
- 1Manjaro的安装与配置_manjaro哪个桌面环境好
- 2PCB设计时铜箔厚度,走线宽度和电流的关系_2oz铜厚可以多少电流
- 3在Git存储库中查找并恢复已删除的文件_为什么推送到git远程仓库的文件会显示被delete了
- 4【vue-2】v-on、v-show、v-if及按键修饰符
- 5【AIGC调研系列】通义千问、文心一言、抖音云雀、智谱清言、讯飞星火的特点分析_通义千问和文心一言哪个更好用
- 6Host头攻击-使用加密和身份验证机制
- 7欠薪6个月:外包公司干(混)了4年,我决定换个活法
- 8数字温度传感器-DS18B20_ds18b20温度传感器csdn
- 9使用cloudreve搭建个人网盘
- 10idea所有子模块启动都出现Error:Kotlin: Module was compiled with an incompatible version of Kotlin.报错
MySQL-InnoDB(B+Tree)_mysql一个索引对应一个b+树
赞
踩
MySQL中有两种表级别的引擎:InnoDB和MyIsam.
现在最常用的就是InnoDB,那么就刨析一下:
InnoDB默认的索引数据结构就是B+Tree
B+Tree
从图中可以看出来,B+Tree的特点是:
盗的图↓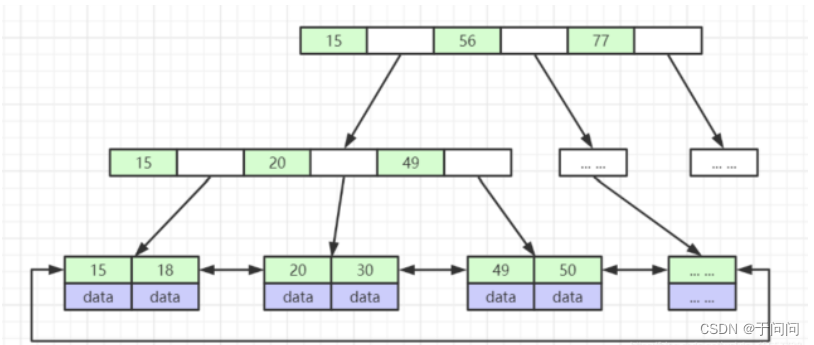
①:只有最底层的叶子节点储存数据
②:其他节点只存储下一层的节点地址
③:最底层的叶子节点具有双链表结构。
④:假设主键是BigInt类型,三层树高可容纳2000万条数据量
计算(1 Page=16k,BigInt=8Byte,空白地址=6Byte)
MAX H1 Count(第一层最大容纳索引数) 16000/8+6=1143
MAX H2 Count(第二层最大容纳索引数) 1143 * 1143 = 1306449
MAX H3 Count(第三层最大容纳索引数) (假设一条data为1k,索引和节点的忽略不计)
1306449 * 16=20903184条数据
想必上边这段公式在别的博文中可能抄的烂大街了(虽然是抄的,但确实言之有理)
B+Tree和B-Tree都是储存相同数据量,为啥B+Tree更快呢?
我一直有一个误区,一直以为B+Tree比B-Tree可以容纳更多的数据,其实并不是
B+Tree更快原因:相同树高的结构,B+Tree比B-Tree要储存的数据量多得多,树越矮遍历的速度越快,自然查询也就越快。
B-Tree:与B+Three不同的是,每个节点下面都挂着数据。
盗图
同样拿data为1k计算
三层树高的最大容量
MAX H1 Count(第一层最大容纳索引数) 16000/1000=16
MAX H2 Count(第二层最大容纳索引数) 16*16=256
MAX H3 Count(第三层最大容纳索引数) 256*16=4096
MAX H4 Count(第四层最大容纳索引数) 4096*16=65,536
MAX H5 Count(第五层最大容纳索引数) 65,536*16=1,048,576
MAX H6 Count(第六层最大容纳索引数) 1,048,576*16=16,777,216
结论:同样三层树高,B+Tree MAX=20903184,B-Three MAX=4096
如果B-Three要达到20903184得需要七层树高才能达到,效率之差,这也是B-Three被淘汰的原因
聚簇索引:
之前也有一个误区,就是以为所有的InnoD的B+树都是聚簇索引,这显然是错误的。
聚簇索引:数据和索引放在一个文件(InnoDB)——.ibd文件
mysql路径下InnoDB建表会有两个文件:.frm(表的结构数据),.ibd(索引和数据)
一张表只允许存在一个聚簇索引.
主键会默认创建聚簇索引.
如果表没有主键,InnoDB会选择一个唯一的非空索引代替.
如果没有这样的索引,InnoDB会隐式定义一个主键作为聚簇索引.
问自己一个问题:B+树所有的索引都是聚簇索引么?
看了大家互相抄袭的文章,我真就以为所有的索引都是聚簇索引了。
答案是否定的。(有主键的情况下)其原理是其他的索引(非主键索引)通过树结构找到最底层的叶子节点,而叶子节点储存的数据并不是该行的所有数据而是该行数据的主键,再拿到这个主键去主键索引树去找该行的所有数据,这个过程称之为回表。
假如寻找的是Alice这条数据,先是在非主键索引里的最底层节点找到该条的主键,再持有这个主键去主键索引树里边回表查询拿到该主键的所有数据

结论:知道这一个流程之后,就明白了,为什么极力推荐主键索引覆盖,因为其他索引需要回表也会影响性能
非聚簇索引:
聚簇索引:数据和索引放在不同文件(MyIsam)——.myd(数据).myi(索引)
MyIsam的树结构最底层的叶子节点存的不是数据而是数据在.myd的内存地址
继续盗图
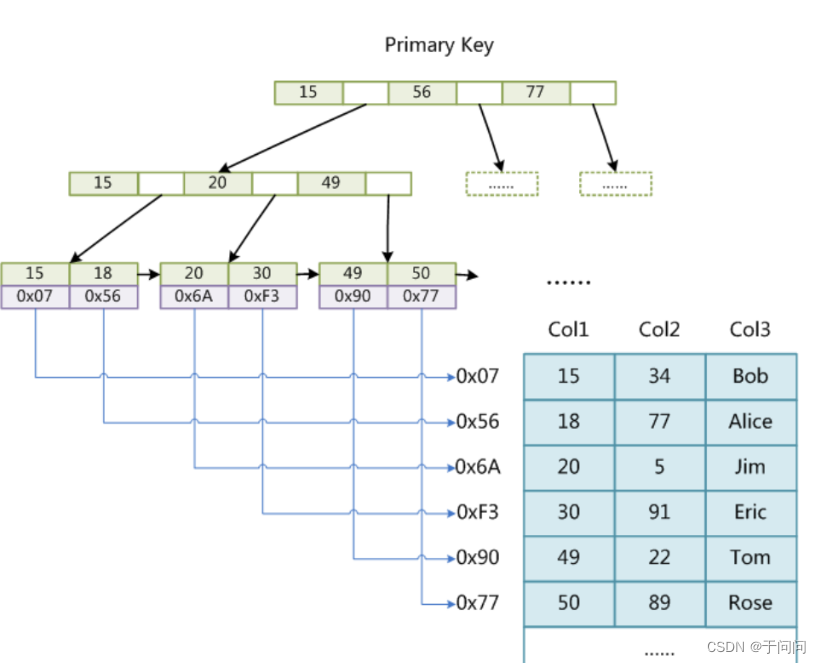
结论:无论如何,MyIsam的树结构都需要回表去找数据,这也是MyIsam效率低下和抛弃它的原因之一。

