
热门标签
热门文章
- 1【nios开发】- 基于Altera(intel) FPGA(cyclone10) NIOS-II Hello World的全流程总结_altera nios 操作系统
- 2关于数据安全中的概念学习——联邦机器学习
- 3socket编程一:socket是什么?套接字是什么?_socket编程 为什么是socket
- 4Hadoop,Hbase启动及用web查看hadoop运行状态_宿主机如何在浏览器中查看虚拟机 hbase状态
- 5Vivado仿真小技巧,让所有模块的波形都可以显示_vivado仿真波形图怎么弄出来
- 6springboot使用neo4j_springboot连接neo4j
- 7【Android】SystemUI通知栏过滤指定应用的通知_systemui状态栏通知图标过滤
- 8Linux 常用命令总结_windows netstat -anp |grep 端口号
- 9LSTM模型+参数调优应用于时间序列数据(含Python代码)_优化lstm模型的方法
- 10从程序员到技术总监的秘诀?饿了么高级总监史海峰访谈
当前位置: article > 正文
PaddleOCR Docker 容器快捷调用,快捷调用OCR API_paddle docker 网络调用
作者:知新_RL | 2024-06-06 00:00:24
赞
踩
paddle docker 网络调用
OCR可以用于清洗数据、文字识别,还是挺有用的,paddleOCR是一个开源的COR工具,效果还是不错的,现在paddleOCR迎来大更新,搞一把新的api接口,直接用起来。直接写调用代码去调用OCR即可,不用关心docker算法启动细节。
如果想直接执行OCR服务,请直接看最后一个章节,启动OCR服务。
搞环境
搞容器:
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04
ENV DEBIAN_FRONTEND=noninteractive
# 安装基本软件包
RUN apt-get update && \
apt-get upgrade -y && \
apt-get -y --no-install-recommends install vim wget curl git build-essential python3.10 python3-pip python3.10-venv sudo && \
update-alternatives --install /usr/bin/python python /usr/bin/python3.10 1 && \
apt-get install -y libgl1 libglib2.0-0
# 安装 tzdata 包并设置时区为上海(无交互)
RUN apt-get update && \
apt-get install -y tzdata && \
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo "Asia/Shanghai" > /etc/timezone
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
docker run -it --gpus all -p 7860:7860 7df2e9c725a9d865ef29b9f8611ee6a2c640a5eb25b6ff5ad66009f4ed9a0947 bash
搞数据:
apt install unzip -y
wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/ppocr_img.zip
unzip ppocr_img.zip
cd ppocr_img
- 1
- 2
- 3
- 4
- 5
搞基础环境:
wget http://nz2.archive.ubuntu.com/ubuntu/pool/main/o/openssl/libssl1.1_1.1.1f-1ubuntu2.20_amd64.deb
sudo dpkg -i libssl1.1_1.1.1f-1ubuntu2.20_amd64.deb
- 1
- 2
搞conda:
wget http://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh
~/miniconda3/bin/conda init
. ~/.bashrc
- 1
- 2
- 3
- 4
搞python:
conda create -n py38 python=3.8 -y
conda activate py38
python -m pip install paddlepaddle-gpu==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "paddleocr>=2.0.1" --upgrade PyMuPDF==1.21.1
conda install numpy=1.20 -y
- 1
- 2
- 3
- 4
- 5
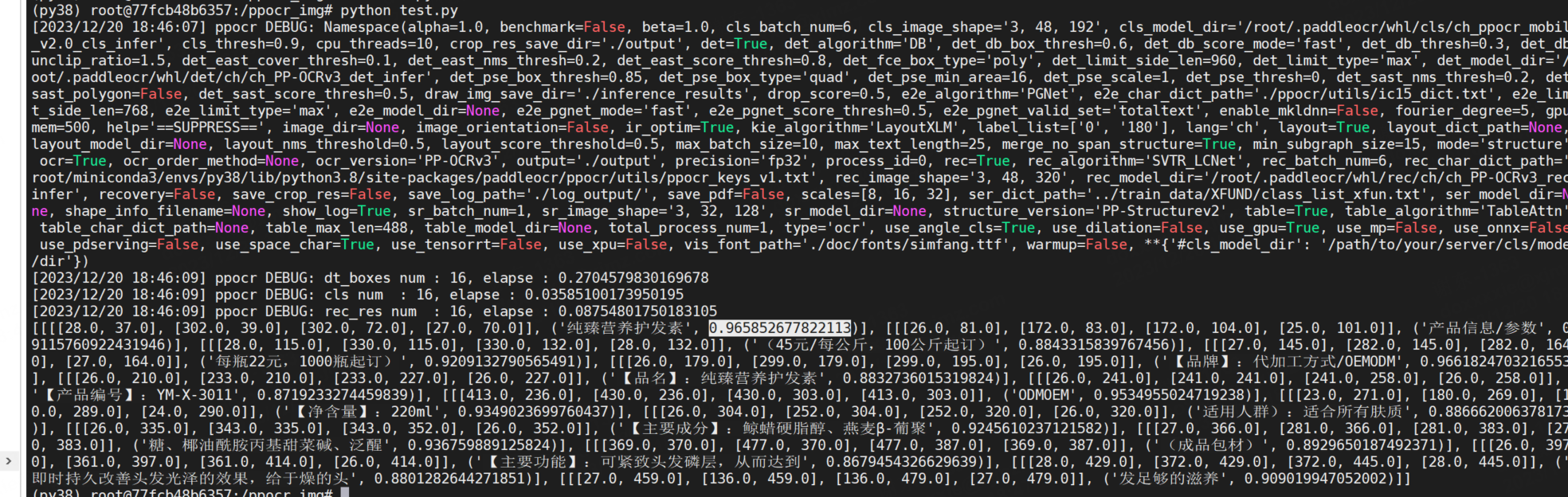
命令行测试
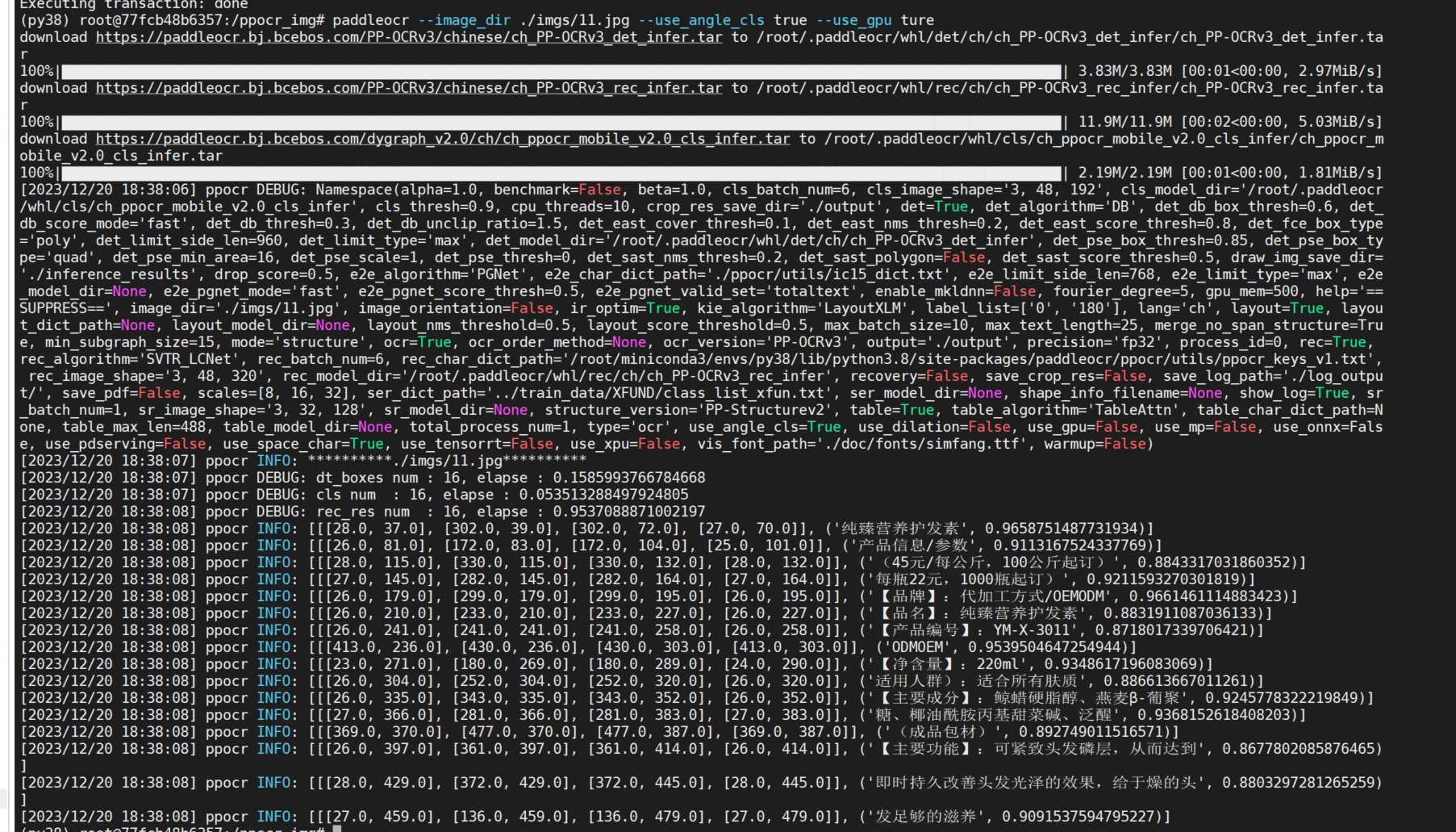
测试:
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu ture
- 1
测试效果:
Python调用测试
from paddleocr import PaddleOCR, draw_ocr
# 定义参数
params = {
#'lang': 'ch, en', # 使用中文和英文模型
#'det_model_dir': '/path/to/your/server/det/model/dir', # 指向服务器上的大模型目录
#'rec_model_dir': '/path/to/your/server/rec/model/dir', # 指向服务器上的大模型目录
#cls_model_dir': '/path/to/your/server/cls/model/dir', # 指向服务器上的大模型目录
'use_gpu': True, # 使用 GPU 执行
'use_angle_cls': True # 进行方向判别
}
# 初始化 OCR 实例
ocr = PaddleOCR(**params)
# 读取图片并进行 OCR
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
print(result )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
转fastapi服务
# python 3.8
pip install fastapi uvicorn python-multipart
- 1
- 2
# main.py
import os
import cv2
import numpy as np
from fastapi import FastAPI, File, UploadFile
from paddleocr import PaddleOCR, draw_ocr
import uvicorn
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
# 初始化 FastAPI 应用
app = FastAPI(
title='PadlleOCR API',
description='基于 PaddleOCR 的 OCR 服务 API 接口',
version='1.0.1',
)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 定义 OCR 参数
params = {
'use_gpu': True,
'use_angle_cls': True
}
# 初始化 OCR 实例
ocr = PaddleOCR(**params)
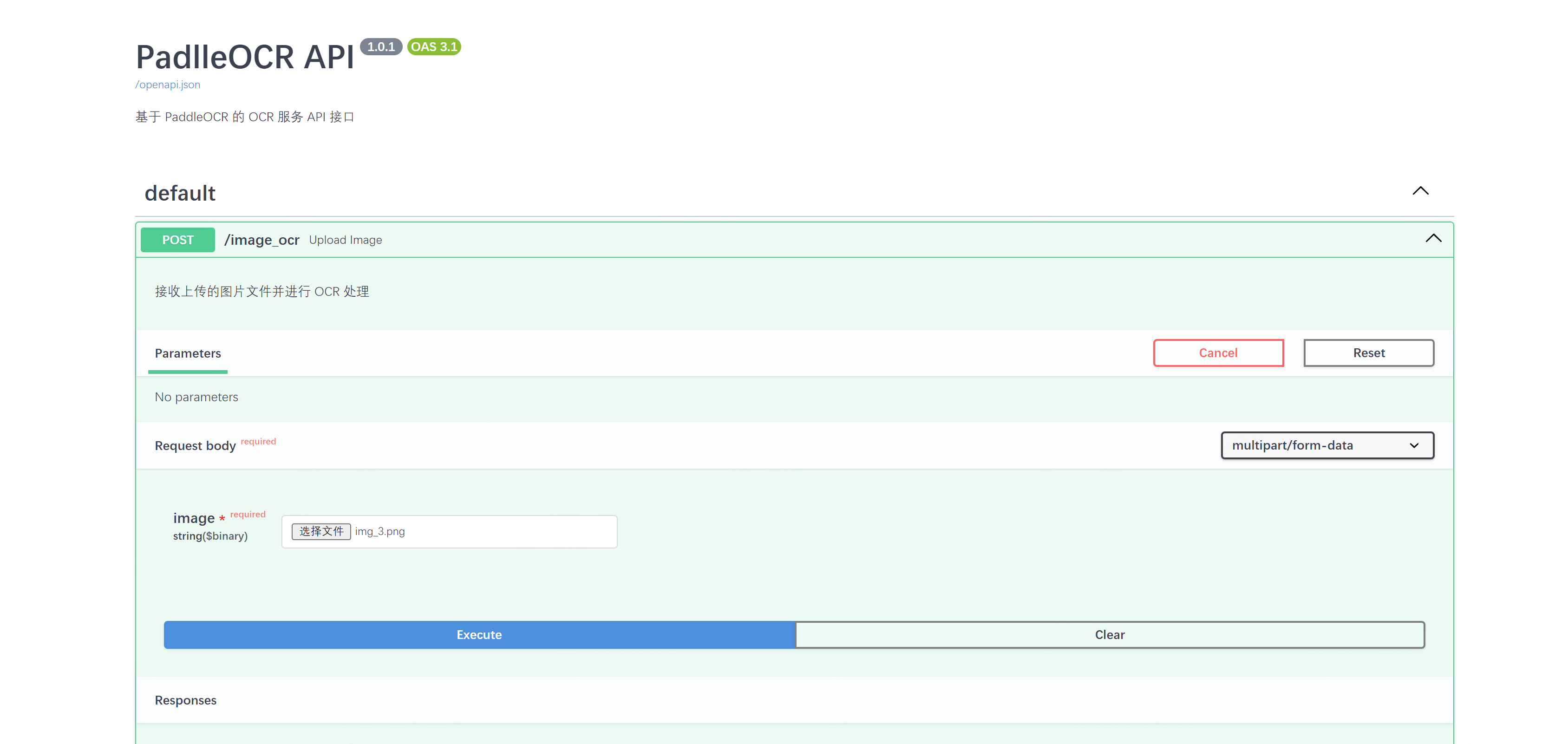
@app.post("/image_ocr")
async def upload_image(image: UploadFile = File(...)):
"""
接收上传的图片文件并进行 OCR 处理
"""
try:
img = cv2.imdecode(np.fromstring(image.file.read(), np.uint8), cv2.IMREAD_COLOR)
# 读取保存的图片并进行 OCR
result = ocr.ocr(img, cls=True)
return result
except:
print("Error")
if __name__ == '__main__':
uvicorn.run(f'{os.path.basename(__file__).split(".")[0]}:app',
host='0.0.0.0',
port=7860,
reload=False,
workers=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
打包成镜像服务
docker commit 77fcb48b6357 kevinchina/deeplearning:paddleocrv4
- 1
Dockerfile
FROM kevinchina/deeplearning:paddleocrv4
EXPOSE 7860
ENTRYPOINT /root/miniconda3/envs/py38/bin/python /ppocr_img/main.py
- 1
- 2
- 3
推到云端:
docker push kevinchina/deeplearning:paddleocrv4_api
- 1
快速启动paddleOCR
启动:
docker run -d --gpus all -p 7860:7860 kevinchina/deeplearning:paddleocrv4_api
- 1
访问:
127.0.0.1:7860/docs
- 1
PaddleOCR 服务端模型
之前采用的都是移动端模型,服务端模型更大,但需要使用CUDA11.6,不然有的算子不支持。
重新制作容器:
FROM nvidia/cuda:11.6.1-cudnn8-devel-ubuntu20.04
ENV DEBIAN_FRONTEND=noninteractive
# 安装基本软件包
RUN apt-get update && \
apt-get upgrade -y && \
apt-get -y --no-install-recommends install vim wget curl && \
apt-get install -y libgl1 libglib2.0-0
# 安装 tzdata 包并设置时区为上海(无交互)
RUN apt-get update && \
apt-get install -y tzdata && \
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo "Asia/Shanghai" > /etc/timezone
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
安装:
python -m pip install paddlepaddle-gpu==2.5.1.post116 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
- 1
dockerfile:
FROM kevinchina/deeplearning:paddleocrv5
EXPOSE 7860
ENTRYPOINT /root/miniconda3/envs/py38/bin/python /ppocr_img/main.py
- 1
- 2
- 3
- 4
模型下载:
https://github.com/PaddlePaddle/PaddleOCR/blob/1b1dc7e44fa4cfbb83c53ee7a844d7f7b467b108/doc/doc_ch/models_list.md#1.1
- 1
代码服务fastapi:
# main.py
import os
import cv2
import numpy as np
from fastapi import FastAPI, File, UploadFile
from paddleocr import PaddleOCR, draw_ocr
import uvicorn
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
# 初始化 FastAPI 应用
app = FastAPI(
title='PadlleOCR API',
description='基于 PaddleOCR 的 OCR 服务 API 接口',
version='1.0.1',
)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 定义 OCR 参数
params = {
'det_model_dir': '/ppocr_img/ch_PP-OCRv4_det_server_infer',
'rec_model_dir': '/ppocr_img/ch_PP-OCRv4_rec_server_infer',
'cls_model_dir': '/ppocr_img/ch_ppocr_mobile_v2.0_cls_slim_infer',
'use_gpu': True,
'use_angle_cls': True
}
# 初始化 OCR 实例
ocr = PaddleOCR(**params)
@app.post("/image_ocr")
async def upload_image(image: UploadFile = File(...)):
"""
接收上传的图片文件并进行 OCR 处理
"""
try:
img = cv2.imdecode(np.fromstring(image.file.read(), np.uint8), cv2.IMREAD_COLOR)
# 读取保存的图片并进行 OCR
result = ocr.ocr(img, cls=True)
return result
except:
print("Error")
if __name__ == '__main__':
uvicorn.run(f'{os.path.basename(__file__).split(".")[0]}:app',
host='0.0.0.0',
port=7860,
reload=False,
workers=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
启动服务即可:
docker run -d --gpus all -p 7860:7860 kevinchina/deeplearning:paddleocrv5_api
- 1
一些修正
发生错误的时候返回错误会更好。
except:
print("Error")
- 1
- 2
所以main.py可以这样写:
# main.py
import os
import cv2
import numpy as np
from fastapi import FastAPI, File, UploadFile
from paddleocr import PaddleOCR, draw_ocr
import uvicorn
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
# 初始化 FastAPI 应用
app = FastAPI(
title='PadlleOCR API',
description='基于 PaddleOCR 的 OCR 服务 API 接口',
version='1.0.1',
)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 定义 OCR 参数
params = {
'det_model_dir': '/ppocr_img/ch_PP-OCRv4_det_server_infer',
'rec_model_dir': '/ppocr_img/ch_PP-OCRv4_rec_server_infer',
'cls_model_dir': '/ppocr_img/ch_ppocr_mobile_v2.0_cls_slim_infer',
'use_gpu': True,
'use_angle_cls': True
}
# 初始化 OCR 实例
ocr = PaddleOCR(**params)
@app.post("/image_ocr")
async def upload_image(image: UploadFile = File(...)):
"""
接收上传的图片文件并进行 OCR 处理
"""
try:
img = cv2.imdecode(np.fromstring(image.file.read(), np.uint8), cv2.IMREAD_COLOR)
# 读取保存的图片并进行 OCR
result = ocr.ocr(img, cls=True)
return result
except:
print("Error")
# 返回HTTP错误码601
raise HTTPException(status_code=601, detail="处理出错")
if __name__ == '__main__':
uvicorn.run(f'{os.path.basename(__file__).split(".")[0]}:app',
host='0.0.0.0',
port=7860,
reload=False,
workers=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
此镜像已经上传,可以这样启用:
docker run -d --gpus 'device=0' -p 7890:7860 kevinchina/deeplearning:paddleocrv5_api002
- 1
总结,直接启动OCR服务
使用小模型的docker 服务【这里使用的是CUDA11.8】:
docker run -d --gpus all -p 7860:7860 kevinchina/deeplearning:paddleocrv4_api
- 1
然后打开127.0.0.1:7860/docs 即可。
使用服务器大一点的模型的docker 服务【CUDA11.6才支持】:
docker run -d --gpus all -p 7860:7860 kevinchina/deeplearning:paddleocrv5_api
- 1
使用服务器大一点的模型的docker 服务,返回错误码601的模型:
docker run -d --gpus 'device=0' -p 7890:7860 kevinchina/deeplearning:paddleocrv5_api002
- 1
然后打开127.0.0.1:7860/docs 即可访问,或者使用python调用此接口。
import requests
def upload_image_for_ocr(file_path):
"""
上传图片并调用OCR接口进行处理
:param file_path: 图片文件路径
:return: OCR处理结果或错误信息
"""
url = "http://10.20.31.16:7890/image_ocr" # 假设服务运行在本地的8000端口
try:
with open(file_path, 'rb') as file:
files = {'image': file}
response = requests.post(url, files=files)
# 检查响应状态码
if response.status_code == 200:
return response.json() # 返回OCR处理结果
elif response.status_code == 601:
return "处理出错" # 返回错误信息
else:
return f"未知错误,状态码:{response.status_code}"
except Exception as e:
return f"发生错误:{e}"
# 调用函数并传入图片路径
file_path = "x000015.jpg" # 替换为您的图片文件路径
result = upload_image_for_ocr(file_path)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/678638
推荐阅读
相关标签

