
- 1高中的信息会教c语言吗,高中信息学竞赛C语言教程(第一讲)初识C程序.ppt
- 2深度学习与AIGC:未来的智能生活
- 3FPGA项目(5)--FPGA控制数码管动态显示的原理_为什么fpga开发板的七段数码管到9就灭了
- 4mysql unknown_mysql碰到unknown variable 'xxxx' 的解决方法
- 5Spark RDD操作之Action操作_sparkrdd的action操作’
- 6如何系统自学软件测试,看这篇软件测试学习方法万字总结就够了_软件测试自学
- 7git 安装配置(windows环境)_git安装win+cmd出现gif config
- 8SCP文件传输命令用法_scp -i
- 9超实用AI工具汇总_ai汇总
- 10AI大模型的使用-让AI帮你写单元测试_ai生成单元测试
5、HIVE DML操作、load数据、update、Delete、Merge、where语句、基于分区的查询、HAVING子句、LIMIT子句、Group By语法、Hive 的Join操作等_hive delete join
赞
踩
目录:
4.2.1 Load文件数据到表中
4.2.2查询的数据插入到表中
4.2.3将Hive查询的结果存到本地Linux的文件系统目录中
4.2.4通过SQL语句的方式插入数据
4.2.5 UPDATE
4.2.6 Delete
4.2.7 Merge
4.3.2WHERE子句
4.3.4基于分区的查询
4.3.5 HAVING子句
4.3.6 LIMIT子句
4.3.7 Group By语法
4.3.7.1简单案例
4.3.8 Select 语句和group by子句
4.3.8.1 Multi-Group-By Inserts
4.3.8.2 Map-side Aggregation for Group By
4.3.8.3 Group By约束条件
4.4 Order, Sort, Cluster, and Distribute By
4.4.1 Order By的语法
4.4.2 Sort By的语法
4.4.3 Order By和Sort By之间的异同
4.4.4 Cluster By和Distribute By的语法
4.5 Hive 的Join操作
4.5.1 Hive的join语法
4.5.2MapJoin的限制条件
4.6Union Syntax
4.6.1 FROM子句中的UNION
4.6.2 Unions in DDL and Insert Statements
4.7 SubQueries
4.7.1 在FROM子句中的Subqueries
4.7.2 Subqueries in the WHERE Clause
4.8 Import/Export
4.8.1 Export/Import语法
4.8.2 Replication语法
4.8.3 export,import
- 简单导出和导出
- 在import时重命名表
- 导出分区并导入
- 导出表并且导入到分区表分区
- 指定导入位置
- 导入作为一个外部表
4.2.1 Load文件数据到表中
加载数据到表中
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- 1
案例:
CREATE TABLE IF NOT EXISTS employee(eid int,name String,destination String) partitioned by(salary String) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE; hive> desc employee; OK eid int name string destination string salary string # Partition Information # col_name data_type comment salary string Time taken: 0.607 seconds, Fetched: 9 row(s) hive> 创建/root/test/sample.txt,内容如下: 1201 pal 45000 Technical manager 1202 Manisha 45000 Proof reader 将上面的数据导入到employee表中: hive> LOAD DATA LOCAL INPATH '/root/test/sample.txt' INTO TABLE employee PARTITION(salary = '45000'); Loading data to table demo_db.employee partition (salary=45000) OK Time taken: 1.392 seconds hive>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
上面的具体含义是将数据添加到45000这个分区中。
添加之后,在hdfs中的效果如下:

再添加salary=40000的分区,并指定分区数据的位置:
hive> ALTER TABLE employee ADD PARTITION (salary = '40000') location '/40000/part40000';
OK
Time taken: 0.203 seconds
hive> show partitions employee;
OK
salary=40000
salary=45000
Time taken: 0.206 seconds, Fetched: 2 row(s)
hive>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
将以下数据添加到hdfs中:


将数据添加到salary=40000的分区中:

4.2.2查询的数据插入到表中
标准语法:
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
- 1
- 2
4.2.3将Hive查询的结果存到本地Linux的文件系统目录中
语法:
Standard syntax: INSERT OVERWRITE [LOCAL] DIRECTORY directory1 [ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0) SELECT ... FROM ... Hive extension (multiple inserts): FROM from_statement INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1 [INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ... row_format : DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char] (Note: Only available starting with Hive 0.13) 案例: hive> INSERT OVERWRITE LOCAL DIRECTORY '/employee' > ROW FORMAT DELIMITED > FIELDS TERMINATED BY '\t' > LINES TERMINATED BY '\n' > STORED AS TEXTFILE > select * from employee;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
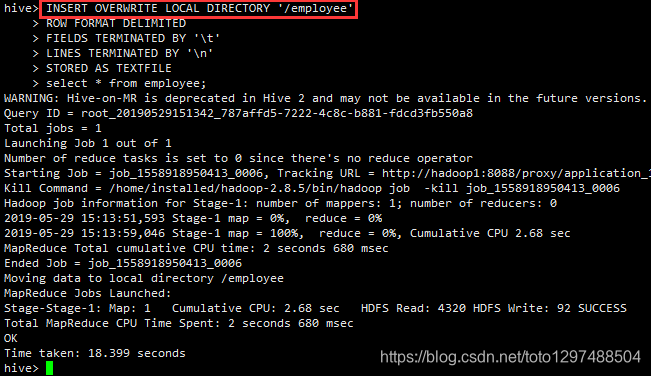
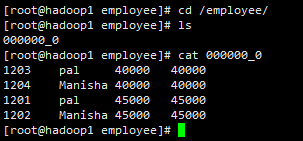
进入本地Linux查看效果:
4.2.4通过SQL语句的方式插入数据
语法:
INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]
- 1
案例:
CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3, 2)) CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC; INSERT INTO TABLE students VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32); CREATE TABLE pageviews (userid VARCHAR(64), link STRING, came_from STRING) PARTITIONED BY (datestamp STRING) CLUSTERED BY (userid) INTO 256 BUCKETS STORED AS ORC; INSERT INTO TABLE pageviews PARTITION (datestamp = '2014-09-23') VALUES ('jsmith', 'mail.com', 'sports.com'), ('jdoe', 'mail.com', null); INSERT INTO TABLE pageviews PARTITION (datestamp) VALUES ('tjohnson', 'sports.com', 'finance.com', '2014-09-23'), ('tlee', 'finance.com', null, '2014-09-21'); INSERT INTO TABLE pageviews VALUES ('tjohnson', 'sports.com', 'finance.com', '2014-09-23'), ('tlee', 'finance.com', null, '2014-09-21');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.2.5 UPDATE
若想让Hive库能够支持UPDATE,需要让它能够支持 Hive Transactions (https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions)
语法是:
UPDATE tablename SET column = value [, column = value ...] [WHERE expression]
- 1
4.2.6 Delete
若想让Hive库能够支持DELETE,需要让它能够支持 Hive Transactions (https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions)
语法是:
DELETE FROM tablename [WHERE expression]
- 1
4.2.7 Merge
语法:
MERGE INTO <target table> AS T USING <source expression/table> AS S
ON <boolean expression1>
WHEN MATCHED [AND <boolean expression2>] THEN UPDATE SET <set clause list>
WHEN MATCHED [AND <boolean expression3>] THEN DELETE
WHEN NOT MATCHED [AND <boolean expression4>] THEN INSERT VALUES<value list>
- 1
- 2
- 3
- 4
- 5
4.3 数据检索—Queries
4.3.1Select语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1、Select语句可以作为union查询和子查询等的一部分。
2、table_reference可以是一个普通的表,视图,一个join构造或者一个子查询。
3、表名和列名是大小写不敏感的。
A:在Hive 0.12及其早期版本中,在表明和列名中只有字母和下划线才被允许。
B:在Hive 0.13及其后期版本中,列名中可以包含任何的Unicode字符。
- 1
- 2
- 3
- 4
- 5
案例:
从t1中获取所有的列和行数
SELECT * FROM t1
- 1
获取当前在使用的数据库:
SELECT current_database()
- 1
4.3.2WHERE子句
案例:
SELECT * FROM sales WHERE amount > 10 AND region = "US"
- 1
4.3.3ALL和DISTINCT子句
ALL和DISTINCT选项指定是否返回重复的行。如果这两个都没有指定,默认是ALL(所有的数据都将会被返回),DISTINCT指定之后,将会移除所有重复行。从Hive 1.1.0之后,Hive开始支持SELECT DISTINCT *查询。
hive> SELECT col1, col2 FROM t1
1 3
1 3
1 4
2 5
hive> SELECT DISTINCT col1, col2 FROM t1
1 3
1 4
2 5
hive> SELECT DISTINCT col1 FROM t1
1
2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
所有的ALL和DISTINCT也可以在UNION子句中使用。
4.3.4基于分区的查询
一般而言,一个SELECT查询将扫描全表(而不是部分数据)。如果一个表是使用PARTITIONED BY创建的,在查询的时候,可以只扫描分区对应的一部分数据。
假设有一个page_views表,这个表是按照date进行分区的,可以通过下面的语句检索出数据行在2008-03-01和2008-03-31之间的数据行。
SELECT page_views.*
FROM page_views
WHERE page_views.date >= '2008-03-01' AND page_views.date <= '2008-03-31'
- 1
- 2
- 3
如果表page_views和dim_users之间进行join操作,在ON子句里面可以指定一些分区。
SELECT page_views.*
FROM page_views JOIN dim_users
ON (page_views.user_id = dim_users.id AND page_views.date >= '2008-03-01' AND page_views.date <= '2008-03-31')
- 1
- 2
- 3
4.3.5 HAVING子句
HAVING子句的这种语法在0.7.0之后开始支持,当然使用子句也可以实现类似的功能。
SELECT col1 FROM t1 GROUP BY col1 HAVING SUM(col2) > 10
- 1
也可以使用子句实现:
SELECT col1 FROM (SELECT col1, SUM(col2) AS col2sum FROM t1 GROUP BY col1) t2 WHERE t2.col2sum > 10;
- 1
4.3.6 LIMIT子句
子句可以被用于约束SELECT子查询的数据行数。
LIMIT接收1或2个数值参数,这两个参数必须都是正整数。第一个参数指定获取的第一行数据的偏移量。第二个参数表示一次性最多返回的数据行数。如果只指定了一个参数,它代表返回最大多少条数据,第一条数据的偏移位置是0。
下面的语句表示返回任意的5条数据。
SELECT * FROM customers LIMIT 5;
- 1
下面的查询返回前5个数据
SELECT * FROM customers ORDER BY create_date LIMIT 5;
- 1
下面的查询返回第3条到第7条的数据
SELECT * FROM customers ORDER BY create_date LIMIT 2,5;
- 1
4.3.7 Group By语法
语法:
Group By子句:GROUP BY groupByExpression (, groupByExpression)*
groupByExpression: expression
Group BY的完整语法:
SELECT expression (, expression)* FROM src groupByClause?
- 1
- 2
- 3
- 4
- 5
- 6
在groupByExpression中,列被指定位确切的名称,不是根据位置数值。当配置一下参数的时候,可以通过指定位置的方式获取数据。
1、Hive 0.11.0到2.1.x,设置 hive.groupby.orderby.position.alias 为true (默认是false).
2、对于Hive 2.2.0及其以后版本,设置 hive.groupby.position.alias 为true (默认是false).
4.3.7.1简单案例
获取表的数据行数
SELECT COUNT(*) FROM table2;
- 1
注意:对于不支持COUNT()的Hive版本,可以使用COUNT(1)代替COUNT()
为了去重的方式获取按照gender分组的用户的数据行数,可以使用以下的命令:
INSERT OVERWRITE TABLE pv_gender_sum
SELECT pv_users.gender, count (DISTINCT pv_users.userid)
FROM pv_users
GROUP BY pv_users.gender;
- 1
- 2
- 3
- 4
可以同时使用多个聚合函数。聚合函数中的列名要相同。
INSERT OVERWRITE TABLE pv_gender_agg
SELECT pv_users.gender, count(DISTINCT pv_users.userid), count(*), sum(DISTINCT pv_users.userid)
FROM pv_users
GROUP BY pv_users.gender;
- 1
- 2
- 3
- 4
注意,上面的COUNT()在有些Hive版本中可能不支持,需要使用COUNT(1)代替COUNT()。
下面的语法中,不支持一个语句中使用多个DISTINCT语句(这个语句中的列不相同),也就是说下面的SQL是错的。
INSERT OVERWRITE TABLE pv_gender_agg
SELECT pv_users.gender, count(DISTINCT pv_users.userid), count(DISTINCT pv_users.ip)
FROM pv_users
GROUP BY pv_users.gender;
- 1
- 2
- 3
- 4
4.3.8 Select 语句和group by子句
当使用group by子句的时候,select语句中的列只能是group by子句中包含的列,当然,你也可以在select语句中含有多个聚合函数(例如:count)。
让我们举一个简单的例子:
CREATE TABLE t1(a INTEGER, b INTGER);
- 1
一个针对上面表的group查询可以类似如下:
SELECT
a,
sum(b)
FROM
t1
GROUP BY
a;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面的查询起作用是因为select子句中包含一个(group by key),并且有一个聚合函数(sum(b))
然而下面的查询就不起作用。
SELECT
a,
b
FROM
t1
GROUP BY
a;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这是因为在这个查询子句中有一个额外的列(b),但是这个b不在group by子句中。并且它也不是一个聚合函数。这是因为,表t1如下:
a b
------
100 1
100 2
100 3
- 1
- 2
- 3
- 4
- 5
4.3.8.1 Multi-Group-By Inserts
将查询到的数据插入到pv_gender_sum表中
INSERT OVERWRITE TABLE pv_gender_sum
SELECT pv_users.gender, count(DISTINCT pv_users.userid)
GROUP BY pv_users.gender
- 1
- 2
- 3
将查询到的数据写入到目录文件中
INSERT OVERWRITE DIRECTORY '/user/facebook/tmp/pv_age_sum'
SELECT pv_users.age, count(DISTINCT pv_users.userid)
GROUP BY pv_users.age;
- 1
- 2
- 3
4.3.8.2 Map-side Aggregation for Group By
hive.map.aggr 控制我们怎样进行聚合操作,它的默认值是false,如果将它设置成true,Hive将直接在map task中做第一级的聚合。
通常情况下,这种操作提供了更好的效率,但是如果想运行成功,需要更多的内存。
set hive.map.aggr=true;
SELECT COUNT(*) FROM table2;
- 1
- 2
要注意的是,有些hive版本不支持count(),需要使用count(1)代替count().
4.3.8.3 Group By约束条件
(1)、不能Group By非标量基元类型的列,如不能Group By text,image或bit类型的列。
(2)、带有Group by子句的时候,Select指定的每一列都应该出现在Group By子句中,除非对这一列使用了聚合函数。聚合函数如:AVG、COUNT、MAX/MIN、SUM
(3)、不能Group By在表中不存在的列。
(4)、进行分组前可以使用Where子句消除不满足条件的行。
(5)、使用Group By子句返回的组没有特定的顺序,可以使用Order By子句指定次序。
4.4 Order, Sort, Cluster, and Distribute By
4.4.1 Order By的语法
在Hive QL中的ORDER BY语法有点类似SQL语言中的ORDER BY语法。
SELECT
expression (‘,’ expression)*
FROM
src
ORDER BY
colName (ASC | DESC) (NULLS FIRST | NULLS LAST);
- 1
- 2
- 3
- 4
- 5
- 6
在”order by”子句中有一些限制,在严格模式下(即: hive.mapred.mode=strict)模式下,order by子句必须在”limit”子句的后面,如果你设置了hive.mapred.mode为nonstrict,原因是为了强制所有结果的总顺序,必须有一个reduce去排序最终的结果。如果输出结果太大,这单个reduce可能需要很长时间才能结束。
注意的是默认的排序是升序ascending(ASC).
在Hive 2.1.0及其以后版本中,支持了为”order by”子句中的每列指定空值排序。对于ASC排序默认的排序是NULLS FIRST,然而,对于DESC排序默认的空值排序是NULLS LAST.
在Hive 3.0.0及更高版本中,没有limit的order by子查询和视图将会被optimizer删除。想要禁用它,得设置hive.remove.orderby.in.subquery 为false。
4.4.2 Sort By的语法
SORT BY的语法类似SQL语言中的ORDER BY语法
SELECT
Expression (‘,’ expression)*
FROM
src
SORT BY
colName (ASC | DESC);
- 1
- 2
- 3
- 4
- 5
- 6
4.4.3 Order By和Sort By之间的异同
Hive支持SORT BY操作,在每个reducer中将sort数据。”order by”和”sort by”之间的不同之处是前者支持输出的结果中所有的都是有序的,而后者只能支持在一个reducer中是有序的。如果有多个reduce,”sort by”可能返回的最终结果是部分有序的。
基本上,在每个reducer中的数据都将按照用户指定的排序类型排序。例如下面的案例:
SELECT key, value FROM src SORT BY key ASC, value DESC
- 1
这个查询有2个reducers,每个的输出是:
0 5
0 3
3 6
9 1
- 1
- 2
- 3
- 4
0 4
0 3
1 1
2 5
- 1
- 2
- 3
- 4
4.4.4 Cluster By和Distribute By的语法
Cluster By和Distribute By主要用在Transform/Map-Reduce脚本中。如果需要分区和排序最终查询的结果,有时候是很有用的。
Cluster By是Distribute By和Sort By的一个快捷的方式。
Hive在Distribute By中使用列的方式将在众多的reducers中数据行均匀分布。所有的拥有相同Distribute By猎德行都将被分配到相同的reducer中。然后,Distribute By不保证在distributed key上的clustering和sorting属性。
例如:下面的5行数据Distributing By x到2个reducer上:
x1
x2
x4
x3
x1
- 1
- 2
- 3
- 4
- 5
reducer 1 获取到:
x1
x2
x1
- 1
- 2
- 3
Reducer 2 获取到:
x4
x3
- 1
- 2
注意:具有相同键x1的行都被保证分配到相同的reducer中(本例中为reduce 1),他们不能保证clustered在相邻位置。
与此相反,如果我们使用Cluster By x,这两个reducers后面将进一步对x上的行进行排序。
Reducer 1获取到:
x1
x1
x2
- 1
- 2
- 3
Reducer 2获取到:
x3
x4
- 1
- 2
用户可以指定Distribute By和Sort By,而不是指定Cluster By,因此分区列和sort的列可以不相同。通常情况下分区列是sort列的前缀,但这不是必需的。
SELECT col1, col2 FROM t1 CLUSTER BY col1
- 1
SELECT col1, col2 FROM t1 DISTRIBUTE BY col1
- 1
SELECT col1, col2 FROM t1 DISTRIBUTE BY col1 SORT BY col1 ASC, col2 DESC
FROM (
FROM pv_users
MAP ( pv_users.userid, pv_users.date )
USING 'map_script'
AS c1, c2, c3
DISTRIBUTE BY c2
SORT BY c2, c1) map_output
INSERT OVERWRITE TABLE pv_users_reduced
REDUCE ( map_output.c1, map_output.c2, map_output.c3 )
USING 'reduce_script'
AS date, count;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.5 Hive 的Join操作
4.5.1 Hive的join语法
Hive支持以下的join tables的语法
join_table: table_reference [INNER] JOIN table_factor [join_condition] | table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition | table_reference LEFT SEMI JOIN table_reference join_condition | table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10) table_reference: table_factor | join_table table_factor: tbl_name [alias] | table_subquery alias | ( table_references ) join_condition: ON expression
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
案例:
允许复合join操作
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department);
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
- 1
- 2
- 3
- 4
- 5
上面的都是有效的join语句
在一个query语句中可以join多于2个表
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- 1
上面的语句也是一个有效的语句
Hive 将多个表的join操作转化到一个map/reduce作业,条件是每个表的join子句中使用相同的列。例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
- 1
上面的语句被转换到一个map/reduce作业中,因为只有b表的key1在join操作中参与了。
另一方面,使用下面的语句时,将有多个map/reduce.
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- 1
上面的操作被转入到两个map/reduce作业,因为b表中的key1列在第一个join条件下使用。b表的key2列在第二个join下执行。第一个map/reduce作业执行a和b的join操作,产生的结果和c表在第二个map/reduce中参与执行。
在join中的每个every/reduce stage,序列中的最后一个表通过reduce进行流处理,而其他表则在其中进行缓存。因此,组织表的时候,使最大的表放在最后面,可以帮助减少reduce中缓存join key的特定值所需的内存。例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
所有的这三张表join的时候在一个map/reduce作业中,a表和b表的特定值被缓存在reduce的内存中。然后,对于从c检索到的每一行,join操作和缓存的行数据进行计算。
类似地:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- 1
在计算join操作的时候有两个map/reduce,第一个步骤是join a和b,缓冲a的值,同时将b的值流到reduce中,第二个map/reduce缓存第一个map/reduce的结果,同时c表的流到reduce中进行处理。
在join的每个map/reduce阶段,可以通过指示要流化的表(通过/*+ STREAMTABLE(a) */),例如:
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
- 1
所有三个表的join操作都在一个map/reduce作业中,表b和表c的键的特定值的值被缓存在reduce器的内存中,然后,对于从a检索到的每一行,join操作使用缓冲行进行计算。如果/*+ STREAMTABLE(表名) */ 遗漏了,在join操作的时候,Hive流化最右边的表。
LEFT,RIGHT和FULL OUTER join存在的目的是为了在没有匹配到的ON子句中提供更多的控制,例如:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key);
- 1
将为a表中的每一行返回一条记录,这各输出的行是b.key = a.key 的a.val,b.val,当没有对应的b.key的值的时候这个输出行将输出a.val,NULL,b的行没有对应a.key时,键值将会被删除。“FROM a LEFT OUTER JOIN b”语法必须写在一行上,以便理解它是如何工作的——在这个查询中,a位于b的左侧,因此保留了来自a的所有行。RIGHT OUTER JOIN将保留b中的所有行,而FULL OUTER JOIN将保留a中的所有行和b中的所有行,OUTER JOIN语义应该符合标准SQL规范。
JOIN语句出现在WHERE子句的前面,如果你想限制一个join的输出,在WHERE子句中需要添加条件,否则就在JOIN子句中。这个问题的一大困惑是分区表:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
- 1
- 2
上面的sql语句在b上join a,产生一个a.val和b.val的列表。然而,在WHERE子句中,也可以也可以引用a和b表中在join输出中的其它列,并且过滤它们。然而,当连接中的行找到a表中的key,而在b表没有找到相应的键时,b的所有列都将为空,包括ds列。这也就是说,你将过滤出所有的行,这些行在join操作输出中没有有效b.key。因此在你的LEFT OUTER中要有更好的条件控制。换句话说,如果你在WHERE子句中引用b表中的任何列,在join中的LEFT OUTER部分是不相关的。相反,在使用OUTER JOINing时,使用下面的语法:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b
ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07')
- 1
- 2
这个join的过滤是预先过滤的,你不会有为这些拥有有效a.key的行有获取后置过滤(post-filtering)的麻烦,同样的逻辑适用于LEFT 或 RIGHT join操作。
JOIN语句是不可以交换的,join是左关联的,不管它们是LEFT还是RIGHT join语句。
SELECT a.val1, a.val2, b.val, c.val
FROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key)
- 1
- 2
- 3
- 4
第一个a在b上的join操作,在另外一个表(最终reduce到的表)中丢弃a或b中没有对应键的所有内容(也就是说只有a.key = b.key的所有数据)。这个reduce过的表接着和c表进行join操作。如果在a和c中都存在一个键,但是b中不存在,则会得不到不直观的结果:所有的行(包括a.val1,a.val2,和a.key)在”a JOIN b”的过程中删除了,因为它不在b中。在这个结果中没有a.key在里面,因此,当它和c执行LEFT OUTER JOIN,c.val不存在,因为没有c.key匹配a.key(因为它已经被删除了),类似的,如果这是一个RIGHT OUTER JOIN(而不是LEFT),我们将得到一个更奇怪的现象:NULL,NULL,NULL, c.val,因为当我们指定a.key = c.key进行join的时候,我们drop了所有的不匹配第一个JOIN的数据行。
为了得到更直观的效果,我们应该将SQL语句改成 FROM c LEFT OUTER JOIN a ON (c.key = a.key) LEFT OUTER JOIN b ON (c.key = b.key).
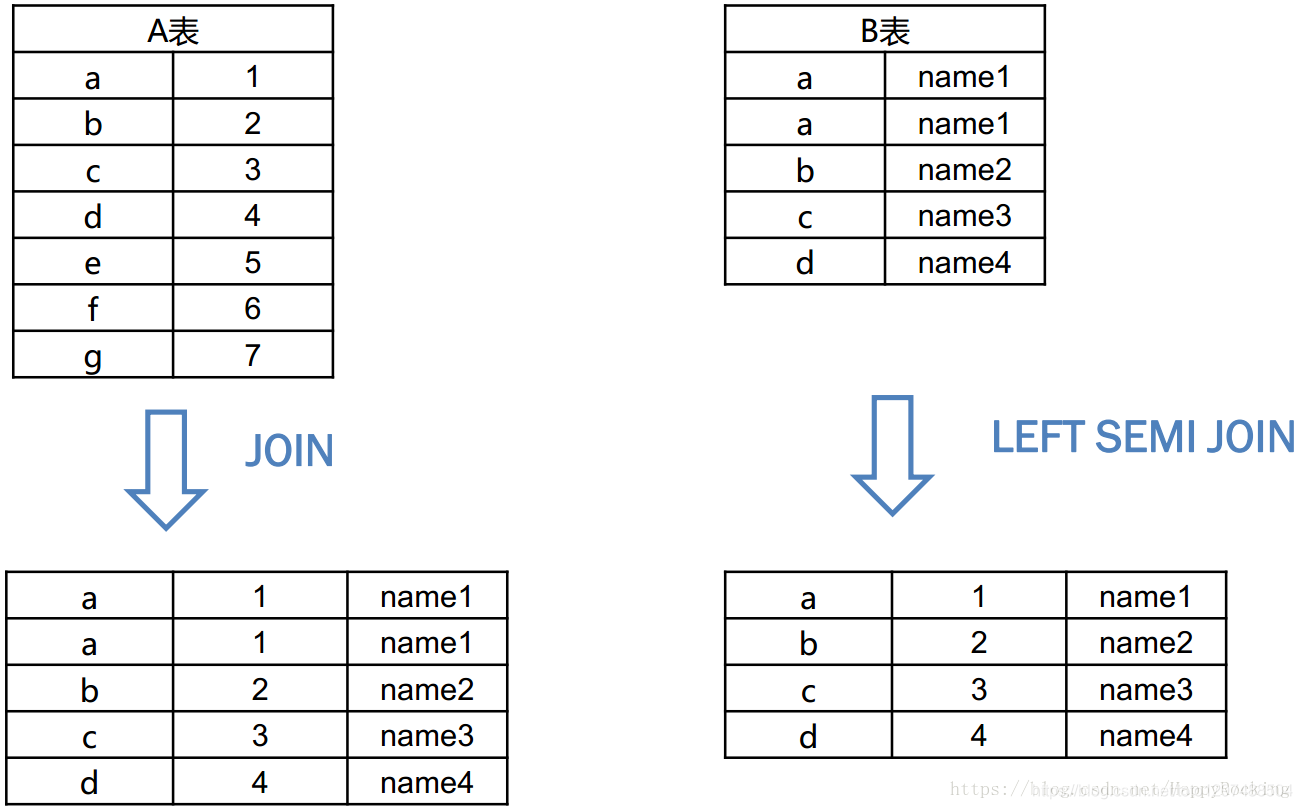
LEFT SEMI JOIN(左半连接)是IN/EXISTS子查询的一种更高效的实现。在Hive 0.13版本IN/NOT IN/EXISTS/NOT EXISTS操作开始支持了,通过子查询的方式,这样大多数子查询就不需要手动执行了。使用左半连接的限制是,右手边的表只能在JOIN条件(on–子句)中引用,而不能再WHERE或select子句中引用。
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以被写成:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b ON (a.key = b.key)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
特点:
1、left semi join 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。
2、left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表。
3、因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条,也会导致 left semi join 的性能更高。
比如以下A表和B表进行join或left semi join,然后select出所有字段,结果区别如下:
MAPJOIN操作
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率。
官方说明:
1、如果join操作的所有表中,有一个表很小,这个作为一个map任务来执行,查询语句如下:
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a JOIN b ON a.key = b.key
- 1
- 2
上面的语句不需要任何一个reducer.对于A的每一个mapper,B都被完全读取。这里面的限制是a FULL/RIGHT OUTER JOIN b不可以被执行。
2、如果join的表被分桶过了,并且分桶的列是join的列,一个表中的桶数是另一个表中的桶数的倍数,这些桶之间可以互相连接。如果表A有4个桶,表B有4个桶,使用下面的join操作:
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a JOIN b ON a.key = b.key
- 1
- 2
上面的语句可以只在mapper中执行,取代了为A的每个mapper获取所有的B的,只有需要的桶数据才被获取到。对于以上的查询,为A处理bucket 1的映射程序将只获取bucket 1 (B)。这不是默认的行为,需要配置一下参数:
set hive.optimize.bucketmapjoin = true
- 1
4、如果join中的表中的join的列被sorted和分桶了。并且他们有相同的桶数,sort-merge可以被执行,对应的桶在mapper是彼此join,如果A和B表都有4个桶,执行以下HiveQL:
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM A a JOIN B b ON a.key = b.key
- 1
- 2
可以在一个mapper中执行,用于A的桶的映射器将遍历对应于B的桶。这个不是默认的行为,下面的参数需要设置:
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
- 1
- 2
- 3
4.5.2MapJoin的限制条件
如果被join的所有表中有一个表很小,join操作执行的时候可以只使用一个map。查询语句是:
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a JOIN b ON a.key = b.key
- 1
- 2
上面的查询语句不需要reducer。
下面的情况不支持
Union后面跟着MapJoin
MapJoin后面跟着Lateral View
MapJoin后面跟着Reduce Sink(Group By/Join/Sort By/Cluster By/Distribute By)
MapJoin后面跟着Union
MapJoin后面跟着Join
MapJoin后面跟着MapJoin
配置变量hive.auto.convert.join(如果设置为true)在运行时自动将连接转换为mapjoin(如果可能的话),并且应该使用它而不是/+ mapjoin(表名)/。/+ mapjoin(表名)/应该只用于以下查询。
1.如果所有输入都进行了分桶(bucketed)或排序(sorted),则join应转换为a bucketized map-side join or bucketized sort-merge join。
考虑不同键上多个mapjoin的可能性:
select /*+MAPJOIN(smallTableTwo)*/ idOne, idTwo, value FROM
( select /*+MAPJOIN(smallTableOne)*/ idOne, idTwo, value FROM
bigTable JOIN smallTableOne on (bigTable.idOne = smallTableOne.idOne)
) firstjoin
JOIN
smallTableTwo ON (firstjoin.idTwo = smallTableTwo.idTwo)
- 1
- 2
- 3
- 4
- 5
- 6
不支持上述查询。如果没有/+MAPJOIN(表名)/,上面的查询将作为两个只包含map-only 作业执行。如果用户知道这个输入足够小,并且可以装入内存,则可以使用以下可配置参数确保查询在单个map-reduce作业中执行。
hive.auto.convert.join.noconditionaltask - Whether Hive enable the optimization about converting common join into mapjoin based on the input file size. If this paramater is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the specified size, the join is directly converted to a mapjoin (there is no conditional task).
hive.auto.convert.join.noconditionaltask.size - If hive.auto.convert.join.noconditionaltask is off, this parameter does not take affect. However, if it is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than this size, the join is directly converted to a mapjoin(there is no conditional task). The default is 10MB.
4.6Union Syntax
语法是:
select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement ...
- 1
UNION用于联合多个select语句的结果到一个结果集里面。
你可以在一个查询语句中混合上UNION ALL和UNION DISTINCT
您可以在同一个查询中混合UNION ALL和UNION DISTINCT。混合UNION类型的处理方式是,一个不同的UNION覆盖其左侧的任何所有UNION。可以通过使用union DISTINCT显式地生成一个不同的union,也可以使用union DISTINCT隐式地生成一个不同的union,而不使用后面带有DISTINCT或ALL关键字的union。
每个select_statement返回的列的数目和名称必须相同。否则,将抛出schema错误。
4.6.1 FROM子句中的UNION
如果有一些要对UNION的结果额外的处理需求,UNION的整个语句可以嵌入在FROM子句中。如下:
SELECT *
FROM (
select_statement
UNION ALL
select_statement
) unionResult
- 1
- 2
- 3
- 4
- 5
- 6
案例:
SELECT u.id, actions.date
FROM (
SELECT av.uid AS uid
FROM action_video av
WHERE av.date = '2008-06-03'
UNION ALL
SELECT ac.uid AS uid
FROM action_comment ac
WHERE ac.date = '2008-06-03'
) actions JOIN users u ON (u.id = actions.uid)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.6.2 Unions in DDL and Insert Statements
案例:
SELECT key FROM (SELECT key FROM src ORDER BY key LIMIT 10)subq1
UNION
SELECT key FROM (SELECT key FROM src1 ORDER BY key LIMIT 10)subq2
- 1
- 2
- 3
案例:
SELECT key FROM src
UNION
SELECT key FROM src1
ORDER BY key LIMIT 10
- 1
- 2
- 3
- 4
将UNION的结果插入到表中
INSERT OVERWRITE TABLE target_table
SELECT name, id, category FROM source_table_1
UNION ALL
SELECT name, id, "Category159" FROM source_table_2
- 1
- 2
- 3
- 4
4.7 SubQueries
4.7.1 在FROM子句中的Subqueries
语法:
SELECT ... FROM (subquery) name ...
SELECT ... FROM (subquery) AS name ... (Note: Only valid starting with Hive 0.13.0)
- 1
- 2
例如:
SELECT col
FROM (
SELECT a+b AS col
FROM t1
) t2
- 1
- 2
- 3
- 4
- 5
带有UNION ALL的子查询
SELECT t3.col
FROM (
SELECT a+b AS col
FROM t1
UNION ALL
SELECT c+d AS col
FROM t2
) t3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.7.2 Subqueries in the WHERE Clause
包含IN和NOT IN的情况:
SELECT *
FROM A
WHERE A.a IN (SELECT foo FROM B);
- 1
- 2
- 3
包含EXISTS和NOT EXISTS
SELECT A
FROM T1
WHERE EXISTS (SELECT B FROM T2 WHERE T1.X = T2.Y)
- 1
- 2
- 3
4.8 Import/Export
使用EXPORT命令可以导出一个表或一个分区的数据,并将数据导出到指定的位置。这个输出路径可以移动到不同的Hadoop或hive实例中。通过IMPORT命令可以将数据导入到hive中。
导出分区数据的时候,由于原始数据可能位于不同的HDFS位置,因此也是支持导出到分区子集的功能。
导出的元数据存储在目标目录中,数据文件存储在子目录中。
IMPORT命令在table或partition不存在的时候,它将创建它们。
4.8.1 Export/Import语法
导出语法:
EXPORT TABLE tablename [PARTITION (part_column="value"[, ...])]
TO 'export_target_path' [ FOR replication('eventid') ]
- 1
- 2
导入语法:
IMPORT [[EXTERNAL] TABLE new_or_original_tablename [PARTITION (part_column="value"[, ...])]]
FROM 'source_path'
[LOCATION 'import_target_path']
- 1
- 2
- 3
4.8.2 Replication语法
Export/import命令当在复制环境中使用时略有不同,并且确定使用该工具在两个数据仓库之间使用复制。在大多数情况下,用户不需要使用这个附加功能,除非手动引导仓库之间的复制,这样它可以作为一个增量复制工具。
他们使用一个特殊的表属性“repl.last.id”在一个表或分区对象中,确保export/import工具每次复制的数据时最近更新的数据。在导出完成后,会对export的dump文件使用一个id打一个复制标签,表示在源仓库集成商单调递增的。此外,为复制导出打印的标记不会导致错误如果试图导出一个对象但是标记列当前不存在。
在import方面,没有语法变化,但是import有一个一般性的标签对于复制的dump文件,他讲检查要复制的对象是否存在,如果对象已经存在,它检查对象的repl.last.id属性,确定是否导入当前对象的最新数据对于目标仓库,如果更新是最新的,那么它将复制最新的信息,如果更新已经是很旧的了对于已经存在的对象,那么更新将被忽略,并且不会产生错误。
对于那些使用export进行首次手动引导用例,用户推荐使用“引导”标签,
4.8.3示例
1.简单导出和导出
export table department to 'hdfs_exports_location/department';
import from 'hdfs_exports_location/department';
- 1
- 2
- 3
具体导出案例:
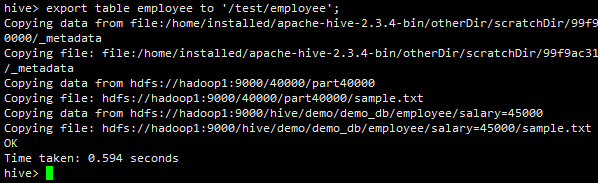

页面中查看:
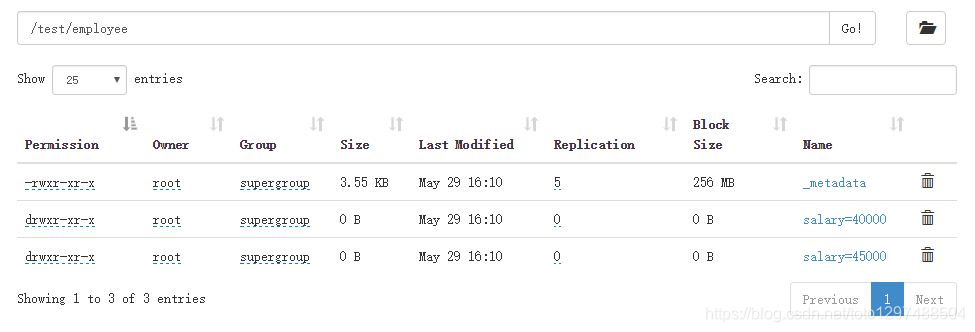
具体导入案例:

2.在import时重命名表
export table department to 'hdfs_exports_location/department';
import table imported_dept from 'hdfs_exports_location/department';
- 1
- 2
- 3
3.导出分区并导入
export table employee partition (emp_country="in", emp_state="ka") to 'hdfs_exports_location/employee';
import from 'hdfs_exports_location/employee';
- 1
- 2
- 3
- 导出表并且导入到分区表分区
export table employee to 'hdfs_exports_location/employee';
import table employee partition (emp_country="us", emp_state="tn") from 'hdfs_exports_location/employee';
- 1
- 2
- 3
5.指定导入位置
export table department to 'hdfs_exports_location/department';
import table department from 'hdfs_exports_location/department'
location 'import_target_location/department';
- 1
- 2
- 3
- 4
- 导入作为一个外部表
export table department to 'hdfs_exports_location/department';
import external table department from 'hdfs_exports_location/department';
- 1
- 2
- 3
打个赏呗,您的支持是我坚持写好博文的动力。


