
- 1智能网联汽车数据安全认识与思考_智能网联汽车数据安全标准化研究项目认识
- 2Hadoop 从HDFS中删除文件夹命令_hdfs删除文件
- 3Windows系统封装(二)导入封装工具安装软件,安装系统。_封装系统软件打包自动安装
- 4VSCode上的Git使用手记(持续更新ing...)_vscode staged changes
- 5Python爬虫学习之requests库
- 6Java Web实现用户登录功能_javaweb登录
- 7速成! | 遗传算法详解及其MATLAB实现_matlab遗传算法
- 8DockerDeskTop系列---【启动DockerDeskTop时报错:Please try shutting WSL down (wsl --shutdown) and...】...
- 9spring boot中多线程并发及利用CountDownLatch并发执行多线程_springboot countdownlatch
- 10ASP.NET 模拟测试001-100题_在asp.net中,为了把页面中一个名为name的string类型的字段帮定到一个textbox控件
飞桨社区项目PaddleMM正式进入木兰开源社区进行孵化
赞
踩

12月6日,PaddleMM在木兰开源社区TOC评审会上投票通过。按照章程,PaddleMM最终准入木兰开源社区进行孵化。木兰社区提供2名项目导师进行后续指导,飞桨也将一如既往为项目提供技术支持。欢迎广大开发者关注和使用PaddleMM,期待⼤家的加⼊和对PaddleMM的不断完善。

关于PaddleMM
PaddleMM是由南京理工大学和百度共同发起的基于飞桨实现的开源多模态学习工具包。该项目提供了模态联合学习和跨模态学习算法模型库,为处理多模态数据提供高效的解决方案,助力多模态学习应用落地。
PaddleMM特性:
丰富的任务场景:工具包提供多模态融合、跨模态检索、图文生成等多种多模态学习任务算法模型,支持用户自定义数据和训练;
成功的工业应用:基于工具包算法已有相关落地应用,如球鞋真伪鉴定、图像字幕生成、舆情监控等。
PaddleMM贡献者:
南京理工大学KMG小组
百度人才智库TIC部门
百度飞桨PaddlePaddle 开发团队
PaddleMM项目地址:
https://gitee.com/njustkmg/Mulan-PaddleMM

关于木兰开源社区
“木兰开源社区”建立于2019年8月,是国家重点研发计划重点专项“云计算和大数据开源社区生态系统”的核心成果。旨在促进产学研用各方开源领域的交流,推动国家科技创新成果开源,加强企业、科教研单位和行业用户之间的沟通,推动开源成果转化落地。同时,为各类开源项目提供中立托管,保证开源项目的持续发展不受第三方影响,通过更加开放的方式来打造和完善开源社区生态。

PaddleMM项目现状
PaddleMM应用展示
部分应用展示如下

球鞋真伪鉴定

智能招聘简历分析
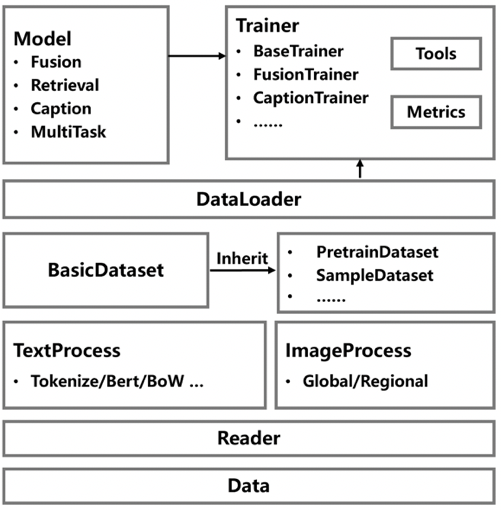
PaddleMM项目架构
PaddleMM主要由以下三个模块组成:
数据处理:提供统一的数据接口和多种数据处理格式;
模型调用:包括多模态融合、跨模态检索、图文生成、多任务算法;
训练评估:对每种任务设置统一的训练流程和相关指标计算。
自定义数据和训练示例
- from paddlemm import PaddleMM
-
- # config: Model running parameters, see configs/
- # data_root: Path to dataset
- # image_root: Path to images
- # gpu: Which gpu to use
-
- runner = PaddleMM(config='configs/cmml.yml',
- data_root='data/COCO',
- image_root='data/COCO/images',
- out_root='experiment/cmml_paddle',
- gpu=0)
-
- runner.train()
- runner.test()
数据处理层:主要面向多模态原始数据,提供统一的数据接口与多模态数据处理方式。当前PaddleMM针对媒体数据提供了图像和文本的数据处理接口,后续会针对音频等模态进行数据接口的更新。
模型调用层:内置了面向多任务的数据集调用与模型库。目前模型仓库主要提供针对多模态联合学习、跨模态检索、跨模态图文生成与预训练模型四个部分的经典模型,如NIC、TMC等。后续会不断增加新的多模态任务以及对应的模型。
训练评估层:设定了任务无关的指标运算与训练流程。主要集成了ACC、Recall、CIDER、BLEU、METOR等多模态常用指标并针对当前的模型库提供统一的训练测试流程。
PaddleMM模型库(持续更新中)
PaddleMM包含了模态联合学习、跨模态学习和基于Transformer结构的多任务框架等一系列多模态学习算法。
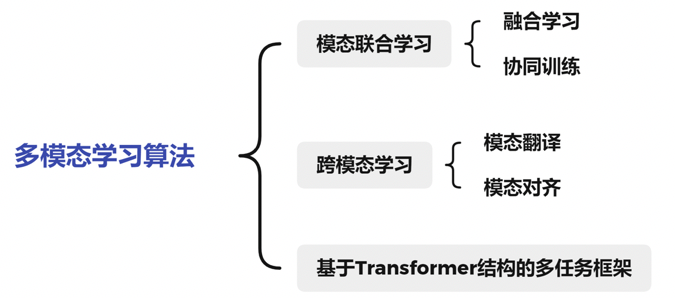
模态联合学习-融合学习
Early (Multi-modal early fusion)
Late (Multi-modal late fusion)
LMF[1]
TMC[2]
模态联合学习-协同训练
CMML[3]
跨模态学习-模态翻译
ShowAttendTell[4]
AoANet[5]
CPRC[6]
跨模态学习-模态对齐
VSE++[7]
SCAN[8]
BFAN[9]
IMRAM[10]
SGRAF[11]
基于 Transformer 结构的多任务框架
VILBERT[12]
 飞桨与开源
飞桨与开源
PaddleMM进入木兰开源社区孵化仅仅只是开始,飞桨欢迎广大开发者,为PaddleMM贡献使用反馈,也期待有更多基于飞桨开发的社区开源项目加入进来。飞桨将携手开源社区,对优秀的开源项目提供技术、资源和项目治理等支持。
PaddleMM项目地址:
https://gitee.com/njustkmg/Mulan-PaddleMM
参考文献
[1] Efficient Low-rank Multimodal Fusion with Modality-Specific Factors
[2] Trusted Multi-View Classification
[3] Comprehensive Semi-Supervised Multi-Modal Learning
[4] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
[5] Attention on Attention for Image Captioning
[6] Exploiting Cross-Modal Prediction and Relation Consistency for Semi-Supervised Image Captioning
[7] VSE++: Improving Visual-Semantic Embeddings with Hard Negatives
[8] Stacked Cross Attention for Image-Text Matching
[9] Focus Your Attention: A Bidirectional Focal Attention Network for Image-Text Matching
[10] IMRAM: Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval
[11] Similarity Reasoning and Filtration for Image-Text Matching
[12] ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

