
- 1池化函数小例子_池化例子
- 2RocketMQ原理学习---生产者普通消息发送_.setmaxreconsumetimes(0)
- 3讲真,计算机还能火多久?2020届本科,非科班,打算22年考研,害怕三四年以后读研出来计算机不行了_计算机不考研真的没出路
- 4B树与B+树的奥秘:原理解析与性能_oracle b+树
- 5Cisco Packet Tracer 路由器基本配置实验_cisco平台上路由器基本操作和路由配置实验
- 6数据结构笔记(王道考研) 第五章:树和二叉树_王道数据结构第五章ppt
- 7OpenCV-细化算法(thinning algorithm)算法详解——提取二值图的骨架_opencv thinning
- 8微信聊天记录导出的开源项目,火了!_开源微信资料备份
- 9使用git bash工具 往 gitee网站传文件
- 107个月吐血整理!Android面试相关文章及Github学习资料(标星3-2K)
超越传统插值:利用深度学习提升视频帧率与清晰度
赞
踩
视频帧率的提升是视频处理领域中一个重要问题,它直接影响到视频的流畅度和观感。随着技术的发展,人们对于视频质量的要求越来越高,尤其是在捕捉快速运动场景时,高帧率视频能够提供更加清晰和连贯的视觉效果。然而,传统的视频拍摄设备往往受限于硬件性能,无法实时记录高帧率视频,这就导致了在回放快速动作时出现模糊和拖影现象。现有的提高视频帧率的方法,如时间插值技术,虽然能够在一定程度上增加视频的帧数,但它们通常无法恢复由于运动模糊和运动混叠而丢失的高频信息。时间插值通常只是简单地在现有帧之间插入额外的帧,而不能解决由于低采样率带来的问题。
时间超分辨率(TSR)方法的出现,为解决这一问题提供了新的途径。TSR不仅能够增加视频的帧率,还能够恢复超出原始视频帧率奈奎斯特极限的高频信息,从而有效解决运动模糊和运动混叠问题。与传统方法相比,TSR的优势在于它能够提供更高质量的视频增强效果,尤其是在处理复杂动态场景时,TSR能够生成更加清晰、自然的高帧率视频。TSR方法不需要外部数据集进行训练,而是直接利用输入视频本身进行自我训练,这使得它能够更好地适应视频内容的特定统计特性,提高了算法的泛化能力和实用性。

跨维度的补丁递归
视频本质上是由连续的帧组成的,这些帧在时间和空间上都存在着一定的冗余性。特别是,视频帧中的小区域,即空间时间补丁(ST-patches),在视频序列内部会以不同的形式重复出现。这种现象称为补丁递归,是视频处理和增强技术中一个重要的概念。
补丁递归不仅在同一维度的不同时空尺度中存在,还特别地出现在视频的时空维度互换中。这意味着,如果我们将视频的时间维度和空间维度进行交换,我们仍然可以观察到类似的递归模式。例如,将视频帧视为空间的x-y平面,时间切片x-t或y-t可以视为在时间上展开的“帧”。

在快速移动物体的视频中,时间切片上的ST-patches往往看起来模糊不清,就像是传统空间帧的低分辨率版本。这种模糊是由于视频帧率不足以捕捉快速运动的细节,导致运动模糊和混叠现象。然而,这些低分辨率的时间切片与高分辨率的空间帧之间存在一种内在联系。

通过观察到的递归性,我们可以利用高分辨率的空间帧来指导如何提高时间切片的分辨率。具体来说,空间帧提供了清晰的参考信息,可以用来恢复时间切片中丢失的细节,从而提高整个视频的时间分辨率。这种方法允许我们在不需要额外数据的情况下,仅通过内部视频数据来增强视频的动态清晰度。
生成内部训练集
在深度学习和卷积神经网络(CNN)的应用中,训练集的质量直接影响模型的性能。为了提升视频的时间分辨率,需要一个高质量的训练集来指导网络学习如何从低时间分辨率(LTR)的视频帧中恢复出高时间分辨率(HTR)的视频帧。
传统的训练方法依赖于大量的外部数据集。然而,本文提出的方法采用了一种创新的途径——生成内部训练集。这种方法直接从输入视频中提取LTR和HTR的示例对,而不需要任何外部数据。
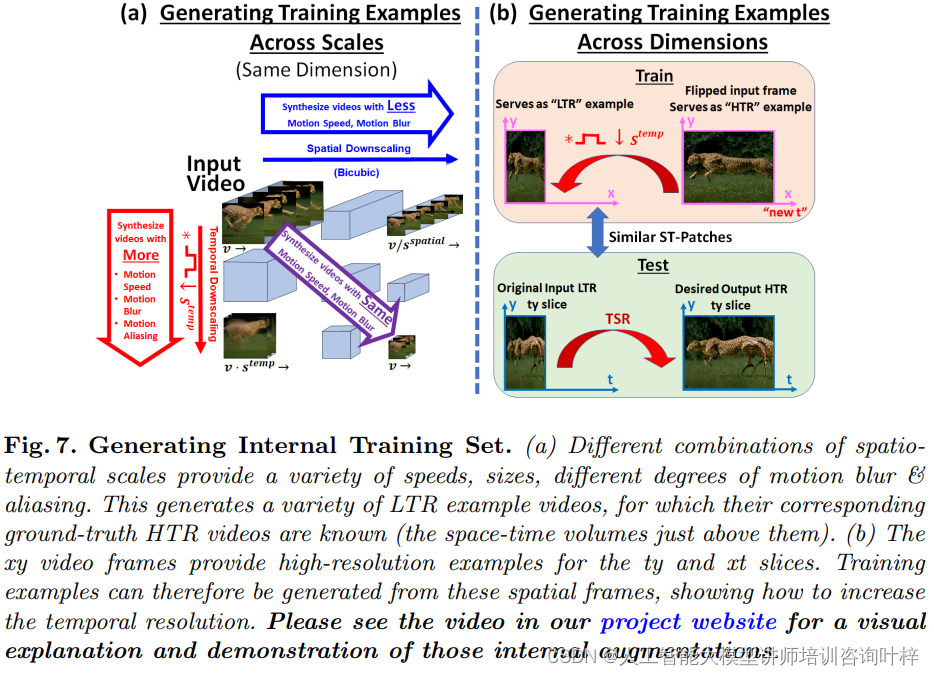
视频帧中的小空间时间补丁(ST-patches)在视频的不同时空尺度上具有递归性。这意味着,即使在不同的尺度上,相似的ST-patches也会重复出现。利用这一特性,可以通过对视频帧进行空间降采样和时间模糊来创建LTR补丁,同时通过时间插值和空间锐化来创建HTR补丁。
除了在同一维度的不同尺度上寻找递归的ST-patches,跨维度的匹配也是一个关键的步骤。通过交换视频的空间和时间维度,研究者们能够在新维度上找到相似的补丁,这为生成训练示例提供了更多的可能性。
生成训练示例的过程涉及对视频帧进行多种变换,包括空间和时间的尺度变换、模糊和锐化等。这些变换帮助创建了从LTR到HTR的对应补丁对,从而形成了训练集。
通过内部生成的训练集,CNN能够学习到与输入视频紧密相关的特定统计特性。这种自我监督的学习方式使得网络能够更好地适应视频内容,提高了模型对新数据的泛化能力。
为了进一步丰富训练集并提高网络的鲁棒性,研究者们还应用了数据增强技术,如镜像翻转、旋转等。这些增强手段增加了训练示例的多样性,有助于网络学习到更加全面的特征表示。
‘零样本’时间超分辨率——算法
在传统的机器学习方法中,模型通常需要大量的标注数据来训练。然而,在时间超分辨率(TSR)的应用中,获取高时间分辨率的真实数据往往是不可行的。为了解决这个问题,所提出的算法采用了零样本学习,即直接利用输入视频本身作为训练数据,无需任何外部样本。这种方法的优势在于能够自动适应输入视频的独特特性,而不需要依赖于预先定义的数据集。
算法采用了一个轻量级的卷积神经网络(CNN),专门针对视频数据进行设计。这个网络保持了较小的感受野,专注于处理小的空间时间补丁(ST-patches)。这种设计选择有助于捕捉视频中的细节信息,并且与ST-patches的递归性相匹配,因为递归性在小补丁上表现得更为明显。
为了有效提高视频的时间分辨率,算法采用了一种粗糙到精细的处理策略。开始时,算法首先对视频进行空间和时间上的降采样,以减少计算复杂度并降低处理难度。随后,网络逐步提高视频的分辨率,从粗略的估计开始,逐渐细化到更精确的输出。

在每个处理阶段,CNN都会从当前的视频分辨率状态中学习,并尝试提高时间分辨率。通过这种方式,网络能够逐步学习如何处理视频中的运动和模糊,最终达到提高时间分辨率的目的。
与传统的监督学习不同,零样本学习不依赖于预先标注好的训练集。相反,它依赖于从输入视频中提取的内部信息来进行自我训练。这种方法使得网络能够专注于学习如何从低时间分辨率的视频恢复出高时间分辨率的视频,而不受外部数据的影响。
由于算法是从输入视频本身提取训练信息,因此它具有很好的泛化能力。这意味着算法不仅能够处理训练时见过的视频类型,还能够适应新的、以前未见过的复杂动态场景。
实验
研究者们首先构建了一个包含25个LTR视频的挑战性数据集,这些视频包含了复杂的快速动态场景,并使用慢速(30fps)视频摄像机进行“记录”,以实现全帧间曝光时间。这些LTR视频是从使用高速摄像机(主要是240fps)记录的真实复杂视频中生成的,通过在时间上模糊和下采样(平均每8帧)来创建。这些视频因其长度较长,提供了大量数据以供比较和评估。
表格中使用了PSNR、SSIM和LPIPS等指标进行定量比较。
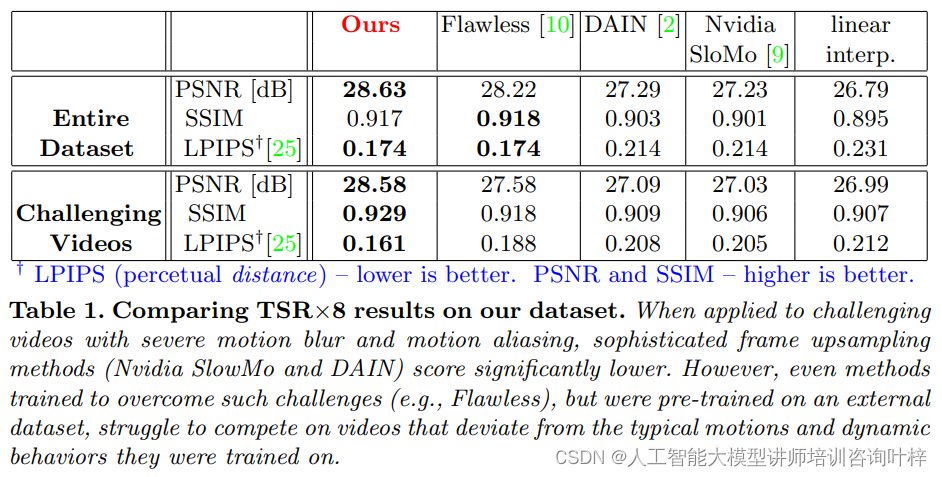
数据集被进一步分为两组:(i) 13个极具挑战性的视频,不仅运动模糊严重,而且还存在严重的运动混叠和/或复杂的高度非刚性运动(例如,飞溅的水,闪烁的火);(ii) 12个较不具挑战性的视频,尽管运动模糊严重,但主要是刚性运动。
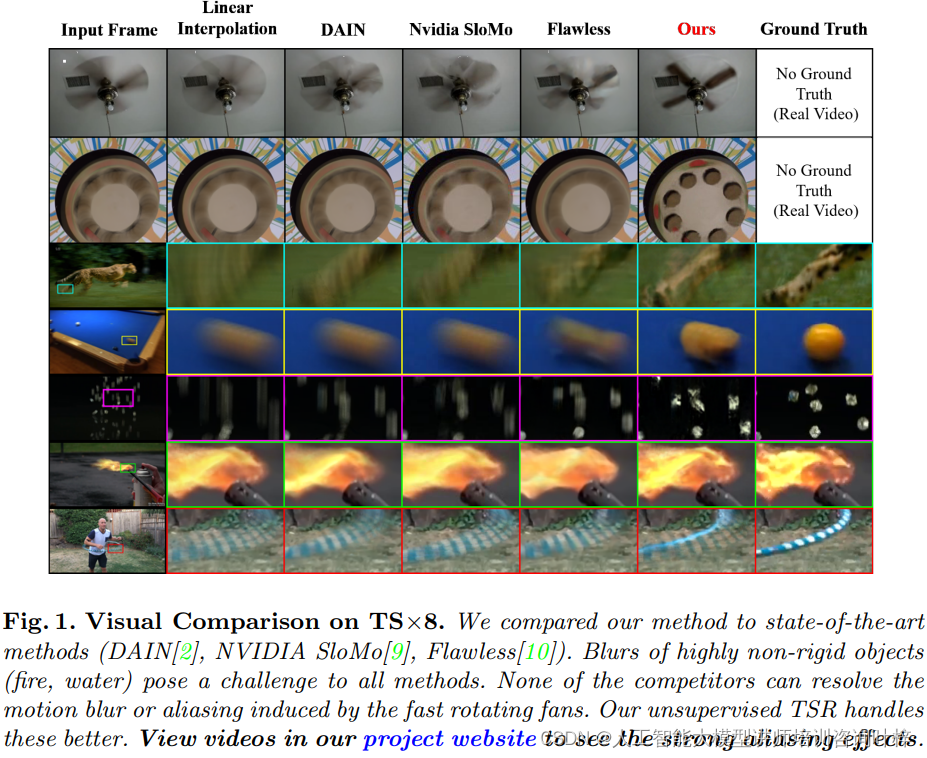
研究者们将所提出的TSR方法与领域内的领先方法(DAIN、NVIDIA SloMo、Flawless)进行了比较。实验结果显示,所有方法在处理复杂动态场景时都面临挑战。特别是,由于快速旋转的风扇/轮子引起的严重运动模糊和严重运动混叠,没有一种方法能够解决这些问题。这些方法不仅恢复的帧极其失真和模糊,而且它们都恢复了错误的运动方向(逆时针旋转),并且旋转速度也是错误的。
研究者们使用峰值信噪比(PSNR)、结构相似性(SSIM)和感知度量(LPIPS)等指标对所有方法在数据集上的性能进行了定量比较。结果表明,尽管Flawless是一个预先训练的监督方法,而本研究所提出的方法是无监督的,不需要任何预先训练的样本,但两者在数据集上提供了可比的定量结果。此外,在极具挑战性的视频子集(高度复杂的非刚性运动)中,无监督的TSR方法优于外部训练的Flawless。
为了检验跨维度增强在提取TSR内部训练样本方面的强大能力,研究者们进行了消融研究。消融研究的结果表明,平均而言,跨维度增强比同一维度内的增强包含更多信息,从而在PSNR、SSIM和LPIPS方面都有所改进。然而,由于不同的视频有不同的偏好,因此使用最佳配置(无论是“内部”、“跨维度”还是两者结合)对每个视频进行训练,可以在所有三个指标上提供额外的整体改进。

深度内部学习是一种创新的时间超分辨率方法,它通过自我训练机制,无需外部数据集即可提高视频的时间分辨率。该方法特别适用于处理包含复杂动态场景的视频,能够显著改善运动模糊和运动混叠问题,超越了以往基于外部视频数据集训练的监督方法。随着技术的不断进步,这种方法有望在未来的视频增强和分析领域发挥重要作用。

