
- 1Oracle物化视图(Materialized View)_oracle 物化视图
- 2基于FPGA的并行DDS设计
- 3python渗透工具编写学习笔记:9、web漏洞检测与利用脚本_python语言写网络渗透测试脚本
- 42024.5月更新大麦autojs代码,实现app端自动抢票_autojs 大麦
- 5AI辅写疑似度高风险?七招助你化险为夷!_论文ai风险高怎么解决
- 6Android Studio入门:Android应用界面详解(上)(View、布局管理器)_android studio的view
- 7腾讯后台开发一面(凉)_腾讯后端一面
- 8最新版IDEA(或Android Studio)Lombok的使用方法_android lombok
- 9Centos7防火墙与IPTABLES详解_centos7 iptables 和防火墙
- 10《动手学ROS2进阶篇》8.2RVIZ2可视化移动机器人模型_如何重装rviz2
云原生数据库Aurora两大特性_aurora数据库
赞
踩
什么是云原生数据库
云原生数据库指的是从设计之初便是为了在云环境中使用的数据库。 云原生数据库充分利用云技术,使得数据库的优势体现在资源池化和资源解耦上,不仅解决了传统数据库所存在的难扩展、难维护等问题,还为数据库的未来发展提供了更多解决方案。九河云将利用此篇文章阐述云原生数据库Aurora两大特性为何成为出海企业“神器”。
什么是 Aurora
Aurora 是 AWS 推出的 OLTP 云数据库先驱,在 MySQL 代码基础上改造出存储计算分离架构。由AWS完全托管的关系数据库引擎,与 MySQL和PostgreSQL兼容
Aurora核心特点:存储计算分离架构
Aurora 下推到存储的主要功能主要和 redo 相关,包括:日志回放、故障恢复和备份还原。技术层保留了查询处理、事务处理、缓存管理、锁管理、访问控制等大部分功能。
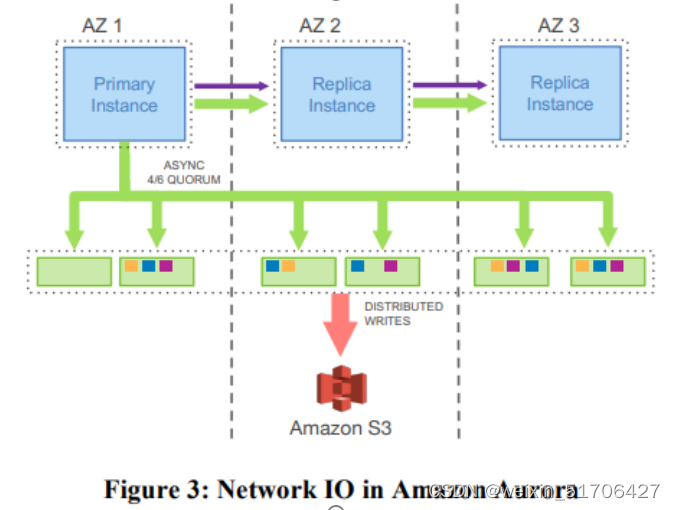
Aurora 的整体由跨 AZ 的一个主实例、多个副本(最多15个)实例及多个存储节点组成。主实例与只读实例/存储节点之间只传递 redo log 和元信息。主实例与副本实例共享一套分布式存储,因此增加副本实例是零存储成本的,这大大提高了 Aurora 的读扩展性。
主实例会异步向副本实例发送 redo log,副本实例收到后开始回放。如果日志对应的 page 不在 本地的 page cache,该 redo log 可以直接丢弃,因为存储节点拥有所有的 page 及 redo log,有需要时直接从存储节点请求即可。
存储节点收到 redo log 后会持久化,而回放日志和回收旧版本数据页的工作,可以一直异步在后台执行。存储节点可以较为灵活地分配资源做前台/后台的工作。同时相较于传统数据库,Aurora 不用后台去推进 checkpoint(这个动作往往会影响前台请求),分离的存储层不断地推进 checkpoint,对数据库实例丝毫没有影响,而且推进的越快,对读请求越有利。
存储层不断推进 checkpoint 也能加快故障恢复的速度,一般情况下,在 10w TPS 压力下,Aurora 可以在 10s 恢复完成。在故障恢复过程中,
Aurora 写流程如下: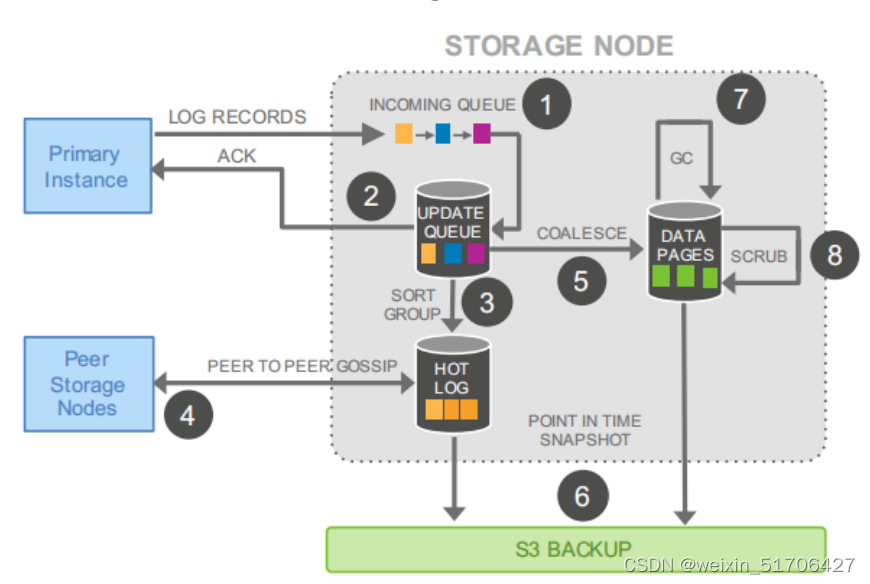
如图所⽰,涉及以下步骤:
(1) 接收⽇志记录并添加到内存队列中
(2) 将记录保留在磁盘上并确认
(3) 组织记录并识别⽇志中的间隙,因为某些批次可能会丢失,
(4) 与对等⽅进⾏闲聊以填补空⽩
(5)将⽇志记录合并到新的数据⻚中
(6) 定期将⽇志和新⻚⾯暂存到S3
(7) 定期对旧版本进⾏垃圾收集
(8) 定期验证⻚⾯上的CRC码
为了保证可用性,Aurora 持久化采用 Quorum 协议。假设复制集合包含 V 个节点,读请求需要得到 Vr 个节点响应,写请求需要得到 Vw 个节点详细,为了保证读写一致性,Quorum 协议主要有两个条件(1)Vr + Vw > V ;(2)Vw > V/2。
主实例的每次写入会发送到位于 3 个 AZ 的 6 个存储节点,收到 4 个持久化成功的回复便认为写入成功。因此 Aurora 的 Quorum 协议中,V = 6,Vw = 4,Vr = 3。当然在实际读请求中,不用真的去 3 个存储节点查询,只需要查询拥有最新数据的那个存储节点就行 。
Quorum 协议可以保证,只要 AZ 级别故障和节点故障不同时发生,数据库的可用性就能得到保证。同时 Aurora 采用分片管理的策略,每个分片 10G,6 个 10G 的副本组成一个 Protected Group,每个分片是一个故障恢复的单位,在 10G/s 网络下,一个分片可以在 10s 内恢复。因此只有当 10s 内同时发生超过2个分片的故障,可用性才会受到影响,这几乎是不可能发生的。
sysbench write only 测试,Aurora是基于镜像MySQL吞吐能力的35倍,每个事务的日志量比基于镜像MySQL日志量要少7.7倍。
Aurora 存储计算分离的架构给用户带来了什么好处?
- 前后台线程互不干扰,后台任务可以不停歇的异步执行。
- 更快的故障恢复时间
- 更高的可用性, Aurora存储计算分离架构支持多个计算实例连接到一个共享存储层。确保了在发生故障或需要进行维护时,可以无缝地进行切换到备用计算实例,从而提供了更高的数据库可用性和容错能力。
- 读副本、存储节点可线性扩展。
- 更好的性能,存储和计算可以分别进行扩展和优化。这意味着计算资源和存储资源可以独立地进行调整,以满足不同工作负载的需求。有助于提高数据库的性能和响应速度。
- 更低的成本,存储计算分离架构使得可以根据实际需要灵活地调整存储和计算资源,避免了购买过多的硬件资源,从而降低了成本。
Aurora核心特点: Global Database
Aurora Global Database 针对全球分布式应用程序而设计,允许单个 Amazon Aurora 数据库跨越多个 AWS 区域。它在不影响数据库性能的情况下复制数据,在每个区域中实现低延迟的快速本地读取,并且在发生区域级的中断时提供灾难恢复能力。
遍布全球的关键工作负载具有严格的可用性要求,可能需要容忍区域级中断。传统上,这需要在性能、可用性、成本和数据完整性之间进行艰难的权衡。Aurora 全球数据库使用基于存储的复制,典型延迟小于 1 秒,并使用让数据库完全可用于处理应用程序工作负载的专用基础设施。在不太可能发生区域性的性能下降或中断的情况下,可以在不到 1 分钟的时间内将其中一个辅助区域提升为具有读取和写入能力。
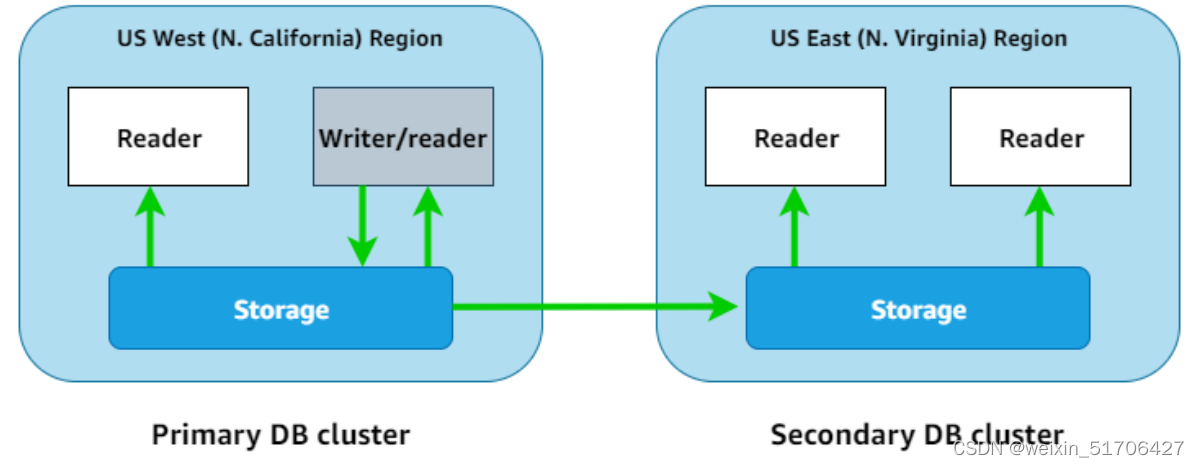
Aurora Global Database的优势
- 全局读取本地延迟,如果用户在世界各地设有办事处,则可以使用 Aurora Global Database在主AWS区域 保持主要信息来源为最新状态。其他区域的办事处可以访问各自区域中的信息,存在本地延迟。
- 可扩展辅助Aurora数据库集群,用户可以通过向辅助AWS区域添加更多只读实例(Aurora 副本)来扩展辅助集群,辅助集群为只读模式,因此它最多可以支持 16 个只读副本实例,而不符合单个集群通常15个此类副本的限制。
- 从主到辅助数据库集群快速复制,Aurora全局数据库执行的复制对主数据库集群造成的性能影响不大。数据库实例的资源完全专用于承担应用程序读取和写入工作负载。
- 从区域范围内的中断中恢复,辅助集群使用户能够比传统复制解决方案更快地(RTO 更低)在新的主AWS区域中使用Aurora Global Database,并且数据损失更少(RPO更低)。
Aurora 云原生数据库的先驱,首次将数据库的存储和计算能力分割,并且将部分数据库的能力下沉到存储节点,大大减少数据的传输量,从而提升性能和效率。对于想将业务扩展全球的客户来说,Aurora Global Database的特性更是出海客户的福音,可以轻松地将数据库读取扩展至世界范围,并使用户的应用程序部署在邻近用户的位置。无论辅助区域的数量和位置如何,客户应用程序都享受快速数据访问

