
- 1【四、性能测试】Linux stress 压力模拟测试工具
- 2k8s之flink的几种创建方式_flink的native kubernetes 模式
- 3ROS高效进阶第五章 -- 机器人语音交互之ros集成科大讯飞星火认知大模型,实现聊天机器人_ros语音调用星火大模型
- 4图像处理-图像滤波
- 5java提高篇(一) java知识汇总-------io流知识汇总(io学习流程)(1)_java学习
- 6毕设开源 Stm32智能家居控制系统(项目+论文)_stm2智能语音家居系统实现功能
- 7决策树与随机森林实验报告(纯Python实现)_决策树算法实验报告python
- 8小红书X-S纯算逆向_小红书x-s算法
- 9uiautomator2+雷电模拟器_uiautomator2 雷电
- 10ISE约束文件UCF与Vivado约束文件XDC FPGA_ise约束文件格式
一维卷积神经网络_人人都能看得懂的卷积神经网络——入门篇
赞
踩
点击蓝字关注我们
近年来,卷积神经网络热度很高,在短时间内,这类网络成为了一种颠覆性技术,打破了从文本、视频到语音多个领域的大量最先进的算法,远远超出其最初在图像处理的应用范围。
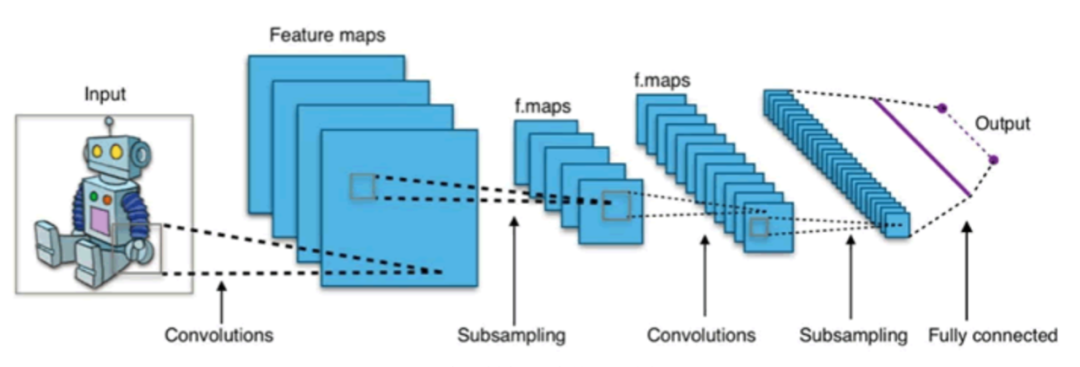
卷积神经网络的一个例子
在客流预测、信号识别等时,深度学习等作为新兴的方法为我们提供了更多的选择,在无需解释参数意义时,往往能提供更精确的预测结果。
因此,笔者将完成对卷积神经网络原理及使用的介绍,在文中将避免复杂的数学公式,以保证其可读性。
ps:本文面向小白,大佬请绕道哦!
关于卷积神经网络
首先,简单介绍一下,人工智能,机器学习,神经网络,深度学习这几个概念的关联。
人工智能:人类通过直觉可以解决,如图像识别、语言理解、语音识别等,但计算机很难解决,而人工智能就是要解决这类问题。
机器学习:如果一个任务可以在任务T上,随着E的增加,效果P也随着增加,那么认为这个程序可以从经验中学习,即机器学习。
神经网络:最初是一个生物学的概念,一般是指大脑神经元,突触等组成的网络,用于产生意识,帮助生物思考和行动,后来人工智能受神经网络的启发,发展出了人工神经网络。所有的人工神经网络本质上就是函数逼近问题,即曲面或函数的拟合。
深度学习:深度学习是机器学习的新方向,其核心就是自动将简单的特征组合成功更加复杂的特征,并用这些特征解决问题。典型的深度学习模型就是很深层的神经网络。
概念之间的关联如下图所示。
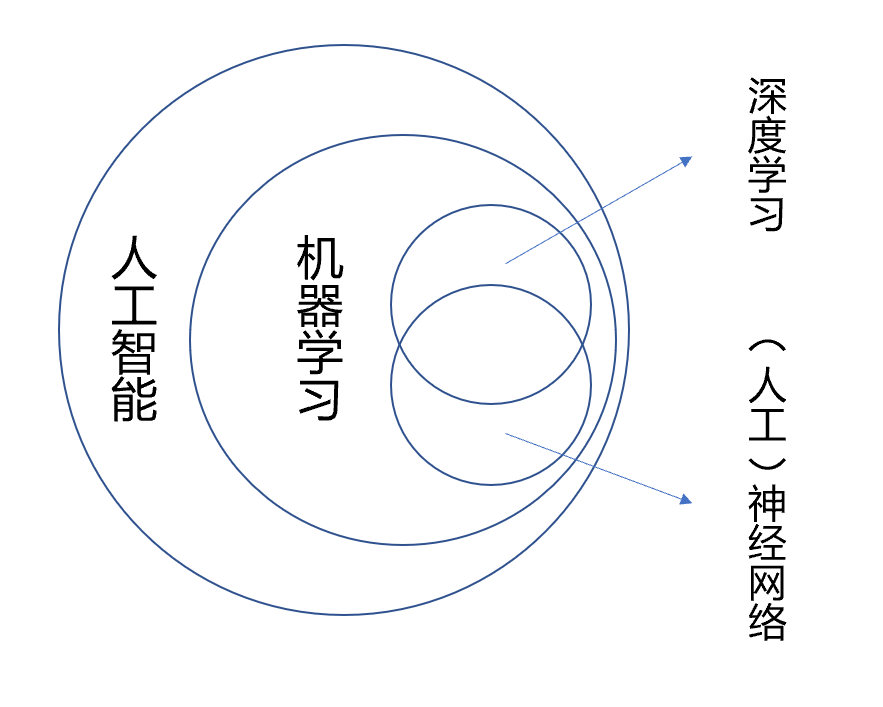
本篇的主角卷积神经网络(Convolutional Neural Networks, CNN)就是典型的深度学习模型,也是一类包含卷积计算且具有深度结构的前馈神经网络。
这里面有两个概念需要解释:
① 前馈神经网络
神经网络包括前馈神经网络和递归神经网络(也称循环神经网络)。前馈指的是网络拓扑结构上不存在环或回路;递归则允许出现环路,如LSTM。
前馈神经网络多处理因果关系的预测;递归神经网络多处理时间序列的预测,网络中的环状结构,可以使其在t时刻的输出状态不仅与t时刻的输入有关,还与t-1时刻的网络状态有关。
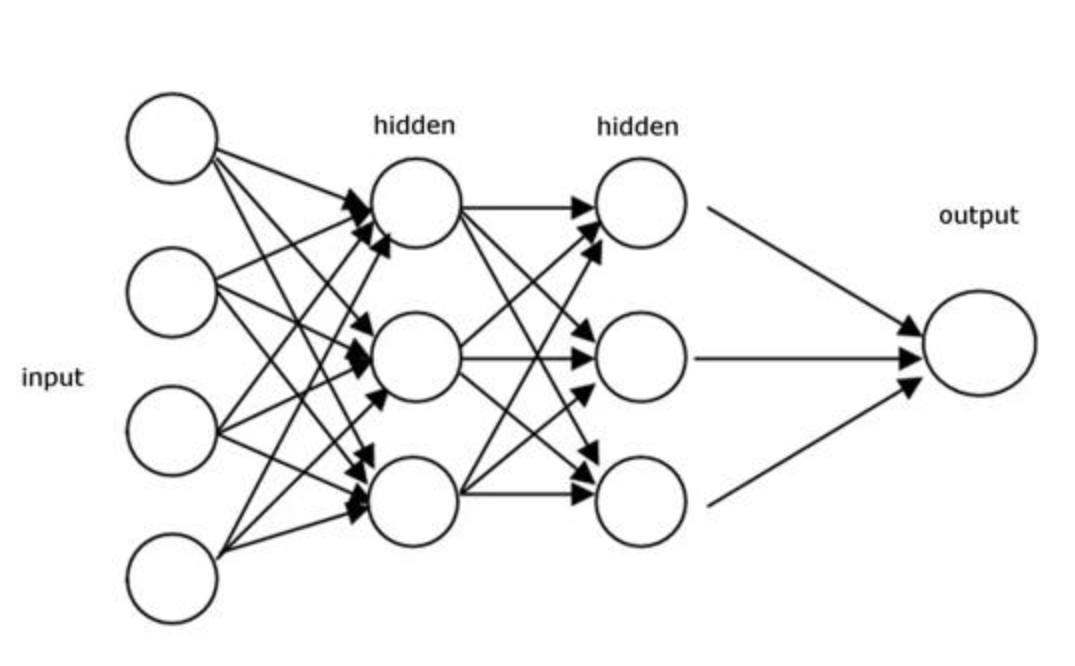
双隐层前馈神经网络
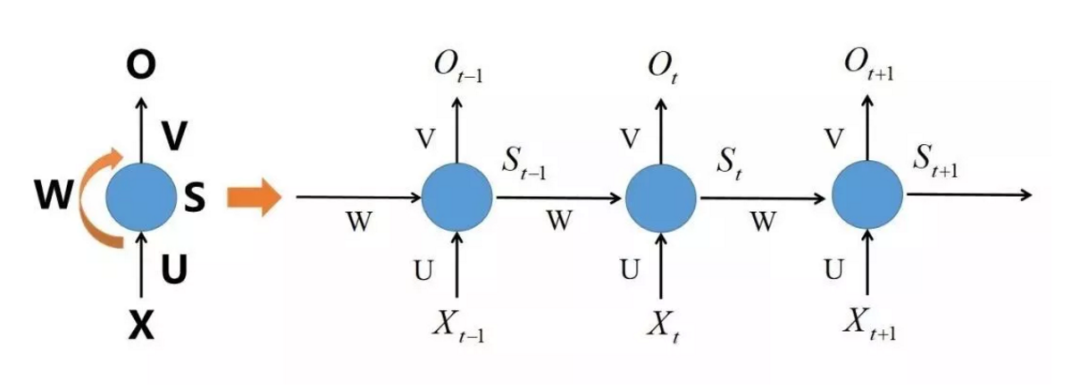
LSTM(具体参数可参考文末链接)
② 卷积
卷积是一种数学运算方式,经常用到的卷积方式包括一维卷积和二维卷积。这里的维度指样本数据的维度。
某种程度上,一维卷积可以理解为移动平均。如下图,输入信号序列,经过滤波器(也称卷积核)[-1,0,1],得到卷积结果。一般而言,滤波器的长度要远小于输入数据的长度,图中连接边上的数字即滤波器的权重。将滤波器与输入序列逐元素相乘以得到输出序列中的一个元素。
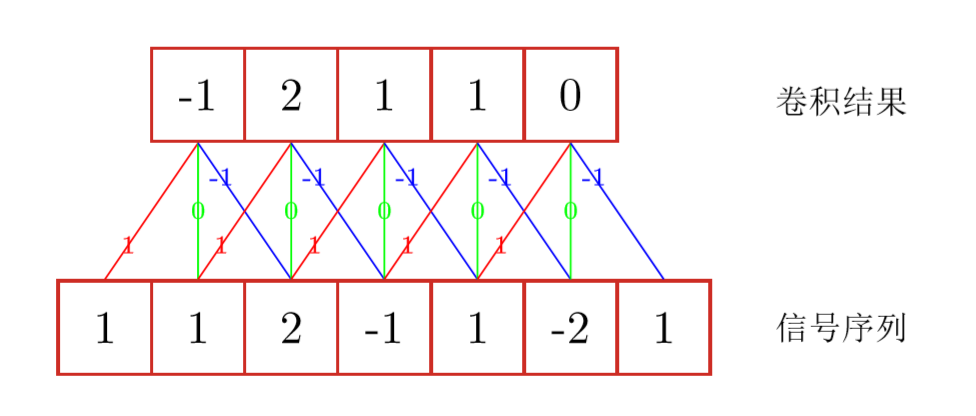
一维卷积示例
同理,二维卷积的输入数据是二维的,即图像处理中经常用到。如下图所示,将滤波器与输入矩阵元素逐个相乘以得到输出矩阵的一个元素,阴影部分为参与卷积的部分数据。
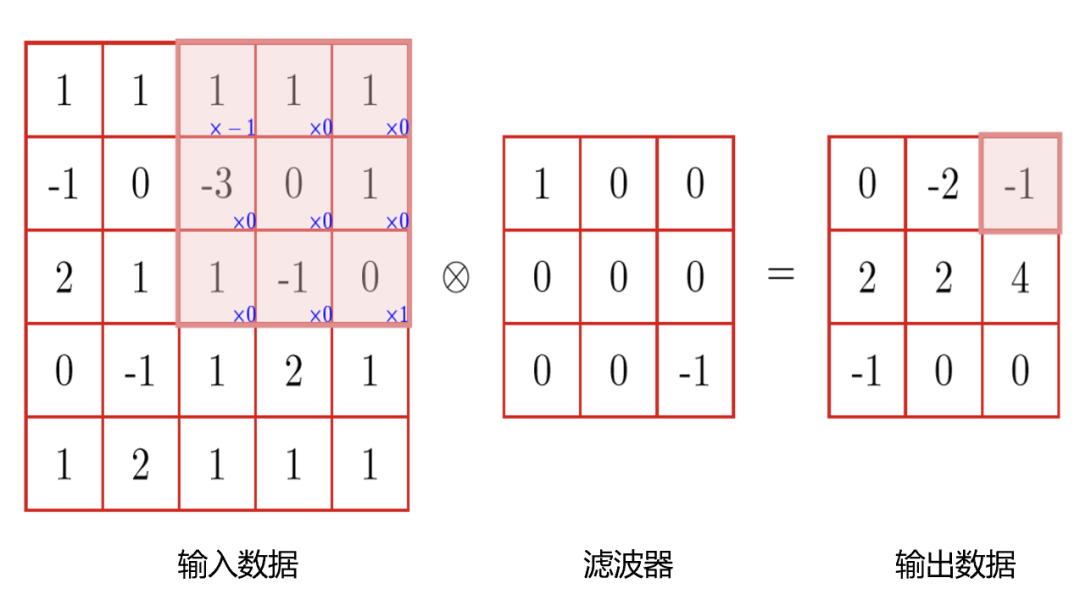
二维卷积示例
关于滤波器的大小、步幅、填充方式均可以自行设定。
一般而言,滤波器的维度要远小于输入数据的维度;
滤波器的步幅,即每次滑动的“距离”,可以是1,也可以大于1,大步幅意味着滤波器应用的更少以及更小的输出尺寸,而小步幅则能保留更多的信息;
至于填充方式,上述示例均为滤波器一旦触及输入数据的边界即停止滑动,而另外一种方式是选择零填充输入,即用0补充输出数据,使输出数据维度与输入数据维度相同。
理解了卷积的含义,我们就可以更能清楚卷积的三个关键动机。
① 感受野
感受野的定义是:卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。如二维卷积示例中的阴影部分即为感受野。
② 共享权重
假设想要从原始像素表示中获得移除与输入图像中位置信息无关的相同特征的能力,一个简单的直觉就是对隐藏层中的所有神经元使用相同的权重。通过这种方式,每层将从图像中学习到独立于位置信息的潜在特征。
③ 池化(也称汇聚)
池化一般包括最大池化和平均池化,如图所示为最大池化的算例。可以看到池化其实就是对输入数据分区域内取最大值或平均值。池化的目的是总结一个特征映射的输出,我们可以使用从单个特征映射产生的输出的空间邻接性,并将子矩阵的值聚合成单个输出值,从而合成地描述与该物理区域相关联的含义。
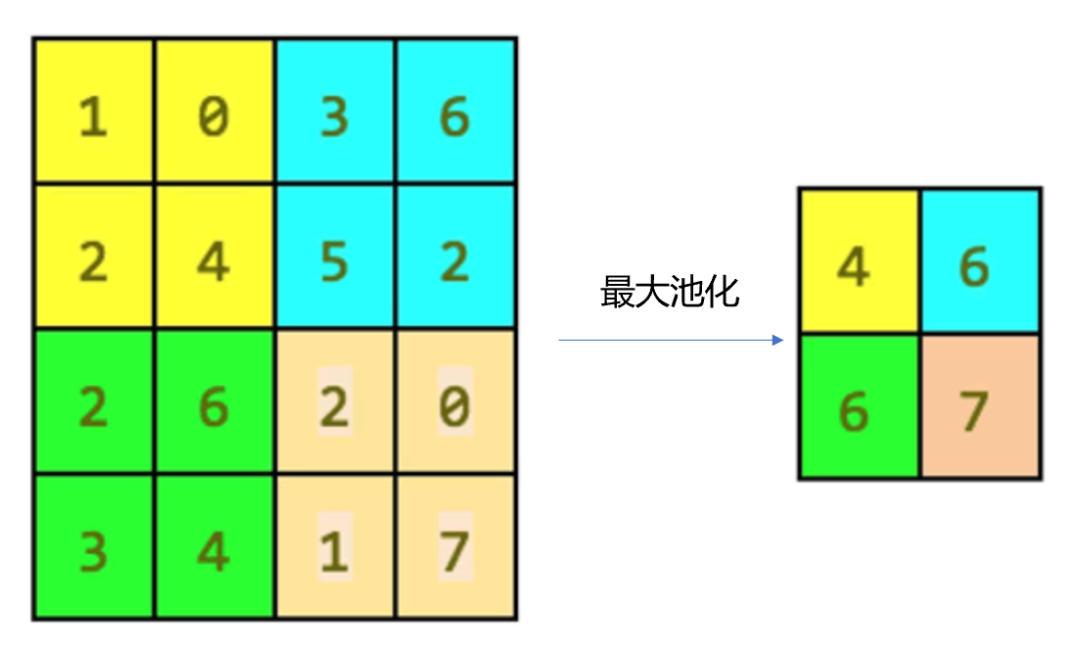
最大池化示例
一个典型的卷积神经网络是由卷积层、池化层、全连接层交叉堆叠而成。如下图所示,图中N个卷积块,M个卷积层,b个池化层(汇聚层),K个全连接层。其中,ReLU为激活函数。
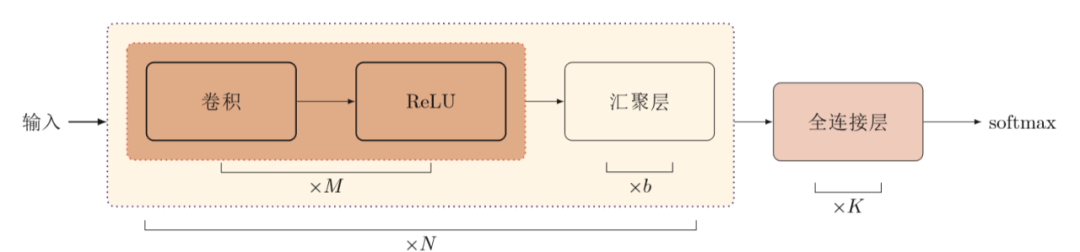
典型的卷积神经网络结构
基于TensorFlow实现CNN
目前主流的深度学习框架包括:Theano、Caffe、TensorFlow、Pytorch、Keras。更多的深度学习框架可以参考:
https://en.wikipedia.org/wiki/Comparison_ of_deep_learning_software
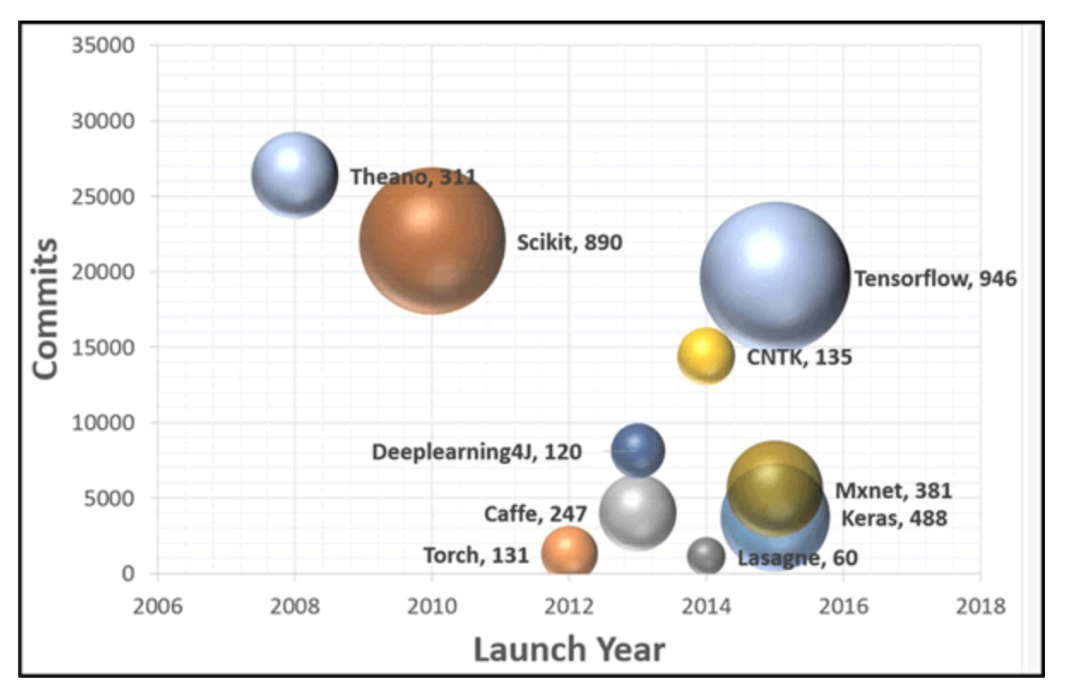
TensorFlow的领先地位示意图
关于TensorFlow和Keras的配置,可参考:
https://blog.csdn.net/lzy_shmily/article/details/80803433
本文将基于TensorFlow实现Mnist手写数据集的识别和预测。
首先,简单介绍下TensorFlow的张量及结构。
① 张量(tensor)
可以理解为一个n维矩阵,所有类型的数据,包括标量(0-D)、向量(1-D)、矩阵(2-D)都是特殊的张量。在TensorFlow中,张量可以分为:常量,变量,占位符。
常量:即值不能改变的张量;
变量:变量需要初始化,但在会话中值也需要更新,如神经网络中的权重;
占位符:无需初始化,仅用于提供训练样本,在会话中与feed_dict一起使用来输入数据。
② TensorFlow结构
可一分为二,计算图的定义和执行两部分,彼此独立。计算图即包含节点和边的网络,包括使用的数据,即张量(常量、变量、占位符),以及需要执行的所有计算(Operation Object,简称 OP)。
而Mnist手写数据集则是机器学习的基础,包含手写数字的图像(0-9)及标签来说明它是哪个数字。同时对输出y使用独热编码(one_hot),如手写数字8,编码为 [0,0,0,0,0,0,0,0,1,0],即输出有10位,且输出仅有一位为1,其余均为0。
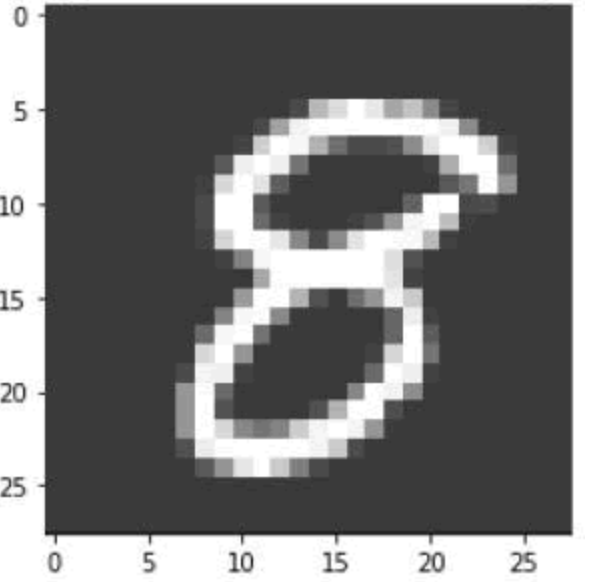
手写数字8的图像
下面是代码部分,使用tensorflow框架搭建神经网络某种程度上可以理解为搭积木~
第一步:导入相应包和数据
import tensorflow as tf# 导入MNIST 数据from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("MNIST_data/",one_hot=True) # 参数—:文件目录,参数二:是否为one_hot向量注意:第一次导入数据时,需要下载,耗时略长~
第二步:搭建网络
数据的输入部分
代码中的x和y均为占位符,即用于提供样本,后续会将网络中涉及到的所有张量和op输出,读者可观察其数据维度的变化。
# 设置计算图输入,定义占位符来存储预测值和真实标签x = tf.placeholder(tf.float32,[None,784]) # 输入# None表示样本数量,之所以使用None,是因为 None 表示张量的第一维度可以是任意维度y = tf.placeholder(tf.int32,[None,10]) #输出print("输入占位符:",x)print("输出占位符:",y)输出:
输入占位符: Tensor("Placeholder_10:0", shape=(?, 784), dtype=float32)输出占位符: Tensor("Placeholder_11:0", shape=(?, 10), dtype=int32)输入层
# 维度:[-1,28,28,1] ,其中:-1表示未知的样本数量,28,28表示图像维度,1表示深度input_x_images = tf.reshape(x,[-1,28,28,1])print("经过reshape后的张量:",input_x_images)输出:
经过reshape后的张量: Tensor("Reshape_13:0", shape=(?, 28, 28, 1), dtype=float32)卷积层1
# 二维卷积层函数:conv2dconv1 = tf.layers.conv2d( inputs = input_x_images, filters = 32, # 滤波器深度32 kernel_size = [5,5], # 滤波器维度[2,2] padding = 'same', # 填充方式为"same",即空余维度的数据用0不全 activation = tf.nn.relu) # 激活函数选择reluprint("经过卷积层1后的张量:",conv1)经过卷积层1后的张量:Tensor("conv2d_8/Relu:0", shape=(?, 28, 28, 32), dtype=float32)(最大)池化层1
# 二维最大池化层函数:max_pooling2dpool1 = tf.layers.max_pooling2d( inputs=conv1, # 输入张量必须有四个维度 pool_size=[2,2], # 池化尺寸 strides=2) # 池化的步幅print("经过池化层1后的张量:",pool1)经过池化层1后的张量:Tensor("max_pooling2d_6/MaxPool:0", shape=(?, 14, 14, 32), dtype=float32)卷积层2
conv2 = tf.layers.conv2d( inputs = pool1, filters = 32, # 滤波器深度32 kernel_size = [2,2], # 滤波器维度[2,2] padding = 'same', # 填充方式为"same",即空余维度的数据用0不全 activation = tf.nn.relu) # 激活函数选择reluprint("经过卷积层2后的张量:",conv1)经过卷积层2后的张量:Tensor("conv2d_8/Relu:0", shape=(?, 28, 28, 32), dtype=float32)(最大)池化层2
pool2 = tf.layers.max_pooling2d( inputs=conv2, # 输入张量必须有四个维度 pool_size=[2,2], # 池化尺寸 strides=2) # 池化的步幅print("经过池化层1后的张量:",pool2)经过池化层1后的张量:Tensor("max_pooling2d_7/MaxPool:0", shape=(?, 7, 7, 32), dtype=float32)平坦化
flat = tf.reshape(pool2,[-1,7*7*32])print("经过平坦化后的张量:",flat)经过平坦化后的张量:Tensor("Reshape_14:0", shape=(?, 1568), dtype=float32)全连接层
dense = tf.layers.dense( inputs=flat, units=1024, # 全连接层的神经元个数 activation=tf.nn.relu)print("经过全连接层后的张量:",dense)输出:
经过全连接层后的张量: Tensor("dense_5/Relu:0", shape=(?, 1024), dtype=float32)Dropout层
# 为防止过拟合,dropout层dropout = tf.layers.dropout( inputs=dense, rate=0.5)print("经过dropout后的张量:",dropout)输出:
经过dropout后的张量: Tensor("dropout_4/Identity:0", shape=(?, 1024), dtype=float32)输出层
# 输出层(本质就是一个全连接层)y_CNN =tf.layers.dense( inputs=dropout, units=10)print("CNN输出张量:",y_CNN)输出:
CNN输出张量: Tensor("dense_6/BiasAdd:0", shape=(?, 10), dtype=float32)关于op (Operation Object),这里主要是误差的反向传播
# 交叉熵损失loss = tf.losses.softmax_cross_entropy(onehot_labels=y,logits=y_CNN)# onehot_labels 为标签值(真实),logits 为神经网络的输出值print("交叉熵损失:",loss)# 训练optrain_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)输出:交叉熵损失:Tensor("softmax_cross_entropy_loss_7/value:0", shape=(), dtype=float32)第三步:执行计算图
# 创建会话sess = tf.Session()# 初始化全局变量和局部变量,使用group结合两个操作init = tf.group( tf.global_variables_initializer(), tf.local_variables_initializer())sess.run(init)training_iters = 2000 # 设置迭代次数step = 1 # 初始化更新次数batch_size = 128display_step = 100 # 每更新50次计算一次损失和精度,并显示while step<=training_iters: batch_x,batch_y = mnist.train.next_batch(batch_size) sess.run(train_op,feed_dict={x:batch_x,y:batch_y}) if step%display_step ==0: loss_train = sess.run(loss,feed_dict={x:batch_x,y:batch_y}) print("step=%d, Train loss=%.4f"%(step,loss_train)) step +=1#测试:打印20个预测值和真实值test_x=mnist.test.images[:3000][:20] #imagetest_y=mnist.test.labels[:3000][:20] #labeltest_output=sess.run(y_CNN,{x:test_x})inferenced_y=np.argmax(test_output,1)print(inferenced_y,'Inferenced numbers')#推测的数字print(np.argmax(test_y,1),'Real numbers')sess.close()输出:
step=100, Train loss=0.1030step=200, Train loss=0.1106step=300, Train loss=0.0607step=400, Train loss=0.0722step=500, Train loss=0.0408step=600, Train loss=0.0366step=700, Train loss=0.0167step=800, Train loss=0.0268step=900, Train loss=0.0632step=1000, Train loss=0.0293step=1100, Train loss=0.0124step=1200, Train loss=0.0131step=1300, Train loss=0.0153step=1400, Train loss=0.0238step=1500, Train loss=0.0200step=1600, Train loss=0.0045step=1700, Train loss=0.0118step=1800, Train loss=0.0220step=1900, Train loss=0.0029step=2000, Train loss=0.0008[7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 5 4] Inferenced numbers[7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 3 4] Real numbers从样本结果可看出,网络仍有较大的优化空间,具体如何优化,这个就留给读者来思考~
关于卷积神经网络的介绍和简单应用就到此结束啦!如果您对卷积神经网络有什么不同的理解,欢迎交流~

参考文献:邱锡鹏. 《神经网络与深度学习》[M]. 清华大学出版社. 2019

【特征工程】:
python实例讲解机器学习中的特征工程(一)
实例讲解机器学习中的特征工程(二)
数据挖掘中重要特征因素筛选方法和实例——机器学习系列(三)
【深度学习】:
深度学习之LSTM 深度学习(LSTM)在交通建模中的应用编辑:庄桢

“交通科研Lab”:分享学习点滴,期待科研交流!

如果觉得还不错
点这里!???


