
- 1oracle做拉链,Datastage实现拉链算法
- 2ShardingSphere读写分离
- 3地理信息系统教程(汤国安)——重点总结_双重独立编码结构
- 4NLP发展简史_nlp的发展阶段
- 5通用与垂直,谁将领跑未来?
- 6 推荐一款高效智能的校园考勤系统:Sistem Absensi Sekolah Berbasis QR Code
- 7python3.7+dlib+face_recognition+tensorflow+keras+scipy+numpy版本(已实现)_scipy对应cpu版本
- 8ARM 上的C语言开发_arm的c语言
- 9【软件工程】——开发模型_软件三大开发方法表格对比
- 10学习笔记Label自右向左滚动和父容器内左右移动方法(含代码)_lvgl文本从右到左滚动
Redis跳跃表(SkipList)_redis 跳跃表
赞
踩
什么是跳跃表
跳跃表(skiplist)是一种有序且随机化的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表的用处
有序集合(zset)的底层可以采用数组、链表、平衡树等结果来实现, 但是他们都有各自的缺点,数组方便查询,但不便于插入和删除;链表方便插入和删除,但是不利于查找;平衡树/红黑树效率高但是实现起来很复杂。
为什么 Redis 不使用这样一些结构呢?
- 性能考虑: 在高并发的情况下,树形结构需要执行一些类似于 rebalance 这样的可能涉及整棵树的操作,相对来说跳跃表的变化只涉及局部
- 实现考虑: 在复杂度与红黑树相同的情况下,跳跃表实现起来更简单,看起来也更加直观
所以Redis自己实现了跳跃表来来当做有序集合(zset)的底层实现, 他的查询复杂度平均O(logN), 最坏O(N), 堪比红黑树,但实现起来远比红黑树简单。
跳跃表解决什么问题
先分析一下链表,链表的优势是插入、删除快,查询很慢。对于链表来讲,即便链表中存储的数据是有序的,如果我们要向在其中查找某个数据,它只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,达到了O(n)。
若要查找值为5的元素,需要从第一个元素依次向后查询,共需比较5次才可以。

假设要查找值为5的元素,可以先在索引层遍历,当遍历到索引层中值为5的元素时就返回。在原单链表中查找值为5的元素,需要遍历比较5次才可以。而现在有了一级索引后,只需要遍历3次就可以找到对应的元素。
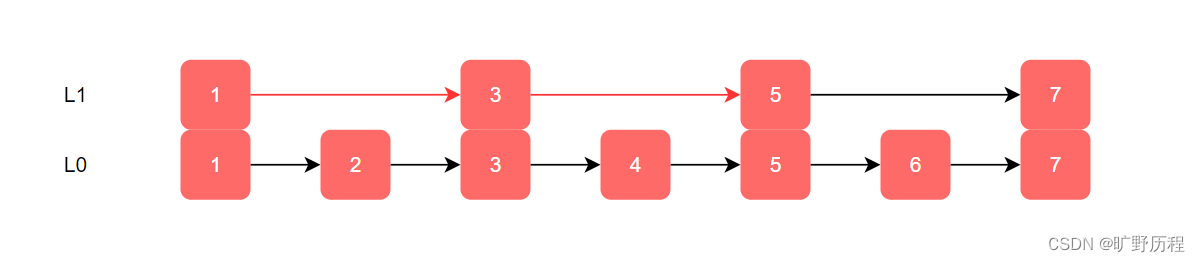
从上个例子中,每加来一层索引后,查找元素需要遍历的次数就会减少,查询效率也得到提升,同理在一级索引的基础上,在加二级索引。
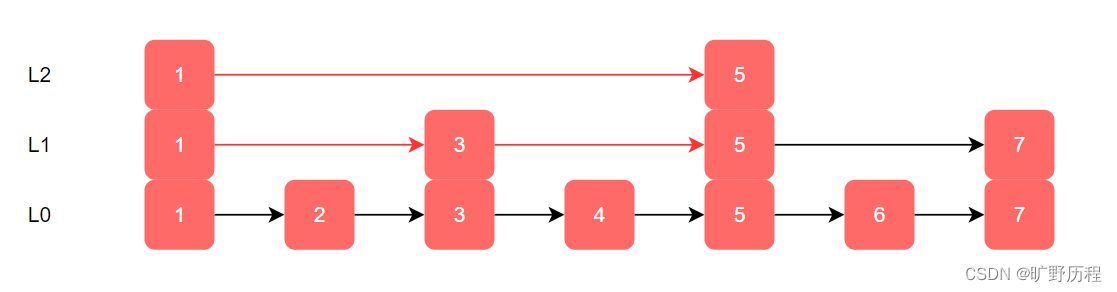
假设要查找值为6的元素,可以先在索引层遍历,当遍历到索引层中值为7的元素时,则会下降到下层链表层继续查找值为6的元素。
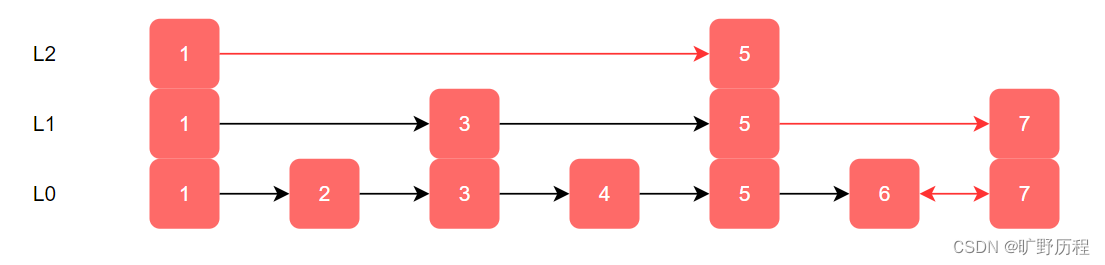
从图中我们可以看出,查找效率又有了提升,因为在这里例子中我们的数据量很少,当有大量的数据时,我们可以增加多级索引,在查询时,效率可以得到明显的提升。像这种链表增加多种索引的结构,就是 跳跃表。
跳跃表是如何进行查找的呢?
- 优先从高层查找
- 若当前节点的值小于要查找的值,且 next 指针指向大于目标值的节点就降一级寻找,或 next 指针指向了 null ,也需要降一级查找。
与 B+树 对比
B+树存储就是一个平衡搜索树,如果要插入一个节点那么就检索到这个节点插入,插入的时候要维护子树的规则(平衡搜索树)还有就是 B+树 在 mysql 当中还要在一定的情况下扩容和缩容。这就要消耗一定的资源算力,而跳表这里用随机层数来解决这个问题,这样就解决了插入的消耗问题,比平衡术更加优秀。
由此可见跳表的本质是解决查找问题。
插入元素实现
如果理解上面所说的跳跃表的原理,那么很容易理清楚插入节点时发生的几个动作 (几乎跟链表类似):
- 找到当前我需要插入的位置
- 创建新节点,调整前后的指针指向,完成插入
跳表的增删改
插入操作
插入操作在实现起来是最麻烦的,需要的考虑的东西最多。插入需要考虑是否插入索引,插入几层等问题。其流程为:
- 首先通过上面查找的方式,找到要插入的节点
- 插入完这一层,需要考虑上一层是否插入,首先判断当前索引层级,如果大于最大值那么就停止(说明已经到最高索引层)。否则就使用随机化的方法去判断是否向上层插入索引,即产生一个[0-1]的随机数。如果小于0.5就向上插入索引,插入完毕后再次使用随机数判断是否向上插入索引
- 继续上的操作,直到概率退出或者索引层数大于最大索引层
删除操作
删除操作比起查询稍微复杂一丢丢,但是比插入简单。删除需要改变链表结构,需要先找到元素,然后对于每个层的相关节点重排前向后向指针,所以需要处理好节点之间的联系,同时还要更新层数。
对于删除操作你需要谨记以下几点:
- 删除当前节点和这个节点的前后节点都有关系
- 删除当前层节点之后,下一层该key的节点也要删除,一直删除到最底层
更新操作
暂时没做研究
总结
- 跳跃表基于单链表+索引的方式实现
- 跳跃表是以空间换时间的方式提升了查找速度
- Redis的跳跃表实现由 zskiplist 和 zskiplistnode 两个结构组成,其中 zskiplist 用于保存跳跃表信息(比如表头节点、表尾节点、长度),而 zskiplistnode 则用于表示跳跃表节点

