
- 1图像去噪_数字图像处理中加法图像数量越多,去噪效果越好对不对
- 2【Neo4j构建知识图谱】配置知识图谱插件APOC与案例实现_知识图谱 前端插件
- 3java socket编程_Java TCP/IP Socket编程
- 4【数据集划分】oracle数据集划分(总结版)
- 5Linux操作系统内存管理(详解)_linux系统的内存管理
- 6黑客团伙利用Python、Golang和Rust恶意软件袭击印国防部门;OpenAI揭秘,AI模型如何被用于全球虚假信息传播? | 安全周报0531_cve-2024-1086 cvss
- 7FPGA 20个例程篇:7.FLASH读写断电存储_极化码 fpga 例程
- 8CentOS 7 搭建 Hadoop3.3.1集群_sentos7 格式化集群 启动
- 9启动vue项目时报错:digital envelope routines::unsupported
- 10live2dviewer android,live2dviewerex最新版
BEV高频面试问题汇总!(纯视觉&多模态融合算法)
赞
踩
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
本文内容均出自国内首个详细入门BEV感知的学习路线!
>>点击进入→自动驾驶之心【BEV感知】技术交流群
BEV感知被公认为是下一代感知的范式,越来越多自动驾驶公司开始部署落地相关方案,自动驾驶之心为大家整理了BEV感知融合(纯视觉+多传感器融合)相关常见问题与答案,希望能够帮助到大家,先预定100问,我们后面将持续保持更新,冲,冲,冲!!!
所有内容出自:国内首个BEV感知全栈学习教程(纯视觉+多传感器融合方案)
一、 BEV感知相关的基础知识
问题1:BEV是什么?
BEV是做自动驾驶场景中3D目标检测任务的一种算法方向,也是最近的顶会,期刊论文数量很多,社区内讨论很热烈的一个研究方向,在一些自动驾驶企业之中,也有很多使用的BEV作为感知方案。
BEV的意思是鸟瞰图,也就是我们会将环视摄像机,激光雷达,甚至是毫米波雷达的数据,经过特征提取之后,统统通过视角变换,转换到鸟瞰图这种场景下,然后会在这些场景下,做一些多传感器数据融合就很方便了,之后我们就可以接各种任务头,做3D目标检测,车道线检测,语义分割,障碍物检测等等,都是可以的。
问题2:BEV感知算法中纯camera的2d->3d是像素坐标转到世界坐标,纯lidar的3d->2d是世界坐标转到像素坐标,可以这样理解吗
2d bev是pillar特征,激光雷达坐标系转到世界坐标系,可以参考pillar的原理
立减50!仅限三天!扫码领取优惠券

问题3:2d转3d原理有什么资料推荐吗?
可以参考《End-to-End Pseudo-LiDAR for Image-Based 3D Object Detection》 related work里面 pseudo lidar部分
问题4:老师好,我想问一下这两个公式怎么理解呀,2D转3D的。

第一个公式:D(u,v)图像深度预测得到深度值,F_2D(u,v)图像特征,两个合在一起,深度d+图像坐标(u,v)可以映射到3d坐标(x,y,z),得到对应特征F_3D,这个过程其实是一个2d→3d的过程,2d坐标+深度得到3d
第二个公式:P_xyz是3d空间坐标,可以投影到2d,比如得到投影像素坐标(u,v),拿到对应2d点的feature,再用函数f,得到BEV特征,所以这个公式是3d→2d的过程,有3d点,投影到2d,拿特征。但是本质上也是用2d特征生成3d特征,只不过是提前预设好了一个3d空间,也就是里面的P_xyz
追问:还有两点没太明白,①公式一里面用了外积操作,2D特征图×对应坐标的深度值,这个是什么物理量呀?为什么一定用外积?②公式二中P_xyz您说是指3D空间坐标,这个是那种均匀分布的Voxel的坐标吗?
问题1:很多时候深度预测是一个分布值,也就是当前像素(u,v)落在固定深度的概率,这个概率可以作为一个权重,乘在feature上的,所以这里外积表示了
问题2:这里用的是体素坐标,具体是平均分布体素,还是采样体素,应该是要结合具体文章来看的。anyway,我觉得只要知道这里表的是3d坐标就行了。
问题5:如何理解bev空间呢,是俯视视角下的一个平面吗,bev空间里的每个点是用(x,y)表示的吗,还是一个三维表示?还有您说的把图像提取出来特征(C,H,W)转换到3D空间后(C,D,H,W)再拍扁到bev空间,具体是什么意思呢,拍扁后的维度是什么,这里不太清楚
Bev就是鸟瞰图,从上往下看应该就是二维的一个平面。第二个问题在说视图转换嘛,如果是相机透视图的话会存在遮挡还有近大远小问题,所以需要转换成bev,但是不能直接转换,需要通过3D空间作为中介,就是先从透视图转换到3D,再从3D转换到bev
二、 课程涉及到的论文相关的问题
问题1:请问这里的blob channel怎么理解?

结合上下文的描述,可以从偏负面的角度去理解blob channel。lidar的feature是sparse的,image的feature是dense,fusion的时候,lidar的某些位置没有值,所以是blob的。当然,我倾向于不用太纠结这个词,因为fusion的方式就那么几种,这里只是一种描述。
问题2:BEVfusion的算法把3D lidar的数据用view transformer变成了2D的,是不是会更省算力?那Lidar的距离信息会丢失嘛?
变成 2d 是会省算力的,但是需要考虑的是 2d 环视是具有很多视角的,3d lidar 投影到哪个呢?投一个还是都投,这个问题其实不是很好解决。所以 bevfusion 把无论是 lidar 还是环视 2d 的都统一到 bev 空间,这样就一致了。
另外,如果投影到 2d, lidar深度信息是会丢失的,但是投影 bev 的话,更多的是高度维度的信息聚合。
问题3:老师,你好,请教个问题,BEVFormer中有六层编码器,每一层的输出都作为下一层的BEV查询输入。不明白的地方在于,每一层的输出应该是提取到的特征图才对,为什么会作为BEV查询输出给下一层,BEV查询只是一些可学习的权重参数,特征图为什么变成了权重参数?
每一层的输出是bev特征图,这个理解没有问题,这个特征其实就是代码里面对应的bev query;
上一层的bev query其实有两个作用,一个是作为查询用,比如为temporal self attention生成offset和weight;一个是组成value用,就是需要去查询的特征,所以上一层的结果并不是完全作为权重用,一部分是self attention的参数,一部分是作为特征保留了。
问题4:那就是说,论文中提到的“bev_query是网格型可学习参数”仅在第一层是这样,第二层及其以后在一定程度上都是特征图了。换句话说,特征图的初始值是学习来的,因为初始值与骨干网络提取的特征无关,只能习得一些位置相关的信息了。
是的 初始化是直接调nn.Embedding出来的,bev query就是embedding.weight
问题5:老师,请问这门课着重会讲解的BEV方法是BEVFusion和BEVFormer吗?我看课程框架介绍可知BEVFusion和BEVFormer都有实战、代码详解部分。初学者选哪一种方法自学较合适?
是的,课程上重点讲的是bevfusion和bevformer,这俩都是基于mmdet3d的。如果要自学的话,建议可以先了解一下mmdetection3d这个框架,https://github.com/open-mmlab/mmdetection3d。
问题6:老师,有没有BEV或视觉注意力,transformer相关的demo代码供学习入门的?就是很简洁,包含了关键结构的那种,一些论文开源的代码目前感觉比较吃力
看代码建议还是不要脱离框架,即使同一块内容,不同框架的实现方式也有区别的。比如同样都是3dfeature extractor部分,openpcdet和mmdet3d两个框架就不太一样。transformer这部分也一样,如果想单独看transformer的实现的话,可以选一个基准框架,比如基于mmdet3d实现的bevformer,看看bevformer里面的transformer是怎么做的,把一个工程弄通,之后再慢慢看看别的transformer是怎么做的。
问题7:我有试过引入transformer在 lidar-base 的3D目标检测任务,但是我数据量比较小,目前来看效果不如之前的Anchor-base和Center-base方法,所以transformer是不是需要更多的训练数据啊?才能达到更好的效果?
是的 transformer对数据量要求更高一点 而且不太推荐用在kitti数据集上 就我个人经验来看 不如nuscene稳定
问题8:老师你好,请教个问题:在BEVFormer的时域特征提取过程中(transformer.py文件的get_bev_features()方法中),从can_bus中获得平移(delta_x,delta_y)和旋转角度ego_angle,计算出bev_angle和平移(shift_x,shift_y),这两组平移和旋转分别代表什么,为什么bev_angle = ego_angle - translation_angle?
ego angle是车的行进角度,translation angle计算是平移偏差角度,也就是同一个函数里面的translation_angle = np.arctan2(delta_y, delta_x) / np.pi * 180,ego angle减去translation angle才是在bev空间中的角度偏差。角度偏差乘上位移距离偏移量,就是最后的shift,在bev空间的偏移量。
所以,这两个偏移量简单理解的区别就是,一个是全局偏移,deltax和deltay,一个是对应到bev空间的便宜shiftx shifty
追问:全局偏移和bev空间的偏移主要差在哪呢,他俩的坐标系不一样??
嗯, bev 是按车建的 车在动 bev 就在动 前后帧 bev 本来就是没对准的。里面的 delta x deltay 给的是全局偏移,也就是车在全局坐标下的位移量。
追问:那也就是整个系统需要一个全局定位的是吧
自车有一个全局坐标系的 类似于地图坐标一样 算车的前后偏移按这个地图坐标看的
问题9:老师,红色和蓝色部分看起来有点问题

anchor-based就是说里面还有有一些anchor prior在的,freeanchor还是基于预设的anchor只不过加了一些匹配策略,centerpoint是anchor-free的没有使用模板先验的,直接预测center和偏移量
问题10:老师 我想请问一下,我看课程里我们介绍的bev的输入都是multi-view images的,那么单目相机的bevfusion有推荐的方法吗,类似Kitty数据集这种?
纯单目的,无点云的kitti bev比较好的工作,一个是eccv2022的dfm,一个是wacv2022的ImVoxelNet。如果说lidar和camera融合的方法,类似于bevfusion的,在kitti数据上,关注点一般都是怎么做fusion,而不是bev空间,像现在kitti榜单上面VirConv,SFD这些,都属于融合类的方法。
问题11:LSS的lift环节,将深度分布特征和图像特征做外积之后,得到的结果为什么叫做视椎特征(frustum-shaped point cloud)?而且是近大远小的视椎特征?
图像投影到3d空间是一个锥状的,可以看一下caddn里面 frustum features画得挺好。
问题12:bevformer中怎么建模高度信息的?
沿高度维度采样 4 个点
问题13:bevfusion论文中有关数据增强操作的的这句话怎么理解?意思是只要有multi view img的输入,就不用数据增强吗?那是不是指单camera支路和fusion步骤都没有数据增强,只有单lidar支路有?bevdet视频中讲到了,为了缓解过拟合问题,bevdet作者在bev特征编码阶段,也加入了bev的数据增强操作。那bevfusion中 有这个操作吗?看论文中的第二句标红的话,是不是bevfusion中 也用了bev的特征增强?单camera 单lidar和fusion这三条路,都有bev特征,那是都有bev的数据增强吗?单camera支路,不就是和bevdet一样吗,bevdet用了bev aug,bevfusion不用,不会造成bevdet遇到的过拟合问题吗?
是的;用了 bev aug 的 在 fusion 支路用,配置文件里面有单独 aug 的 config,两条单支路没用aug,说了 train the fusion phase,如果想用的话,应该也可以试试 不过我觉得应该没啥提升 不然他就写了;肯定会有的吧 单 camera 支路性能也不高啊,但是最后反正是要 fusion 的 时候做 应该就够了;去看一下官方的训练过程,是否加aug,他会做区分的。
问题14:BEVDet论文中NxDx64xH/16xW/16这部分是怎么转换成Point Cloud的呢,Point Cloud又是怎么转换成BEVfeature形成 64x128x128的feature的呢?我理解是,N个图通过视角转换模块,再结合深度图D和内外参,转换到点云坐标系,然后通过画网格进行AvgPooling得到这个Bev feature。depth Refinement是怎么做的呢?
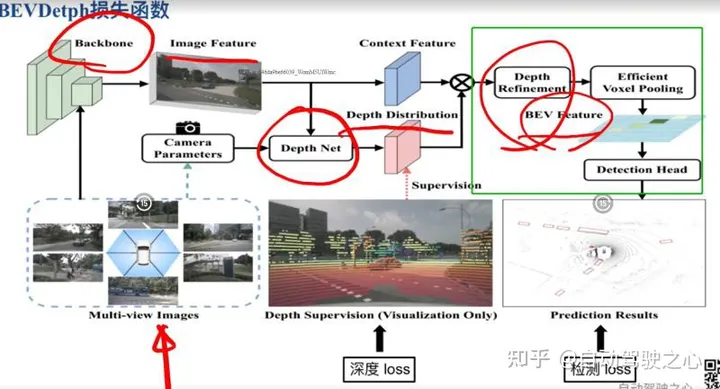
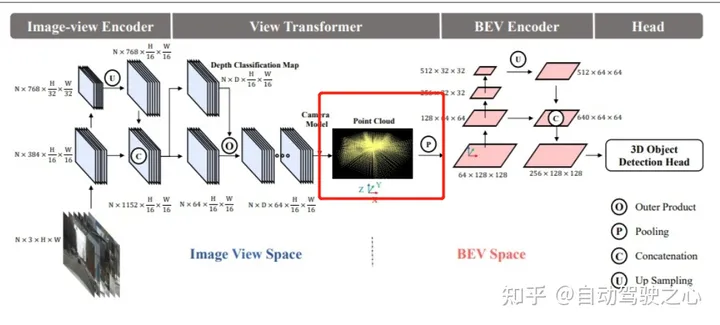
这个就是LSS方案,看看图像特征到3D空间的变换关系(基于内外参),然后生成的xyz根据x和y坐标投射到128x128格子里面,一般是-51.2~51.2m范围,每个格子是0.8m,这样就换算到-64~64再到0-128了,x和y两个维度就是128x128;沿着深度维度做特征聚合,具体可以参考这个。
问题15:现在点云和图像融合的工作,有用query查询机制,自上而下建立bev空间的工作吗?类似于bevformer的思路,但是 是用于多传感器的,有类似工作吗?
query 的好像比较少见 ref point 的倒是有 比如 futr3d
问题16:bevdepth论文中将离散深度分布替换为软硬随机数并没有崩,这是什么原因呢?
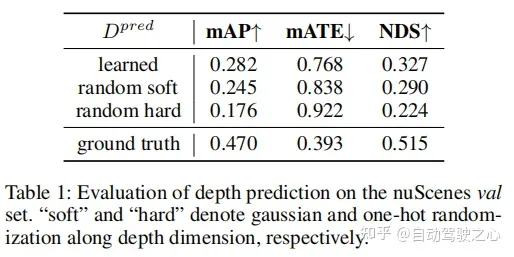
他这个具体的实验的时候应该不是我们通常理解上的全随机,估计也是加了采样或者范围上的限定的。random soft 更具代表性吧,就是说只要 depth 位置有响应,依赖后续的检测头还是能测出来的。random hard 这个就比较依赖初始化量了,初始不好估计很可能直接崩的。
问题17:bevformer的dataset的时间轴上的读取问题。论文中说是以当前时刻为基准、在过去2秒中任意取3个过去的sample和当前的sample,这个操作怎么弄的,源码中在哪里写的 是data loader么?
看一下nuscenes_dataset.py脚本里面prepare_train_data这个函数.
问题18:BEVFormer网络通过backbone提取出来的特征具体是什么?是位置?方向?还是别的什么?
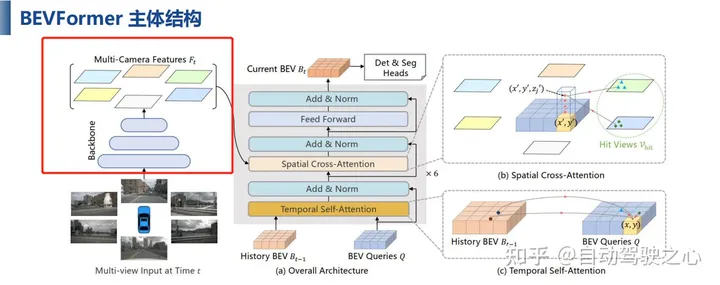
就是基本的图像特征,和一些2D任务提取的特征类似。
立减50!仅限三天!扫码领取优惠券


① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码免费学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、Occupancy、多传感器融合、大模型、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

