
- 1AI绘画:数字时代的提示工程新兴应用_新兴领域ai制图等
- 2学习taro+react从0-1完整版5/7 --- 实现tabBar效果_taro 自定义tabbar
- 3ue4 行为树_simpleparallel
- 4一切皆是映射:自然语言处理(NLP)中的AI技术_自然语言处理、语言论证等其他ai领域
- 5主流框架选择:React、Angular、Vue的详细比较_vue angular react比较
- 6【顶级快刊】IEEE(Trans),审稿快仅2个月录用,入选CCF-B,现在投最快!_ieee trans期刊
- 7【智绘未来】气候变局中的智慧之眼:机器学习赋能气候变化预测与缓解
- 8研究生写爬虫险些锒铛入狱,起因竟是为爱冲锋?_写爬虫的违法还是用的人违法
- 9OpenCV与AI深度学习 | 实战 | YOLOv8自定义数据集训练实现手势识别 (标注+训练+预测 保姆级教程)_yolov8手势识别
- 10那些程序员们后知后觉的职涯经验_后知后觉 预判
58行代码把Llama 3扩展到100万上下文,任何微调版都适用 | 最新快讯
赞
踩
量子位公众号 QbitAI
堂堂开源之王 Llama 3,原版上下文窗口居然只有……8k,让到嘴边的一句“真香”又咽回去了。
在 32k 起步,100k 寻常的今天,这是故意要给开源社区留做贡献的空间吗?

开源社区当然不会放过这个机会:
现在只需 58 行代码,任何 Llama 3 70b 的微调版本都能自动扩展到 1048k(一百万)上下文。

背后是一个 LoRA,从扩展好上下文的 Llama 3 70B Instruct 微调版本中提取出来,文件只有 800mb。
接下来使用 Mergekit,就可以与其他同架构模型一起运行或直接合并到模型中。
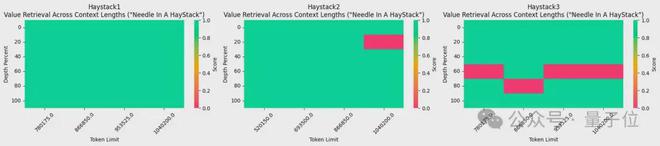
所使用的 1048k 上下文微调版本,刚刚在流行的大海捞针测试中达到全绿(100% 准确率)的成绩。

不得不说,开源的进步速度是指数级的。

1048k 上下文 LoRA 怎么炼成的
首先 1048k 上下文版 Llama 3 微调模型来自 Gradient AI,一个企业 AI 解决方案初创公司。

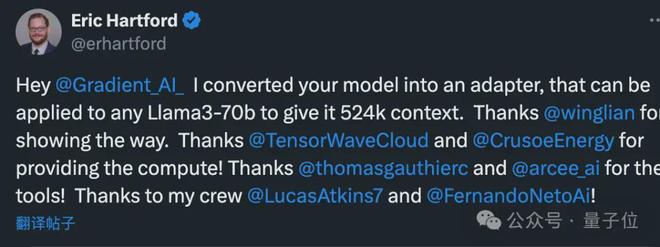
而对应的 LoRA 来自开发者Eric Hartford,通过比较微调模型与原版的差异,提取出参数的变化。
他先制作了 524k 上下文版,随后又更新了 1048k 版本。
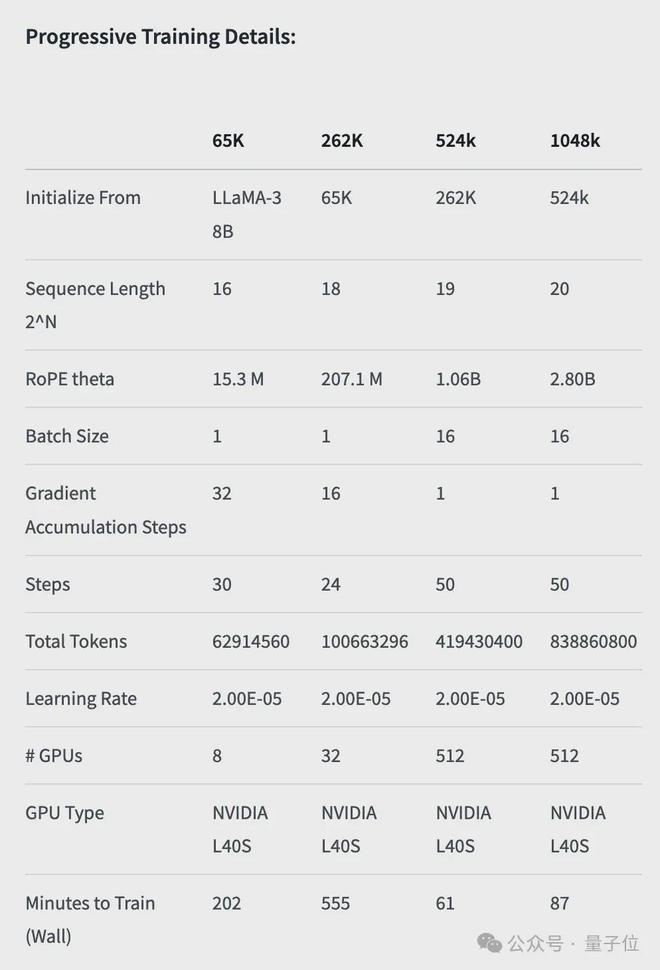
首先,Gradient 团队先在原版 Llama 3 70B Instruct 的基础上继续训练,得到 Llama-3-70B-Instruct-Gradient-1048k。
具体方法如下:
- 调整位置编码:用 NTK-aware 插值初始化 RoPE theta 的最佳调度,进行优化,防止扩展长度后丢失高频信息
- 渐进式训练:使用 UC 伯克利 Pieter Abbeel 团队提出的 Blockwise RingAttention 方法扩展模型的上下文长度
值得注意的是,团队通过自定义网络拓扑在 Ring Attention 之上分层并行化,更好地利用大型 GPU 集群来应对设备之间传递许多 KV blocks 带来的网络瓶颈。
最终使模型的训练速度提高了 33 倍。
长文本检索性能评估中,只在最难的版本中,当“针”藏在文本中间部分时容易出错。

有了扩展好上下文的微调模型之后,使用开源工具 Mergekit 比较微调模型和基础模型,提取参数的差异成为 LoRA。
同样使用 Mergekit,就可以把提取好的 LoRA 合并到其他同架构模型中了。
合并代码也由 Eric Hartford 开源在 GitHub 上,只有 58 行。
目前尚不清楚这种 LoRA 合并是否适用于在中文上微调的 Llama 3。
不过可以看到,中文开发者社区已经关注到了这一进展。
524k 版本 LoRA:
https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
1048k 版本 LoRA:
https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
合并代码:
https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
参考链接:
[1]https://twitter.com/erhartford/status/1786887884211138784
java相关学习资源、电视剧等资源下载,请点击
来自: 网易科技

