
- 1Zookeeper 安装教程和使用指南_zk 安装完后如何使用
- 2k8s 安装_树莓派k8s集群安装kafka集群及监控
- 3《如何把桌面变成苹果电脑的桌面,如何安装MyDockfinder》
- 4An unexpected error was encountered while executing a WSL command. Common causes include access righ_an unexpected error occurred while executing a wsl
- 5vivado报位置约束指令的critical warning_common 17-55
- 6神经网络习题
- 7下一代传感器军备竞赛打响,欧菲光备战全栈式智能驾驶解决方案
- 8VUE官方文档学习---组件基础_vue 组件 官方
- 9【刷题笔记】动态规划--字符串最少修改次数_字符串次数变更
- 10redis数据类型
我们离GPT-4V还有多远?_intern vl1.5
赞
踩
来自中国四所大学研究所及上海AI研究院的报告介绍了InternVL 1.5,这是一个开源的多模态大型语言模型(MLLM),旨在缩小开源模型与专有商业模型在多模态理解方面的性能差距。研究团队引入了三项简单的改进:(1)强大的视觉编码器:他们探索了一种持续学习策略,用于大规模视觉基础模型InternViT-6B,提升了它的视觉理解能力,并使其可以在不同的大型语言模型中转移和重复使用。(2)动态高分辨率:根据输入图像的长宽比和分辨率,他们将图像分割成1到40个448x448像素的图块,支持高达4K分辨率的输入。(3)高质量双语数据集:研究团队精心收集了一个高质量的双语数据集,涵盖常见场景、文档图像,并用英文和中文的问答对进行了注释,显著提升了OCR和中文相关任务的性能。他们通过一系列基准测试和比较研究来评估InternVL 1.5。与开源和专有模型相比,InternVL 1.5表现出竞争力,在18个基准测试中的8个达到了最先进的结果。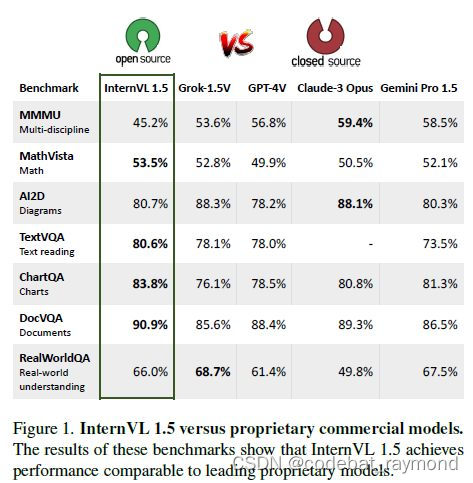
这些设计赋予了该模型几个优势:(1)灵活的分辨率:类似于GPT-4V中的"低"或"高"模式,InternVL 1.5允许用户为图像选择最佳分辨率,例如对场景主体描述使用低分辨率,对文档理解使用高分辨率(最高4K),有效平衡计算效率和细节保留。(2)双语精通:InternVL 1.5展现出强大的双语能力,精通处理英文和中文的多模态感知和理解任务。值得注意的是,在与中文相关的任务中,该模型通常优于领先的商业模型GPT-4V。(3)强大的视觉表示:通过实施持续学习策略,研究团队提高了InternViT-6B的视觉表示能力,使其能够灵活适应不同的输入分辨率和各种视觉领域。得益于InternViT-6B的大量参数,该模型实现了与超过200亿参数的LLMs相媲美的视觉表示水平。视觉和语言处理之间的这种协同作用赋予了该系统强大的多模态能力。
研究团队在18个具有代表性的多模态基准测试上评估了InternVL 1.5,这些基准测试分为四个特定类别:OCR相关、通用多模态、数学和多轮对话基准测试。与开源和专有模型相比,InternVL 1.5表现出竞争力,在18个基准测试中的8个达到了最先进的结果。值得注意的是,它甚至在四个特定基准测试中超过了领先的专有模型,如Grok-1.5V、GPT-4V、Claude-3 Opus和Gemini Pro 1.5,特别是在OCR相关的数据集如TextVQA、ChartQA和DocVQA上。这项评估表明,InternVL 1.5有效缩小了开源模型与领先商业模型之间的差距。研究团队希望他们的方法和开源模型权重能够为多模态社区的发展做出贡献。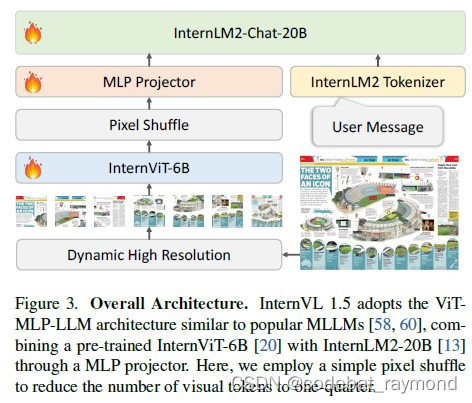
在消融研究中,研究团队调查了LLMs和VFMs之间的相互作用。比较涉及两个开源MLLMs,LLaVA-NeXT和InternVL 1.2,每个模型都配备了340亿参数的LLMs。值得注意的是,尽管两个模型使用相同规模的LLMs,但InternVL 1.2集成了一个显著更大的VFM,具有60亿参数,而LLaVA-NeXT只有3亿参数。尽管这种比较并不完全公平或等效,但研究结果仍揭示了值得注意的见解。例如,在排除五个OCR相关数据集、ConvBench和RealWorldQA后,InternVL 1.2在其余11个数据集中的9个上优于LLaVA-NeXT。这种性能差异支持了研究团队的假设,即对于大规模LLM(如34B),更大的VFM(如6B)可以有效提高模型处理复杂多模态任务的能力,从而提高整体性能。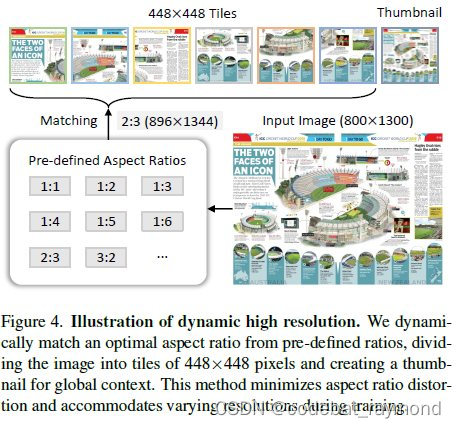
此外,研究团队还调查了动态分辨率在各种多模态基准测试中的有效性。他们发现并非所有任务都需要高分辨率。总的来说,InternVL 1.5表现出对动态分辨率的强大鲁棒性。它可以根据每项任务的具体要求调整分辨率,在高分辨率有益的地方确保最佳性能,在高分辨率无益的地方节约资源。
在定性结果方面,研究团队在各种场景下对InternVL 1.5模型与GPT-4V进行了比较,包括通用QA、OCR相关QA、科学理解、中国传统文化、物体定位和多图像对话。他们旨在从实际用户体验的角度展示该模型在现实应用中的实用性和通用性。结果表明,InternVL 1.5在各个领域都展现出了与GPT-4V相当的能力。值得注意的是,InternVL 1.5在中国传统文化方面展现出对这种文化更深入的理解,从其回应中对文化元素的更详细描述可以看出。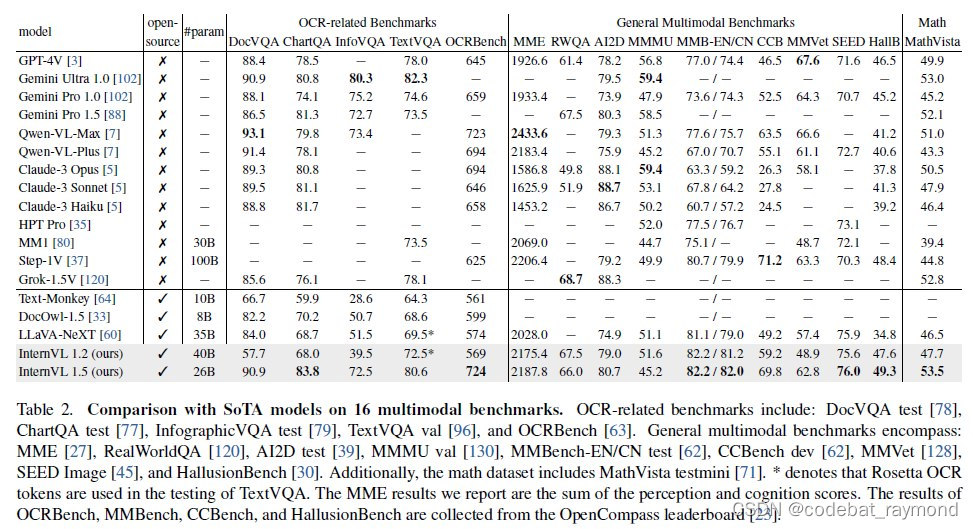
本研究介绍了InternVL 1.5,这是一个开源的多模态大型语言模型(MLLM),旨在缩小开源模型与专有商业模型在多模态理解方面的性能差距。通过整合具有持续学习能力的强大视觉编码器,采用动态高分辨率策略,并利用高质量的双语数据集,InternVL 1.5在各种多模态基准测试中展现出强劲的性能。研究团队的评估表明,该模型实现了与领先的专有模型相当的性能,特别是在OCR相关任务中表现出色,并在中文相关场景理解方面显著提升。尽管InternVL 1.5为开源多模态理解做出了贡献,但该领域随着许多挑战的出现而不断发展。研究团队渴望进一步增强InternVL的能力,并邀请全球研究界的合作,希望共同丰富和扩展开源模型的影响力。
Demo: https://internvl.opengvlab.com
Code: https://github.com/OpenGVLab/InternVL
Model: https://huggingface.co/OpenGVLab/InternVL-Chat-V1-5

