
- 1java.sql.SQLSyntaxErrorException: Unknown column ‘id‘ in ‘field list‘_unknown column 'id' in 'field list
- 2Android ADB工具使用
- 3mySQL创建表_mysql创建一个姓名-密码的表
- 4LaTex的下载与安装超详细windows版_latex下载
- 5呼叫中心系统对接web业务系统实现网页通话能力_web端如何实现打电话功能
- 6uniapp 动态导航栏 原生导航栏 原生导航栏样式动态变化_uniapp tabbar 在設置"navigationstyle": "custom" 顯示
- 7机器人核心期刊及会议_机器人工程看什么英文期刊
- 8AWS re_Invent 2022 - Keynote with Ruba Borno
- 9华为:人工智能HCIA-AI初级笔记:python基础
- 10实现create-react-app react-scripts中的 start 和 build 命令_react-scripts start
【深度学习】一次性分割一切,比SAM更强,华人团队的通用分割模型SEEM来了
赞
踩
本文转载自机器之心。
CV 领域已经卷到了一个新的高度。
本月初,Meta 发布「分割一切」AI 模型 ——Segment Anything Model(SAM)。SAM 被认为是一个通用的图像分割基础模型,它学会了关于物体的一般概念,可以为任何图像或视频中的任何物体生成 mask,包括在训练过程中没有遇到过的物体和图像类型。这种「零样本迁移」的能力令人惊叹,甚至有人称 CV 领域迎来了「GPT-3 时刻」。
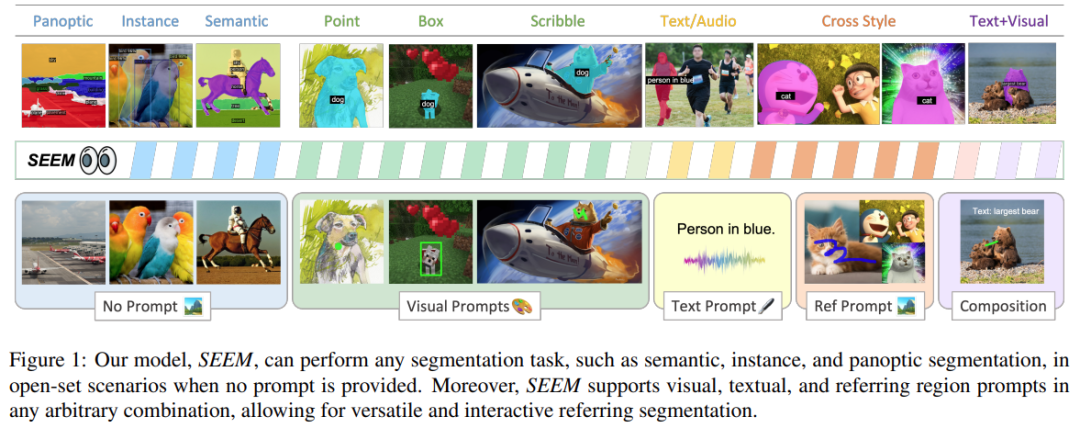
最近,一篇「一次性分割一切」的新论文《Segment Everything Everywhere All at Once》再次引起关注。在该论文中,来自威斯康星大学麦迪逊分校、微软、香港科技大学的几位华人研究者提出了一种基于 prompt 的新型交互模型 SEEM。SEEM 能够根据用户给出的各种模态的输入(包括文本、图像、涂鸦等等),一次性分割图像或视频中的所有内容,并识别出物体类别。
该项目已经开源,并提供了试玩地址供大家体验。

论文链接:https://arxiv.org/pdf/2304.06718.pdf
项目链接:https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
试玩地址:https://huggingface.co/spaces/xdecoder/SEEM
该研究通过全面的实验验证了 SEEM 在各种分割任务上的有效性。即使 SEEM 不具有了解用户意图的能力,但它表现出强大的泛化能力,因为它学会了在统一的表征空间中编写不同类型的 prompt。此外,SEEM 可以通过轻量级的 prompt 解码器有效地处理多轮交互。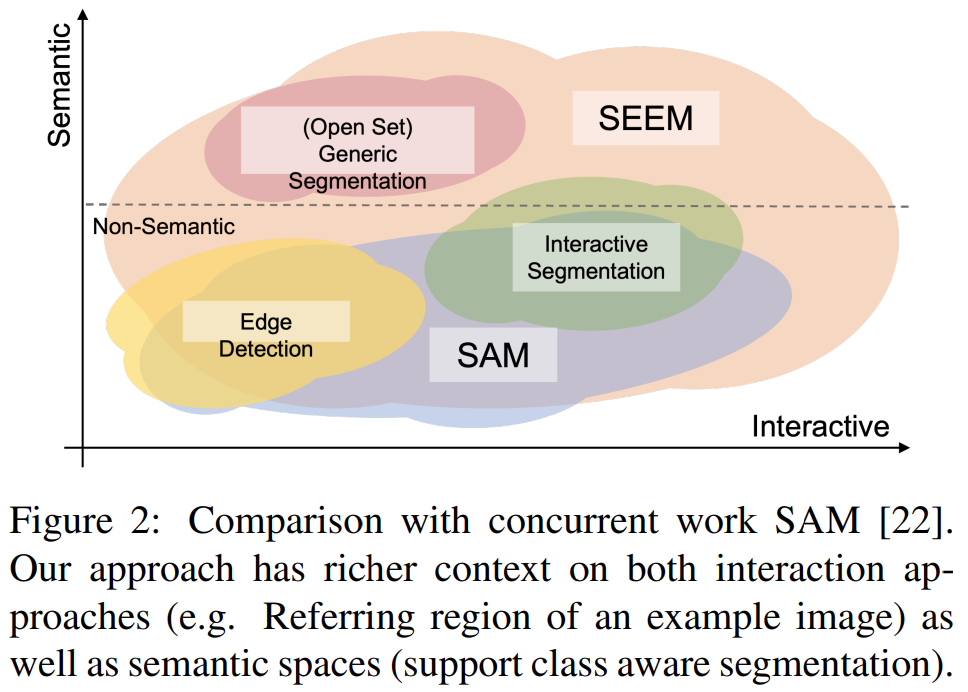
先来看一下分割效果:
在变形金刚的合影中把「擎天柱」分割出来:

还能对一类物体做分割,比如在一张景观图片中分割出所有建筑物:
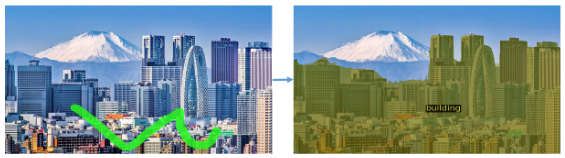
SEEM 也能轻松分割出视频中移动的物体:

这个分割效果可以说是非常丝滑了。我们来看一下该研究提出的方法。
方法概述
该研究旨在提出一个通用接口,以借助多模态 prompt 进行图像分割。为了实现这一目标,他们提出了一种包含 4 个属性的新方案,包括多功能性(versatility)、组合性(compositionality)、交互性(interactivity)和语义感知能力(semantic-awareness),具体包括:
1)多功能性:该研究提出将点、掩码、文本、检测框(box)甚至是另一个图像的参考区域(referred region)这些异构的元素,编码成同一个联合视觉语义空间中的 prompt。
2)组合性:通过学习视觉和文本 prompt 的联合视觉语义空间来即时编写查询以进行推理。SEEM 可以处理输入 prompt 的任意组合。
3)交互性:该研究引入了通过结合可学习的记忆(memory) prompt,并通过掩码指导的交叉注意力保留对话历史信息。
4)语义感知能力:使用文本编码器对文本查询和掩码标签进行编码,从而为所有输出分割结果提供了开放集语义。
架构方面,SEEM 遵循一个简单的 Transformer 编码器 - 解码器架构,并额外添加了一个文本编码器。在 SEEM 中,解码过程类似于生成式 LLM,但具有多模态输入和多模态输出。所有查询都作为 prompt 反馈到解码器,图像和文本编码器用作 prompt 编码器来编码所有类型的查询。
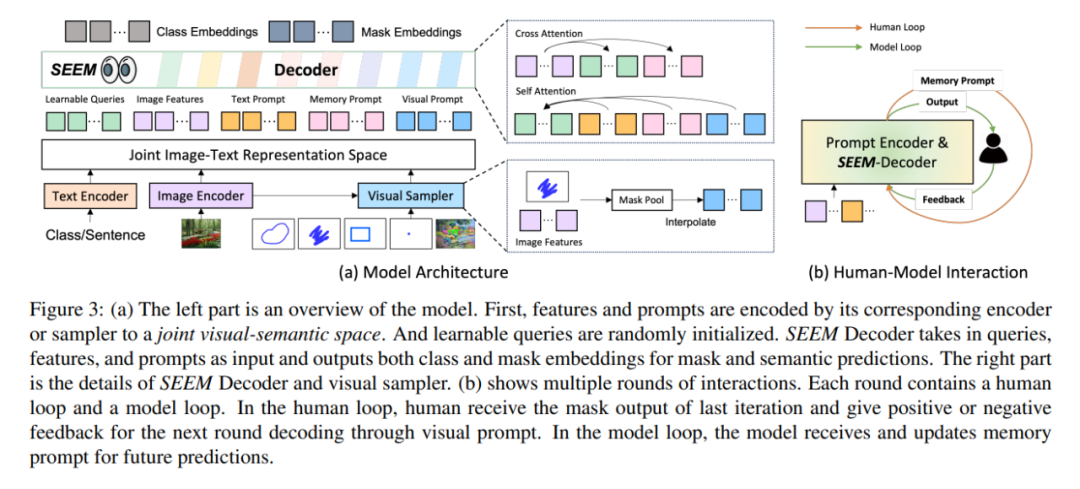
具体来说,该研究将所有查询(如点、框和掩码)编码为视觉 prompt,同时使用文本编码器将文本查询转换为文本 prompt,这样视觉和文本 prompt 就能保持对齐。5 种不同类型的 prompt 都能都映射到联合视觉语义空间中,通过零样本适应来处理未见过的用户 prompt。通过对不同的分割任务进行训练,模型具有处理各种 prompt 的能力。此外,不同类型的 prompt 可以借助交叉注意力互相辅助。最终,SEEM 模型可以使用各种 prompt 来获得卓越的分割结果。
除了强大的泛化能力,SEEM 在运行方面也很高效。研究人员将 prompt 作为解码器的输入,因此在与人类进行多轮交互时,SEEM 只需要在最开始运行一次特征提取器。在每次迭代中,只需要使用新的 prompt 再次运行一个轻量级的解码器。因此,在部署模型时,参数量大运行负担重的特征提取器可以在服务器上运行,而在用户的机器上仅运行相对轻量级的解码器,以缓解多次远程调用中的网络延迟问题。
如上图 3(b)所示,在多轮交互中,每次交互包含一个人工循环和一个模型循环。在人工循环中,人接收上一次迭代的掩码输出,并通过视觉 prompt 给出下一轮解码的正反馈或负反馈。在模型循环中,模型接收并更新记忆 prompt 供未来的预测。
实验结果
该研究将 SEEM 模型与 SOTA 交互式分割模型进行了实验比较,结果如下表 1 所示。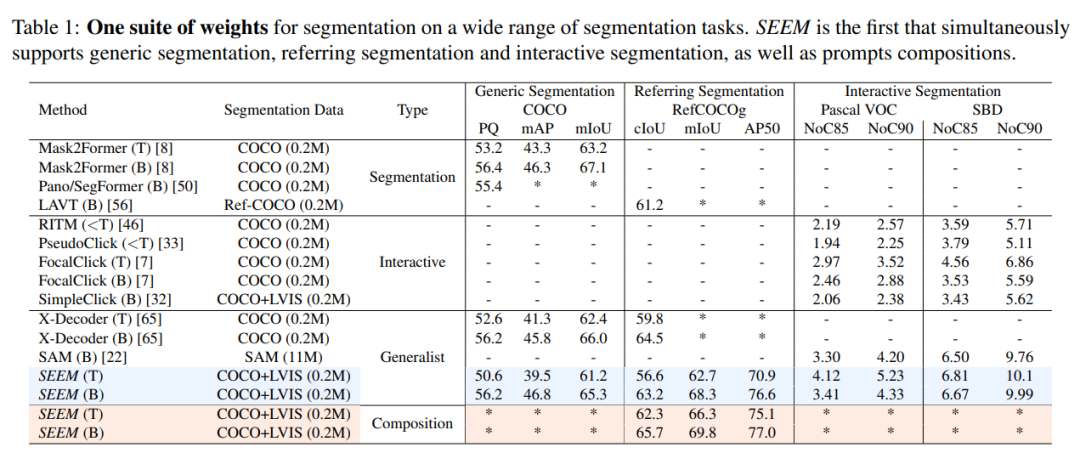
作为一个通用模型,SEEM 实现了与 RITM,SimpleClick 等模型相当的性能,并且与 SAM 的性能非常接近,而 SAM 用于训练的分割数据是 SEEM 的 50 倍之多。
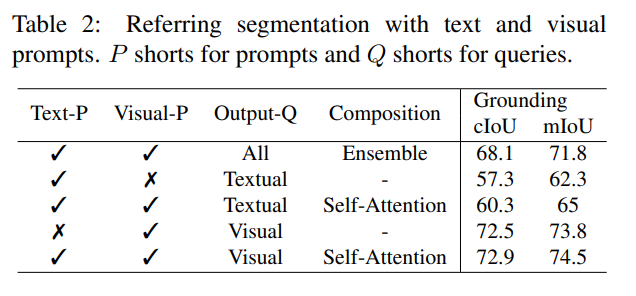
与现有的交互式模型不同,SEEM 是第一个不仅支持经典分割任务,还支持各种用户输入类型的通用接口,包括文本、点、涂鸦、框和图像,提供强大的组合功能。如下表 2 所示,通过添加可组合的 prompt,SEEM 在 cIoU,mIoU 等指标上有了显著的分割性能提升。
我们再来看一下交互式图像分割的可视化结果。用户只需要画出一个点或简单涂鸦,SEEM 就能提供非常好的分割结果
也可以输入文本,让 SEEM 进行图像分割

还能直接输入参考图像并指出参考区域,对其他图像进行分割,找出与参考区域一致的物体:


该项目已经可以线上试玩,感兴趣的读者快去试试吧。

往期精彩回顾
交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)

