
- 1性能之选:2024年最令人期待的开源Web服务器
- 2移动端跨平台方案对比:React Native、weex、Flutter_weex rtc
- 3用Python一分钟搞定,从几百个Excel中查找数据_python从多个excel表中提取多个元素
- 4text2sql框架-vanna-1_vanna前端
- 5【华为OD机试C卷D卷】字符串变换最小字符串【C++/Java/Python】_给定一个字符串 最多只能交换一次 返回变换后能得到的最小字符串
- 6【mysql】mysql调优时必须掌握的慢查询语句排查命令_mysql exporter 慢查询
- 7cefsharp实现资源替换如网页背景、移除替换标签、html标识、执行javascript脚本学习笔记(含源码说明)_cef执行js脚本
- 8python解析html标签_[python] 常用正则表达式爬取网页信息及分析HTML标签总结
- 9vue3.0常用eslint配置详解 .eslintrc.js_vue3 .eslintrc.js
- 10【NLP】PageRank、TextRank算法的原理解析_textrank和pagerank
滑块验证码------啥?你居然还在手动滑动,你不来试试自动滑动吗_canvas 标签 如何实现滑块验证
赞
踩
测试网站
测试网站:https://www.geetest.com/demo/slide-float.html
我的giteer:秦老大大 (qin-laoda) - Gitee.com里面有我写的代码
作者备注:由于我个人原因,文章写得感觉太长,后面我会把一个知识分成多部文章,这样可以简单明了的看到了
验证码的思路有两种:一种是通过selenium来操作,这种操作简单但是运行过程速度慢,二是用js去做,这种做法比较麻烦,但是速度快
下面我来讲解一下selenium的做法 :
第一步,先在网页定位到我们要操作的地方,html的标签canvas

思路1:要拿到两张图片,一张有缺口的图片,一张没有缺口的图片,后面我们可以通过比例来获取滑块需要滑动的距离(因为网页上的图片大小和实际的图片大小不一样,因为那是按比例缩小或者放大的)
思路2:获取缺口图片和滑块图片,来做对比得到滑块滑动的距离
如果细心的小可爱就会发现,滑块图片没有链接下载
下面我们来一一解决,首先我们要获取图片

我们要个改一下页面的html代码如上图所示:
而实际发送回来的却是没有改的,我们需要用python代码更改一下:
代码:
- # 修改css的样式
- def get_css(self):
- time.sleep(2)
- # js语句执行 改变css
- self.driver.execute_script("document.querySelectorAll('canvas')[2].style=''")# canvas标签的个数下标从0开始,更改第三个的style
结果:

获取图片代码如下:
- def crop_image(self,img_name):
- # 获取该图片的大小,可以通过div的框的大小进行
- img=self.driver.find_element_by_xpath('//div[@class="geetest_canvas_img geetest_absolute"]')
-
- # 把页面全屏化
- # self.driver.maximize_window()
-
- # 框的左上角的位置(x,y)
- img_left_up=img.location
- print(img_left_up)
-
- # 获取div框的大小(一个字典)
- print(img.size)
-
- # 获取图片右下角的坐标
- img_x,img_y=img_left_up["x"],img_left_up["y"]
- img_right_below_x,img_right_below_y=img_x + img.size["width"],img_y + img.size["height"]
-
- # 截屏(二进制)
- screen_shot=self.driver.get_screenshot_as_png()
- # 读取这个图片(读取内存中的二进制)
- by_io=BytesIO(screen_shot)
- # 打开图片
- op_img=Image.open(by_io)
- # 截取图片(截取下来的宽高),一个元组(a,b)
- cap_img=op_img.crop((int(img_x),int(img_y),int(img_right_below_x),int(img_right_below_y)))
- # 保存图片到文件中
- cap_img.save(img_name)
- return cap_img

下面我来一一讲解

我们要先清楚,因为我们没有链接下载图片,就只能截取图片,截图要清楚截图哪个地方 ,

首先我们要截图div的框的大小
img=self.driver.find_element_by_xpath('//div[@class="geetest_canvas_img geetest_absolute"]')
我是定位了这个div框
img_left_up=img.location
这行代码比较重要,location返回一个坐标,返回哪个坐标,嘿嘿,我来告诉你们,
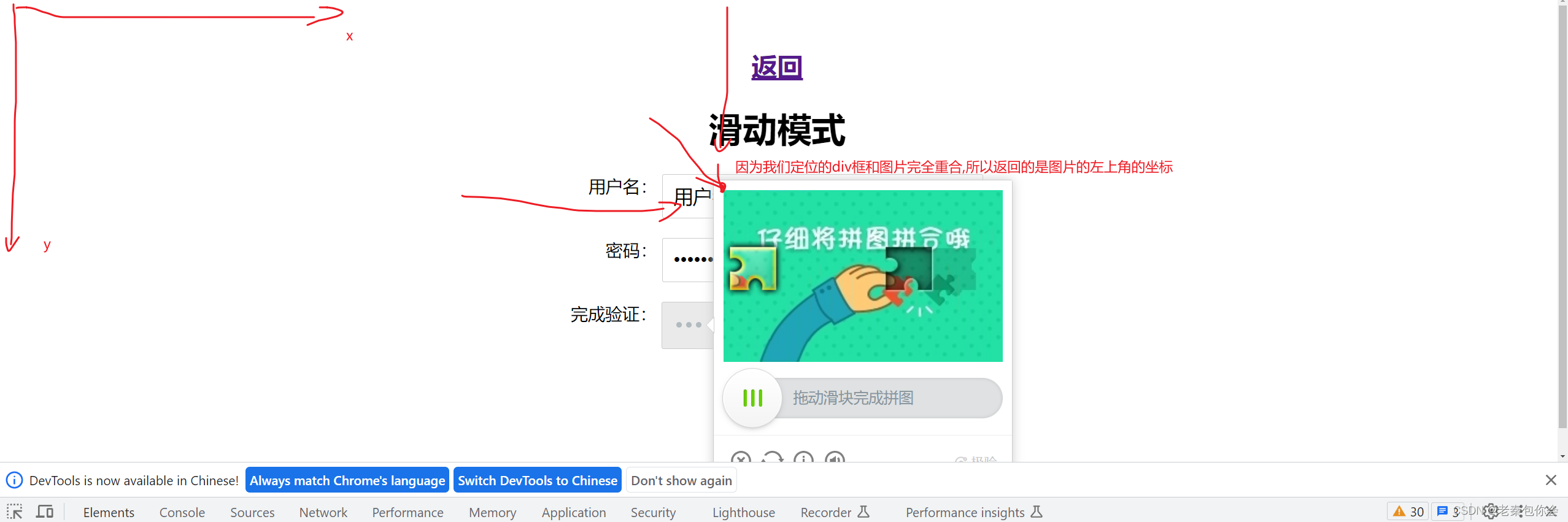
返回的是我们定位框的左上角的坐标(因为框和图片重合了,可以理解为图片的左上角坐标),
可是,我们要截图给光靠一个坐标还不行,我们还需得到右下角的坐标,怎么获取?我们可以获取框的大小,通过数学算法来得出
print(img.size)打印的是一个字典,返回了框的大小,
img_x,img_y=img_left_up["x"],img_left_up["y"] img_right_below_x,img_right_below_y=img_x + img.size["width"],img_y + img.size["height"]
这两行代码就得出了右下角的坐标了
那我们就来截取图片吧
screen_shot=self.driver.get_screenshot_as_png()
可以看出这个截图方法和我们之前的截图方法有点不一样
driver.save_screenshot("百度.png")
可以看出这个是有保存在文件里的,所以get_screenshot_as_png()是保存在内存里的(二进制)
那我们需要读取这个图片(二进制)就需要我们导入from io import BytesIO
BytesIO(二进制)
读取过后,我们还需要打开图片,
我们就需要下载模块了pip install pillow
导入模块:
from PIL import Image
打开图片
Image.open(by_io)
下面我们就要截取图片l:
cap_img=crop((x1,y1,x2,y2))
保存图片
cap_img.save("文件路径")
因为我们要保存两张图片一张原图,一张是有滑块的
原图:
滑块图:
图片的对比:


我们要比较无滑块的部分(利用RGB三色比较色差)
下面两张图可以让你们理解一下页面的坐标轴


代码如下:
- # 像素的对比
- def compare_pixel(self,img1,img2,i,j):
- pixel1=img1.load()[i,j]# 加载img1需要对比的像素并转换为RGB
- pixel2=img2.load()[i,j]# 加载img2需要对比的像素并转换为RGB
- # 对比误差范围
- threshold=60
- #RGB三颜色
- if(pixel1[0]-pixel2[0])<=threshold and (pixel1[1]-pixel2[1])<=threshold and(pixel1[2]-pixel2[2])<=threshold:
- return True
- return False
-
- def pixel(self,img1,img2):
- left=60#从像素60的位置开始
- has_find=False #没有发现那个凹槽
- #图片的大小(截取下来的宽高),一个元组(a,b)
- print(img1.size)
- # 一个个像素对比
- for i in range(left,img1.size[0]):#宽
- if has_find:
- break
- for j in range(img2.size[1]):
- if not self.compare_pixel(img1,img2,i,j):#img1对应的像素点(i,j)和img2对应的像素点(i,j)做对比(一个个的对比)
- distance=i
- print(distance)
- has_find=True
- # 只要碰到就立刻停止
- break
- return distance
我先来讲解一下第二个实例方法:
left=60从像素50开始对比
has_find=False是用于判断循环的在碰见凹槽时就停止循环,
return返回遇见有凹槽第一个像素的坐标的x,(这个只是大概的后面还需要微调)
第一个实例方法:
pixel1=img1.load()[i,j]# 加载img1需要对比的像素并转换为RGB pixel2=img2.load()[i,j]# 加载img2需要对比的像素并转换为RGB
load()加载 [i,j]对应的像素位置
threshold=60
色差
RGB有三色,三色比较,每一种色差不超过600
由于我们得到了移动的大概距离,因为有检测,我们就要躲过检测,模拟人来滑动
模拟人工滑动轨迹
代码如下:
- #移动的轨迹
- def trajectory(self,distance):
- # d=vt+1/2at**2==>位移=初速度*时间+1/2加速度*时间的平方
- # v1=v+at
- # 思路:先加速,然后加速
- # 移动轨迹
- distance-=6
- track=[]
- # 当前移动的距离
- current=0
- # 移动到某个地方开始减速
- mid=distance*3/4
- # 间隔时间(加速时间)
- t=0.1
- # 初速度
- v=0
- pass
- while current<distance:
- if(current<mid):
- a=random.randint(2,3)
- else:
- a=random.randint(4,5)
- v0=v
- v=v0+a*t
- move=v0*t+1/2*a*t**2
- current+=move
- track.append(round(move))
- return track
我们可以借用物理的位移公式
d=vt+1/2at**2==>位移=初速度*时间+1/2加速度*时间的平方
我们需要自定义初速度,加速时间,加速度
思路:如果位移小于要移动的距离,继续移动
我们还要设计一个加速度在哪个地方加大
最后我们通过位移公式来计算每加速t秒移动的距离,设计成运动轨迹
selenium操作移动
代码如下:
- def selenium(self,track):
- # js过检
- js = "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"
- self.driver.execute_script(js)
- #运用行为链
- ac=ActionChains(self.driver)
- #定位
- div=self.driver.find_element_by_class_name("geetest_slider_button")
- # 按住不松
- ac.click_and_hold(div)
- # 移动
- for i in track:
- ac.move_by_offset(xoffset=i,yoffset=0)
- time.sleep(0.1)
- # 松开
- ac.release()
- # 提交行为
- ac.perform()
前面看过我写过的selenium的文章就会知道思路来,
我还是一一来解释一下:
利用行为链来操作
导入
from selenium.webdriver.common.action_chains import ActionChainsc
创建行为链对象
ac=ActionChains(self.driver)
进行操作:
定位
div=self.driver.find_element_by_class_name("geetest_slider_button")
# 按住不松
ac.click_and_hold(div)
# 移动
for i in track:
ac.move_by_offset(xoffset=i,yoffset=0)
time.sleep(0.1)
# 松开
ac.release()
注意ac.move_by_offset(xoffset=i,yoffset=0)是每次移动多少距离,
全部代码如下:
- from selenium import webdriver
- import time
- from PIL import Image
- from io import BytesIO
- import random
- from selenium.webdriver.common.action_chains import ActionChains
-
- class Radar(object):
- def __init__(self):
- self.url="https://www.geetest.com/demo/slide-float.html"
- # 创建一个浏览器
- self.driver=webdriver.Chrome()
- # 打开网页
- self.driver.get(self.url)
- # 隐式等待
- self.driver.implicitly_wait(5)
-
- # 定位
- def gps(self):
- return self.driver.find_element_by_xpath('//span[@class="geetest_radar_tip_content"]')
-
- # 点击
- def click1(self):
- self.gps().click()
-
- # 修改css的样式
- def get_css(self):
- # 加个休息时间,让页面加载出来
- time.sleep(2)
- # js语句执行 改变css(把有缺口的图片隐藏起来)
- self.driver.execute_script("document.querySelectorAll('canvas')[2].style=''")# canvas标签的个数下标从0开始,更改第三个的style
-
- # 恢复有缺口的图片
- def restore_img(self):
- # 加个休息时间,让页面加载出来
- time.sleep(2)
- # 显示出有缺口的图片
- self.driver.execute_script("document.querySelectorAll('canvas')[2].style='display:none'")
-
- # 截取验证码
- def crop_image(self,img_name):
- # 获取该图片的大小,可以通过div的框的大小进行
- img=self.driver.find_element_by_xpath('//div[@class="geetest_canvas_img geetest_absolute"]')
-
- # 把页面全屏化
- # self.driver.maximize_window()
-
- # 框的左上角的位置(x,y)
- img_left_up=img.location
- print(img_left_up)
-
- # 获取div框的大小(一个字典)
- print(img.size)
-
- # 获取图片右下角的坐标
- img_x,img_y=img_left_up["x"],img_left_up["y"]
- img_right_below_x,img_right_below_y=img_x + img.size["width"],img_y + img.size["height"]
-
- # 截屏(二进制)
- screen_shot=self.driver.get_screenshot_as_png()
- # 读取这个图片(读取内存中的二进制)
- by_io=BytesIO(screen_shot)
- # 打开图片
- op_img=Image.open(by_io)
- # 截取图片(截取下来的宽高),一个元组(a,b)
- cap_img=op_img.crop((int(img_x),int(img_y),int(img_right_below_x),int(img_right_below_y)))
- # 保存图片到文件中
- cap_img.save(img_name)
- return cap_img
-
- # 像素的对比
- def compare_pixel(self,img1,img2,i,j):
- pixel1=img1.load()[i,j]# 加载img1需要对比的像素并转换为RGB
- pixel2=img2.load()[i,j]# 加载img2需要对比的像素并转换为RGB
- # 对比误差范围
- threshold=60
- #RGB三颜色
- if(pixel1[0]-pixel2[0])<=threshold and (pixel1[1]-pixel2[1])<=threshold and(pixel1[2]-pixel2[2])<=threshold:
- return True
- return False
-
- def pixel(self,img1,img2):
- left=60#从像素60的位置开始
- has_find=False #没有发现那个凹槽
- #图片的大小(截取下来的宽高),一个元组(a,b)
- print(img1.size)
- # 一个个像素对比
- for i in range(left,img1.size[0]):#宽
- if has_find:
- break
- for j in range(img2.size[1]):
- if not self.compare_pixel(img1,img2,i,j):#img1对应的像素点(i,j)和img2对应的像素点(i,j)做对比(一个个的对比)
- distance=i
- print(distance)
- has_find=True
- # 只要碰到就立刻停止
- break
- return distance
-
- #移动的轨迹
- def trajectory(self,distance):
- # d=vt+1/2at**2==>位移=初速度*时间+1/2加速度*时间的平方
- # v1=v+at
- # 思路:先加速,然后加速
- # 移动轨迹
- distance-=6
- track=[]
- # 当前移动的距离
- current=0
- # 移动到某个地方开始减速
- mid=distance*3/4
- # 间隔时间(加速时间)
- t=0.1
- # 初速度
- v=0
- pass
- while current<distance:
- if(current<mid):
- a=random.randint(2,3)
- else:
- a=random.randint(4,5)
- v0=v
- v=v0+a*t
- move=v0*t+1/2*a*t**2
- current+=move
- track.append(round(move))
- return track
-
- def selenium(self,track):
- # js过检
- js = "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"
- self.driver.execute_script(js)
- #运用行为链
- ac=ActionChains(self.driver)
- #定位
- div=self.driver.find_element_by_class_name("geetest_slider_button")
- # 按住不松
- ac.click_and_hold(div)
- # 移动
- for i in track:
- ac.move_by_offset(xoffset=i,yoffset=0)
- time.sleep(0.1)
- # 松开
- ac.release()
- # 提交行为
- ac.perform()
-
-
-
-
-
-
-
-
-
-
-
-
-
- def main(radar):
- radar.gps()
- radar.click1()
- #下载无缺口图片
- radar.get_css()
- img1=radar.crop_image("./截图.png")
- # 下载有缺口的图片
- radar.restore_img()
- img2=radar.crop_image("./截图1.png")
- # 获取距离
- distance=radar.pixel(img1,img2)
- # 人工模拟滑动轨迹
- track=radar.trajectory(distance)
- print(track)
-
- #selenium滑动
- radar.selenium(track)
-
-
- if __name__ == '__main__':
- radar=Radar()
- main(radar)
总结:滑块验证码最重要的思路就是能算出移动距离,selenium移动只是一个辅助,着重看计算距离的代码,因为现在很多能检测到selenium特征的反爬,后面我会写另一种,滑块验证,有兴趣的小可爱可以过来参观

