
- 1用evo工具评估SLAM轨迹_slam估计轨迹怎么得到
- 2第7章 Python字符串处理_使用单引号定义 1 个字符串变量,使得 print 输出后的结果对齐
- 3软考中级信息系统监理师(第二版)-第4章信息资源系统_信息系统监理师第二版教程电子版
- 4mysql connector c++ 使用_MySQL Connector/C++ 使用 | 学步园
- 5大数据从入门到实战——Hive综合应用案例 ——学生成绩查询_第1关:计算每个班的语文总成绩和数学总成绩
- 6android 后台运行服务之创建后台服务篇_编制一个在安卓手机后台运行的程序
- 7快速上手Python数据分析——Matplotlib要点总结
- 8编写一个录音软件,使用AudioRecorder录制音频,并使用MediaCodeC编码(aac格式),编码封装成mp4文件,保存到对应目录_mediacodec 保存mp4
- 9智谱AI大模型ChatGLM3-6B更新,快來部署体验_智谱 ai 开源
- 10vmware安装龙蜥操作系统
Python爬虫以及数据可视化分析!这才是零基础入门案例!_python爬虫+可视化
赞
踩
def main():
url = ‘https://www.bilibili.com/v/popular/rank/bangumi’ # 网址
html = get_html(url) # 获取返回值
print(html) # 打印
if __name__ == ‘__main__’: #入口
main()
爬取结果如下图所示:
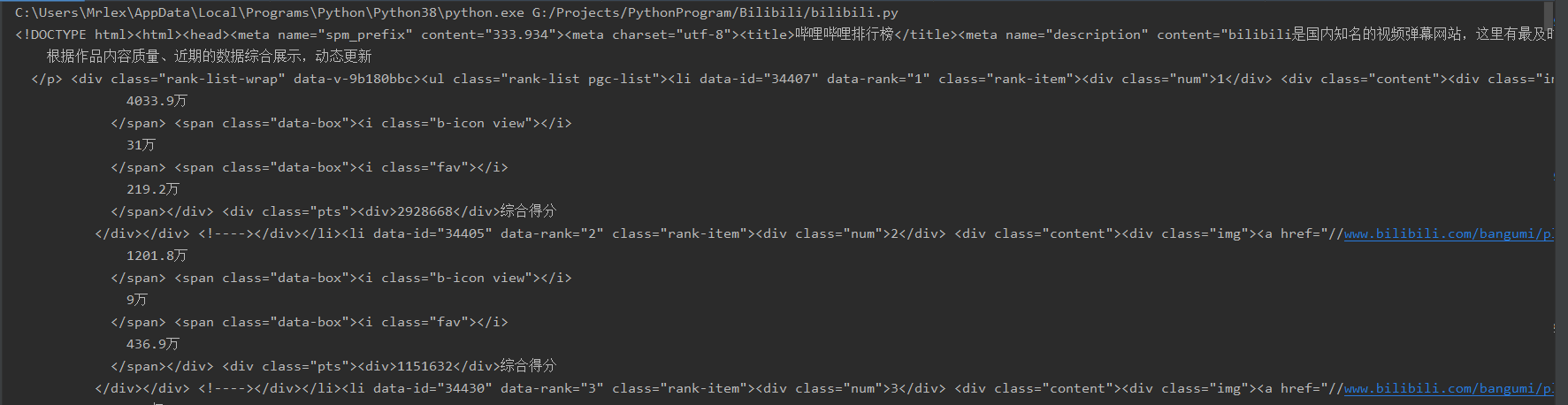
成功!
二、信息解析阶段:
第一步,先构建BeautifulSoup实例
soup = BeautifulSoup(html, ‘html.parser’) # 指定BeautifulSoup的解析器
第二步,初始化要存入信息的容器
# 定义好相关列表准备存储相关信息
TScore = [] # 综合评分
name = [] # 动漫名字
play= [] # 播放量
review = [] # 评论数
favorite= [] # 收藏数
第三步,开始信息整理
我们先获取番剧的名字,并将它们先存进列表中
# ******************************************** 动漫名字存储
for tag in soup.find_all(‘div’, class_=‘info’):
print(tag)
bf = tag.a.string
name.append(str(bf))
print(name)
此处我们用到了beautifulsoup的find_all()来进行解析。在这里,find_all()的第一个参数是标签名,第二个是标签中的class值(注意下划线哦(class_=‘info’))。 我们在网页界面按下F12,就能看到网页代码,找到相应位置,就能清晰地看见相关信息:
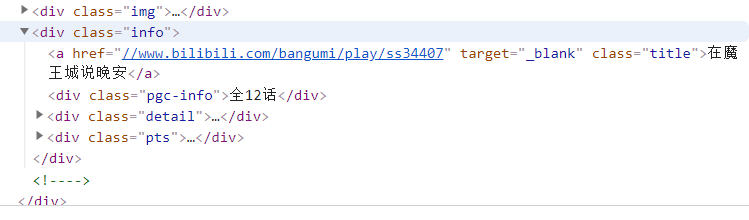
接着,我们用几乎相同的方法来对综合评分、播放量,评论数和收藏数来进行提取
# ******************************************** 播放量存储
for tag in soup.find_all(‘div’, class_=‘detail’):
print(tag)
bf = tag.find(‘span’, class_=‘data-box’).get_text()
统一单位为‘万’
if ‘亿’ in bf:
num = float(re.search(r’\d(.\d)?', bf).group()) * 10000
print(num)
bf = num
else:
bf = re.search(r’\d*(\.)?\d’, bf).group()
play.append(float(bf))
print(play)
******************************************** 评论数存储
for tag in soup.find_all(‘div’, class_=‘detail’):
pl = tag.span.next_sibling.next_sibling
pl = tag.find(‘span’, class_=‘data-box’).next_sibling.next_sibling.get_text()
*********统一单位
if ‘万’ not in pl:
pl = ‘%.1f’ % (float(pl) / 10000)
print(123, pl)
else:
pl = re.search(r’\d*(\.)?\d’, pl).group()
review.append(float(pl))
print(review)
******************************************** 收藏数
for tag in soup.find_all(‘div’, class_=‘detail’):
sc = tag.find(‘span’, class_=‘data-box’).next_sibling.next_sibling.next_sibling.next_sibling.get_text()
sc = re.search(r’\d*(\.)?\d’, sc).group()
favorite.append(float(sc))
print(favorite)

