
- 1算法设计:2.向下取整、向上取整符号_向上取整和向下取整
- 2crossover永久试用mac crossover试用期限已到还能用吗_银河麒麟crossover超过15天后续期方法
- 3[收藏] 三种 无限级分类 的数据库设计方案(菜单,,权限管理)_数据库无限层级分类设计方案
- 4先进先出页面置换算法详解_先进先出算法流程图
- 5注册Github账号详细教程【超详细篇--适合新手入门】_建立github账户
- 6【服务器部署系列-001】java环境部署_正式环境部署可以用java -jar方式部署吗
- 7多数据源 dynamic-datasource 模块使用_多数据源datasource如何使用
- 8macbook无法打开移动硬盘 为什么mac上显示不了移动硬盘_mac 移动硬盘不识别 磁盘管理也看不到
- 9SpringAMQP创建交换机和队列_java 使用spring qmpa 创建队列和交换机
- 10git 设置对文件名称大小写不敏感_git 大小写不敏感
Flink 内容分享(九):Flink生产环境相关问题_flink生产中遇到的问题
赞
踩
目录
2. 你们的Flink怎么提交的?使用的per-job模式吗?
3. 了解过Flink的两阶段提交策略吗?讲讲详细过程。如果第一阶段宕机了会怎么办?第二阶段呢?
6. Flink的checkpoint文件是保存在哪里, 可以选择哪些?
7. Flink 维表关联怎么做的(应该是开发必做,建议提前准备)
14. Flink的怎么和RocksDB交互的。怎样一个流程?
20. Flink的boardcast join 的原理是什么?
23. 你们用Flink怎么去开发一些checkpoint的超时问题?
1. Flink+Kafka保证精确一次消费相关问题?
Fink的检查点和恢复机制和可以重置读位置的source连接器结合使用,比如kafka,可以保证应用程序不会丢失数据。尽管如此,应用程序可能会发出两次计算结果,因为从上一次检查点恢复的应用程序所计算的结果将会被重新发送一次(一些结果已经发送出去了,这时任务故障,然后从上一次检查点恢复,这些结果将被重新计算一次然后发送出去)。这个时候需要下层sink做到幂等性或者事务。
所以· souce:使用执行ExactlyOnce的数据源,比如kafka等 · 内部使用FlinkKafakConsumer,并开启CheckPoint,偏移量会保存到StateBackend中,并且默认会将偏移量写入到topic中去,即_consumer_offsets Flink设置CheckepointingModel.EXACTLY_ONCE · sink:存储系统支持覆盖也即幂等性:如Redis,Hbase,ES等 存储系统不支持覆:需要支持事务(预写式日志或者两阶段提交),两阶段提交可参考Flink集成的kafka sink的实现。
2. 你们的Flink怎么提交的?使用的per-job模式吗?
| 模式 | 生命周期 | 资源隔离 | 优点 | 缺点 | main方法 |
|---|---|---|---|---|---|
| Session | 关闭会话,才会停止 | 共用JM和TM | 预先启动,启动作业不再启动。资源充分共享 | 资源隔离比较差,TM不容易扩展 | 在客户端执行 |
| Per-job | Job停止,集群停止 | 单个Job独享JM和TM | 充分隔离,资源根据job按需申请 | job启动慢,每个job需要启动一个JobManager | 在客户端执行 |
| Application | 当Application全部执行完,集群才会停止 | Application使用一套JM和TM | Client负载低,Application之间实现资源隔离,Application内实现资源共享 | 对per-job模式和session模式的优化部署模式(优点) | 在Cluster中 |
3. 了解过Flink的两阶段提交策略吗?讲讲详细过程。如果第一阶段宕机了会怎么办?第二阶段呢?
顾名思义,2PC将分布式事务分成了两个阶段,两个阶段分别为提交请求和提交。协调者根据参与者的响应来决定是否需要真正地执行事务
提交请求阶段· 协调者向所有参与者发送prepare请求与事务内容,询问是否可以准备事务提交,并等待参与者的响应。· 参与者执行事务中包含的操作,并记录undo日志(用于回滚)和redo日志(用于重放),但不真正提交。· 参与者向协调者返回事务操作的执行结果,执行成功返回yes,否则返回no
提交执行阶段分为成功与失败两种情况。若所有参与者都返回yes,说明事务可以提交:· 协调者向所有参与者发送commit请求。· 参与者收到commit请求后,将事务真正地提交上去,并释放占用的事务资源,并向协调者返回ack。· 协调者收到所有参与者的ack消息,事务成功完成。若有参与者返回no或者超时未返回,说明事务中断,需要回滚:· 协调者向所有参与者发送rollback请求 · 参与者收到rollback请求后,根据undo日志回滚到事务执行前的状态,释放占用的事务资源,并向协调者返回ack · 协调者收到所有参与者的ack消息,事务回滚完成
对于Flink sink是kafka为例
每当需要做checkpoint时,JobManager就在数据流中打入一个屏障(barrier),作为检查点的界限。屏障随着算子链向下游传递,每到达一个算子都会触发将状态快照写入状态后端(state BackEnd)的动作。
当屏障到达Kafka sink后,触发preCommit(实际上是KafkaProducer.flush())方法刷写消息数据,但还未真正提交。接下来还是需要通过检查点来触发提交阶段。
第一阶段宕机,这个时候offset没有提交,重新启动会按offset继续消费和从状态中恢复状态值。
第二阶段宕机,分两种情况,在提交阶段后宕机,因为这个链路已经处理完,重新启动会按offset继续消费。在checkpint完成后宕机,还没有来得及触发提交阶段,这个时候可能会出现丢数据情况,这个时候有学者提出了三阶段提交。
4. 你是如何通过Flink实现uv的?
用户id刚好是数字,可以使用bitmap去重,简单原理是:把 user_id 作为 bit 的偏移量 offset,设置为 1 表示有访问,使用 1 MB的空间就可以存放 800 多万用户的一天访问计数情况。
- val bloomFilter = new Bloom(1<<29)
- // 先定义redis中存储位图的key
- val storedBitMapKey = "xxxxx"
- // 去重:判断当前userId的hash值对应的位图位置,是否为0
- val userId = elements.last._2.toString
- // 计算hash值,就对应着位图中的偏移量
- val offset = bloomFilter.hash(userId, 61)
- val isExist = jedis.getbit(storedBitMapKey, offset)
-
-
- class Bloom(size: Long) extends Serializable{
- private val cap = size // 默认cap应该是2的整次幂
-
- //hash函数 value即userid,seed随机数种子
- def hash(value: String, seed: Int): Long = {
- var result = 0
- //遍历userid,对每一位进行随机数种子的处理
- for( i <- 0 until value.length ){
- result = result * seed + value.charAt(i)
- }
- // 返回hash值,要映射到cap范围内
- (cap - 1) & result
- }
- }

当然还有:Flink自带BloomFilter, google现成的布隆过滤器。
5. Flink中的双流join怎么实现?
Flink双流JOIN主要分为两大类。一类是基于原生State的Connect算子操作,另一类是基于窗口的JOIN操作。其中基于窗口的JOIN可细分为window join和interval join两种。
实现原理:底层原理依赖Flink的State状态存储,通过将数据存储到State中进行关联join, 最终输出结果。
Window join
将两条实时流中元素分配到同一个时间窗口中完成Join。底层原理: 两条实时流数据缓存在Window State中,当窗口触发计算时,执行join操作。源码核心总结:windows窗口 + state存储 + 双层for循环执行join()
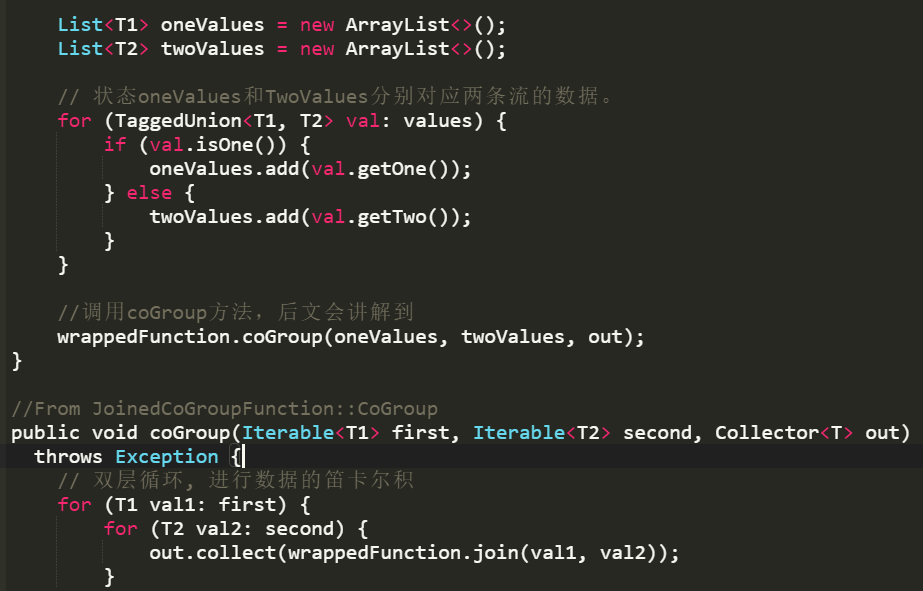
join+where+equalTo 算子实现
inner join coGroup+where+equalTo 可算子实现left/right join ,这个时候有个问题,某流数据可能晚到,导致窗口关闭了都没有join上
Interval Join的双流JOIN实现机制
Interval Join根据右流相对左流偏移的时间区间(interval)作为关联窗口,在偏移区间窗口中完成join操作。满足数据流stream2在数据流stream1的 interval(low, high)偏移区间内关联join。interval越大,关联上的数据就越多,超出interval的数据不再关联。
实现原理:interval join也是利用Flink的state存储数据,不过此时存在state失效机制ttl,触发数据清理操作。比如:
- orderStream.keyBy(_.1)
- // 调用intervalJoin关联
- .intervalJoin(orderDetailStream._2)
- // 设定时间上限和下限
- .between(Time.milliseconds(-30), Time.milliseconds(30))
- .process(new ProcessWindowFunction())
-
- class ProcessWindowFunction extends ProcessJoinFunction...{
- override def processElement(...) {
- collector.collect((r1, r2) => r1 + " : " + r2)
- }
- }
基于Connect的双流JOIN实现机制
对两个DataStream执行connect操作,将其转化为ConnectedStreams, 生成的Streams可以调用不同方法在两个实时流上执行,且双流之间可以共享状态。这个时候结合状态,如果某流数据没有过来先存状态,后流过来去状态去找,没有再存状态。
- orderStream.connect(orderDetailStream)
- .keyBy("orderId", "orderId")
- .process(new orderProcessFunc());
6. Flink的checkpoint文件是保存在哪里, 可以选择哪些?
MemoryStateBackend在 CheckPoint 时,State Backend 对状态进行快照,并将快照信息作为 CheckPoint 应答消息的一部分发送给 JobManager(master),同时 JobManager 也将快照信息存储在堆内存中。
FsStateBackendFsStateBackend 将正在运行中的状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中。少量的元数据信息存储到 JobManager 的内存中。
RocksDBStateBackendRocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 的数据目录。CheckPoint 时,整个 RocksDB 数据库被 checkpoint 到配置的文件系统目录中。
7. Flink 维表关联怎么做的(应该是开发必做,建议提前准备)
(1) 查找关联(同步,异步)
(2) 状态编程,预加载数据到状态中,按需取
(3) 冷热数据
(4) 广播维表
(5) Temporal Table Join
8. Flink 数据倾斜是怎么解决的?
(1)定位反压
Flink Web UI 自带的反压监控(直接方式)、Flink Task Metrics(间接方式)。通过监控反压的信息,可以获取到数据处理瓶颈的 Subtask。
(2)确定数据倾斜
Flink Web UI 自带Subtask 接收和发送的数据量。当 Subtasks 之间处理的数据量有较大的差距,则该 Subtask 出现数据倾斜。
解决
(1)数据源 source 消费不均匀
通过调整Flink并行度,解决数据源消费不均匀或者数据源反压的情况。我们常常例如kafka数据源,调整并行度的原则:Source并行度与 kafka分区数是一样的,或者 kafka 分区数是KafkaSource 并发度的整数倍。建议是并行度等于分区数。
(2)key 分布不均匀
上游数据分布不均匀,使用keyBy来打散数据的时候出现倾斜。通过添加随机前缀,打散 key 的分布,使得数据不会集中在几个 Subtask。
两阶段聚合解决 KeyBy(加盐局部聚合+去盐全局聚合) 预聚合:加盐局部聚合,在原来的 key 上加随机的前缀或者后缀。聚合:去盐全局聚合,删除预聚合添加的前缀或者后缀,然后进行聚合统计。
9. Flink如何处理乱序数据?
比如我们现在设置了每5秒一次的滚动窗口,比如我们从Kafka中的读取到的第一个事件时间为10:00:00 以此从kafka读取数据如下:
A(10:00:00),B(10:00:01),C(10:00:05),D(10:00:06),E(10:00:03),F(10:00:04)
当D(10:00:06)时间到了,就会触发【10:00:00-10:00:05)窗口(只是简单举个例子,没有严格意义上的按照源码公式去划分窗口),后续的E,F数据就会被抛弃,会被忽略计算。
为了解决根据事件时间计算可能会产生这种问题,Flink 提供了WaterMarker机制,利用一定的延迟容忍,可一定程度上避免因消息乱序导致的错误计算或者数据丢失。单数据流情况(并行度=1):WaterMarker=当前数据流中当前元素最大事件时间 - 最大允许的延迟时间或乱序时间。
对于多流而言(并行度>1的source task),它每个独立的subtask都会生成各自的watermark。这些watermark会随着流数据一起分发到下游算子,并覆盖掉之前的watermark。当有多个watermark同时到达下游算子的时候,flink会选择较小的watermark进行更新。当一个task的watermark大于窗口结束时间时,就会立马触发窗口操作。
watermark可以在一定程度上解决事件乱序问题,但严重的乱序问题依然无法解决!我们可以结合侧位输出来收集更为延迟的数据,避免延迟数据丢失。所以,不可过度依赖WaterMarker帮助我们解决乱序问题,如果发生过多乱序问题应注重检查生产数据的生产端问题。还有一点要注意的:watermark是一个全局的值,不是某一个key下的值,所以即使不是同一个key的数据,其watermark也会不断增加。
10. Flink内存溢出怎么办?
当Flink程序在运行过程中发生内存溢出,一种可能的原因是任务需要处理的数据量超过了可以保存在内存中的数据,导致运算符将部分数据溢出到磁盘。对于这种情况,我们可以尝试以下几种解决方法:
-
优化程序逻辑,减小数据的处理量。例如,我们可以使用更高效的算法或者对数据进行预处理来减少数据的复杂性。
-
调整Flink程序的并行度。根据具体的问题和硬件环境,增加或减少并行度可能会带来更好的性能。
-
调整Flink程序的内存配置。我们可以根据程序的实际需求和系统资源情况,提高或降低Flink程序可以使用的内存量。
-
如果上述方法都无法解决问题,那么可能需要考虑升级硬件资源,增加服务器的内存。
11. Flink试过哪些优化?
优化的话:可以参考下面几点
-
GC的配置
(1)调整老年代与新生代的比值 或者 更换垃圾收集器
(2)增加JVM内存
-
数据倾斜
(1)需要重新设计key,以更小粒度的key使得task大小合理化。
(2)当分区导致数据倾斜时,需要考虑优化分区。避免非并行度操作,有些对DataStream的操作会导致无法并行,例如WindowAll。
(3)调用rebalance操作,使数据分区均匀。
(4)自定义分区:使用一个用户自定义的Partitioner对每一个元素选择目标task,由于用户对自己的数据更加熟悉,可以按照某个特征进行分区,从而优化任务执行。
-
checkpoint
(1)频率不宜过高
(2)超时时间不要过长,一般在频率一半
(3)使用异步
4.其他配置
- (1)配置JobManager内存
-
- (2)配置TaskManager个数
-
- (3)配置TaskManager Slot数
5.其他
(1)背压的时候大家往往忽略了数据的序列化和反序列化,过程所造成的性能问题。
(2) 一些数据结构 ,比如 HashMap 和 HashSet 这种 key 需要经过 hash 计算的数据结构,在数据量大的时候使用 keyby 进行操作, 造成的性能影响是非常大的。
(3) 如果我们的下游是 MySQL,HBase这种,我们都会进行一个批处理的操作,就是让数据存储到一个 buffer 里面,在达到某些条件的时候再进行发送,这样做的目的就是减少和外部系统的交互,降低网络开销的成本。
(4) 频繁GC ,无论是 CMS 也好,G1也好,在进行 GC 的时候,都会停止整个作业的运行,GC 时间较长还会导致 JobManager 和 TaskManager 没有办法准时发送心跳,此时 JobManager 就会认为此 TaskManager 失联,它就会另外开启一个新的 TaskManager。
-
场景
产生背压的时候如果定位下游计算不过来,导致上游挤压严重,这个时候想着怎么去增加并行度也好或者利用多线程也好,目的就是增加计算能力。如果多线程计算,这个时候更多关注cpu核数,来分配更多的时间片,提高计算能力。
12. Flink的重启策略怎么设置的?
如果启用了checkpoint并且没有显式配置重启策略,会默认使用fixeddelay策略,最大重试次数为Integer.MAX_VALUE。
固定延迟重启策略
固定延迟重启策略是尝试给定次数重新启动作业。如果超过最大尝试次数,则作业失败。在两次连续重启尝试之间,会有一个固定的延迟等待时间
- // 配置文件设置
- restart-strategy: fixed-delay # fixed-delay:固定延迟策略
-
- restart-strategy.fixed-delay.attempts: 5 # 尝试5次,默认Integer.MAX_VALUE
-
- restart-strategy.fixed-delay.delay: 10s # 设置延迟时间10s,默认为 akka.ask.timeout时间
-
-
- // 代码设置固定延迟重启策略
- env.setRestartStrategy(RestartStrategies
- .fixedDelayRestart(3,Time.seconds(3)));
故障率重启策略
故障率重启策略在故障后重新作业,当设置的故障率(failure rate)(每个时间间隔内发生故障的次数)超过设定的限制时,作业将会被判断为最终失败,作业最终失败。在两次连续重启尝试之间,重启策略延迟等待一段时间。
- restart-strategy: failure-rate # 设置重启策略为failure-rate
-
- restart-strategy.failure-rate.max-failures-per-interval: 3 # 失败作业之前的给定时间间隔内的最大重启次数,默认1
-
- restart-strategy.failure-rate.failure-rate-interval: 5min # 测量故障率的时间间隔。默认1min
-
- restart-strategy.failure-rate.delay: 10s # 两次连续重启尝试之间的延迟,默认akka.ask.timeout时间
-
- 失败后,5分钟内重启3次(每次重启间隔10s),如果第3次还是失败,则任务最终是失败,不再重启
-
无重启策略
restart-strategy: none
13. Flink重大版本差别?
Flink 1.9
阿里内部版本Blink首次合并入Flink
重构 Flink WebUI
Flink 1.10
原生 Kubernetes 的初步集成(beta 版本)以及对 Python 支持(PyFlink)的重大优化。
Flink 1.11
非对齐的 Checkpoint 机制。这一机制是对 Flink 容错机制的一个重要改进,它可以提高严重反压作业的 Checkpoint 速度。
Flink SQL 引入了对 CDC
PyFlink 优化了多个部分的性能,包括对向量化的用户自定义函数(Python UDF)的支持。
Application 部署模式
Flink 1.12
DataStream API 上添加了高效的批执行模式的支持。这是批处理和流处理实现真正统一的运行时的一个重要里程碑。
扩展了 Kafka SQL connector,使其可以在 upsert 模式下工作。
SQL 中 支持 Temporal Table Join
剩下的版本在原有的基础上优化等等。
14. Flink的怎么和RocksDB交互的。怎样一个流程?
Flink和RocksDB的交互主要通过Java Native接口(JNI)实现。具体来说,Flink作业运行时,RocksDB会被内嵌到TaskManager进程中,并以本地线程方式运行来读写本地文件。
15. Flink topN的实现?
统计最近10 秒钟内最热门的两个 url 链接,并且每 5 秒钟更新一次
- stream.map(data -> data.getUserName())
- .windowAll(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
- .aggregate(new UserHashMapCountAgg(), new UserCountWindowResult())
- .print();
-
- public static class UserHashMapCountAgg implements AggregateFunction<String, HashMap<String, Long>, List<Tuple2<String, Long>>>{
- @Override
- public HashMap<String, Long> createAccumulator() {
- return new HashMap<>();
- }
-
- @Override
- public HashMap<String, Long> add(String value, HashMap<String, Long> accumulator) {
- if (accumulator.containsKey(value)){
- accumulator.put(value, accumulator.get(value) + 1L);
- }else{
- accumulator.put(value, 1L);
- }
- return accumulator;
- }
-
- @Override
- public List<Tuple2<String, Long>> getResult(HashMap<String, Long> accumulator) {
- List<Tuple2<String, Long>> resultList = new ArrayList<>();
- accumulator.forEach((key, count) -> {
- resultList.add(Tuple2.of(key, count));
- });
-
- //排序
- resultList.sort(new Comparator<Tuple2<String, Long>>() {
- @Override
- public int compare(Tuple2<String, Long> o1, Tuple2<String, Long> o2) {
- return o2.f1.intValue() - o1.f1.intValue();
- }
- });
- return resultList;
- }
-
- @Override
- public HashMap<String, Long> merge(HashMap<String, Long> a, HashMap<String, Long> b) {
- //do nothing
- return null;
- }
- }
16. Flink监控怎么做的?
Web UI方式: Flink提供了一个web UI来观察、监视和调试正在运行的应用服务。并且还可以执行或取消组件或任务的执行。
Prometheus + Grafana:Flink提供了一个复杂的度量系统来收集和报告系统和用户定义的度量指标信息。flink-metrics-prometheus 的相关jar放到lib下,然后在fink-conf中配置相关信息即可。然后配置相关的指标信息和报警即可。
17. Flink关闭后状态端数据恢复得慢怎么办?
(1)选用合理的state数据结构和 statebackend
(2)并行度合理设置
18. Flink的序列化讲讲呢?
目前,绝大多数的大数据计算框架都是基于JVM实现的,为了快速地计算数据,需要将数据加载到内存中进行处理。当大量数据需要加载到内存中时,如果使用Java序列化方式来存储对象,占用的空间会较大降低存储传输效率。
例如:一个只包含布尔类型的对象需要占用16个字节的内存:对象头要占8个字节、boolean属性占用1个字节、对齐填充还要占用7个字节。
Java序列化方式存储对象存储密度是很低的。也是基于此,Flink框架实现了自己的内存管理系统,在Flink自定义内存池分配和回收内存,然后将自己实现的序列化对象存储在内存块中。
所谓序列化和反序列化的含义:
序列化: 就是将一个内存对象转换成二进制串,形成网络传输或者持久化的数据流。
反序列化:将二进制串转换为内存对。
TypeInformation 是 Flink 类型系统的核心类
在Flink中,当数据需要进行序列化时,会使用TypeInformation的生成序列化器接口调用一个 createSerialize() 方法,创建出TypeSerializer,TypeSerializer提供了序列化和反序列化能力。如下图所示:Flink 的序列化过程
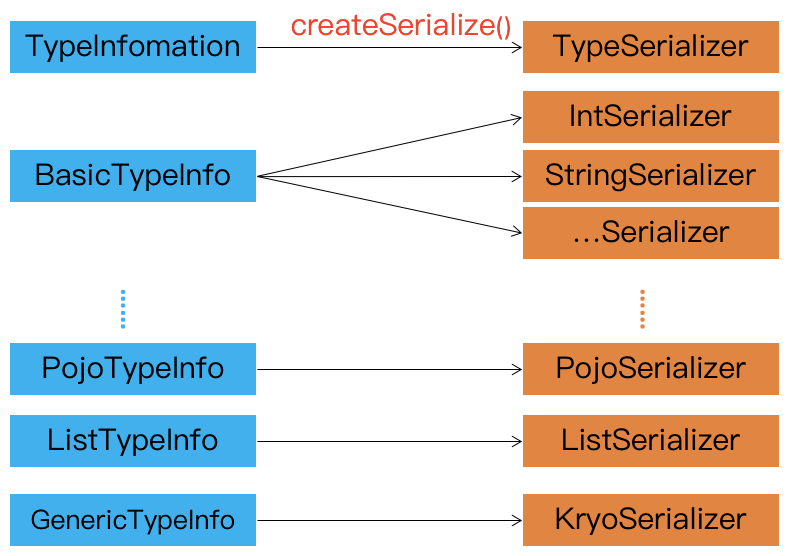
对于大多数数据类型 Flink 可以自动生成对应的序列化器,能非常高效地对数据集进行序列化和反序列化 ,如下图:
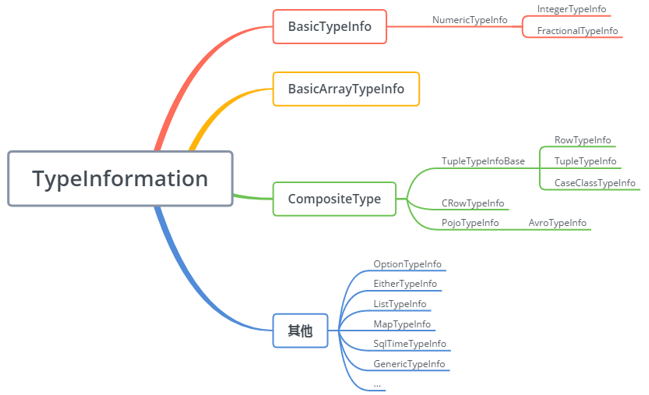
比如,BasicTypeInfo、WritableTypeIno ,但针对 GenericTypeInfo 类型,Flink 会使用 Kyro 进行序列化和反序列化。其中,Tuple、Pojo 和 CaseClass 类型是复合类型,它们可能嵌套一个或者多个数据类型。在这种情况下,它们的序列化器同样是复合的。它们会将内嵌类型的序列化委托给对应类型的序列化器。
通过一个案例介绍Flink序列化和反序列化:
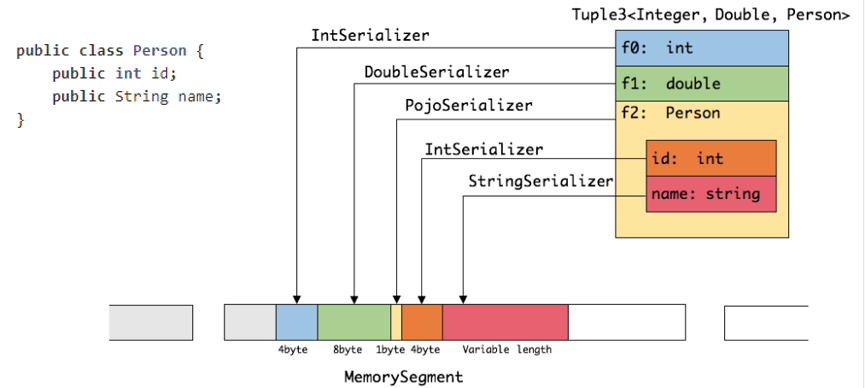
如上图所示,当创建一个Tuple 3 对象时,包含三个层面,一是 int 类型,一是 double 类型,还有一个是 Person。Person对象包含两个字段,一是 int 型的 ID,另一个是 String 类型的 name
(1)在序列化操作时,会委托相应具体序列化的序列化器进行相应的序列化操作。从图中可以看到 Tuple 3 会把 int 类型通过 IntSerializer 进行序列化操作,此时 int 只需要占用四个字节。
(2)Person 类会被当成一个 Pojo 对象来进行处理,PojoSerializer 序列化器会把一些属性信息使用一个字节存储起来。同样,其字段则采取相对应的序列化器进行相应序列化,在序列化完的结果中,可以看到所有的数据都是由 MemorySegment 去支持。
MemorySegment 具有什么作用呢?
MemorySegment 在 Flink 中会将对象序列化到预分配的内存块上,它代表 1 个固定长度的内存,默认大小为 32 kb。MemorySegment 代表 Flink 中的一个最小的内存分配单元,相当于是 Java 的一个 byte 数组。每条记录都会以序列化的形式存储在一个或多个 MemorySegment 中。
19. Flink的异步有了解吗?
- // 创建一个原始的流
- val stream: DataStream[String] = ...
-
- // 添加一个 async I/O
- val resultStream: DataStream[(String, String)] =
- AsyncDataStream.(un)orderedWait(
- stream, new AsyncDatabaseRequest(),
- 500, TimeUnit.MILLISECONDS, // 超时时间
- 120) // 进行中的异步请求的最大数量
无序模式:异步请求一结束就立刻发出结果记录。流中记录的顺序在经过异步 I/O 算子之后发生了改变。当使用 处理时间 作为基本时间特征时,这个模式具有最低的延迟和最少的开销。此模式使用 AsyncDataStream.unorderedWait(...) 方法。
有序模式: 这种模式保持了流的顺序。发出结果记录的顺序与触发异步请求的顺序(记录输入算子的顺序)相同。
20. Flink的boardcast join 的原理是什么?
利用 broadcast State 将维度数据流广播到下游所有 task 中。这个 broadcast 的流可以与我们的事件流进行 connect,然后在后续的 process 算子中进行关联操作即可。
当维度信息修改后,flink 的 broadcast 流实时消费 MQ 中数据,就可以实时读取到维表的更新,然后配置就会在 Flink 任务生效,通过这种方法及时的修改了维度信息。broadcast 可以动态实时更新配置。
21. 你们有用过Flink的背压吗,怎么做优化和调整?
简单来说就是下游处理速率 跟不上 上游发送数据的速率,下游来不及消费,导致队列被占满后,上游的生产会被阻塞,最终导致数据源的摄入被阻塞。
反压会影响到两项指标: checkpoint 时长和 state 大小
(1)前者是因为 checkpoint barrier 是不会越过普通数据的,数据处理被阻塞也会导致 checkpoint barrier 流经整个数据管道的时长变长,因而 checkpoint 总体时间(End to End Duration)变长。
(2)后者是因为为保证 EOS(Exactly-Once-Semantics,准确一次),对于有两个以上输入管道的 Operator,checkpoint barrier 需要对齐(Alignment),接受到较快的输入管道的 barrier 后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的 barrier 也到达,这些被缓存的数据会被放到state 里面,导致 checkpoint 变大。
Flink反压如何解决?
(1)定位反压节点 要解决反压首先要做的是定位到造成反压的节点,这主要有两种办法:
1. 通过 Flink Web UI 自带的反压监控面板;
2. 通过 Flink Task Metrics。
(1)反压监控面板
Flink Web UI 的反压监控提供了 SubTask 级别的反压监控,原理是通过周期性对 Task 线程的栈信息采样,得到线程被阻塞在请求 Buffer(意味着被下游队列阻塞)的频率来判断该节点是否处于反压状态。默认配置下,这个频率在 0.1 以下则为 OK,0.1 至 0.5 为 LOW,而超过 0.5 则为 HIGH。
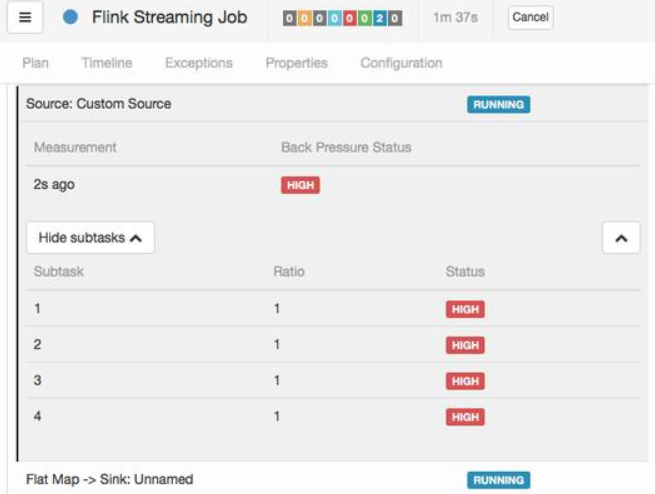
(2)Task Metrics
Flink 提供的 Task Metrics 是更好的反压监控手段 如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了;如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。
22. Flink的CBO,物理执行计划和逻辑执行计划?
Flink的优化执行其实是借鉴的数据库的优化器来生成的执行计划。
CBO,成本优化器,代价最小的执行计划就是最好的执行计划。传统的数据库,成本优化器做出最优化的执行计划是依据统计信息来计算的。Flink 的成本优化器也一样。Flink 在提供最终执行前,优化每个查询的执行逻辑和物理执行计划。这些优化工作是交给底层来完成的。根据查询成本执行进一步的优化,从而产生潜在的不同决策:如何排序连接,执行哪种类型的连接,并行度等等。
23. 你们用Flink怎么去开发一些checkpoint的超时问题?
Flink 的 Checkpoint 包括如下几个部分:
● JM trigger checkpoint
● Source 收到 trigger checkpoint 的 PRC,自己开始做 snapshot,并往下游发送 barrier
● 下游接收 barrier(需要 barrier 都到齐才会开始做 checkpoint)
● Task 开始同步阶段 snapshot
● Task 开始异步阶段 snapshot
● Task snapshot 完成,汇报给 JM
上面的任何一个步骤不成功,整个 checkpoint 都会失败。
从webui上可以看到,Acknowledged 一列表示有多少个 subtask 对这个 Checkpoint 进行了 ack,失败的情况大多数总有几个subtask 失败。
(1)Checkpoint Decline 当前 Flink 中如果较小的 Checkpoint 还没有对齐的情况下,收到了更大的 Checkpoint,则会把较小的 Checkpoint 给取消掉。
(2)Checkpoint Expire Checkpoint 做的非常慢,超过了 timeout 还没有完成,则整个 Checkpoint 也会失败。
生产比如:
(1)采用短连接方式获取数据库连接,每次来一波数据都创建连接,发送完断开连接。因此很容易因为获取不到连接而使得processElement方法处于阻塞状态。而processElement方法阻塞进而影响Barrier的流动,所以导致了Checkpoint发生超时。
(2)Checkpoint状态比较大,增 量 Checkpoint, 则 只 备 份 上 一 次 Checkpoint 中 不 存 在 的 state。
(3)作业存在反压或者数据倾斜,barrier 发送慢,从而整体影响 Checkpoint 的时间。
(4)主线程太忙,导致没机会做 snapshot。在 task 端,所有的处理都是单线程的,数据处理和 barrier 处理都由主线程处理,如果主线程在处理太慢,也会影响整体 Checkpoint 的进度。
org.apache.flink [详细] 赞
踩

