
- 1webshell连接工具流量特征_webshell base64
- 2MapReduce计算手机流量案例_根据提示,在右侧编辑器补充代码,计算出每个手机号码的一年总流量。 main 方法已给
- 3华大基因肿瘤检测产品华甘宁:提高早期肝癌诊断率的利器!_华甘宁 无创肝癌基因检测
- 4TensorFlow中的模型迁移学习和模型微调_tensorflow 迁移学习
- 5OpenCV的Java开发介绍_为什么没有人用java做opencv
- 6Android-OCR识别文字_android ocr
- 7diffusers中的dreambooth的微调和lora微调_dreambooth和lora区别
- 8解决git clone 报错unable to access问题_git unable to access
- 9unity游戏云化后,暂停后游戏会继续执行问题解决_unity 暂停时间后还会转
- 10Android本地文件操作_android 选择本地文件
【论文翻译】Semantic Abstraction: Open-World 3D Scene Understanding from 2D Vision-Language Model【未完】_semantic exploration from language abstractions an
赞
踩
| Abstract: We study open-world 3D scene understanding, a family of tasks that require agents to reason about their 3D environment with an open-set vocabulary and out-of-domain visual inputs – a critical skill for robots to operate in the unstructured 3D world. Towards this end, we propose Semantic Abstraction (SemAbs), a framework that equips 2D Vision-Language Models (VLMs) with new 3D spatial capabilities, while maintaining their zero-shot robustness. We achieve this abstraction using relevancy maps extracted from CLIP, and learn 3D spatial and geometric reasoning skills on top of those abstractions in a semantic-agnostic manner. We demonstrate the usefulness of SemAbs on two open-world 3D scene understanding tasks: 1) completing partially observed objects and 2) localizing hidden objects from language descriptions. SemAbs can generalize to novel vocabulary for object attributes and nouns, materials/lighting, classes, and domains (i.e., real-world scans) from training on limited 3D synthetic data. | 摘要:我们研究开放世界3D场景理解,这是一个系列的任务,要求代理使用开放词汇和域外视觉输入来推理其3D环境的任务,这是机器人在非结构化3D世界中操作的关键技能。为此,我们提出了语义抽象(SemAbs),这是一个为2D视觉语言模型(vlm)提供新的3D空间能力的框架,同时保持其zero-shot鲁棒性。我们使用从clip中提取的关联图来实现这种抽象,并以语义不可知的方式在这些抽象的基础上学习3D空间和几何推理技能。我们证明了SemAbs在两个开放世界3D场景理解任务中的有用性:1)完成部分观察的对象和2)从语言描述中定位隐藏的对象。SemAbs可以从有限的3D合成数据的训练中归纳出用于对象属性和名词、材料/照明、类别和域(即,真实世界扫描)的新颖词汇。 |
| Keywords: 3D scene understanding, out-of-domain generalization, language | 关键词:三维场景理解,out-of-domain generalization,语言 |
1 Introduction
| To assist people in their daily life, robots must recognize a large, context-dependent, and dynamic set of semantic categories from their visual sensors. However, if their 3D training environment contains only common categories like desks, office chairs, and book shelves, how could they represent and localize long-tail objects, such as the "used N95s in the garbage bin" (Fig 1)? | 为了在日常生活中帮助人们,机器人必须从它们的视觉传感器中识别大量的、上下文相关的、动态的语义类别。然而,如果他们的3D训练环境只包含常见的类别,如桌子、办公椅和书架,他们如何表示和定位长尾对象,如“垃圾箱中用过的N95”(图1)? |
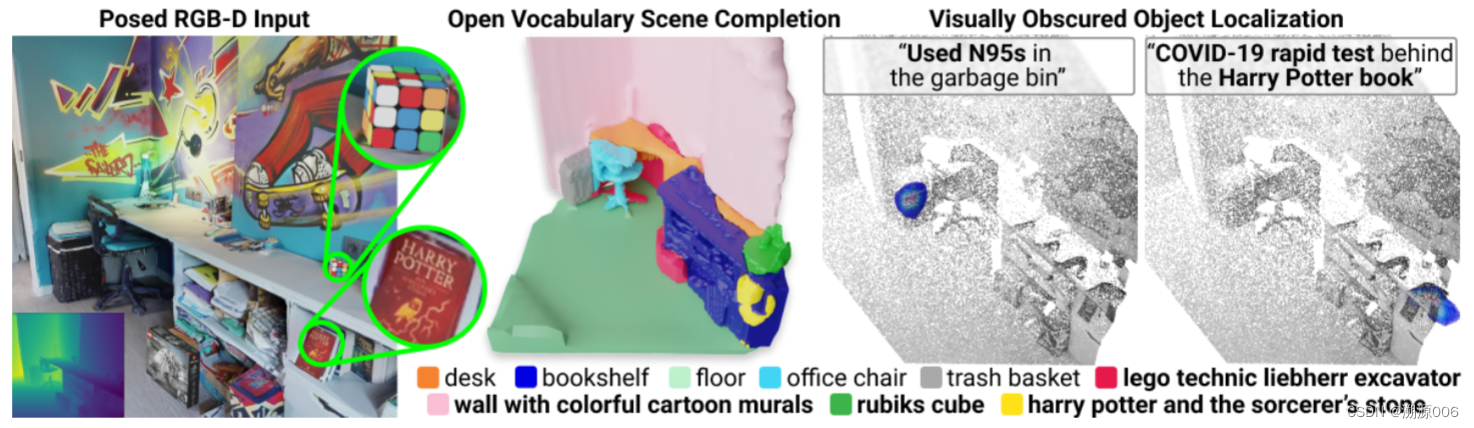
Figure 1: Open-World 3D Scene Understanding. Our approach, Semantic Abstraction, unlocks 2D VLM's capabilities to 3D scene understanding. Trained with a small simulated data, our model generalizes to unseen classes in a novel domain (i.e., real world scans), from small objects like "rubiks cube", to long-tail concepts like "harry potter", to hidden objects like the "used N95s in the garbage bin".
图1:开放世界3D场景理解。我们的方法——语义抽象——释放了2D·VLM在3D场景理解的能力。通过一个小的模拟数据训练,我们的模型可以推广到一个新领域(即真实世界扫描)中的未知类别,从“魔方”这样的小对象,到“哈利·波特”这样的长尾概念,再到“垃圾箱中用过的N95s”这样的隐藏对象。
| This is an example of an open-world 3D scene understanding task (Fig. 2), a family of 3D vision-language tasks which encompasses open-set classification (evaluation on novel classes) with extra generalization requirements to novel vocabulary (i.e., object attributes, synonyms of object nouns), visual properties (e.g. lighting, textures), and domains (e.g. sim v.s. real). The core challenge in such tasks is the limited data: all existing 3D datasets [1–6] are limited in diversity and scale compared to their internet-scale 2D counterparts [7–9], so training on them does not prepare robots for the open 3D world. | 这是一个开放世界3D场景理解任务的例子(图2),这是一个3D视觉语言任务系列,该系列就是针对不同的泛化需求-----新的词汇(即对象属性,对象名词的同义词)、新的视觉属性(例如照明,纹理)以及新的domain(例如sim v.s. real)----的开放集分类(对新类的评估)。此类任务的核心挑战是数据有限:与互联网规模的2D数据集[7-9]相比,所有现有的3D数据集[1-6]在多样性和规模上都受到限制,因此对它们的训练并不能为开放的3D世界准备机器人。 |
| On the other hand, large-scale 2D vision language models (VLM) [7–11] have demonstrated impressive performance on open-set image classification. Through exposure to many image-caption pairs from the internet, they have acquired an unprecedented level of robustness to visual distributional shifts and a large repertoire of visual-semantic concepts and vocabulary. However, fine-tuning these pretrained models reduces their open-set classification robustness [7, 10, 12, 13]. Compared to internet-scale image-caption data, the finetuning datasets, including the existing 3D datasets [1–6], show a significant reduction in scale and diversity, which causes finetuned models to become task-specialized and lose their generality. Hence, we investigate the following question: How can we equip 2D VLMs with new 3D capabilities, while maintaining their zero-shot robustness? | 另一方面,大规模2D视觉语言模型(VLM)[7-11]在开集图像分类方面表现出令人印象深刻的性能。通过接触互联网上的许多图像标题对,他们已经获得了前所未有的视觉分布变化的鲁棒性,以及大量的视觉语义概念和词汇。然而,微调这些预训练模型会降低其开放集分类鲁棒性[7,10,12,13]。与互联网规模的图像标题数据相比,微调数据集(包括现有的3D数据集[1-6])显示出规模和多样性的显着减少,这导致微调的模型变得特定于任务并失去其通用性。因此,我们调查以下问题: 我们如何为 2D VLM 配备新的 3D 功能,同时保持其zero-shot稳健性? |
| We propose Semantic Abstraction (SemAbs), a framework for tackling visual-semantic reasoning in open-world 3D scene understanding tasks using 2D VLMs. We hypothesize that, while open-world visual-semantic reasoning requires exposure to internet-scale datasets, 3D spatial and geometric reasoning is tractable even with a limited synthetic dataset, and could generalize better if learned in a semantic-agnostic manner. For instance, instead of learning the concept of "behind the Harry Potter book", the 3D localization model only needs to learn the concept of "behind that object". | 我们提出了语义抽象(SemAbs),这是一个使用2D VLM在开放世界3D场景理解任务中处理视觉语义推理的框架。我们假设,虽然开放世界的视觉语义推理需要接触互联网规模的数据集,但即使使用有限的合成数据集,3D 空间和几何推理也是可以处理的,如果以语义不可知的方式学习,可以更好地泛化。例如,3D定位模型不需要学习“哈利波特书后面”的概念,只需要学习“那个物体后面”的概念。 |

Figure 2: Open-world generalization requirements can build on top of each other, forming tiers of open-worldness (distinct property of each tier outlined yellow).
图2:开放世界的泛化需求可以建立在彼此之上,形成开放世界的层次(每层的不同属性用黄色标出)。
图 2:开放世界的泛化需求可以相互叠加,形成开放世界的层次(每一层的不同属性用黄色勾勒出来)。
| To achieve this abstraction, we leverage the relevancy maps extracted from 2D VLMs and used them as the "abstracted object" representation that is agnostic to their semantic labels. The SemAbs module factorizes into two submodules: 1) A semantic-aware wrapper that takes an input RGB-D image and object category label and outputs the relevancy map of a pre-trained 2D VLM model (i.e., CLIP [7]) for that label, and 2) a semantic-abstracted 3D module that uses the relevancy map to predict 3D occupancy. This 3D occupancy can either represent the 3D geometry of a partially observed object or the possible 3D locations of a hidden object (e.g. mask in the trash) conditioned on the language input. | 为了实现这种抽象,我们利用从2D VLM中提取的相关图,并将它们用作“抽象对象”表示,与它们的语义标签无关。SemAbs模块分解为两个子模块:1)语义感知包装器,它采用输入RGB-D图像和对象类别标签,并为该标签输出预先训练的2D VLM模型(即CLIP [7])的相关性图,以及2)语义抽象的3D模块,它使用相关性图来预测3D occupancy。这种 3D 占用可以表示部分观察对象的 3D 几何形状,也可以表示以语言输入为条件的隐藏对象(例如垃圾箱中的mask)的可能 3D 位置。 |
| While we only train the 3D network on a limited synthetic 3D dataset, it generalizes to any novel semantic labels, vocabulary, visual properties, and domains that the 2D VLM can generalize to. As a result, the SemAbs module inherits the VLM's visual robustness and open-set classification abilities while adding the spatial reasoning abilities it lacks [14–16]. In summary, our contributions are three-fold1: | 虽然我们只在有限的合成3D数据集上训练3D网络,但它可以推广到2D VLM可以泛化到的任何新的语义标签,词汇表,视觉属性和域。因此,SemAbs模块继承了VLM的视觉鲁棒性和开放分类能力,同时增加了它所缺乏的空间推理能力[14-16]。总之,我们的贡献有三个方面1: |
| 1)Semantic Abstraction, a framework for augmenting 2D VLMs with 3D reasoning capabilities for open-world 3D scene understanding tasks. By abstracting semantics away using relevancy maps, our SemAbs module generalizes to novel semantic labels, vocabulary, visual properties, and domains (i.e., sim2real) despite being trained on only a limited synthetic 3D dataset. | 1)Semantic Abstraction,一个用于增强 2D VLM 的框架,具有 3D 推理功能,用于开放世界的 3D 场景理解任务。通过使用相关性图抽象出语义,我们的 SemAbs 模块可以泛化到新的语义标签、词汇、视觉属性和领域(即 sim2real),尽管仅在有限的合成 3D 数据集上进行了训练。 |
| 2)Efficient Multiscale Relevancy Extraction. To support Semantic Abstraction, we propose a multi-scale relevancy extractor for vision transformers [17] (ViTs), which robustly detects small, long-tail objects and achieves over ×60 speed up from prior work [18]. | 2)高效的多尺度相关性提取。为了支持语义抽象,我们提出了一种用于视觉transformers的多尺度相关性提取器[17](ViTs),它可以可靠地检测小型长尾物体,并比以前的工作[18]实现超过×60的加速。 |
| 3)Two novel Open-world 3D Scene Understanding tasks (open-vocabulary semantic scene completion and visually obscured object localization), a data generation pipeline with AI2-THOR [1] simulator for the tasks, and a systematic open-world evaluation procedure. We believe these two tasks are important primitives for bridging existing robotics tasks to the open-world. | 3)两个新颖的开放世界3D场景理解任务(开放词汇语义场景完成和视觉模糊对象定位),一个带有AI2-THOR [1]模拟器的数据生成pipeline,以及一个系统的开放世界评估程序。我们相信这两个任务是将现有机器人任务连接到开放世界的重要基元。 |
2 Related Works
| 2D Visual Language Models. The recent advancements in scaling up contrasting learning have enabled the training of large 2D vision language models (VLM). Through their exposure to millions of internet image-caption pairs, these VLMs [7, 9–11] acquire a remarkable level of zero-shot robustness – they can recognize a diverse set of long-tail semantic concepts robustly under distributional shifts. However, the learned image-level representations are not directly applicable to spatial-reasoning tasks which require pixel-level information. To address this issue, approaches were proposed to extract dense features [19–21] or relevancy maps [18, 22]. These advancements complement our contribution, which leverages such techniques for interfacing 2D VLMs to open-world 3D scene understanding tasks. | 2D 视觉语言模型。最近在扩大对比学习方面的进展使大型 2D 视觉语言模型 (VLM) 的训练成为可能。通过接触数百万个互联网图像-标题对,这些VLM [7, 9–11]获得了显著的zero-shot鲁棒性——它们可以在分布偏移下可靠地识别一组不同的长尾语义概念。然而,学习到的图像级表示并不直接适用于需要像素级信息的空间推理任务。为了解决这个问题,提出了提取dense特征的方法[19‒21]或相关性图[18,22]。这些进步补充了我们的贡献,即利用这些技术将 2D VLM 连接到开放世界的 3D 场景理解任务。 |
| Transferring 2D VLMs to 2D Applications. Encouraged by their impressive cabilities, many downstream tasks build around these pretrained VLMs [14, 23–28], often finetuning them (either end-to-end or train learnable weights on top of the pretrained encoder) on a small task-specific dataset. However, many recent studies show that finetuning these VLMs significantly weakens their zero-shot robustness [7, 10, 12, 13, 19], which motivates a new paradigm for using pretrained models. By combining a fixed pretrained VLM with prompting [29] or attention extraction [15, 19–21], the new generation of zero-shot transfer techniques can inherit the VLM's robustness in their downstream tasks without overfitting to any visual domain. However, all existing zero-shot transfer techniques have been confined to the realms of 2D vision. | 将2D vlm转移到2D应用。受到其令人印象深刻的能力的鼓舞,许多下游任务围绕这些预训练的vlm[14,23–28]构建,通常在一个小型任务特定的数据集上对它们进行微调(端到端或在预训练的编码器上训练可学习的权重)。然而,最近的许多研究表明,微调这些vlm会显著削弱其零炮鲁棒性[7,10,12,13,19],这激发了使用预训练模型的新范式。通过将固定的预训练VLM与提示[29]或注意力提取[15,19–21]相结合,新一代zero-shot转移技术可以在下游任务中继承VLM的鲁棒性,而不会过度适应任何视觉域。然而,所有现有的zero-shot转移技术都局限于2D视觉领域。 |
| Closed-World 3D Scene Understanding. Understanding the semantics and 3D structure of an unstructured environment is a fundamental capability for robots. However, prior works in 3D object detection [30–32], semantic scene completion [33–35], and language-informed object localization [6, 36] are typically concerned with limited visual diversity and object categories, limitations imposed by their 3D training data. Despite great efforts from the community [1–6], existing 3D datasets' scale, diversity, and coverage pale in comparison to internet-scale image-text pairs [7–9]. However, our key insight is that visual-semantic reasoning can be learned separately from 3D reasoning. That is, with the right abstraction,the complex visual-semantic reasoning can be offloaded to 2D VLMs, while the 3D model specializes in semantic-agnostic spatial and geometry reasoning. | 封闭世界 3D 场景理解。理解非结构化环境的语义和3D结构是机器人的基本能力。然而,在3D对象检测[30-32],语义场景完成[33-35]和语言信息对象定位[6,36]方面的先前工作通常关注有限的视觉多样性和对象类别,以及其3D训练数据的限制。尽管社区做出了巨大努力[1-6],但与互联网规模的图像文本对相比,现有3D数据集的规模、多样性和覆盖范围相形见绌[7-9]。然而,我们的关键见解是,视觉语义推理可以与3D推理分开学习。也就是说,通过正确的抽象,复杂的视觉语义推理可以卸载到2D VLM,而3D模型专门用于与语义无关的空间和几何推理。 |
3 Method: Semantic Abstraction
空间和几何概念空间小(可以分解为sets of primitives),可以认为是封闭的。语义概念空间要大得多(不能分解为sets of primitives)。
| Evidence from linguistics and cognitive science suggests that semantic concepts are much more diverse than spatial and geometric concepts. While the average adult knows roughly 10,000 nouns for object categories, there are only 90 words in English for describing spatial relations [37]. In fact, there are so few spatial prepositions that they are typically considered a closed-class vocabulary [38]. Similarly for 3D geometry, the idea that our 3D world can be decomposed into sets of primitives [39] has been applied in many works, such as generalized cylinders [40] and block worlds [41]. In contrast, the space of nouns for semantic concepts is large and often cannot be further decomposed into common primitives. This suggests that while we may need a large and diverse dataset for semantic and visual concept learning, a relatively small 3D dataset could cover spatial and geometric reasoning. This observation motivates our approach, Semantic Abstraction. | 语言学和认知科学的证据表明,语义概念比空间和几何概念更加多样化。虽然普通成年人知道大约10,000个对象类别的名词,但英语中只有90个单词用于描述空间关系[37]。事实上,空间介词太少了,它们通常被认为是封闭类词汇[38]。同样,对于3D几何,我们的3D世界可以分解为基元集[39]的想法已经应用于许多作品中,例如广义圆柱[40]和块世界[41]。相比之下,语义概念的名词空间很大,往往不能进一步分解为常见的原语。这表明,虽然我们可能需要一个庞大而多样化的数据集来进行语义和视觉概念学习,但相对较小的3D数据集可以涵盖空间和几何推理。这一观察结果激发了我们的方法,语义抽象。 |
3.1 Abstraction via Relevancy
| The Semantic Abstraction (SemAbs) module (Fig 3c) takes as input an RGB-D image | 语义抽象 (SemAbs) 模块(图 3c)将 RGB-D 图像 |
| The semantic-aware wrapper (Fig 3c, green background) abstracts I and T into a relevancy map | 语义感知包装器(图 3c,绿色背景)将 I 和 T 抽象为relevancy map |
| The semantic-abstracted 3D module (Fig 3c, grey background) treats the relevancy point cloud as the localization of a partially observed object and completes it into that object's 3D occupancy. To do this, we first scatter | 语义抽象的3D模块(图3c,灰色背景)将相关性点云视为部分观察到的对象的定位,并将其完成到该对象的3D占用中。为此,我们首先将 |
| Although the semantic-abstracted 3D module only observes relevancy abstractions of the semantic label T but not T itself, the semantic-abstracted 3D module's output can be interpretted as the 3D occupancy for T . This means it generalizes to any semantic label that can be recognized by the 2D VLMs' relevancy maps even if it was trained on a limited 3D dataset. In our implementation, we use CLIP [7] as our VLM. However, our framework is VLM-agnostic, as long as relevancy maps can be generated. It is a interesting future direction to investigate how different VLMs [7–11], their training procedure [43], and different relevancy approaches [18, 22, 44, 45] affect the performance of different downstream 3D scene understanding tasks. In the next sections, we explain how to ensure the visual-semantic concepts are reliably recognized by the relevancy maps (Sec. 3.2), and how to apply SemAbs to 3D scene understanding tasks (Sec. 3.3, Sec. 3.4). | 虽然语义抽象的 3D 模块只观察语义标签 T 的相关性抽象,而不观察 T 本身,但语义抽象 3D 模块的输出可以解释为 T 的 3D 占有。这意味着它可以泛化到任何可以被 2D VLM 的相关性映射识别的语义标签,即使它是在有限的 3D 数据集上训练的。在我们的实现中,我们使用 CLIP [7] 作为我们的 VLM。但是,我们的框架与VLM无关,只要可以生成相关性图即可。研究不同的VLM[7‒11]、它们的训练过程[43]和不同的相关性方法[18,22,44,45]如何影响不同下游3D场景理解任务的性能,这是一个有趣的未来方向。在接下来的章节中,我们将解释如何确保相关性图可靠地识别视觉语义概念(第 3.2 节),以及如何将 SemAbs 应用于 3D 场景理解任务(第 3.3 节、第 3.4 节)。 |

Figure 3: Semantic Abstraction Overview. Our framework can be applied to open-world 3D scene understanding tasks (a-b) using the SemAbs module (c). It consists of a semantic-aware wrapper (green background) that abstracts the input image and semantic label into a relevancy map, and a semantic-abstracted 3D module (grey background) that completes the projected relevancy map into a 3D occupancy. This abstraction allows our approach to generalize to long-tail semantic labels unseen (bolded) during 3D training, such as the "CoRL ticket on top of the fireplace".
图 3:语义抽象概述。我们的框架可以使用 SemAbs 模块 (c) 用于开放世界 3D 场景理解任务 (a-b)。它由一个语义感知包装器(绿色背景)和语义抽象的 3D 模块(灰色背景)组成,前者将输入图像和语义标签抽象为相关性图,后者将投影的相关性图完成为 3D 占用。这种抽象允许我们的方法泛化到3D训练期间看不见(粗体)的长尾语义标签,例如“壁炉顶部的CoRL票证”。
3.2 A Multi-Scale Relevancy Extractor
| We choose to use ViT-based CLIP [7] due to their superior performance over the ResNet variants. However, existing ViT relevancy techniques [18] often produce noisy, low-resolution maps that highlight irrelevant regions or miss small objects [27, 46]. | 我们选择使用基于 ViT 的 CLIP [7],因为它们的性能优于 ResNet 变体。然而,现有的ViT相关性技术[18]经常产生嘈杂的低分辨率maps,突出显示不相关的区域或遗漏小物体[27,46]。 |
| To reduce noise from irrelevant regions, we use horizontal flips and RGB augmentations [27] of I and obtain a relevancy map for each augmentation. To reliably detect small objects, we propose a multi-scale relevancy extractor that densely computes relevancies at different scales and locations in a sliding window fashion (an analogous relevancy-based approach to Li et al.'s local attention-pooling). The final relevancy map is averaged across all augmentations and scales. | 为了减少来自不相关区域的噪声,我们使用I的水平翻转和 RGB 增强 [27],并获得每个增强的相关性图。为了可靠地检测小物体,我们提出了一种多尺度相关性提取器,它以滑动窗口的方式密集计算不同尺度和位置的相关性(类似于 Li 等人的局部注意力池的基于相关性的方法)。最终的相关性图是在所有增强和比例上取平均值的。 |
| Qualitatively, while augmentations help in reducing irrelevant regions (e.g. Fig. 4, from localizing the entire fireplace in the 1st column to only the vase in the 2nd column), they still often miss small objects. However, with our multi-scale relevancy extractor, our relevancy maps can detect small objects such as the tiny "nintendo switch" (Fig. 4, bottom right). To support efficient multi-scale relevancy extraction, we implemented a batch-parallelized ViT relevancy extractor. At 0.4 seconds per text label on average2, we achieve over × 60 speed up compared to the non-parallelized implementation. With the rise in popularity of ViTs, we believe this efficient ViT relevancy extractor implementation will be a useful primitive for the research community and have released it on Github and a Hugging Face Spaces. | 从定性上讲,虽然增强有助于减少不相关的区域(例如图 4,从第一列的整个壁炉定位到第二列的花瓶),但它们仍然经常遗漏小物体。然而,使用我们的多尺度相关性提取器,我们的相关性地图可以检测小物体,例如微小的“nintendo switch”(图 4,右下角)。为了支持高效的多尺度相关性提取,我们实现了批量并行化的 ViT 相关性提取器。每个文本标签平均需要 0.4 秒2,与非并行化实现相比,我们实现了超过 × 60 的速度提升。随着 ViT 的普及,我们相信这种高效的 ViT 相关性提取器实现将成为研究界有用的原语,并已在 Github 和 Hugging Face Spaces 上发布。 |
| 2:measured over 10 repetitions with 100 text labels on a GTX 1080 Ti machine with a light load. We provide extra details in the appendix. | 2:在轻负载的 GTX 1080 Ti 机器上使用 100 个文本标签重复 10 次测量。我们在附录中提供了更多详细信息。 |
3.3 Application to Open Vocabulary Semantic Scene Completion (OVSSC)
| Task. Given as input a single RGB-D image I and a set of K object class labels, represented as openvocabulary text {Tk}K k=1, the task is to complete the 3D geometry of all the partially observed objects referred by {Tk}K k=1. In contrast to its closed-world variant [33], where the object list is fixed for all scenes, OVSSC formulation accounts for context-dependency, which allows the class labels to change from scene to scene and from training to testing. From this 3D semantic scene completion, robots can use the detailed 3D geometry for low level planning such as grasping and motion planning. | 任务。 给定一个 RGB-D 图像 I 和 K个 对象类标签作为输入,表示为开放词汇文本 |
| Applying SemAbs to OVSSC is a matter of applying the SemAbs module K times, once per object label. First, the semantic-aware wrapper abstracts I and {Tk}K k=1 into K relevancy point clouds {Rprojk }K k=1. Then, the semantic-abstracted 3D module extracts K feature volumes {Zk}K k=1, used to decode K 3D occupancies {Ok}K k=1. The final OVSSC output is a point-wise argmax of occupancy probability over theK classes. Query points with the maximum occupancy probability less than a threshold c are labeled as empty. We provide data generation and training details in the appendix. | 将 SemAbs 应用于 OVSSC 只需将 SemAbs 模块应用 K 次,每个对象标签一次。首先,语义感知包装器将 I 和 |
3.4 Application to Visually Obscured Object Localization (VOOL)
| Motivation. Even after completing partially visible objects in the scene, OVSSC's output may not be complete – the scene may contain visually obscured or hidden objects (e.g., the ticket on the fireplace in Fig. 3b). In such cases, the human user can provide additional hints to the robot using natural language to help localize the object, which motivates our VOOL task. | 动机。即使在完成了场景中部分可见的对象之后,OVSSC 的输出也可能不完整——场景可能包含视觉上被遮挡或隐藏的对象(例如,图 3b 中壁炉上的票)。在这种情况下,人类用户可以使用自然语言向机器人提供额外的提示,以帮助定位对象,从而激励我们的VOOL任务。 |
| Task. Given as input a single RGB-D image I of a 3D scene and a description D of an object's location in the scene, the task is to predict the possible occupancies of the referred object. Similar to prior works [47], we assume that the description is in the standard linguistic representation of an object's place [37]. Specifically, D =〈Ttarget,S,Tref〉, where the open-vocabulary target object label Ttarget (e.g. "rapid test") is the visually obscured object to be located, the open-vocabulary reference object label Tref (e.g. "harry potter book") is presumably a visible object, and the closed-vocabulary spatial preprosition S describes Ttarget's location with respect to Tref (e.g. "behind"). Unlike the referred expression 3D object localization task [6] which assumes full visibility (i.e., fused pointcloud), VOOL takes as input only the current RGB-D image, and thus is more suited for a dynamic, partially observable environment. Further, in contrast to bounding boxes, VOOL's occupancy can be disjoint regions in space, which accounts the multi-modal uncertainty when objects are hidden. Downstream robotic applications, such as object searching, benefit more from the uncertainty information encoded in a VOOL's output than bounding boxes. | 任务。给定一个 3D 场景的单个 RGB-D 图像 I 和对象在场景中位置的描述 D 作为输入,任务是预测所引用对象的可能占用。与先前的工作[47]类似,我们假设描述是以物体位置的标准语言表示[37]。具体来说,D =〈Ttarget,S,Tref〉,其中开放词汇目标对象标签Ttarget(例如“快速测试”)是视觉上被遮挡的对象,开放词汇参考对象标签Tref(例如“哈利波特书”)可能是可见对象,封闭词汇空间预置S描述了Ttarget相对于Tref的位置(例如“后面”)。与假定完全可见性(即融合点云)的引用表达式 3D 对象定位任务 [6] 不同,VOOL 仅将当前的 RGB-D 图像作为输入,因此更适合动态的、部分可观察的环境。此外,与边界框相比,VOOL的占用可以是空间中的不相交区域,这解释了隐藏对象时的多模态不确定性。下游机器人应用(如对象搜索)比边界框更能受益于 VOOL 输出中编码的不确定性信息。 |
| Applying SemAbs to VOOL. We propose to learn an embedding fspatial(S) ∈ R2D for each spatial relation (Fig. 3b, blue box), since the set of spatial prepositions is small and finite [37], and use them as follows. As in OVSSC (§3.3), we can get occupancy feature volumes Ztarget and Zref for the target and reference objects respectively. Given a set of fixed query points Q = {qi}N i=1, we extract their local feature point clouds φZtargetQ ,φZrefQ ∈ RN×D, then concatenate them to get a new feature pointcloudφZtarget‖ZrefQ ∈ RN×2D. Finally, to get the 3D localization occupancy O, we perform a point-wise cosinesimilarity between φZtarget‖ZrefQ and fspatial(S). For this task, we only need to learn the spatial embeddingsfspatial conditioned on the occupancy information encoded in Ztarget and Zref, since semantic reasoning ofTtarget and Tref has been offloaded to the SemAbs (and, therefore, to CLIP). We provide data generation and training details in the appendix. | 将 SemAbs 应用于 VOOL。由于空间介词集很小且有限[37],我们建议为每个空间关系学习一个嵌入fspatial(S)∈R2D(图3b,蓝框),并按如下方式使用它们。与 OVSSC (§3.3) 一样,我们可以分别获得目标对象和参考对象的占用特征卷 Ztarget 和 Zref。给定一组固定的查询点 Q = {qi}N i=1,我们提取它们的局部特征点云 φZtargetQ 、φZrefQ ∈ RN×D,然后将它们连接起来得到一个新特征 |
4 Experiments
| We design experiments to systemically investigate Semantic Abstraction's open-world generalization abilities to novel3 concepts in 3D scene understanding. Our benchmark include the following categories: 1) Novel Rooms: we follow AI2-THOR [1]'s split, which holds out 20 rooms for as novel rooms, while training on 100 rooms. 2) Novel Visual: we use AI2-THOR's randomize material and lighting functionality to generate more varied 2D visual conditions of novel rooms. 3) Novel Synonyms: we manually picked out 17 classes which had natural synonyms (e.g. "pillow" to "cushion", complete list included in appendix) and replace their occurrences in text inputs (i.e., object label in OVSSC, description in VOOL) to these synonyms. 4) Novel Class: we hold out 6 classes out of the 202 classes in AI2-THOR. For OVSSC, any view which contains one of these novel classes is held out for testing. For VOOL, any scene with a description that contains a novel class (as either the target or reference object) is held out. 5) Novel Domain: We also provide qualitative evaluations (Fig. 5) using real world scans from HM3D [4]. | 我们设计实验来系统地研究语义抽象在3D场景理解中的开放世界泛化能力。我们的基准包括以下类别:1)新房间:我们遵循AI2-THOR[1]的拆分,将20个房间作为新房间,同时对100个房间进行训练。2)新的视觉效果:我们使用AI2-THOR的随机化材料和照明功能来生成新房间的更多样化的2D视觉条件。3)新近义词:我们手动挑选了17个具有自然同义词的类(例如,“枕头”到“垫子”,完整列表包含在附录中),并将它们在文本输入中的出现(即OVSSC中的对象标签,VOOL中的描述)替换为这些同义词。4)新类别:我们在AI2-THOR的202个类别中开设了6个类别。对于 OVSSC,任何包含这些新类之一的视图都将进行测试。对于 VOOL,任何具有包含新类(作为目标对象或引用对象)的描述的场景都会被保留。5)新领域:我们还使用HM3D的真实世界扫描[4]提供定性评估(图5)。 |
| Metrics & Baselines. For both tasks, we measure the learner's performance with voxel IoU of dimension32×32×32, where the ground truth of each task is generated as described in §3.3 for OVSSC and §3.4 for VOOL. We compare with following categories of baselines: | 指标和基线。对于这两项任务,我们使用 32×32×32 的体素 IoU 来衡量学习器的表现,其中每个任务的ground truth 都按照 OVSSC 的 §3.3 和 VOOL 的 §3.4 中所述生成。我们与以下类别的基线进行比较: |
| • Semantic-Aware (SemAware). To evaluate the effectiveness of semantic abstraction, we design baselines that perform visual-semantic reasoning themselves by taking RGB point clouds as input (instead of relevancy point clouds). For OVSSC, the baseline's feature point cloud is supervised with BCE to be aligned (i.e., using cosine similarity) with the correct object class text embedding. Similarly, for VOOL, the feature point cloud's cosine similarity with an embedding of the entire localization description (e.g. "N95s inside the trash") is supervised using BCE to the target object occupancy. | • 语义感知 (SemAware)。为了评估语义抽象的有效性,我们设计了基线,通过采用RGB点云作为输入(而不是相关性点云)来执行视觉语义推理。对于 OVSSC,基线的特征点云使用 BCE 进行监督,以便与正确的对象类文本嵌入对齐(即使用余弦相似性)。同样,对于 VOOL,特征点云的余弦相似性与整个定位描述的嵌入(例如“垃圾桶内的 N95”)使用 BCE 对目标对象占用进行监督。 |
| • Semantic & Spatial Abstraction (ClipSpatial). What if we off-load both 3D and visual-semantic reasoning to 2D VLMs (instead of just the latter, as in our approach)? To answer this, we designed CLIPSpatial, a VOOL baseline that uses relevancy maps for the entire description (e.g. "N95s inside the trash") as input. We expect this approach to perform poorly since it has been demonstrated that current 2D VLMs [7, 8] struggles with spatial relations [14–16, 48]. | 语义和空间抽象(ClipSpatial)。如果我们将 3D 和视觉语义推理都卸载到 2D VLM(而不是像我们的方法中那样只是后者)会怎样?为了回答这个问题,我们设计了 CLIPSpatial,这是一个 VOOL 基线,它使用整个描述的相关性图(例如“垃圾桶内的 N95”)作为输入。我们预计这种方法表现不佳,因为已经证明当前的 2D VLM [7, 8] 在空间关系方面存在困难 [14–16, 48]。 |
| • Naive Relevancy Extraction. (SemAbs + [18]) To investigate the effects of relevancy quality, we replace our multi-scale relevancy extractor with Chefer et al. [18]'s approach. | • 朴素相关性提取。(SemAbs + [18])为了研究相关性质量的影响,我们用Chefer等人[18]的方法取代了我们的多尺度相关性提取器。 |
| The first two baselines can be seen as two extremes on a spectrum of how much we rely on pretrained 2D VLMs. While SemAware learns both semantics and 3D spatial reasoning, CLIPSpatial delegates both to pretrained 2D VLMs. Our approach is in between these two extremes, designed such that it builds on 2D VLMs' visual robustness and open-classification strengths while addressing its spatial reasoning weaknesses. | 前两个基线可以看作是我们对预训练 2D VLM 的依赖程度的两个极端。虽然 SemAware 同时学习语义和 3D 空间推理,但 CLIPSpatial 将两者都委托给预训练的 2D VLM。我们的方法介于这两个极端之间,其设计使其建立在2D VLM的视觉鲁棒性和开放分类优势之上,同时解决了其空间推理的弱点。 |
4.1 Open-world Evaluation Results
| Tab. 1 and 2 summarize the quantitative results, and Fig. 5 shows real world qualitative results tested on Matterport scenes [4]. More results and comparisons can be found on the project website. | 表 1 和表 2 总结了定量结果,图 5 显示了在 Matterport 场景 [4] 上测试的真实世界定性结果。更多结果和比较可以在项目网站上找到。 |
| Semantic Abstraction simplifies open-world generalization. SemAware baselines especially struggle to generalize to novel semantic classes (Tab. 1, Tab. 2).We hypothesize that observing text embeddings during training causes these baselines to specialize to this distribution of embeddings, such that some synonyms and most novel class labels are out-of-distribution inputs. Our approach significantly outperforms the SemAware baseline across the board, suggesting that Semantic Abstraction not only simplifies open-world generalization but is also a strong inductive bias for learning the task. | 语义抽象简化了开放世界的泛化。SemAware基线尤其难以泛化到新的语义类(表1,表2)。我们假设,在训练期间观察文本嵌入会导致这些基线专门针对这种嵌入分布,因此一些同义词和大多数新的类标签都是分布外输入。我们的方法在全面上明显优于 SemAware 基线,这表明语义抽象不仅简化了开放世界的泛化,而且对学习任务也是一种强烈的归纳偏见。 |
| Semantic & Spatial Abstraction generalizes poorly. The CLIPSpatial baseline achieves 8.0-9.0 IoU worse than our approach in all generalization scenarios (Tab. 2). This indicates that our design of learning spatial reasoning instead of relying on CLIP was crucial to semantic abstraction's performance. | 语义和空间抽象的泛化很差。在所有泛化场景中,CLIPSpatial 基线达到 8.0-9.0 IoU 比我们的方法差(表 2)。这表明,我们学习空间推理而不是依赖 CLIP 的设计对于语义抽象的性能至关重要。 |
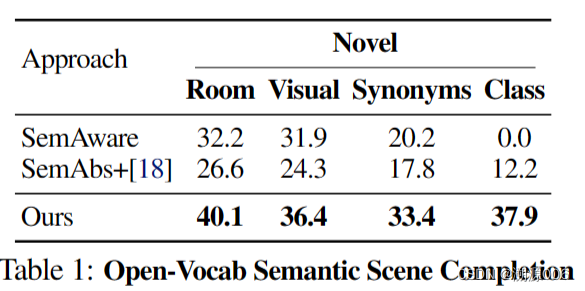
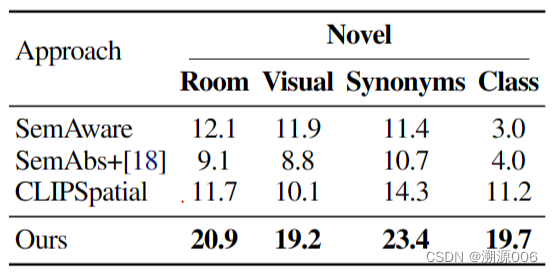
| Semantic Abstraction requires high quality relevancy maps. Intuitively, the model can only output high quality completions if its relevancy maps are also high quality (i.e., highlights the target object, especially when the object is small). Our average IoU is ×1.5 (novel room, visual, synonyms, Table 1), over ×2.0 (novel classes, Table 1, novel room, visual, synonyms, Table 2) or ×5.0(novel class, Table 2) compared to SemAbs + [18], which demonstrates the importance of our relevancy extractor in a successful application of Semantic Abstraction. | 语义抽象需要高质量的相关性图。直观地说,只有当模型的相关性映射也是高质量的(即突出显示目标对象,尤其是当对象很小时),模型才能输出高质量的完成。与 SemAbs + [18] 相比,我们的平均 IoU 为 ×1.5(novel room、visual、synonyms,表 1)、×2.0(novel class,表 1、novel room、visual、synonyms,表 2)或 ×5.0(novel class,表 2),这表明我们的相关性提取器在语义抽象的成功应用中的重要性。 |
| Inheriting VLM zero-shot robustness enables Sim2Real transfer. Despite training in simulation, our approach can perform completion and localization from real-world matterport scans [4] (Fig. 1 and 5). From novel vocabulary for describing materials (e.g. "leather sofa", "wooden pouf"), colors (e.g. "red folder", "blue folder"), conjunctions of them (e.g. "black aluminum file cabinet") to novel semantic classes (e.g. "roomba", "Hogwarts box"), our approach unlocks CLIP's visual robustness and large repertoire of visual-semantic concepts to 3D scene understanding. When OVSSC's completion misses objects (e.g. "hydrangea", "keychain"), VOOL can still localize them (e.g. +0.13 IoU for keychain). | 继承 VLM 零样本鲁棒性可实现 Sim2Real 传输。尽管是在仿真环境里进行的训练,但我们的方法可以从真实世界的 matterport 扫描中执行完成和定位 [4](图 1 和 5)。从描述材料(例如“真皮沙发”、“木制坐凳”)、颜色(例如“红色文件夹”、“蓝色文件夹”)、它们的连词(例如“黑色铝制文件柜”)到新颖的语义类(例如“roomba”、“霍格沃茨盒子”),我们的方法解锁了 CLIP 的视觉鲁棒性和大量视觉语义概念,以实现 3D 场景理解。当 OVSSC 的完成遗漏对象(例如“绣球花”、“钥匙扣”)时,VOOL 仍然可以对它们进行定位(例如钥匙串的 +0.13 IoU)。 |
4.2 Zero-shot Evaluation Results
| The NYUv2 CAD dataset [49, 50] is a popular closed-vocabulary SSC benchmark. Although it contains 894 object classes, prior works [33, 51, 52] collapse it down to 11 classes to avoid the challenge in learning the "long-tail" categories (e.g. ,"puppy toy","ipod", "hand sculture"). We evaluate our model zero-shot on NYUv2 directly on all 894 classes as well as the 11 classes for comparison (Fig. 6, Tab. 3, Ours). We also train a SemAbs model from scratch in NYU to investigate the generalization gap between our dataset and NYUv2 (Tab. 3, Ours NYU). We use the same training/testing split [33]. Similar to prior works [33], we report volumetric IoU at a voxel dimension of 60. As in our THOR dataset, we only train fencode andfdecode in the semantic abstracted 3D module, not the 2D VLM. To our knowledge, our approach is the first to output the full list of 894 object categories in this benchmark. | NYUv2 CAD 数据集 [49, 50] 是一个流行的封闭词汇 SSC 基准。虽然它包含894个对象类,但先前的工作[33,51,52]将其缩减为11个类,以避免学习“长尾”类别的挑战(例如,“小狗玩具”,“ipod”,“手文化”)。我们直接在所有 894 个类以及 11 个类上评估我们在 NYUv2 上的模型零样本进行比较(图 6,表 3,我们的)。我们还在纽约大学从头开始训练 SemAbs 模型,以调查我们的数据集与 NYUv2(表 3,我们的纽约大学)之间的泛化差距。我们使用相同的训练/测试拆分[33]。与之前的工作[33]类似,我们报道了体素维数为60的体积IoU。与我们的 THOR 数据集一样,我们只在语义抽象的 3D 模块中训练 fencode 和 fdecode,而不是在 2D VLM 中训练。据我们所知,我们的方法是第一个在此基准测试中输出 894 个对象类别的完整列表的方法。 |
| Open-world versus Closed-world formulation. Our work investigates open-world 3D scene understanding, which means specializing to one data distribution is not our focus. However, we hope these results on a standard closed-world benchmark along with our discussion below are helpful to the research community in understanding practical trade-offs in algorithm and evaluation design between the open-world versus closed-world formulation. Below summarizes our key findings: | 开放世界与封闭世界公式。我们的工作是研究开放世界的3D场景理解,这意味着专注于一个数据分布不是我们的重点。然而,我们希望这些在标准封闭世界基准上的结果以及我们下面的讨论有助于研究界理解开放世界与封闭世界公式之间算法和评估设计的实际权衡。以下是我们的主要发现: |
| + Flexibility to object labels. Our framework directly outputs the full 894 object categories, of which 108 do not appear in the training split, and its predictions can map back to the collapsed 11 classes. This has never been attempted by prior works. This flexibility is achieved by building on top of 2D VLMs. | + 对象标签的灵活性。我们的框架直接输出完整的 894 个对象类别,其中 108 个没有出现在训练拆分中,其预测可以映射回折叠的 11 个类别。这是以前的作品从未尝试过的。这种灵活性是通过构建在 2D VLM 之上实现的。 |
| + Robust detection of small, long-tail object categories. "Due to the heavy-tailed distribution of object instances in natural images, a large number of objects will occur too infrequently to build usable recognition models" [41]. However, our approach can robustly detect not just long-tail object classes, but also small ones – challenging scenarios for perception systems. For instance, from Fig. 6, our multi-scale relevancy extractor can output highly localized relevancy maps around "puppy toy","ipod", and "hand sculpture". | + 对小型长尾物体类别的可靠检测。“由于自然图像中物体实例的尾部分布较重,大量物体的出现频率太低,无法构建可用的识别模型”[41]。然而,我们的方法不仅可以可靠地检测长尾物体类别,还可以检测小物体类别——这对感知系统来说是一个具有挑战性的场景。例如,从图 6 中,我们的多尺度相关性提取器可以围绕“小狗玩具”、“ipod”和“手雕”输出高度本地化的相关性图。 |
| - Inability to finetune large pretrained models. As shown in prior works [7, 10, 12, 13, 19], directly finetuning 2D VLMs on small datasets hurts their robustness. We cannot finetune the visual encoders (and thus, its relevancy activations) to specialize on the visual and class distribution on a small dataset (e.g., NYUv2) without sacrificing it robustness and generality. This is an open and important research direction and recent work [53] has demonstrated promising results in image classification. | - 无法微调大型预训练模型。正如之前的工作[7,10,12,13,19]所示,直接在小数据集上微调2D VLM会损害其鲁棒性。我们无法在不牺牲其鲁棒性和通用性的情况下,对视觉编码器(以及其相关性激活)进行微调,以专注于小型数据集(例如 NYUv2)上的视觉和类分布。这是一个开放而重要的研究方向,最近的工作[53]在图像分类方面取得了可喜的成果。 |
| - Bias from image caption data. The typical training paradigm of current 2D VLMs [7, 10, 11] is contrastive learning over image-caption pairs on the internet. While their dataset covers a large number of semantic concepts, they still have their limits. For instance, we observed that for "wall" and "ceiling" – two classes which closed-world approaches typically achieve high performance for – our approach achieved an much lower IoU of only 33.9 and 22.6. Since these classes are often not the subject of internet captions, our approach inherit this bias from 2D VLMs. However, our framework is VLMagnostic, which means it can continue to benefit from future and more powerful versions of 2D VLMs. | - 图像标题数据的偏差。当前 2D VLM [7, 10, 11] 的典型训练范式是互联网上图像-字幕对的对比学习。虽然他们的数据集涵盖了大量的语义概念,但它们仍然有其局限性。例如,我们观察到,对于“墙”和“天花板”——封闭世界方法通常实现高性能的两个类——我们的方法实现了低得多的 IoU,仅为 33.9 和 22.6。由于这些类通常不是互联网字幕的主题,因此我们的方法继承了 2D VLM 的这种偏差。但是,我们的框架是 VLM agnostic,这意味着它可以继续受益于未来更强大的 2D VLM 版本。 |
4.3 Limitations and assumptions
| Our key assumption is that geometry and spatial reasoning can be done in a semantic agnostic manner. This assumption does not hold when we care about completing detailed object geometry, which is often semantic-dependent. However, we believe that coarse 3D reasoning with paired semantic labels may already useful for open-world robotic applications such as object retrieval. Second, while we have assumed a simple description syntax and a small set of spatial prepositions for object localization, incorporating natural language understanding (i.e., to support open-set phrases for richer spatial descriptions) into open-world 3D scene understanding is an important extension of our work. Lastly, we assumed that relevancy maps highlight only relevant regions. Limited by current VLMs, our relevancy extractor can sometimes fail to distinguish highly related concepts (e.g. book v.s. bookshelf). However, since Semantic Abstraction is VLM-agnostic, this limitation could be addressed by using other VLMs. | 我们的关键假设是几何和空间推理可以以语义不可知的方式完成。当我们关心完成详细的对象几何形状时,这个假设就不成立了,这通常是语义依赖的。然而,我们认为,带有成对语义标签的粗略 3D 推理可能已经对开放世界的机器人应用程序(例如对象检索)有用。其次,虽然我们假设了简单的描述语法和一小组用于对象定位的空间介词,但将自然语言理解(即支持开放集短语以获得更丰富的空间描述)纳入开放世界的 3D 场景理解是我们工作的重要扩展。最后,我们假设相关性地图仅突出显示相关区域。受当前VLM的限制,我们的相关性提取器有时可能无法区分高度相关的概念(例如书架与书架)。但是,由于语义抽象与 VLM 无关,因此可以通过使用其他 VLM 来解决此限制。 |
5 Conclusion
| We proposed Semantic Abstraction, a framework that equips 2D VLMs with 3D spatial capabilities for open-world 3D scene understanding tasks. By abstracting RGB and semantic label inputs as relevancy maps, our learned 3D spatial and geometric reasoning skills generalizes to novel vocabulary for object attributes and nouns, visual properties, semantic classes, and domains. Since scene completion and 3D object localization are fundamental primitives for many robotic tasks, we believe our approach can assist in bridging currently close-world robotics tasks, such as object retrieval, into the open-world formulation. More importantly, we hope our framework encourages roboticists to embrace building systems around large pretrained models, as a path towards open-world robotics. | 我们提出了语义抽象,这是一个为2D VLM提供3D空间功能的框架,用于开放世界的3D场景理解任务。通过将RGB和语义标签输入抽象为相关性图,我们学到的3D空间和几何推理技能可以推广到对象属性和名词、视觉属性、语义类和域的新词汇。由于场景完成和 3D 对象定位是许多机器人任务的基本基元,我们相信我们的方法可以帮助将当前封闭世界的机器人任务(例如对象检索)桥接到开放世界的公式中。更重要的是,我们希望我们的框架鼓励机器人专家围绕大型预训练模型构建系统,作为通往开放世界机器人的途径。 |
All code, data, and models is publicly available at:
https://github.com/columbia-ai-robotics/semantic-abstraction

