- 1全自动ai生成视频MoneyPrinterTurbo源码 在线ai生成视频源码
- 2免费小说阅读器(Android版本)全站开源_开源小说阅读器
- 3基于Java的甜品商城系统【附源码】_蛋糕商城源码
- 4spring框架_spring是一个轻量级的javaee
- 5配置微信小程序自动更新_小程序自动更新版本
- 6使用U盘在VMware虚拟机安装Windows和Ubuntu(Linux)系统,非常详细!_u盘配置vmware虚拟机ubuntu
- 7【大数据】一些基本概念_读取型schema
- 8Spring事务与数据库事务之间的关系_spring事务和数据库事务的关系
- 9MongoDB教程:创建用户并添加角色_mongodb 角色
- 10未来已来!AI数字人客服引领服务行业革新潮流_越来越多商圈 数字人客服
MySQL事务和锁_事务一直在进行, 数据库连接会释放吗
赞
踩
1.事务
1.什么是事务?
事务: 要么全部成功,要么全部失败
事务是数据库管理系统(DBMS)执行过程中的一个 逻辑单位 ,由一个 有限的数据库操作序列 组成。
逻辑单位:最小的操作单位,不可再分割。
有限的数据库操作序列:包含一个或多个DML语句。
支持事务的引擎: InnoDB、NDB
2.事务的四大特性是啥?
ACID: 最终目的——保证数据的一致性。
原子性(Atomicity): 事务是不可分割的工作单位,DML语句要么全部成功,要么全部失败。
一致性(Consistency): 事务执行前后,数据库中的数据必须保持一致。
隔离性(Isolation): 多用户并发访问数据库时,每个用户之间的操作不会相互影响。
持久性(Durablity): 事务一旦被提交,它对数据库的改变就是不可逆的。
3.事务相关操作
查看事务开启状态:
SHOW VARIABLES LIKE 'autocommit';
- 1
自动提交事务默认开启
关闭事务自动提交:
SET SESSION autocommit = off;
- 1
手动开启事务:
-- 下列两个命令是等价的
BEGIN;
-- 或者
START TRANSACTION;
- 1
- 2
- 3
- 4
结束事务:回滚或者提交
-- 回滚
ROLLBACK;
-- 提交
COMMIT;
- 1
- 2
- 3
- 4
- 5
还有一种结束:使用可视化界面工具执行了一条DML语句,还没回滚或者提交,就把页面关闭了,后台也会结束事务。
事务持有的锁,会在事务结束的时候释放。
4.事务并发带来的问题有哪些?
1.脏读
脏读(Dirty read): 一个事务读取到了另一个事务 未提交 的数据。
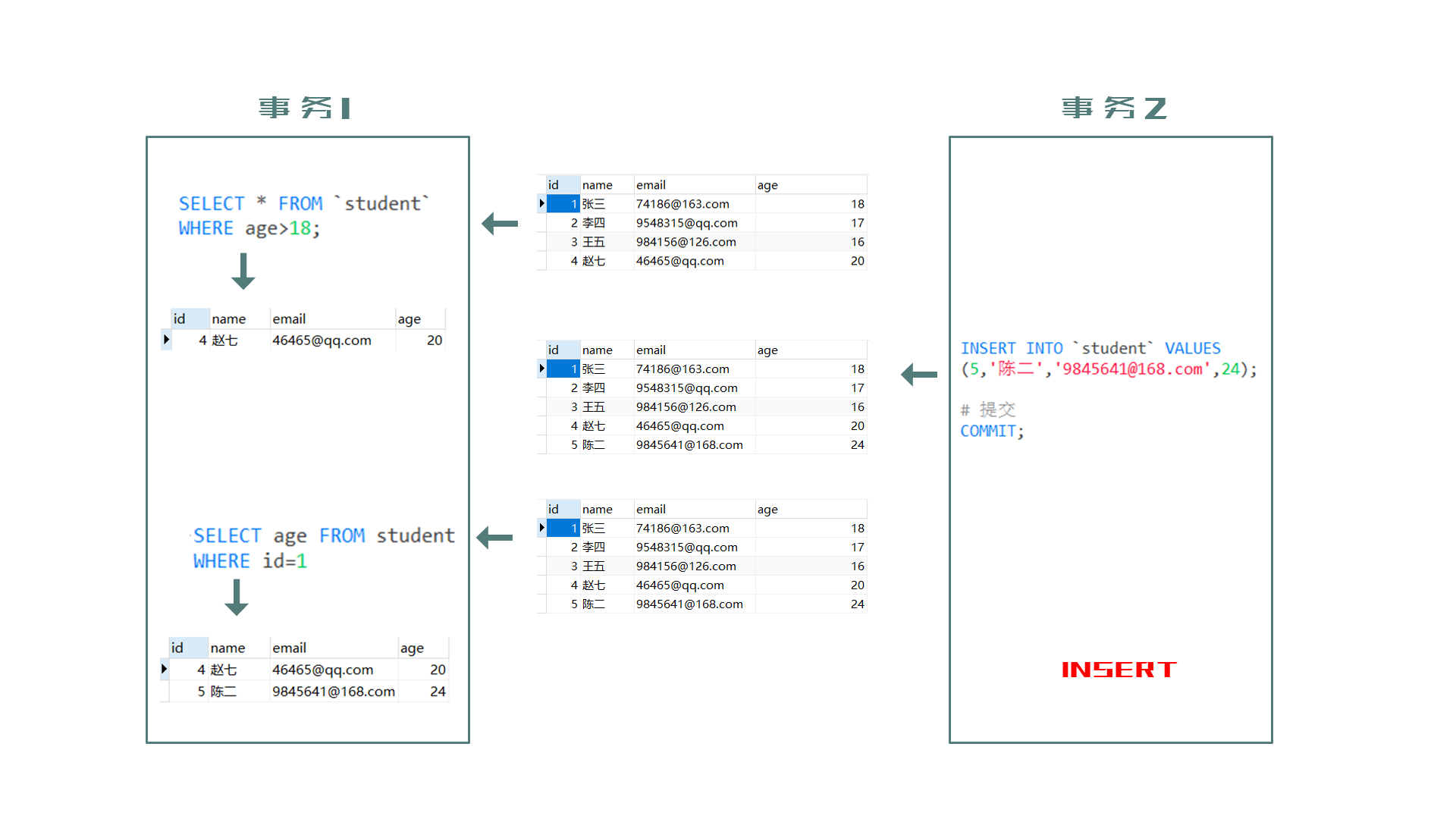
图解:以下为自动提交事务关闭情况
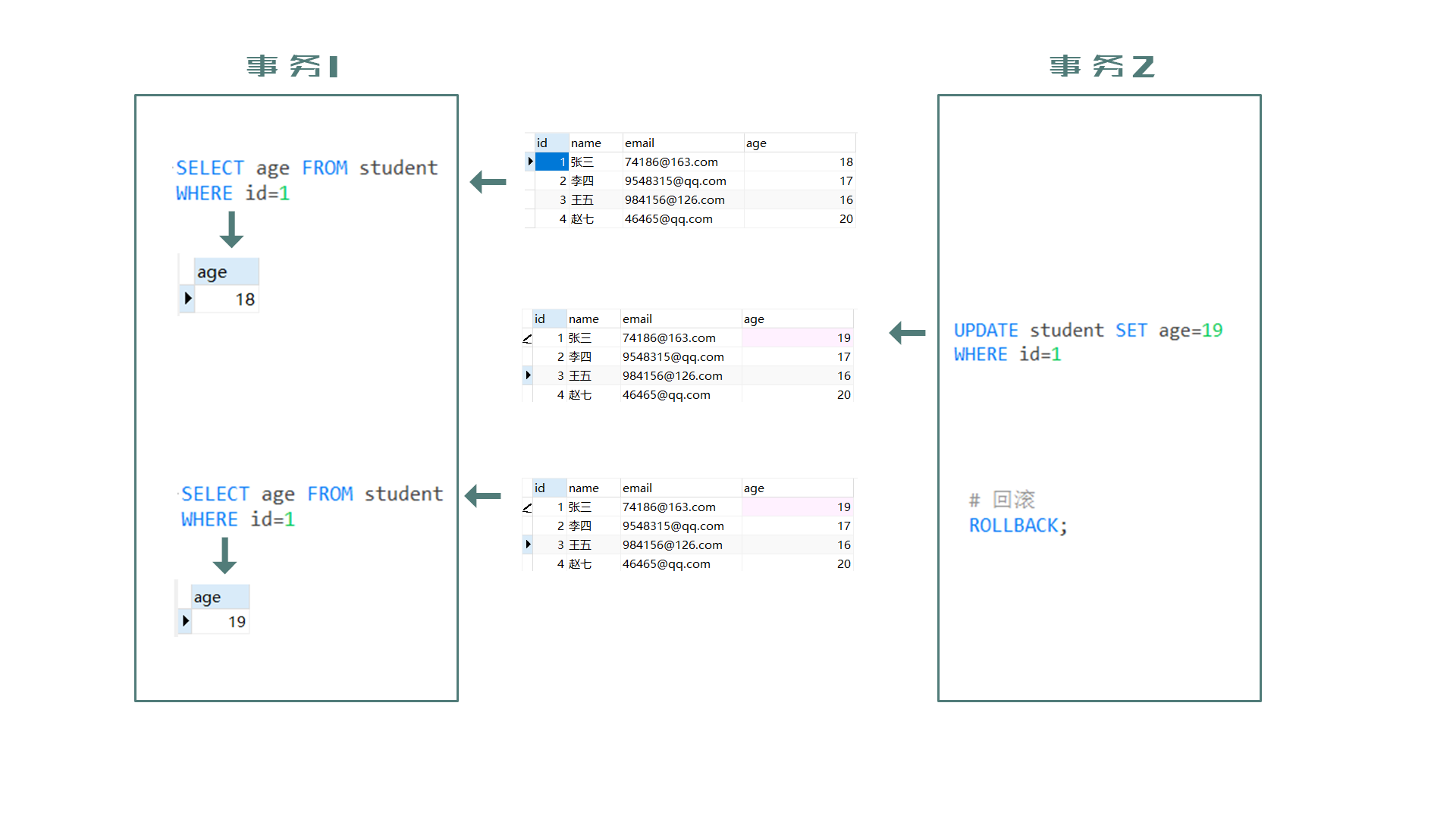
事务2修改了age(age=19),但并未提交,这时候事务1却读取了此数据(age=19),而事务2却回滚取消了此数据修改(age=18)。
这时候数据库中age的age是18,但是事务1却读到了age是19,故而产生了脏读。
2.不可重复度
不可重复度(Non-repeatable read): 一个事务中前后执行两次相同的查询操作,由于第二次读取到了其他事务 已提交 的数据,得到了不同的查询结果。
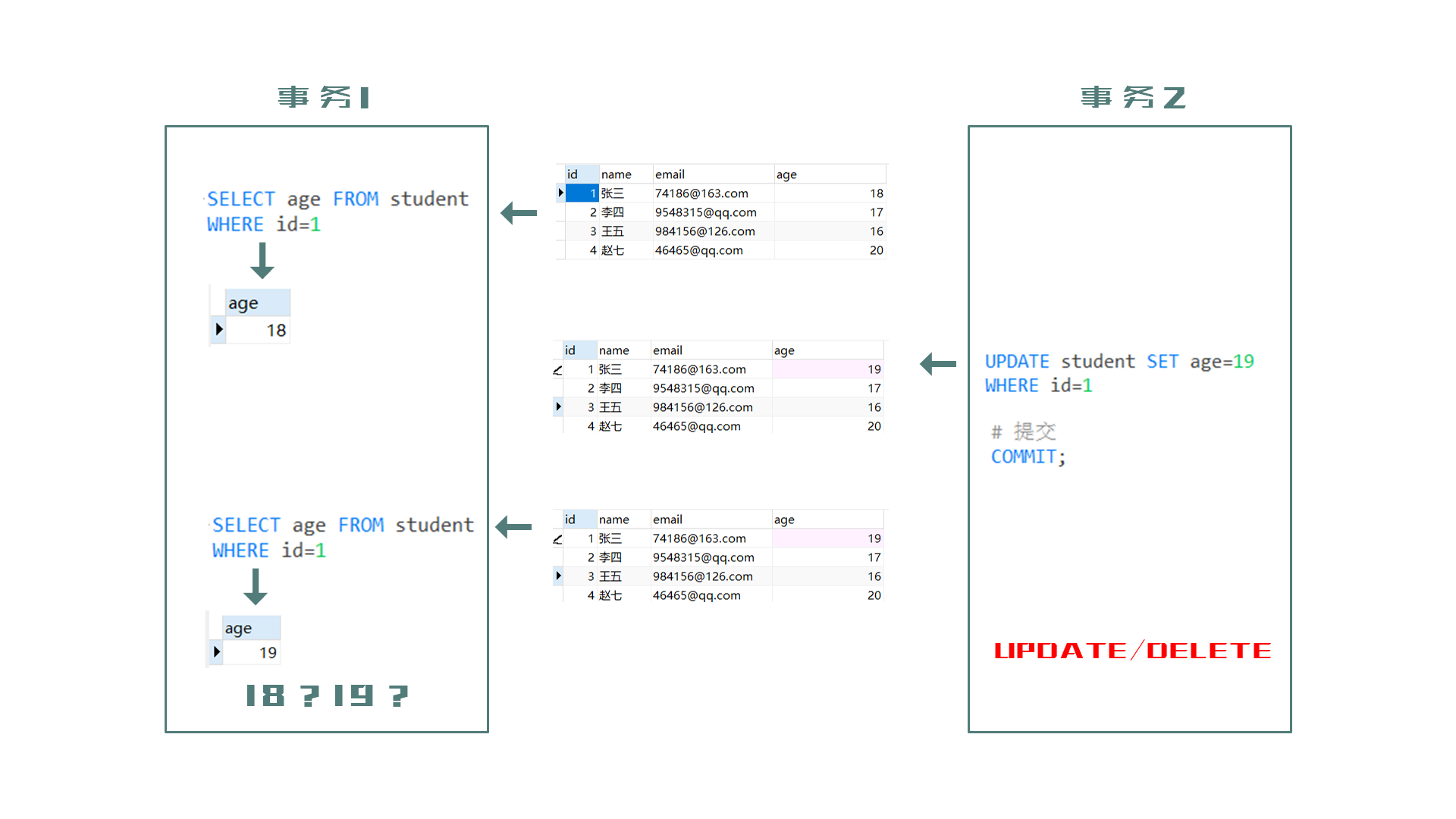
事务1第一次度到的id为1的age为18,之后由于事务2对于数据的修改(已提交),事务1再次读取age,确实19,两次读取的结果不一致。
3.幻读
幻读(Phantom)与不可重复度的区别: 由于 插入数据 而导致两次查询结果不一致叫幻读,由于 删改 数据而导致两次查询结果不一致叫不可重复读。
4.小结
事务并发的三大问题其实都是数据库 读一致性 问题,必须由数据库提供一定的 事务隔离机制 来解决。
由此,提出了 SQL92 ANSI/ISO标准
5.事务的四个隔离级别
读未提交(READ UNCOMMITTED): 可以读取到事务未提交的数据,最低的事务隔离级别。
读已提交(READ COMMITTED): 只能读已提交的数据,解决了脏读。
可重复读(REPEATABLE READ): 一个事务开始读取数据后, 其他事务不能修改数据(update/delete),解决的可重复读、脏读。
串行化(SERIALIZABLE): 事务一个一个地排队执行,不能进行并发操作,可以避免所有并发问题。但是效率低下,很消耗数据库性能。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | √ | √ | √ |
| 读已提交 | √ | √ | |
| 可重复读 | √ | ||
| 串行化 |
事务隔离级别预告,并发度越低。
注意: InnoDB在可重复读级别已经解决了幻读的问题,完全不需要使用到串行化。InnoDB的默认级别是可重复读。
7.如何解决读一致性问题?
即,如何保证事务中前后两次读取数据结果一致?
1.LBCC(Lock Based Concurrent Control) : 在读取数据前,对其加锁,阻止其他事务对数据库进行修改
并发度大大降低,影响数据库性能。
2.MVCC(Multi Version Concurrency Control) : 生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取
通过建立快照(相当于备份),并访问快照的方式。
2.锁
mysql的锁
- 从锁的粒度:行锁、表锁
- 从锁的用法:乐观锁、悲观锁
- 从锁的模式:排它锁、意向锁、共享锁、自增锁
- 从锁的算法:间隙锁、记录所、插入意向锁、临键锁
- 锁的问题:死锁
表锁与行锁的区别:
- 锁定粒度:表锁 > 行锁
- 加锁效率:表锁 > 行锁
- 冲突概率:表锁 > 行锁
- 并发性能:表锁 < 行锁
MyISAM支持表锁
InnoDB支持行锁也支持表锁(默认行锁,冲突概率更低)
锁锁住的是什么?
是索引
那没有声明索引的表为什么还能锁表?
一张表不可能没有索引
- 主键 → 聚集索引
- 其他索引
- 将隐藏字段 _rowid 作为默认索引
InnoDB 锁类型
锁的模式(Lock Mode)
1.行锁
● 共享锁(Shared Locks): 行锁
又称 读锁 ,即多个事务对于同一数据共享一把锁,都能访问到数据,但 只能读不能改
# 加锁,有多个事务可以同时上共享锁
SELECT * FROM `student`
WHERE id=1
LOCK IN SHARE MODE;
# 释放锁(结束事务)
COMMIT;
# 或
ROLLBACK;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
● 排他锁(Exclusive Locks): 行锁
又称 写锁 ,不能与其他锁并存,当一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的锁(共享锁、排他锁),只有该获取了排他锁的事务可以对数据进行读写操作。
# 自动加锁
# 增删改语句默认加排他锁
DELETE/UPDATE/INSERT
# 手动加锁
SELECT * FROM `student`
WHERE id=1
FOR UPDATE;
# 释放锁(结束事务)
COMMIT;
# 或
ROLLBACK;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
意向锁:由数据引擎自己维护的,用户无法手动操作。
-
意向共享锁(Intention Shared Locks,IS):表锁
表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁前必须先获取该表的IS锁 -
意象排它锁(Intention Exclusive Locks,IX):表锁
表示事务准备给数据行加入排他锁,说明事物在一个数据行加排他锁前必须获取到该锁的IX锁
即,先由数据库引擎加上IS锁,才能加上共享锁;先由数据库引擎加上IX锁,才能加上排他锁。
意向锁的作用:提高加锁的效率。
即,通过查看表/行是否有意向锁,就能判断它是否已经上锁。相当于一个 上锁标志位 ,而非一个真正的锁。
2.行锁算法
区间的定义:
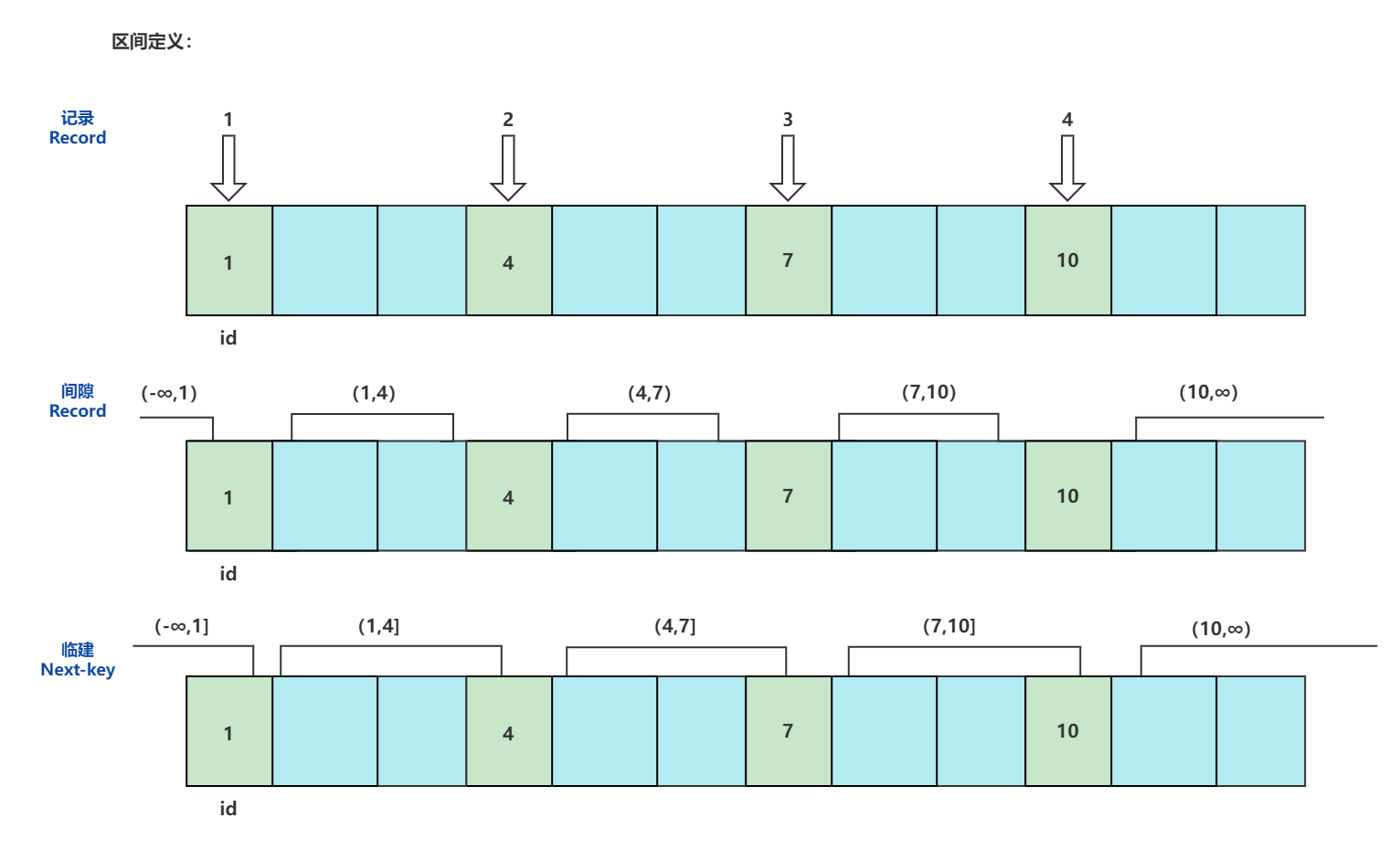
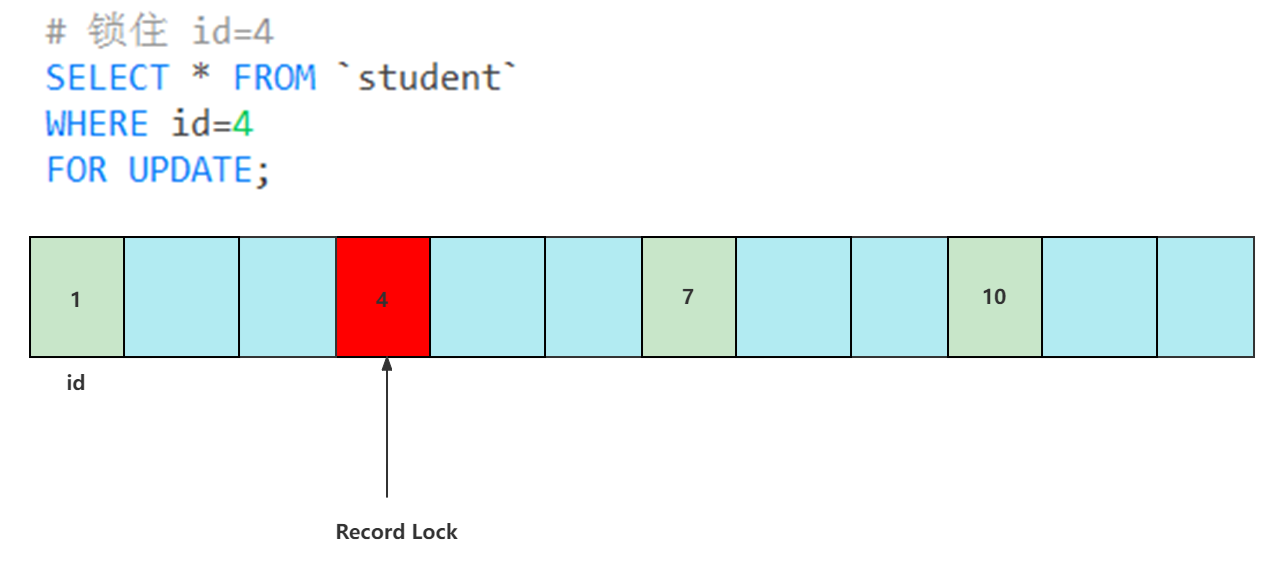
记录锁(Record Locks): 唯一性索引(唯一/主键)等值查询,精准匹配
间隙锁(Gap Locks): 记录锁不存在
Gap Lock之间不冲突
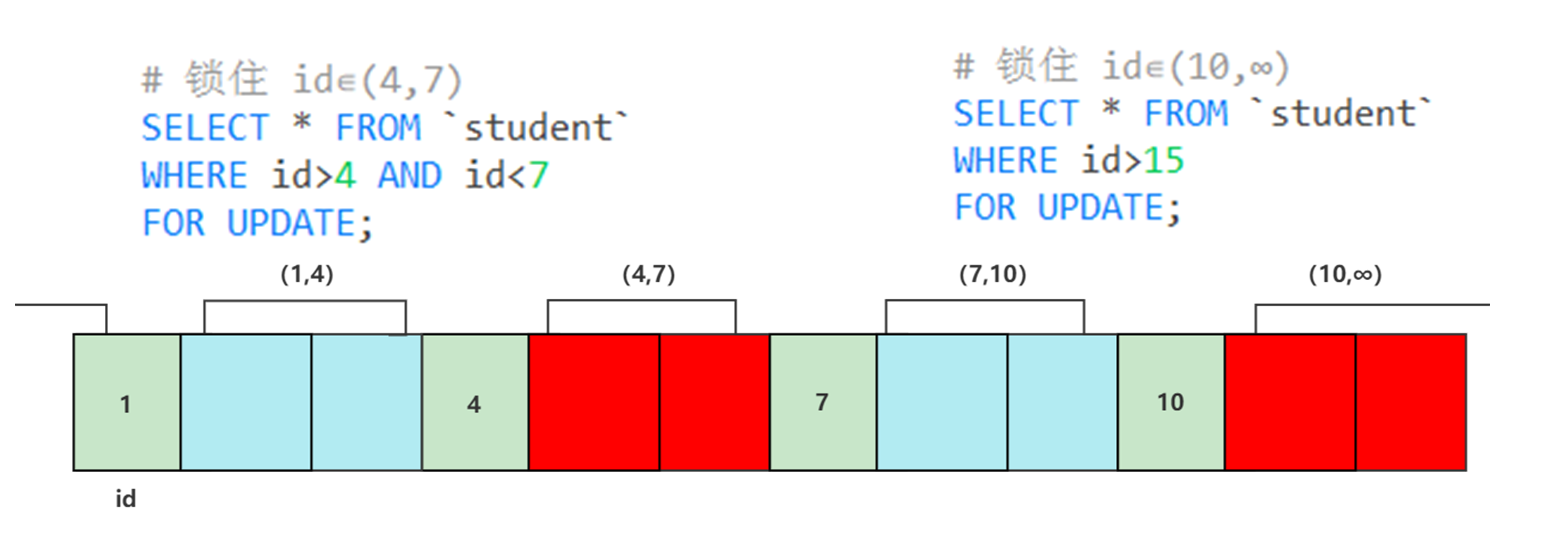
InnoDB中就是通过间隙锁,防止插入的(也就防止了幻读)
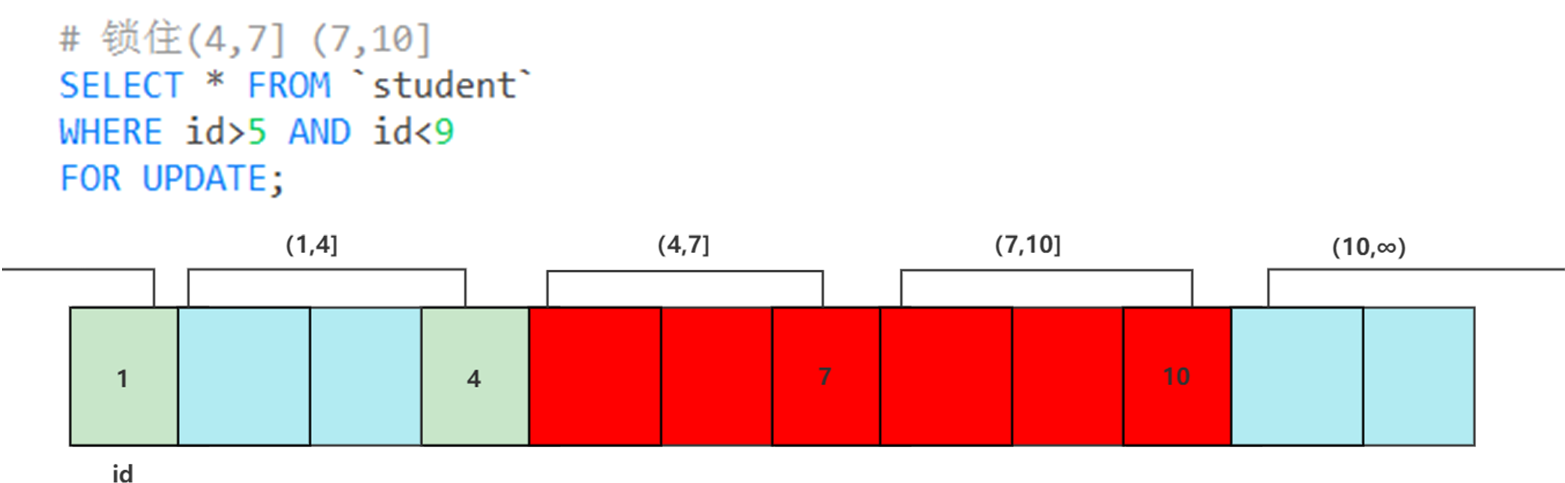
临键锁(Next-key Locks): 范围查询,包含记录和区间
锁住的是左区间的数据到右区间的下一个数据。
记录锁 + 间隙锁