
- 1华为OD机试C、D卷 - 拼接URL(Java & JS & Python & C & C++)_org.springframework.amqp.amqpioexception: java.io.
- 2太原理工大学软件学院信息安全方向信息安全技术与应用复习_太原理工大学软件安全技术
- 32024-05-19 RabbitMq整合SpringBoot快速入门_rabbittemplate创建绑定队列
- 4HTML5---Canvas-画线,空心图,矩形,文字,三角形,旋转图片_canvas三角形绘制文字
- 5Qt制作程序启动界面类QSplashScreen实例测试详解
- 6AI大模型探索之路-实战篇:智能化IT领域搜索引擎之github网站在线搜索
- 7Flink中的分流合流操作_flink 分流操作
- 8P5018 [NOIP2018 普及组] 对称二叉树
- 9详解LinkedList与链表_listnode 与linkedlistnode
- 10基于K8s调度器实现自定义调度
交互模型你快跑,双塔要卷过来了
赞
踩
文本匹配是NLP的一个重要任务,应用场景也十分广泛,比如搜索中query和doc的匹配、问答中query和answer的匹配、甚至再泛化点来讲,也可应用到推荐、多模态图文匹配中,甚至NER、分类都可以用匹配来解。去年写过一篇文本匹配的综述,分别列举了匹配任务中的两种范式,双塔式和交互式:
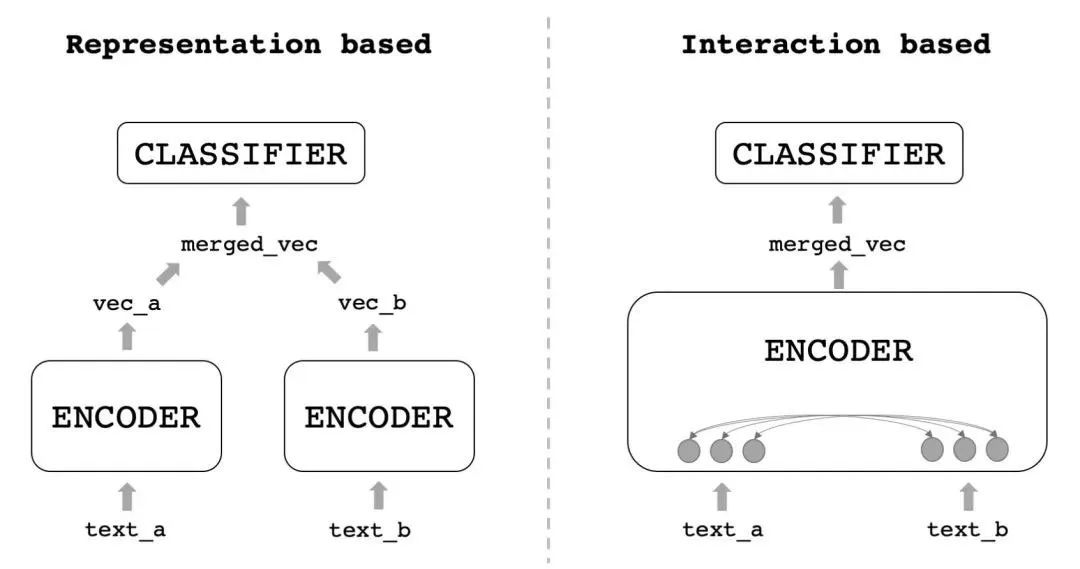
这两种范式各有优缺点:
双塔(左图)的速度很快,但是由于缺少两个句子的细粒度交互,效果始终有限
交互(右图)则完全相反,效果很好,但速度一言难尽
如果直接来对比,是这样的:

那么有没有什么方法,既有双塔的速度,又有交互的精度呢?
一年前我写文章的时候还没有,而现在,我发现离这个目标不远了,因为我们有万能的蒸馏!
那怎么才能把交互模型的知识蒸馏到双塔呢?
没想到竟然有三篇paper都在想这件事,下面我们就按照arxiv的发表顺序,来看看各位算法大佬的做法。
VIRT
第一篇是21年12月8号中科大和美团合作的文章,他们提出了一个Virtual Interaction机制,在训练阶段,把attention的交互信息蒸馏到双塔中。
对于双塔的attention,两个句子是没有交互的(下图右missing的位置):
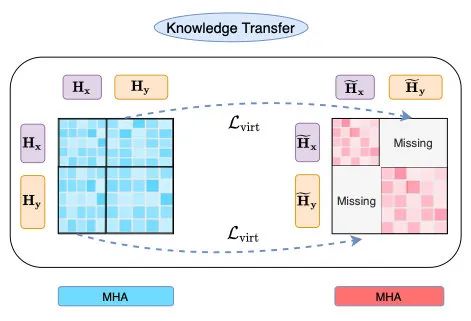
所以作者就单独把双塔的隐层拿出来做一次attention:
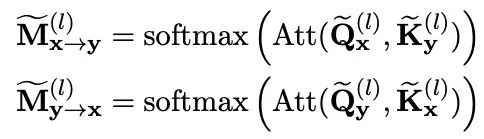
再和交互模型相同位置的attention计算L2损失:
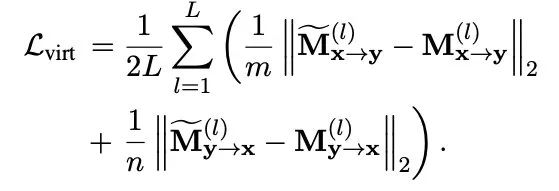
最后,为了更好地利用上一点学到的交互知识,作者在双塔模型的metric计算上又加了一个attention机制,名为VIRT-adapted Interaction。具体计算方式为:
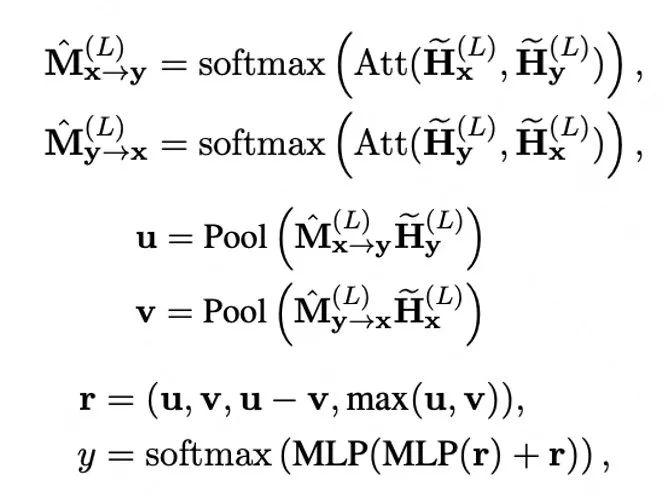
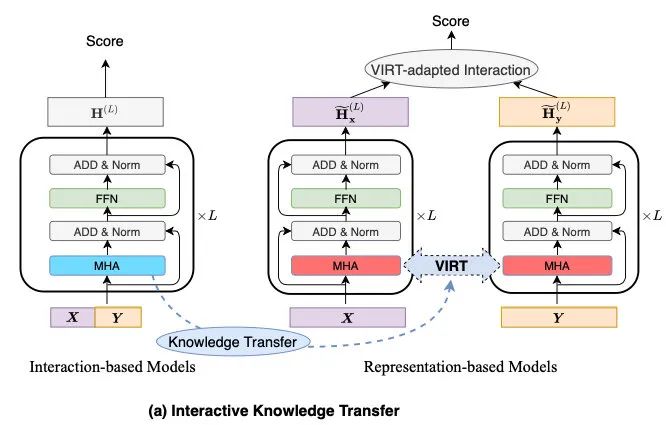
最终整体结构如下:
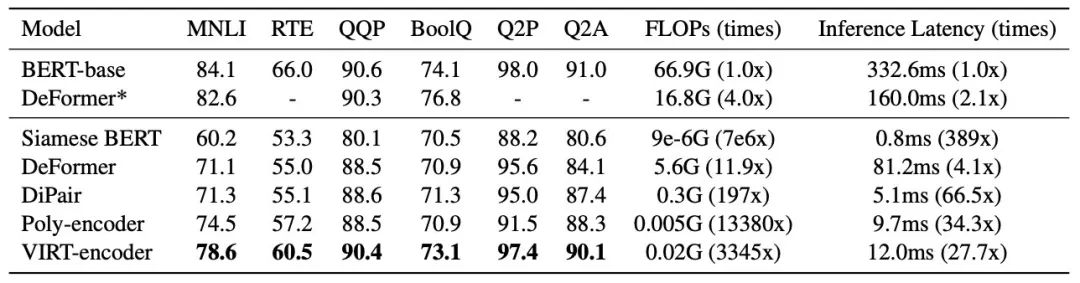
这样蒸馏之后,双塔模型的提升十分显著,比起双塔baseline有十个点多,甚至好几个任务都要追上交互模型了:
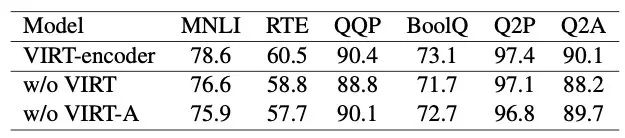
从消融实验来看,最终所加的adaption还是十分重要的,VIRT在前半部分让双塔学到了如何交互,所以最后一交互就抓到了重点:
Distilled-DualEncoder
这篇是哈工大和微软合作的工作,跟VIRT的时间算是前后脚,21年12月16号挂到arxiv上,不过这篇工作主要是做图像和文本匹配的。出发点和VIRT也比较相似,只不过是用KL散度来蒸馏(老实说L2、KL散度、交叉墒在蒸馏时都可以用,具体效果我实践下来差距还不小,很玄学),并且在最后没有增加额外的attention:
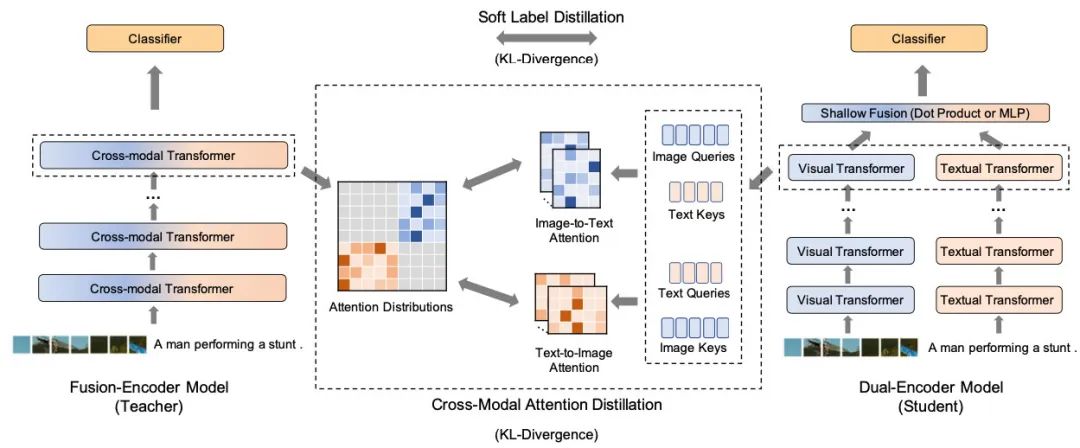
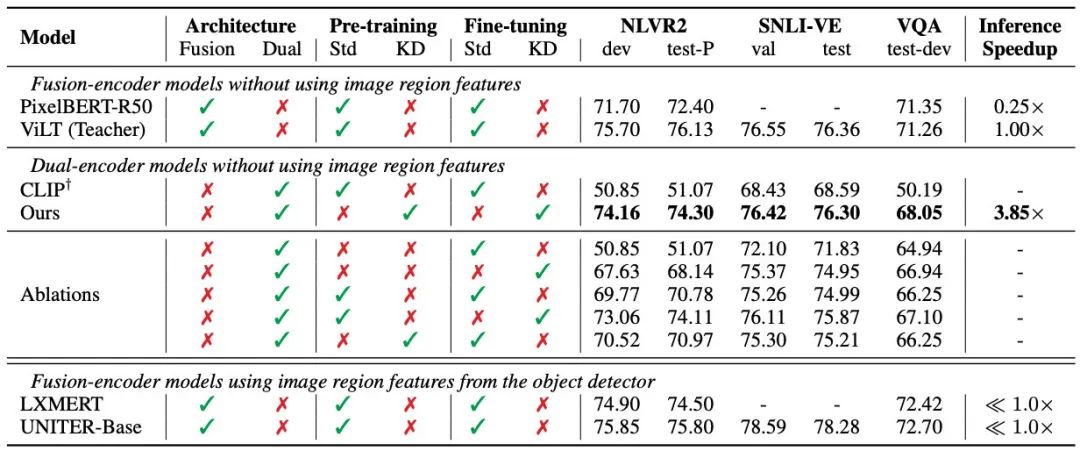
但作者除了在精调阶段蒸馏之外,也进行了预训练蒸馏,效果同样是比CLIP基线好了不少:
ERNIE-Search
这篇是百度22年5月18号挂在arxiv的工作,不过他们没有对每层的attention进行蒸馏,而是重点攻克最后一层。作者主要参考了ColBERT,ColBERT在最后的交互上使用了一个MaxSim机制:
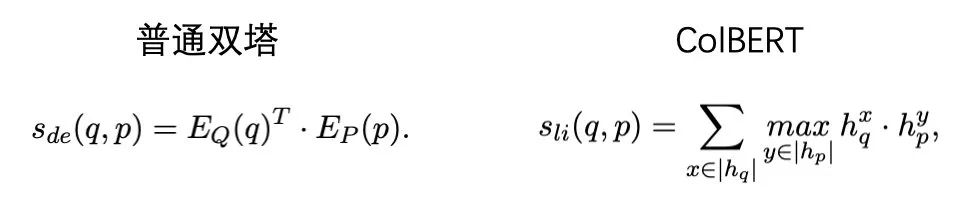
作者使用KL散度,分别把交互模型的attention和最终logits都蒸馏给了ColBERT(attention的蒸馏和上两个工作的计算一样):
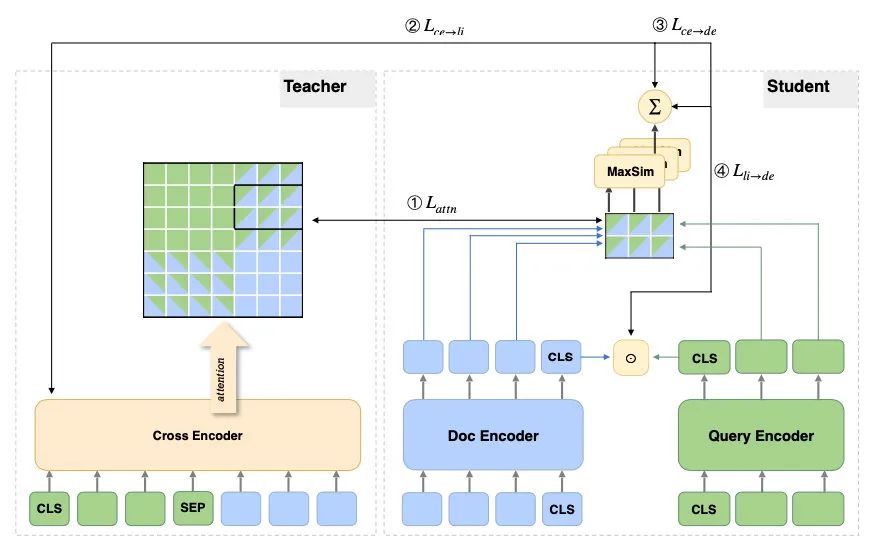
把知识蒸馏给ColBERT之后,作者对于速度的追求依旧不减,又把ColBERT的MaxSim分数蒸馏给了dot product:
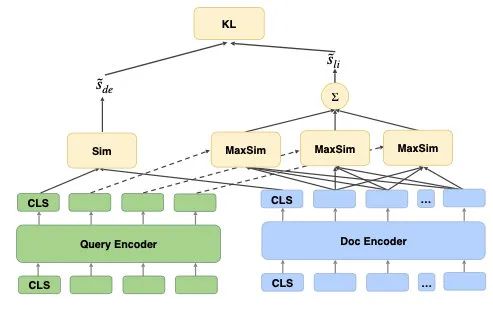
在训练的过程中,所有的模型都是一起训练的(教师模型并没有freeze),一共有7个损失,幸亏作者没给损失加超参数,不然这个调参量有点巨大:
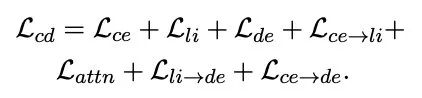
其中ce=cross-encoder, li=ColBERT的late interaction, de=dual encoder。
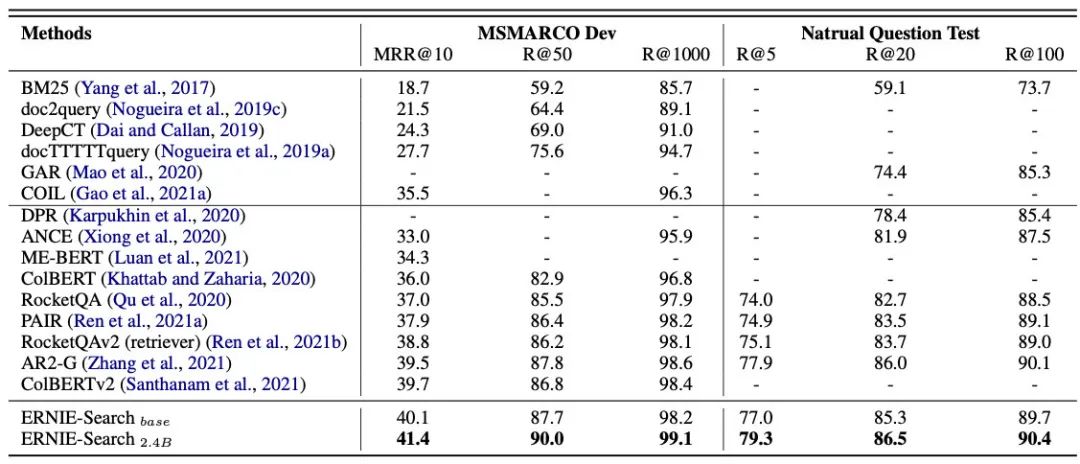
最终效果主要是在搜索和问答数据上看的:
总结
上面三篇工作各有千秋,应用场景也不一样,不过在优化双塔模型的出发点上都想到了一起,就是给双塔增加更多的交互。那么除了蒸馏,还有没有别的办法呢?这个问题,就留给你吧。

一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



