
热门标签
热门文章
- 1openpose安装(Linux_ubuntu_16.04+cuda9+cudnn7.1.4+protobuf2.6.1)_openpose linux
- 2TensorRT加速方法介绍(python pytorch模型)_detected invalid timing cache, setup a local cache
- 3[halcon]--图像锐化--索贝尔、拉普拉斯_halcon 锐化
- 4题解 CF283E 【Cow Tennis Tournament】
- 5飞桨社区项目PaddleMM正式进入木兰开源社区进行孵化
- 6深拷贝与浅拷贝的区别以及Object.assign()用法_阐述object.assign的用法,深拷贝与浅拷贝的区别?
- 7云上无极限:亚马逊云科技开启开发者新纪元
- 8【软件设计师-中级——刷题记录6(纯干货)】_软件设计师近几年题目
- 9手把手教会你docker之环境搭建_docker搭建
- 10微服务架构与SpringCloud
当前位置: article > 正文
Python 玩转数据 16 - Pandas 数据处理 追加 df.append()
作者:知新_RL | 2024-02-08 15:26:25
赞
踩
df.append
引言
本文主要介绍 pandas 数据追加 df.append(),更多 Python 进阶系列文章,请参考 Python 进阶学习 玩转数据系列
内容提要:
df1.append()
追加 DataFrame
追加 Series
追加 dict 字典
df1.append()
按行追加拼接,将一个 DataFrame 的行拼接到另外一个 DataFrame 的末尾,返回一个新的 DataFrame。如果列名不在第一个 DataFrame出现,则将以新的列名添加,没有对应内容的会为空。不会改变原来的 DataFrame,只会创建一个新的 DataFrame,包含拼接的数据。
重点:因为会创建一个新的 index 和 data buffer,所以效率不高。推荐用 pd.concat(),而且 pd.concat() 功能更强大,详情请参考 Pandas 数据处理 拼接 pd.concat()
df.append(other: DataFrame | Series[Dtype@append] | Dict[_str, Any], ignore_index: _bool = …, verify_integrity: _bool = …, sort: _bool = …)
| 参数 | 说明 |
|---|---|
| other | 是它要追加的其他 DataFrame 或者类似序列内容 |
| ignore_index | 如果为 True 则重新进行自然索引 |
| verify_integrity | 如果为 True 则遇到重复索引内容时报错 |
| sort | 进行排序 |
追加 DataFrame
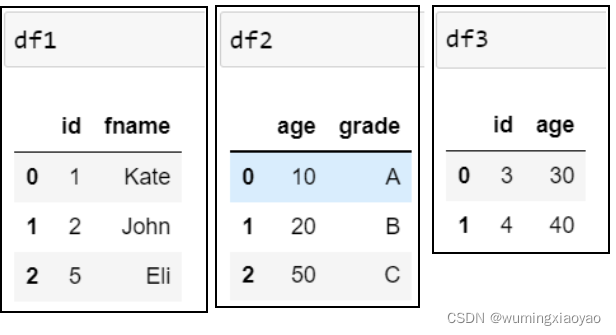
两个 df 拼接,并保留原索引:
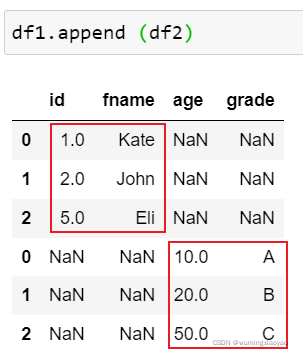
多个 df 拼接,在合并不保留原索引,启用新的自然索引

代码:
import pandas as pd idnumber = [1,2,5] fname = ['Kate','John','Eli'] age = [10,20,50] grade = ['A','B','C'] df1 = pd.DataFrame({'id':idnumber,'fname':fname}) df2 = pd.DataFrame({'age':age,'grade':grade}) df3 = pd.DataFrame({'id':[3,4],'age':[30,40]}) print("df1:\n{}".format(df1)) print("df2:\n{}".format(df2)) print("df3:\n{}".format(df3)) df1_append_df2 = df1.append(df2) print("df1_append_df2:\n{}".format(df1_append_df2)) df1_append_df2_df3 = df1.append([df2,df3], ignore_index = True) print("df1_append_df2_df3:\n{}".format(df1_append_df2_df3))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输出:
df1: id fname 0 1 Kate 1 2 John 2 5 Eli df2: age grade 0 10 A 1 20 B 2 50 C df3: id age 0 3 30 1 4 40 df1_append_df2: id fname age grade 0 1.0 Kate NaN NaN 1 2.0 John NaN NaN 2 5.0 Eli NaN NaN 0 NaN NaN 10.0 A 1 NaN NaN 20.0 B 2 NaN NaN 50.0 C df1_append_df2_df3: id fname age grade 0 1.0 Kate NaN NaN 1 2.0 John NaN NaN 2 5.0 Eli NaN NaN 3 NaN NaN 10.0 A 4 NaN NaN 20.0 B 5 NaN NaN 50.0 C 6 3.0 NaN 30.0 NaN 7 4.0 NaN 40.0 NaN
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
追加 Series
拼接 Series 一定要加上参数 ignore_index=True
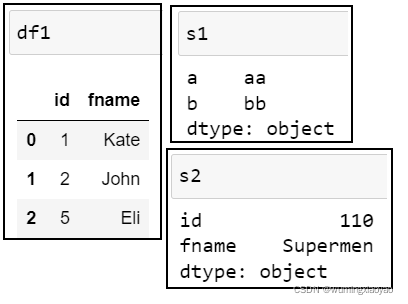
Series 的 index 会分别对应列名
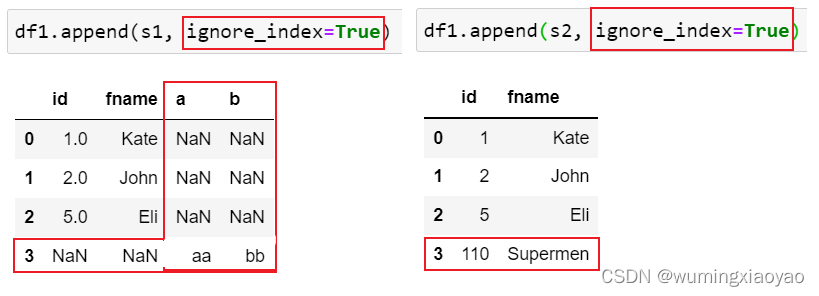
代码:
import pandas as pd idnumber = [1,2,5] fname = ['Kate','John','Eli'] df1 = pd.DataFrame({'id':idnumber,'fname':fname}) s1 = pd.Series(["aa", "bb"], index=["a", "b"]) s2 = pd.Series(["110", "Supermen"], index=["id", "fname"]) print("df1:\n{}".format(df1)) print("s1:\n{}".format(s1)) print("s2:\n{}".format(s2)) df1_appened_s1 = df1.append(s1, ignore_index=True) df1_appened_s2 = df1.append(s2, ignore_index=True) print("df1_appened_s1:\n{}".format(df1_appened_s1)) print("df1_appened_s2:\n{}".format(df1_appened_s2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
输出:
df1: id fname 0 1 Kate 1 2 John 2 5 Eli s1: a aa b bb dtype: object s2: id 110 fname Supermen dtype: object df1_appened_s1: id fname a b 0 1.0 Kate NaN NaN 1 2.0 John NaN NaN 2 5.0 Eli NaN NaN 3 NaN NaN aa bb df1_appened_s2: id fname 0 1 Kate 1 2 John 2 5 Eli 3 110 Supermen
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
追加 dict 字典

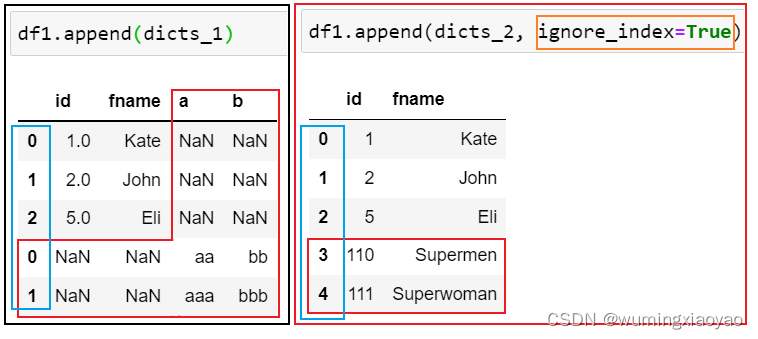
代码:
import pandas as pd idnumber = [1,2,5] fname = ['Kate','John','Eli'] df1 = pd.DataFrame({'id':idnumber,'fname':fname}) dicts_1 =[{"a":"aa", "b":"bb"},{"a":"aaa", "b":"bbb"}] dicts_2 =[{"id":"110", "fname":"Supermen"},{"id":"111", "fname":"Superwoman"}] print("df1:\n{}".format(df1)) print("dicts_1:\n{}".format(dicts_1)) print("dicts_1:\n{}".format(dicts_1)) df1_appened_dicts_1 = df1.append(dicts_1) df1_appened_dicts_2 = df1.append(dicts_2, ignore_index=True) print("df1_appened_dicts_1:\n{}".format(df1_appened_dicts_1)) print("df1_appened_dicts_2:\n{}".format(df1_appened_dicts_2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输出:
df1: id fname 0 1 Kate 1 2 John 2 5 Eli dicts_1: [{'a': 'aa', 'b': 'bb'}, {'a': 'aaa', 'b': 'bbb'}] dicts_1: [{'a': 'aa', 'b': 'bb'}, {'a': 'aaa', 'b': 'bbb'}] df1_appened_dicts_1: id fname a b 0 1.0 Kate NaN NaN 1 2.0 John NaN NaN 2 5.0 Eli NaN NaN 0 NaN NaN aa bb 1 NaN NaN aaa bbb df1_appened_dicts_2: id fname 0 1 Kate 1 2 John 2 5 Eli 3 110 Supermen 4 111 Superwoman
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/69704
推荐阅读
相关标签

