情绪。我们使用1-3的数字范围来表示神经、中度和重度的阳性表达,使用负数来表示阴性表达。
因此,我们得到10维向量来表示推特文本内容的语言属性。
2) 视觉属性:
基于之前对情感图像分类[22]和颜色心理学理论[23]的研究,我们结合以下特征作为视觉中层表征:
五色主题(15个维度):HSV颜色空间中五种主要颜色的组合,代表图像的主要颜色分布。心理学和艺术理论表明,它对人类情感有重要影响[22]。
饱和度(2维):饱和度的平均值及其对比度。
亮度(二维):亮度及其对比度的平均值。
暖色或冷色(一维):HSV空间中色调([0-360])介于30和110之间的冷色比率。
透明或暗淡颜色(一维):亮度([0-1])和饱和度小于0.6的颜色的比率。
因此,基于心理学研究和色彩理论,我们最终从推特的图像内容中获得了21维属性。
3) 社会属性:
除了推文的文本内容和图像内容外,一些额外的功能,如评论、转发和喜欢,表明推文受到朋友的社会关注。它们也可以在某种程度上暗示一个人的压力状态。我们使用一条推文的评论、转发和赞数来衡量推文的社会关注度,将其转化为社会属性。因此,我们得到了一个三维向量来表示推特的社会属性。
3.2 Statistical Attributes
Statistical attributes are summarized from users’ tweets in a specific sampling period. We use one week as the sampling period in this paper. On one hand, psychological stress often results from cumulative events or mental states; on the other hand, users may express their chronic stress in a series of tweets rather than one. Appropriately designed statistical attributes can provide a macroscope of a user’s stress states, and avoid noise or missing data. We define statistical attributes from three aspects to measure the differences between stressed and non-stressed states based on users’ weekly tweet postings. The details of the statistical attributes are described as follows:
-
Social Engagement:
We consider 3 measures to characterize the social engagement from users’ weekly tweet postings: the @-mentions, @-replies and the retweets from a user’s friend. These three behaviors are the most commonly used ways to interact with friends on microblog platforms. Unlike the social attributes in a single tweet, the social engagement attributes are measured in numbers of @-mentions and @-replies in weekly tweet postings, indicating one’s social interaction activeness with friends. -
Behavioral Attributes:
We define a set of behavioral measures for users, including tweeting time and tweeting types, based on the weekly tweet postings. These measures are described as follows:
Tweeting time:
Tweeting time can indicate users’ daily routines at some point. We consider two measures that derive from the tweeting time information of tweets: tweeting frequency and tweeting time distribution. Tweeting frequency is measured in the average number of tweets posted in a day, while tweeting time distribution is measured in numbers of tweets posted in hours with a 24 dimensional vector.
Tweeting Type:
Users usually post tweets on micro-blog with diverse motivations, making the tweets to be presented in different types. We categorize users’ tweets into mainly four types: 1) image tweets (tweets containing images) 2) original tweets (tweets that are originally posted by tweets’ users) 3) information query tweets 4) information sharing tweets (tweets that contain outside hyperlinks). We use a 4 dimensional vector of the numbers of tweets in the above 4 types respectively to represent the tweeting type attribute.
- Linguistic Style:
We introduce measures to characterize linguistic styles in users’ weekly tweet postings using the psychological dictionary LIWC [20]. LIWC categorizes frequently-used words into more than 60 categories. We adapt 10 categories from LIWC that are related to daily life, social events, e.g.: personal pronouns, home, work, money, religion, death, health, ingestion, friends and family. We extract words from users’ weekly tweet postings and use a 10 dimensional vector of numbers of words in the 10 categories to represent the linguistic style attribute. Different from the linguistic attributes of a single tweet which mainly measures the emotions, the linguistic style can measure one’s linguistic behavior in aggregated tweets.
3.2统计属性
统计属性总结自特定采样期内用户的推文。本文以一周为采样周期。一方面,心理压力往往是由累积事件或心理状态引起的;另一方面,用户可能会通过一系列推文而不是一条推文来表达他们的长期压力。适当设计的统计属性可以提供用户压力状态的宏观范围,并避免噪音或丢失数据。我们从三个方面定义统计属性,根据用户每周发布的推文来衡量压力状态和非压力状态之间的差异。统计属性的详细信息描述如下:
1) 社会参与:
我们考虑了三种衡量用户每周推特帖子社交参与度的指标:提及@、回复@和用户朋友的转发。这三种行为是在微博平台上与朋友互动最常用的方式。与单个推文中的社交属性不同,社交参与属性是以每周推文帖子中@提及和@回复的数量来衡量的,表明一个人与朋友的社交互动活跃度。
2) 行为属性:
我们根据每周发布的推文,为用户定义了一组行为度量,包括推文时间和推文类型。这些措施描述如下:
推特时间:
推特时间可以指示用户在某个时刻的日常活动。我们考虑从推文的推文时间信息得出的两个度量:推文频率和推文时间分布。推文频率以一天内发布的平均推文数衡量,而推文时间分布则以24维向量以小时内发布的推文数衡量。
推文类型:
用户通常以不同的动机在微博上发布推文,使推文呈现出不同的类型。我们将用户的推文主要分为四类:1)图像推文(包含图像的推文)2)原始推文(最初由推文用户发布的推文)3)信息查询推文4)信息共享推文(包含外部超链接的推文)。我们分别使用上述4种类型中推文数量的四维向量来表示推文类型属性。
3) 语言风格:
我们使用心理词典LIWC[20]介绍了描述用户每周推特帖子中语言风格的方法。LIWC将常用词分为60多个类别。我们改编了LIWC中与日常生活、社会事件相关的10个类别,例如:人称代词、家庭、工作、金钱、宗教、死亡、健康、摄入、朋友和家人。我们从用户每周发布的推文中提取单词,并使用10个类别中单词数量的10维向量来表示语言风格属性。与单个推文的语言属性主要衡量情感不同,语言风格可以衡量聚合推文中的语言行为。
- MODEL AND LEARNING
4.1 Architecture
As described in section 3, we define low-level content attributes from each single tweet in tweet-scope, and statistical attributes from aggregated tweets in user-scope. In tweet-scope, we concern about the low-level content attributes of a single tweet as defined in Section 3.1, while in user-scope, we concern about one’s states reflected by several tweets in a period. These two sets of attributes cannot be combined directly since their mathematical descriptions are not in the same domain. So we need to generate latent userscope content attributes from low-level content attributes at first. After that, both of the two user-scope attribute sets, including the content attributes and statistical attributes, can be finally fed into a classifier for user-level stress detection.
In the following sections, we will address our solution through the following two key components: 1) First we design a convolutional neural network with cross autoencoders to generate user-scope content attributes from low-level content attributes, thus the tweet-scope content attributes can be combined with the userscope statistical attributes; 2) We propose a deep neural network model to incorporate the two types of user-scope attributes for user-level psychological stress detection.
4、建模与学习
4.1架构
如第3节所述,我们定义推特范围内每个推特的低级内容属性,以及用户范围内聚合推特的统计属性。在推特范围内,我们关注第3.1节中定义的单个推特的低级内容属性,而在用户范围内,我们关注一段时间内多条推特反映的个人状态。这两组属性不能直接组合,因为它们的数学描述不在同一个域中。因此,我们首先需要从低级内容属性生成潜在的用户范围内容属性。然后,两个用户范围属性集(包括内容属性和统计属性)最终都可以输入分类器,用于用户级压力检测。
在以下几节中,我们将通过以下两个关键组件来解决我们的解决方案:1)首先,我们设计了一个带有交叉自动编码器的卷积神经网络,从低级内容属性生成用户范围内容属性,因此推特范围内容属性可以与用户范围统计属性相结合;2) 我们提出了一种深度神经网络模型,将两种类型的用户范围属性结合起来,用于用户级心理压力检测。
- EXPERIMENTS
5.1 Experimental setup
Dataset. We perform our experiments on four datasets DB1-DB4 collected from three different micro-blog platforms: Sina Weibo, Tencent Weibo1, and Twitter. DB1 from Sina Weibo has the most number of tweets and users which has been described in Section 2, Table 1. The details of the other 3 datasets are shown in Table 3. The Tencent Weibo (DB3) and Twitter (DB4) are labeled using the sentence pattern method described in Section 2. Especially, to avoid the noise in data ground truth, we establish a small scale dataset DB2 from Sina Weibo. DB2 is collected from the users that have shared the score of a psychological stress scale2 with 50 items via Sina Weibo. If the resulted score is over 80, then the test subject is claimed to be stressed. We crawl the shared scores and the corresponding users’ information and weeks’ tweets. In this way, for DB2 we finally get 98 weeks of stressed tweets (scale score > 80) and 112 weeks of non-stressed tweets (scale score < 80) as a small but reliable ground truth data to further validate the reliability of the sentence pattern based ground truth labeling method.
In the following experiments, we first train and test our model on the large-scale Sina Weibo dataset DB1. Then we further test our model on the other 3 datasets to show effectiveness of the proposed model on different data sources or different ground truth labeling methods. For all of our analyses, we use 5-fold cross validation, over 10 randomized experimental runs.
Comparison Methods. We compare the following classification methods for user-level psychological stress detection:
Naive Bayes (NB) is a simple probabilistic classifier based on Bayes’ theorem that calculates the posterior probability by calculating prior probability of attributes. The classifier assigns sample with the largest calculated posterior [26].
Support Vector Machine (SVM) is a popular and binary classifier that is proved to be effective on a huge category of classification problems. It tries to find a hyperplane that divides training samples into their classes with maximum margin [27]. In our problem we use SVM with RBF kernel which can handle most nonlinear binary classifications better.
Random Forest (RF) is an ensemble learning method for decision trees by building a set of decision trees with random subsets of attributes and bagging them for classification results [28].
Deep Neural Network (DNN). The proposed model in this paper. We use a 4-layer DNN with a softmax classifier for the detection task. We also evaluate the influence of using different size of networks.
Measures. For a fully investigation of proposed methods, we consider the following aspects: Performance. To evaluate the detection performance of our method, we evaluate the results with Accuracy and F1-score.
By dividing user samples as stressed (positive) and nonstressed (negative) ones, detection results of testing data can be categorized into the following classes:
True Positive (TP): stressed user sample correctly detected (true) as stressed (positive).
False Negative (FN): stressed user sample incorrectly determined (false) as non-stressed (negative).
False Positive (FP): non-stressed user sample incorrectly detected (false) as stressed (positive).
True Negative (TN): non-stressed user sample correctly determined (true) as non-stressed (negative).
Accuracy is the proportion of correct prediction or true results among testing samples. More formally it is given by
5实验
5.1实验装置
数据集。我们在从三个不同的微博平台:新浪微博、腾讯微博和推特收集的四个数据集DB1-DB4上进行了实验。新浪微博DB1的推文和用户数量最多,如第2节表1所述。其他3个数据集的详细信息如表3所示。腾讯微博(DB3)和推特(DB4)使用第2节所述的句型方法进行标记。特别是,为了避免数据背景真实性中的噪声,我们从新浪微博建立了一个小规模的数据集DB2。DB2是从通过新浪微博分享了50个条目的心理压力量表2的用户中收集的。如果结果分数超过80分,则表明受试者承受了压力。我们抓取共享分数和相应用户的信息以及数周的推文。这样,对于DB2,我们最终得到98周的有压力推文(尺度分数>80)和112周的无压力推文(尺度分数<80),作为一个小但可靠的基础真理数据,以进一步验证基于句型的基础真理标记方法的可靠性。
在接下来的实验中,我们首先在大规模新浪微博数据集DB1上训练并测试了我们的模型。然后,我们在其他3个数据集上进一步测试了我们的模型,以证明所提出的模型在不同数据源或不同地面真值标记方法上的有效性。对于我们的所有分析,我们使用5倍交叉验证,超过10次随机实验运行。
比较方法。我们比较了以下用于用户级心理压力检测的分类方法:
朴素贝叶斯(NB)是一种基于贝叶斯定理的简单概率分类器,通过计算属性的先验概率来计算后验概率。分类器为样本分配最大的计算后验值[26]。
支持向量机(SVM)是一种流行的二进制分类器,已被证明对一大类分类问题有效。它试图找到一个超平面,将训练样本划分为具有 最大裕度的类[27]。在我们的问题中,我们使用带RBF核的支持向量机,它可以更好地处理大多数非线性二进制分类。
随机森林(RF)是一种决策树集成学习方法,通过构建一组具有随机属性子集的决策树,并将其打包以获得分类结果[28]。
深度神经网络(DNN)。本文提出的模型。我们使用带有softmax分类器的4层DNN进行检测任务。我们还评估了使用不同大小网络的影响。
措施。为了全面研究所提出的方法,我们考虑了以下几个方面:性能。为了评估我们方法的检测性能,我们使用准确性和F1分数来评估结果。
通过将用户样本分为应激(阳性)和非应激(阴性)样本,测试数据的检测结果可分为以下几类:
真阳性(TP):应力用户样本正确检测(真)为应力(阳性)。
假阴性(FN):应力用户样本错误地确定(假)为非应力(阴性)。
假阳性(FP):非应力用户样本被错误检测(假)为应力(阳性)。
真阴性(TN):无应力用户样本正确确定(真)为无应力(阴性)。
准确度是测试样本中正确预测或真实结果的比例。更正式的说法是
5.2 Detection Performance
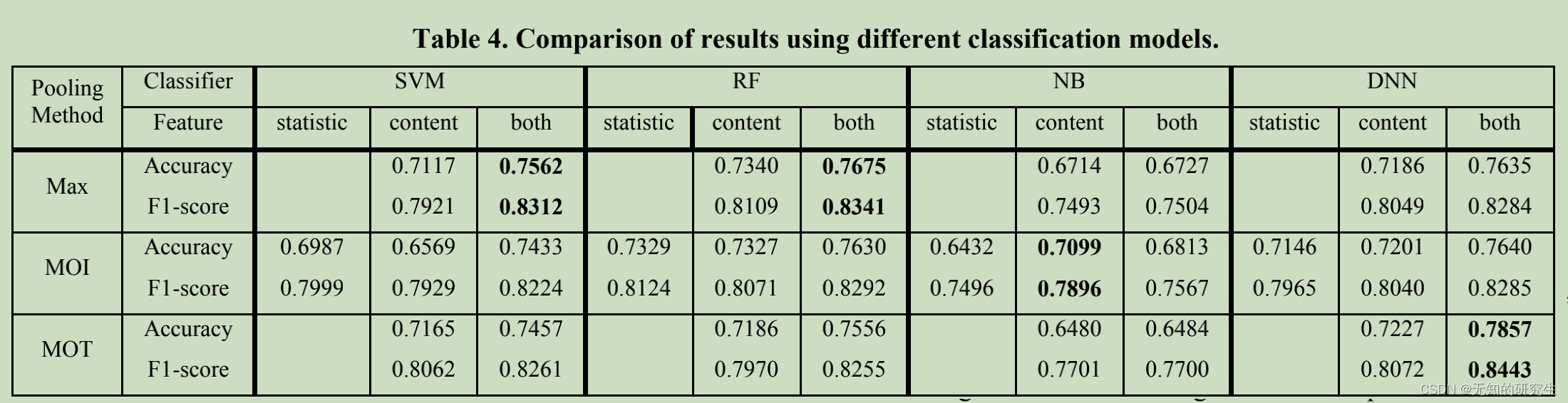
To evaluate the effectiveness of the proposed model, we first perform a fully test against large-scale DB1 from Sina Weibo. We consider working with statistical attributes and content attributes extracted by proposed CNN with CAE from cross-modal tweets data of a week respectively, and then using both of them together. For the pooling method, we also test the all three methods: max pooling, mean -over-instance (MOI) pooling and mean-over-time (MOT) pooling. For comprehensive comparisons, we test SVM, RF, NB as well as the proposed DNN as classifiers in this experiment. For this experiment, a 4-layer DNN is used.
Table 4 demonstrates the results of extensive experiments. Regarding different classifiers, SVM gets an accuracy of 75.62% and F1-score 0.8341 using both attributes together and max pooling. RF gets similar results where the accuracy is 76.75% and F1-score is 0.8341. NB does not work well with statistical attributes. It gets its best result working with content based attribute alone using MOI pooling. The proposed DNN classifier reaches the overall best performance with an accuracy of 78.57% and F1-score of 0.8443. Classification using two types of attributes together with MOT pooling outperforms all the baselines. It achieves a ~3% improvement over SVM and ~2% improvement over RF. When it works with the single type of attribute or other pooling methods it also get competitive results.
As for comparison with previous work, due to the different goal, our results are not comparable with [17]. Actually, the most related user-level prediction work is [11], with the best result of 74% for a binary choice. Our model can achieve a more compelling result of 84%.
5.2检测性能
为了评估所提出模型的有效性,我们首先对新浪微博上的大规模DB1进行了全面测试。我们考虑使用拟议的CNN和CAE分别从一周的跨模式推文数据中提取的统计属性和内容属性,然后将两者结合使用。对于池方法,我们还测试了这三种方法:最大池、实例平均(MOI)池和时间平均(MOT)池。为了进行综合比较,我们在本实验中测试了支持向量机、RF、NB以及提出的DNN作为分类器。在本实验中,使用了4层DNN。
表4显示了大量实验的结果。对于不同的分类器,同时使用属性和最大池,支持向量机的准确率为75.62%,F1得分为0.8341。RF得到了相似的结果,准确率为76.75%,F1分数为0.8341。NB与统计属性不匹配。使用MOI池单独使用基于内容的属性可以获得最佳效果。提出的DNN分类器达到了总体最佳性能,准确率为78.57%,F1分数为0.8443。使用两种类型的属性以及MOT池进行分类的性能优于所有基线。它比支持向量机提高了约3%,比射频提高了约2%。当它与单一类型的属性或其他池方法一起使用时,也会得到有竞争力的结果。
至于与之前工作的比较,由于目标不同,我们的结果与[17]不可比。实际上,最相关的用户级预测工作是[11],对于二进制选择,最佳结果为74%。我们的模型可以实现84%的更令人信服的结果。
5.4 Factor Contribution Analysis
Impact of content and statistical attributes: Table 4 also reveals the impact of two types of attributes. With solely statistical or content attribute, all classifiers get fair results around accuracy of 70%. While both types of attributes are used, there is a growth of about 5%. Trend of F1-score is similar that using both types of attributes provides a better result. These results show the effectiveness of combining both classes of attributes, which also prove that the proposed model is reliable for user-level stress detection.
Impact of pooling methods: Comparison results using max pooling, MOI pooling and MOT pooling are also shown in Table 4. We can see that MOT pooling gets an obvious better result working with DNN. When SVM or RF is considered, all three methods get similar results and max pooling is fractionally ahead in all three pooling methods. In summary, MOT is a better choice for high performance detection.
Impact of different modalities in content attributes: Tweets content come with multiple modalities. To evaluate the contribution of each data modality, we conduct experiments with different combination of attributes. Since text is the necessary part of a tweet, we test using solely text attributes, using combination of text and visual attributes, using combination of text and social attributes, as well as using all attributes.
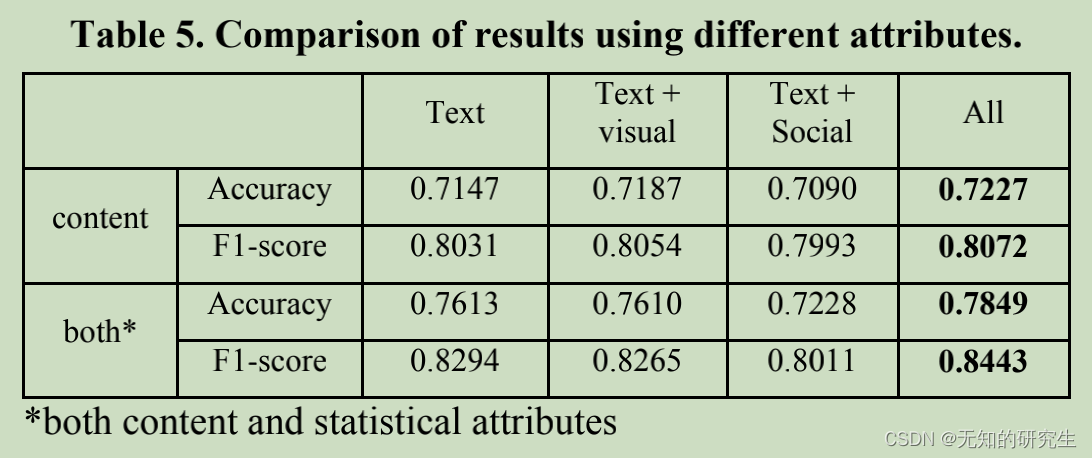
As shown in Table 5, we report predict performance of using content attributes (composed with only the named attributes in Table 5) alone as well as combining with statistical attributes. Using just text attribute gains rather high performance. Simply combining visual or social attributes even reduces the result, especially the social attributes. This trend is even more obvious when both types of attributes (content and statistical) are used. Nevertheless, using all attributes together outperforms using only text attributes. Highest detection performance is observed when using all attribute and working with both types of attributes.
Impact of scale of data. Model learning of the proposed CNN attributes extraction model with CAE is a key link of the whole framework. The model is trained in unsupervised scheme and takes advantage of large-scale unlabeled data. DNN classifier model also utilizes large-scale training data. We investigate the impact of data scale on training the network.
We measure the overall quality by final detection performance. In order to focus the discussion on neural network model, we evaluate with all attributes and only use content attributes. Figure 9 shows the trend of detection performance with different proportion of training data. In our case, the size of time series sets is the number of weeks. We pretrain with all data in DB1 (Table 1) and each filteris trained with roughly 1M patches when 100% data is used. We can see the advantage of using larger training set from the result.

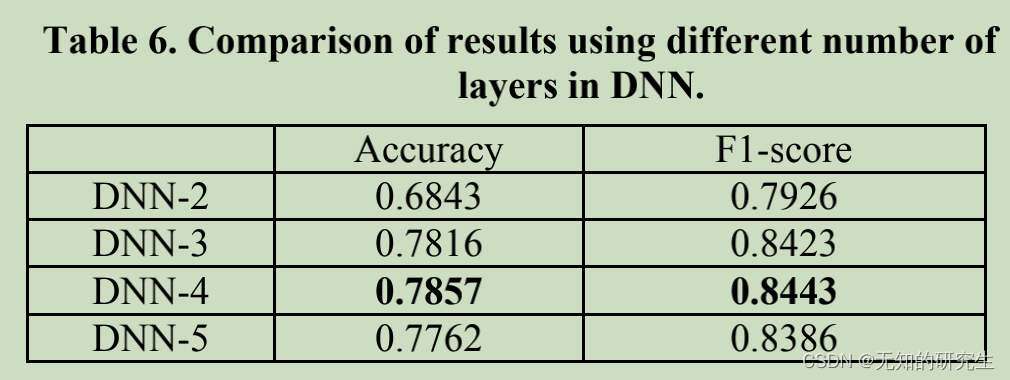
Impact of size of network. Size of network is a critical issue in setting up DNN model. Shallow networks result in trivial model that cannot catch any underlying correlation in data, whereas too deep networks lead to over-complex model which is difficult to tune and may suffer from problems like over-fitting. To choose an appropriate DNN model for classification, we test DNN with different number of layers.
Table 6 summarizes the experiment results. It is clear that 2-layer is not enough for the model to get a satisfactory result. 3-layer model improve significantly while 4-layer model reaches the peak. 5-layer model does not get better result. This is mainly due to the network is too large that it cannot be tuned to a good local minimum with available data and within a feasible training time.
5.4因素贡献分析
内容和统计属性的影响:表4还显示了两种类型属性的影响。仅使用统计或内容属性,所有分类器都可以获得大约70%的准确率。虽然使用了这两种类型的属性,但增长了约5%。F1得分的趋势相似,使用这两种类型的属性可以提供更好的结果。这些结果表明了将这两类属性相结合的有效性,这也证明了所提出的模型对于用户级压力检测是可靠的。
池方法的影响:使用最大池、MOI池和MOT池的比较结果也显示在表4中。我们可以看到,使用DNN时,MOT池的效果明显更好。当考虑支持向量机或RF时,这三种方法得到的结果相似,最大池在所有三种池方法中都略微领先。总之,MOT是高性能检测的更好选择。
不同模式对内容属性的影响:推特内容具有多种模式。为了评估每个数据模式的贡献,我们使用不同的属性组合进行了实验。由于文本是推特的必要部分,我们测试仅使用文本属性,使用文本和视觉属性的组合,使用文本和社交属性的组合,以及使用所有属性。
如表5所示,我们报告了单独使用内容属性(仅由表5中的命名属性组成)以及与统计属性相结合的预测性能。仅使用文本属性可以获得相当高的性能。简单地结合视觉或社会属性甚至会降低结果,尤其是社会属性。当使用两种类型的属性(内容和统计)时,这种趋势更加明显。然而,同时使用所有属性优于仅使用文本属性。当使用所有属性并使用这两种类型的属性时,可以观察到最高的检测性能。
数据规模的影响。利用CAE对提出的CNN属性提取模型进行模型学习是整个框架的关键环节。该模型在无监督方案中训练,并利用大规模未标记数据。DNN分类器模型还利用大规模训练数据。我们研究了数据规模对网络训练的影响。
我们通过最终检测性能来衡量整体质量。为了集中讨论神经网络模型,我们使用所有属性进行评估,并且仅使用内容属性。图9显示了不同训练数据比例下检测性能的趋势。在我们的例子中,时间序列集的大小是周数。我们用DB1(表1)中的所有数据进行预训练,当使用100%数据时,每个滤波器用大约1M个补丁进行训练。从结果中我们可以看出使用较大训练集的优势。
网络规模的影响。网络规模是建立DNN模型的关键问题。浅层网络导致琐碎的模型无法捕捉数据中的任何潜在相关性,而太深的网络则导致模型过于复杂,难以调整,并可能出现过拟合等问题。为了选择合适的DNN模型进行分类,我们测试了不同层数的DNN。
表6总结了实验结果。显然,2层模型不足以获得满意的结果。三层模型显著改善,而四层模型达到峰值。五层模型并没有得到更好的结果。这主要是由于网络太大,无法在可用数据和可行的训练时间内将其调整到良好的局部最小值。
5.5 Model Efficiency
For the classification models aforementioned, we also consider their efficiency performance. Though the training of model can be done offline, efficiency is still a considerable factor for evaluating an algorithm. For DNN model, we sum up both pre-training phase and finetuning phase. Table 7 lists the CPU time of each model to train with all labeled data. The results show that training DNN takes around 5 hours which is still reasonable while it get the best detection performance results.

5.5模型效率
对于上述分类模型,我们还考虑了它们的效率性能。虽然模型的训练可以离线完成,但效率仍然是评估算法的一个重要因素。对于DNN模型,我们总结了预训练阶段和微调阶段。表7列出了每个模型使用所有标记数据进行训练的CPU时间。结果表明,训练DNN大约需要5小时,这仍然是合理的,但它获得了最佳的检测性能结果。
5.6 Results on Other Datasets
We further evaluate our model on other datasets DB2-DB4 to show that our model is a universal model. For this part of experiments, we use statistical attributes together with content attributes using MOT pooling, and with 4-layer DNN model.
DB2 from Sina Weibo with PSTR label. We use a matured model trained with large scale Sina Weibo dataset, and then test it against another set of subject independently sampled from Sina Weibo. For the test set, we collect weekly tweets from the users that have shared the score of a psychological stress scale with 50 items via Sina Weibo. Detection result shows that the test accuracy is 74.13% and f1-score is 0.7778, which approves that the overall model is consistent and the sentence pattern based ground truth labeling method is reliable.
DB3 from Tencent Weibo. We test on data collected from another major Chinese Micro-blog platform. For this test, we use the attribute extractor trained with large scale Sina Weibo dataset and only finetune the network with Twitter dataset in 5-fold. The accuracy is 76.78% and f1-score is 0.7915 which demonstrate the capability of the proposed model.
DB4 from Twitter. We also test against the twitter dataset. We still use the attribute extractor trained with large scale Sina Weibo dataset and only finetune the network with Twitter dataset in 5-fold. The accuracy is 67.43% and f1-score is 0.7224. One reason for this modest result is that users in Twitter dataset and Sina Weibo dataset come from different language and culture background. Another factor could be that the scale of this dataset is rather small. Subjects in the Twitter dataset are on the order of 10% of large scale Sina Weibo dataset. We look into the collected data and find that, by coincidence, all tweets in this dataset have no social activity. We suggest this is also a cause of the unsatisfactory result.
5.6其他数据集的结果
我们在其他数据集DB2-DB4上进一步评估了我们的模型,以表明我们的模型是一个通用模型。在这部分实验中,我们使用统计属性和使用MOT池的内容属性,并使用4层DNN模型。
DB2来自新浪微博,带有PSTR标签。我们使用了一个用大规模新浪微博数据集训练的成熟模型,然后用从新浪微博上独立抽样的另一组主题进行测试。对于测试集,我们每周收集来自用户的推文,这些用户通过新浪微博分享了50个条目的心理压力量表分数。检测结果表明,测试准确率为74.13%,f1分数为0.7778,验证了整体模型的一致性和基于句型的地面真值标注方法的可靠性。
DB3来自腾讯微博。我们测试了从另一个主要的中国微博平台收集的数据。在这个测试中,我们使用了使用大规模新浪微博数据集训练的属性提取器,并且只使用推特数据集对网络进行了5倍的微调。精度为76.78%,f1分数为0.7915,证明了该模型的能力。
来自Twitter的DB4。我们还针对twitter数据集进行了测试。我们仍然使用用大规模新浪微博数据集训练的属性提取器,并且只使用推特数据集对网络进行5倍微调。准确率为67.43%,f1得分为0.7224。这一适度结果的一个原因是推特数据集和新浪微博数据集中的用户来自不同的语言和文化背景。另一个因素可能是该数据集的规模相当小。推特数据集中的主题约占新浪微博大规模数据集的10%。我们查看了收集的数据,发现巧合的是,这个数据集中的所有推特都没有社交活动。我们认为这也是结果不令人满意的原因之一。
- CONCLUSION
In this paper, we present a user-level psychological stress detection from users’ weekly micro-blog data. First we use the sentence patterns like “I feel stressed” to collect the ground truth labeled microblog data in week unit. Then we define a set of low-level content attributes from single tweet’s text, images and social interactions. We also present a variety of statistical attributes like behavioral attributes, social engagement and linguistic style attributes from users’ weekly tweet postings. A convolutional neural network with cross autoencoders is designed to aggregate weekly low-level content attributes and generate user-scope attributes. Finally we propose a deep neural network model to further learn higher-level attributes in user-scope and predict users’ stress. In our proposed method, the userscope attribute extractor and classification model forms a uniform deep architecture which bridges the gap between each single tweet and user’s psychological stress state. We test the model on four different datasets from major micro-blog platforms with different scales and ground truth labeling methods, and deeply discuss the influence of model parameters on experimental results. The results show that the proposed model is effective and efficient on detecting psychological stress from micro-blog data.
6、结论
本文提出了一种基于用户每周微博数据的用户级心理压力检测方法。首先,我们使用“我感到有压力”这样的句型,以周为单位收集标记为微博数据的基本事实。然后,我们从单个推文的文本、图像和社交互动中定义了一组低级内容属性。我们还提供了各种统计属性,如用户每周发布的推文中的行为属性、社交参与度和语言风格属性。设计了一种带有交叉自动编码器的卷积神经网络,用于聚合每周的低级内容属性并生成用户范围属性。最后,我们提出了一个深度神经网络模型,以进一步学习用户范围内的高级属性并预测用户的压力。在我们提出的方法中,用户范围属性抽取器和分类模型形成了一个统一的深层架构,它弥合了每条推特和用户心理压力状态之间的差距。我们使用不同的尺度和地面真值标记方法,在来自主要微博平台的四个不同数据集上测试了该模型,并深入讨论了模型参数对实验结果的影响。结果表明,该模型能够有效地检测微博数据中的心理压力。

![解决运行在微信小程序中报[ app.json 文件内容错误] app.json: app.json](https://img-blog.csdnimg.cn/a36884f0e7b44b94a13607806095f5e8.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

