
- 1PyQt5快速入门教程1-PyQt5开发环境的搭建_pyqt stubs
- 2stm32毕设分享 基于PID控制的智能平衡车 - stm32 物联网 单片机 超详细_stm32自平衡小车pid
- 3python实验题在哪搜题_知到智慧树Python语言应用选择题答案
- 4Leetcode 214. 最短回文串 C++_最短回文串c++
- 5[译] WebSockets 与长轮询的较量
- 6Selenium chromeDriver启动时报错:session not created: This version of ChromeDriver only supports Chrome_org.openqa.selenium.sessionnotcreatedexception: se
- 7GitHub的账号注册教程_gethub注册
- 8KT6368A蓝牙芯片双模BLE透传AT指令的硬件说明_蓝牙双模芯片
- 9git小乌龟的安装及使用_gitxiaowugui安装
- 10离线部署Nginx的安装详细教程+遇到的问题和解决方法_离线安装nginx
大数据入门-大数据技术概述(一)_大数据基础
赞
踩
====
大数据技术是指在构架大数据平台的时候需要的技术。包含存储系统,数据库,数据仓库,资源调度,查询引擎,实时框架等。下面以我目前所了解到的一些技术做简要介绍。目前之介绍简单概念。
二、技术详解
======
1.基础架构:Hadoop
1.架构
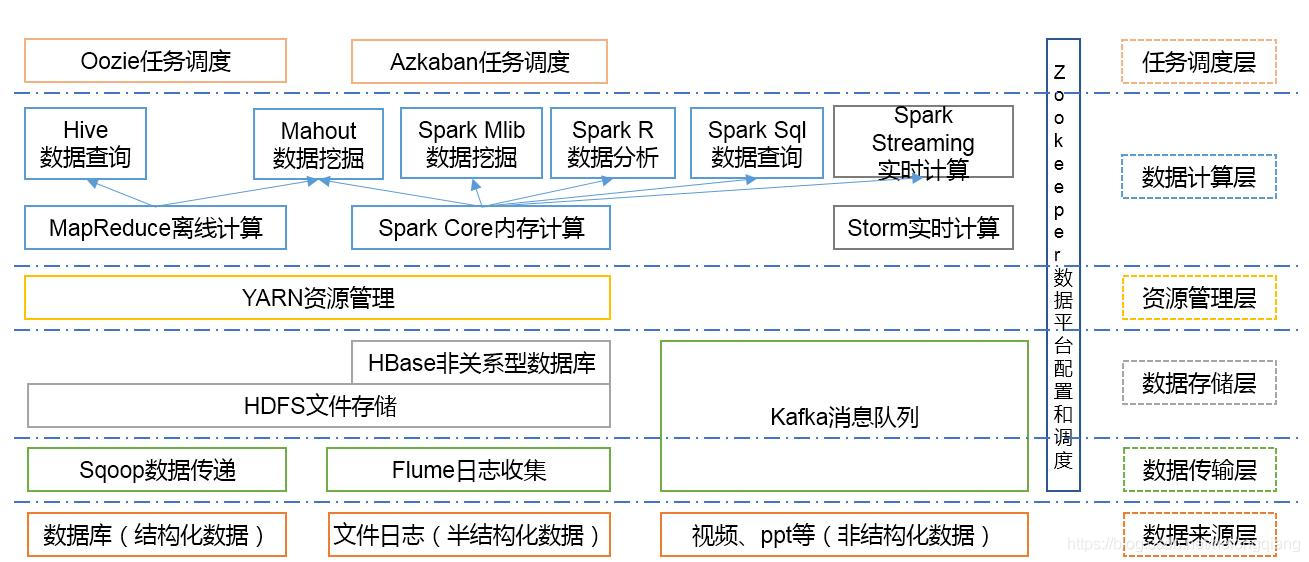
2.简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
2.分布式文件系统:HDFS
1.HDFS架构
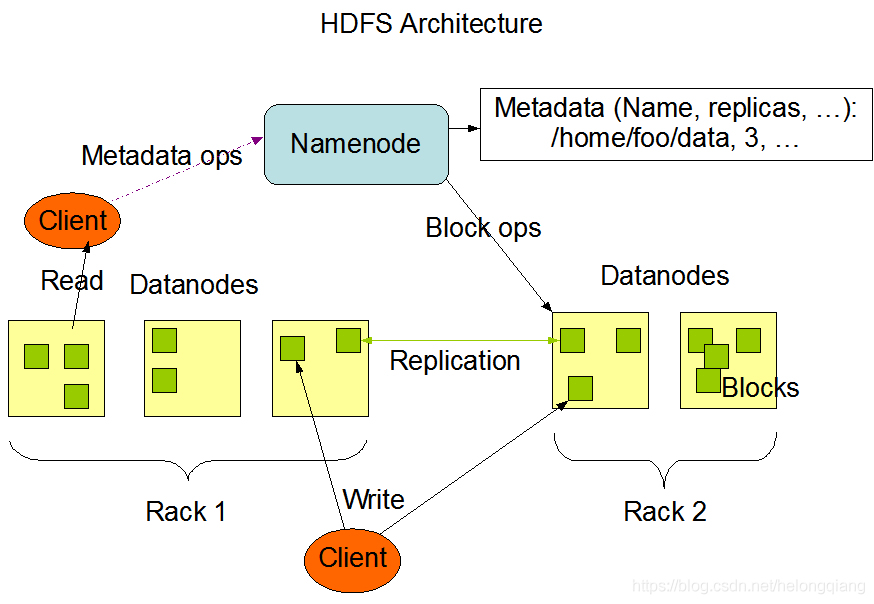
2.简介
指被设计成适合运行在通用硬件上的分布式文件系统。
3.特点
HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。
3.数据仓库:Hive
1.架构
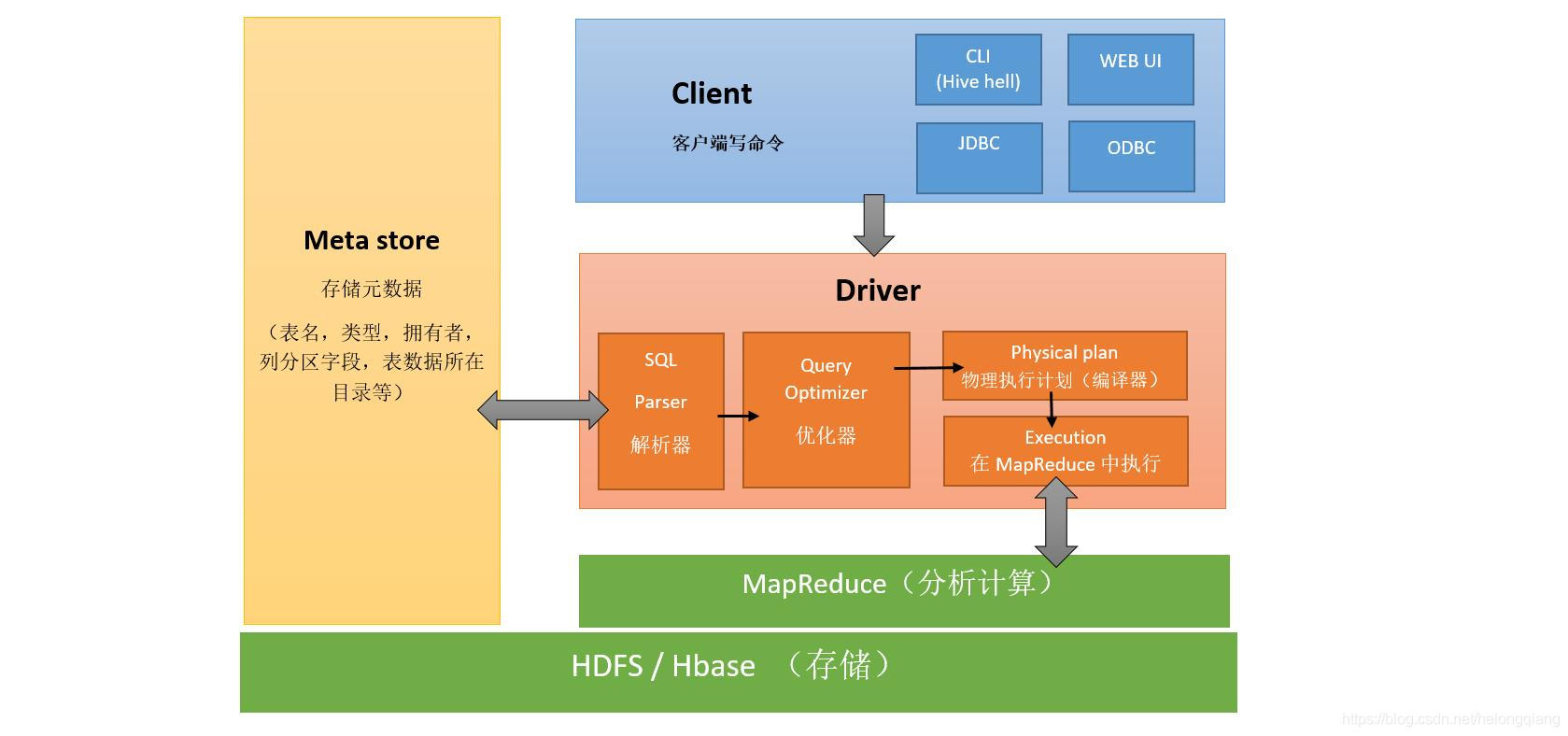
2.简介
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
3.特点
执行过程走MapReduce比较慢,处理规模大,可扩展性高,加载模式为读时模式。后面就MapReduce会做专门的解释。
4.存储引擎:Kudu
1.架构

2.简介
Apache Kudu是由Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。Kudu支持水平扩展,使用Raft协议进行一致性保证,并且与Cloudera Impala和Apache Spark等当前流行的大数据查询和分析工具结合紧密。
3.特点
支持随机读写,支持OLAP 分析,太多列查询时性能下降,跟关系型数据有点类似。其存储文件不在HDFS上面,有自己的存储文件系统。
5.分布式数据库:HBase
1.架构
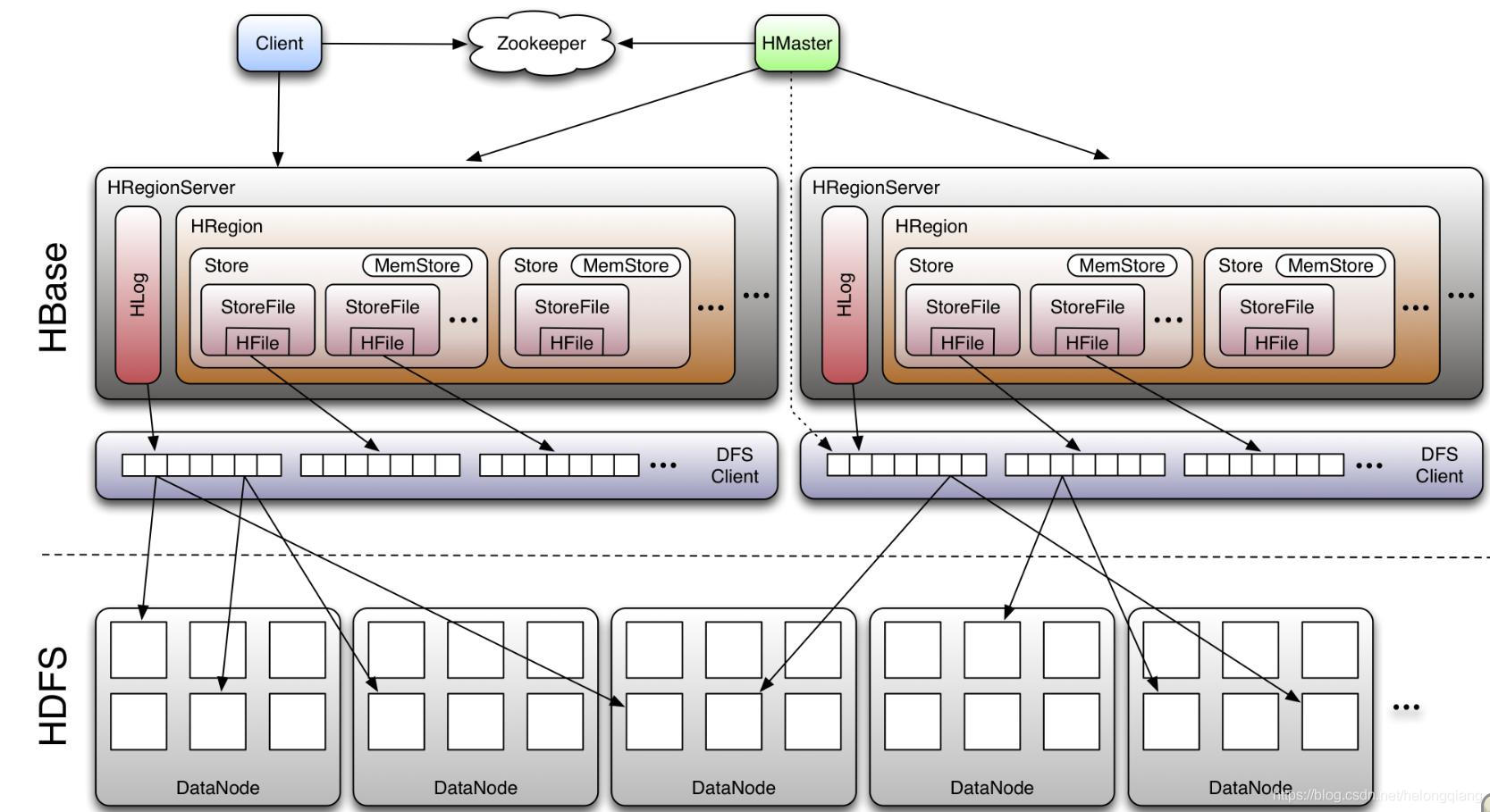
2.简介
HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。
3.特点
高可靠、高性能、面向列、可伸缩。
6.实时框架:Flink
1.架构
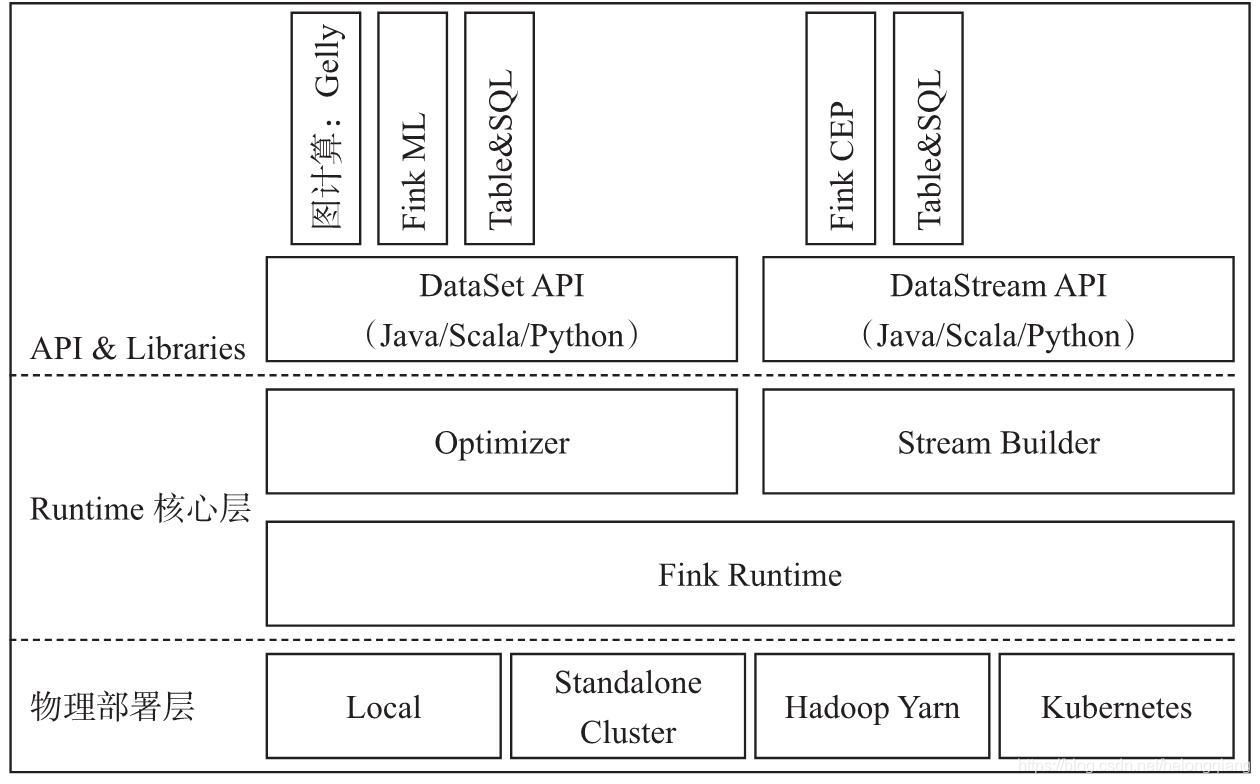
2.简介
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结
本文从基础到高级再到实战,由浅入深,把MySQL讲的清清楚楚,明明白白,这应该是我目前为止看到过最好的有关MySQL的学习笔记了,我相信如果你把这份笔记认真看完后,无论是工作中碰到的问题还是被面试官问到的问题都能迎刃而解!
MySQL50道高频面试题整理:

《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
看完后,无论是工作中碰到的问题还是被面试官问到的问题都能迎刃而解!
MySQL50道高频面试题整理:
[外链图片转存中…(img-JNKknXB3-1712423630370)]
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!

