
- 1创建和使用DirectX接口(并再次理解COM对象)_c#使用 com directx2d
- 2数据库之事务隔离级别详解_事务的隔离级别
- 3基于二阶锥优化电气综合能源系统优化调度研究 考虑气电联合需求响应的气电综合能源配网系统协调优化运行_考虑气网管存的电-气联合优化调度研究
- 4一文搞懂LLM大模型!LLM从入门到精通万字长文(2024.7月最新)_llm入门
- 5盘点目前有关数字人的开源项目_数字人开源项目
- 6Transformer模型代码(详细注释,适合新手)_transformers建模代码
- 7Git入门(一)之Windows系统下gitee仓库--本地仓库--修改仓库--gitee仓库?_gitee将本地仓库和远程仓库地址修改
- 8Hadoop2.7.6在Windows7单机部署_hadoop2.7.7gitub补丁下载windows
- 9You are applying Flutter‘s app_plugin_loader Gradle plugin imperatively using the apply script metho_you are applying flutter's main gradle plugin impe
- 10推荐开源项目:YOLO_SlowFast — 实时视频对象检测的新里程碑
python序列类型_序列类型python
赞
踩
数据容器(序列)是一种可以存储多个元素的Python数据类型,包含:
list(列表)、tuple(元组)、str(字符串)、set(集合)、dict(字典)
一、list(列表)
列表是一种可修改的集合类型,其元素可以是数字、字符串等基本类型,也可以是列表、元组、字典等集合类型,甚至可以是自定义的类型。
列表的特点有:

1.列表的定义方式
创建一个列表,只要用逗号分隔的不同的数据,然后使用方括号括起来即可:
- letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
- lst = list(('a', 'b', 'c'))
- print(type(letters), type(lst))
-
- # 得到输出:<class 'list'> <class 'list'>
数据容器内的每一份数据,都称之为元素,元素的数据类型没有任何限制,甚至元素也可以是列表,这样就定义了嵌套列表
- mix = [['a', 3.14, 999], ["all kinds of data"]]
- print(mix, type(mix))
-
- # 输出:[['a', 3.14, 999], ['all kinds of data']] <class 'list'>
2.列表的下标(索引)
列表的每一个元素都有编号,从列表中取出特定位置的数据叫做下标索引。
- # 下标索引
- hero_name = ["盖伦", "亚托克斯", "瑟提", "德莱厄斯"]
正向索引:元素的序号即从前往后的方向,从0开始,依次递增

列表名[n] 表示索引列表中第n+1个元素
反向索引:元素的序号即从后往前的方向,从-1开始,依次递减

()列表名[n] 表示索引列表中倒数第n个元素
- print(hero_name[0])
- print(hero_name[1])
- print(hero_name[-1])
- print(hero_name[-2])
-
- """
- 输出:
- 盖伦
- 亚托克斯
- 德莱厄斯
- 瑟提
- """
(通常情况下的讨论均是正向序列)
那么如果是嵌套列表应该如何根据下标索引呢?其实只需要根据嵌套层数多次索引即可
- # 列表嵌套
- mix = [['a', 3.14, 999], ["all kinds of data"]]
- print(mix[0][1])
-
- # 输出:3.14
-
- print(mix[-1][-6])
-
- # 报错:IndexError: list index out of range
要注意下标索引的取值范围,超出范围无法取出元素,并且会报错。
3.列表的一些操作(增删改查)
①列表的查询
列表类型提供的查询功能,用于查找指定元素对应的列表的下标。
查询方式:列表.index(元素)
其中, index就是列表对象(变量)内置的方法(函数),如果找不到,则会报错ValueError
- list_ex = [250, 3.14, 0.142857, 'k', "petrichor", 999]
- # 列表的查询,输出:5
- print(list_ex.index(999))
②列表的修改
如果想要修改列表中特定位置(索引)的元素, 可以通过直接对指定下标的值进行重新赋值(正向、反向下标均可操作)。
修改方式:列表[下标] = 值
- list_ex = [250, 3.14, 0.142857, 'k', "petrichor", 999]
-
- # 列表的修改,输出:996
- list_ex[5] = 996
- print(list_ex[5])
③列表的插入
列表类型提供的查询功能,用于在指定的下标位置,插入指定的元素。
插入方式:列表.insert(下标, 元素)
- list_ex = [250, 3.14, 0.142857, 'k', "petrichor", 999]
- # 列表的插入
- list_ex.insert(5, "007")
- print(list_ex)
-
- # 输出:[250, 3.14, 0.142857, 'k', 'petrichor', '007', 996]
④列表的追加
列表类型提供的追加功能,用于将指定元素,追加到列表的尾部。
追加方式1:列表.append(元素)
此外,还可以将其它数据容器的内容取出,依次追加到列表尾部。
追加方式2:列表.extend(其它数据容器)
- list_ex = [250, 3.14, 0.142857, 'k', "petrichor", 999]
- # 列表的追加
-
- # 追加方式1
- list_ex.append(4.44)
- print(list_ex)
-
- #输出:[250, 3.14, 0.142857, 'k', 'petrichor', '007', 996, 4.44]
-
- # 追加方式2
- list_ex.extend(["frank", "tony", "rain"])
- print(list_ex)
-
- #输出:250, 3.14, 0.142857, 'k', 'petrichor', '007', 996, 4.44, 'frank', 'tony', 'rain']
⑤列表的删除
想要删除列表中的某个元素有两种方法,一种是通过索引下标删除,另一种是通过直接根据首次匹配的元素进行删除。
删除方式1(下标法):del 列表[下标]
删除方式2(下标法):列表.pop(下标)
删除方式3(元素法):列表.remove(元素)
- list_ex = [250, 3.14, 0.142857, 'k', 'petrichor', '007', 996, 4.44, 'frank', 'tony', 'rain']
-
- # 列表的删除
-
- # 方式1
- del list_ex[3]
- print(list_ex)
-
- #输出:250, 3.14, 0.142857, 'petrichor', '007', 996, 4.44, 'frank', 'tony', 'rain']
-
- # 方式2
- list_ex.pop(2)
- print(list_ex)
-
- #输出:[250, 3.14, 'petrichor', '007', 996, 4.44, 'frank', 'tony', 'rain']
-
- # 方式3
- list_ex.remove(250)
- print(list_ex)
-
- #输出:[3.14, 'petrichor', '007', 996, 4.44, 'frank', 'tony', 'rain']
 '运行
'运行⑥列表的统计
统计某元素在列表内的数量
统计方式:列表.count(元素)
统计列表内有多少元素
统计方式:len(列表)
- # 列表的计数
- list_ex = [2, 2, 3, 3, 6]
-
- print(list_ex.count(2))
- print(len(list_ex))
-
- """
- 输出:
- 2
- 5
- """
⑦列表的清空
想要对列表进行全部删除可以通过清空操作
清空方式:列表.clear()
- # 列表的清空
- list_ex = [2, 2, 3, 3, 6]
- list_ex.clear()
-
- print(list_ex)
总结:
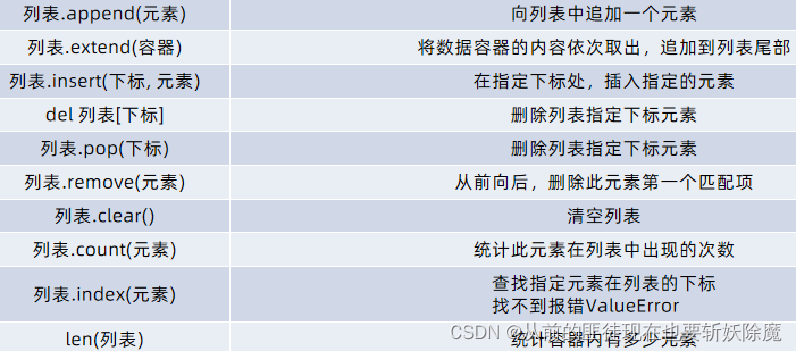
4.列表的遍历
将容器内的元素依次取出进行处理的行为称为遍历。
①while循环遍历
- mylist = ["Mollie", "I", "miss you"]
-
- # while循环遍历列表
- def list_while():
- """
- 使用while循环遍历列表的演示函数:
- 循环控制变量通过下标索引
- 每一次循环将下标索引变量 + 1
- 循环条件: 下标索引变量 < 列表元素数量
- :return: None
- """
- index = 0
- while index < len(mylist):
- element = mylist[index]
- index += 1
- print(f"列表的元素有:{element}")
-
-
- # 调用while遍历
- list_while()
②for循环遍历
- mylist = ["Mollie", "I", "miss you"]
-
- # for循环遍历列表
- def list_for():
- for element in mylist:
- print(f"列表的元素有:{element}")
-
-
- # 调用for遍历
- list_for()
两种遍历方式的对比
在循环控制上:
while循环可以自定循环条件,并自行控制
for循环不可以自定循环条件,只可以一个个从容器内取出数据
在无限循环上:
while循环可以通过条件控制做到无限循环
for循环理论上不可以,因为被遍历的容器容量不是无限的
在使用场景上:
while循环适用于任何想要循环的场景
for循环适用于,遍历数据容器的场景或简单的固定次数循环场景
二、tuple(元组)
元组同列表一样,可以封装多个不同类型的元素在内,但最大的不同在于元组一旦定义完成,就不可修改。
当我们需要在程序内封装数据,又不希望封装的数据被篡改,那么元组则是一个好的选择。
元组的特点:
有序、任意数量元素、允许重复元素
不可修改(元组元素不可修改,但元组内嵌套的列表可修改)
1.元组的定义方式
定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
- # 元组的定义
- tp1 = (1, "hello", True)
- tp2 = ()
- tp3 = tuple()
- print(type(tp1), type(tp2), type(tp3))
-
- # 定义单元素元组
- tp4 = ("frank")
- tp5 = ("frank", )
-
- print(type(tp4), type(tp5))
-
- # 输出: <class 'str'> <class 'tuple'>
注意,当元组内只有一个元素时,数据后面需要添加逗号才能定义为元组。
元组的嵌套:
- # 嵌套元组
- tp6 = ((1, 2, 3), (4, 5, 6))
- print(type(tp6))
2.元组的一些操作
元组由于不可修改的特性,所以其操作方法非常少,其他许多操作都与列表相似:
①下标索引取出元素
- # 嵌套元组
- tp6 = ((1, 2, 3), (4, 5, 6))
- print(type(tp6))
②元组的查询
- # 元组的查询
- tp7 = ("艾欧尼亚", "德玛西亚", "黑色玫瑰", "班德尔城")
- index = tp7.index("黑色玫瑰")
- print(index)
-
- # 输出:2
③元组的统计
- # 元组的统计
- tp8 = (3, 1, 4, 1, 5, 9, 2, 6)
- print(tp8.count(1), len(tp8))
-
- # 输出:2 8
总结
| 编号 | 方法 | 作用 |
| 1 | index() | 查找某个数据,如果数据存在返回对应的下标,否则报错 |
| 2 | count() | 统计某个数据在当前元组出现的次数 |
| 3 | len(元组) | 统计元组内的元素个数 |
3.元组的遍历
- tp8 = (3, 1, 4, 1, 5, 9, 2, 6)
-
- # while循环遍历元组
- index = 0
- while index < len(tp8):
- print(f"元组含有元素:{tp8[index]}")
- index += 1
-
- # for循环遍历元组
- for element in tp8:
- print(f"元组含有元素:{element}")
三、str(字符串)
字符串是字符的容器,一个字符串可以存放任意数量的字符,同元组一样是一个无法修改的数据容器。
1.字符串的下标(索引)
字符串同样支持正向和反向的下标索引:
- # 字符串的下标索引
- my_str = "I lost you"
- print(my_str[2])
- print(my_str[-8])
2.字符串的一些操作
①字符串的查询
同元组和列表一样,通过字符串.index(元素)来查询元素下标
- my_str = "I lost you"
-
- # 字符串的查询
- print(my_str.index('l'))
②字符串的替换
字符串的替换是指将字符串内的全部字符串1替换为字符串2;
此方法不能修改字符串本身,只能通过它得到一个新的字符串。
- # 字符串的替换
- my_str = "a1b2c3d4e2f1g3"
- print(my_str)
- my_str.replace('1', '0')
- print(my_str)
- new_str = my_str.replace('1', '0')
- print(new_str)
-
- """
- 输出:
- a1b2c3d4e2f1g3
- a1b2c3d4e2f1g3
- a0b2c3d4e2f0g3
- """
③字符串的分割
字符串的分割是指按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中;
此方法同样无法改变字符串本身,而是得到了一个列表对象。
- # 字符串的分割
- my_str = "a1 b2 c3 d4 e2 f1 g3"
- new_str = my_str.split(" ")
- print(f"分割后的字符串为:{new_str}, 类型是:{type(new_str)}")
-
- # 输出:分割后的字符串为:['a1', 'b2', 'c3', 'd4', 'e2', 'f1', 'g3'], 类型是:<class 'list'>
④字符串的规整
字符串的规整操作通常是指对字符串进行预处理,去除字符串两端的空白字符(包括空格、制表符、换行符等)以使其更加整洁。
当.strip()括号内传入特定字符时,则会按照传入的单个字符对字符串两端进行去除。
- # 字符串的规整
- my_str = " I miss you "
- print(my_str)
- print(my_str.strip())
-
- str1 = "山外青山"
- print(str1.strip("山"))
- str2 = "2134512"
- print(str2.strip("12"))
- str3 = "----hello world----"
- print(str3.strip("-"))
-
- """
- 输出:
- I miss you
- I miss you
- 外青
- 345
- hello world
- """
⑤字符串的统计
字符串的统计同样包括字符串中某字符串的出现次数和字符串的长度,数字(1、2、3...)、 字母(abcd、ABCD等)、 符号(空格、!、@、#等)、 中文均算作1个字符。
- # 字符串的统计
- my_str = "interesting"
- print(my_str.count('i'), len(my_str))
总结
| 编号 | 操作 | 说明 |
| 1 | 字符串[下标] | 根据下标索引取出特定位置字符 |
| 2 | 字符串.index(字符串) | 查找给定字符的第一个匹配项的下标 |
| 3 | 字符串.replace(字符串1, 字符串2) | 将字符串内的全部字符串1,替换为字符串2 不会修改原字符串,而是得到一个新的 |
| 4 | 字符串.split(字符串) | 按照给定字符串,对字符串进行分隔 不会修改原字符串,而是得到一个新的列表 |
| 5 | 字符串.strip() 字符串.strip(字符串) | 移除首尾的空格和换行符或指定字符串 |
| 6 | 字符串.count(字符串) | 统计字符串内某字符串的出现次数 |
| 7 | len(字符串) | 统计字符串的字符个数 |
3.字符串的遍历
- # 字符串的遍历
- my_str = "Welcome To NewYork"
-
- # while循环
- index = 0
- while index < len(my_str):
- print(f"字符串包含的字符有:{my_str[index]}")
- index += 1
-
- # for循环
- for element in my_str:
- print(f"字符串包含的字符有:{element}")
四、(序列的)切片
之前也提到过,序列是指内容连续、有序,可使用下标索引的一类数据容器,我们所学过的列表、元组、字符串,均可以可以视为序列。
而序列有一个常用的操作叫做切片,即从一个序列中,取出一个子序列;列表、元组、字符串,均支持进行切片操作。
切片方式:序列[起始下标:结束下标:步长]
其中,起始下标表示从何处开始,当起始下标为空则视作从头开始,起始下标是闭区间
结束下标表示何处结束,当结束下标为空视作截取到结尾,结束下标是开区间
步长表示,依次取元素的间隔,例如步长1表示,一个个取元素;步长2表示,每次跳过1个元素取; 步长N表示,每次跳过N-1个元素取
步长为负数时,表示反向取(注意,起始下标和结束下标也要反向标记)
注意,由于元组、字符串不可修改的特点,序列的切片操作不会影响序列本身,而是会得到一个新的序列。
- # 序列的切片
- my_list = [0, 1, 2, 3, 4, 5, 6, 7]
- result0 = my_list[::2]
- print(result0)
- result1 = my_list[1:4] # 当步长为1时可以省略不写
- print(result1)
-
- my_tuple = (0, 1, 2, 3, 4, 5, 6, 7)
- result2 = my_tuple[:]
- print(result2)
-
- my_str = "01234567"
- result3 = my_str[:4:2]
- print(result3)
-
- """
- 输出:
- [0, 2, 4, 6]
- [1, 2, 3]
- (0, 1, 2, 3, 4, 5, 6, 7)
- 02
- """
五、集合(set)
相比之前学习到的列表、元组和字符串,集合内不允许重复元素且集合内的元素是无序的,即集合具有去重无序的特点。
1.集合的定义方式
- # 集合的定义
- myset = {"浙江大学", "同济大学", "东南大学", "同济大学", "重庆大学"}
- print(myset)
-
- # 输出:{'浙江大学', '重庆大学', '东南大学', '同济大学'}
2.集合的一些操作
首先,因为集合是无序的,所以集合不支持下标索引访问,但是集合和列表一样,是允许修改的。
①增加元素
集合.add(新元素) (一次只能增加一个新元素)
- # 集合的定义
- myset = {"浙江大学", "同济大学", "东南大学", "同济大学", "重庆大学"}
- print(myset)
-
- #增加元素
- myset.add("武汉大学")
- print(myset)
-
- """
- 输出:
- {'重庆大学', '浙江大学', '东南大学', '同济大学'}
- {'武汉大学', '同济大学', '浙江大学', '东南大学', '重庆大学'}
- """
②删除元素
集合.remove(待删元素)
- # 集合的定义
- myset = {"浙江大学", "同济大学", "东南大学", "同济大学", "重庆大学"}
- print(myset)
-
- #增加元素
- myset.add("武汉大学")
- print(myset)
-
- #删除元素
- myset.remove("同济大学")
- print(myset)
-
- """
- 输出:
- {'浙江大学', '重庆大学', '同济大学', '东南大学'}
- {'浙江大学', '同济大学', '东南大学', '重庆大学', '武汉大学'}
- {'浙江大学', '东南大学', '重庆大学', '武汉大学'}
- """
③随机取元素
集合.pop()
- # 集合的定义
- myset = {"浙江大学", "同济大学", "东南大学", "同济大学", "重庆大学"}
- print(myset)
-
- # 增加元素
- myset.add("武汉大学")
- print(myset)
-
- # 删除元素
- myset.remove("同济大学")
- print(myset)
-
- # 随机取出一个元素
- elment = myset.pop()
- print(elment)
-
- """
- 输出:
- {'同济大学', '东南大学', '重庆大学', '浙江大学'}
- {'浙江大学', '同济大学', '东南大学', '武汉大学', '重庆大学'}
- {'浙江大学', '东南大学', '武汉大学', '重庆大学'}
- 浙江大学
- """
④清空集合
集合.clear()
- # 集合的定义
- myset = {"浙江大学", "同济大学", "东南大学", "同济大学", "重庆大学"}
- print(myset)
-
- # 增加元素
- myset.add("武汉大学")
- print(myset)
-
- # 删除元素
- myset.remove("同济大学")
- print(myset)
-
- # 随机取出一个元素
- elment = myset.pop()
- print(elment)
-
- # 清空集合
- myset1 = myset
- myset1.clear()
- print(myset1)
-
- """
- 输出:
- {'浙江大学', '重庆大学', '同济大学', '东南大学'}
- {'重庆大学', '武汉大学', '浙江大学', '同济大学', '东南大学'}
- {'重庆大学', '武汉大学', '浙江大学', '东南大学'}
- 重庆大学
- set()
- """
⑤取两个集合的差集
集合1.difference(集合2)
- # 取两集合的差集
- myset1 = {985, 211, "双一流"}
- myset2 = {211, "双一流"}
- myset3 = myset1.difference(myset2)
- print(myset3)
-
- # 输出:{985}
⑥消除两集合的差集
集合1.difference_update(集合2)
在集合1内,删除和集合2相同的元素,集合1被修改,集合2不变
- # 取两集合的差集
- myset1 = {985, 211, "双一流"}
- myset2 = {211, "双一流"}
- myset3 = myset1.difference(myset2)
- print(myset3)
-
- #消除两个集合的差集
- myset1.difference_update(myset2)
- print(myset1)
-
- """
- 输出:
- {985}
- {985}
- """
⑦合并两个集合
集合1.union(集合2)
可以得到新集合,集合1和集合2不变
- # 合并两集合
- myset4 = {1314}
- myset5 = {520}
- myset6 = myset4.union(myset5)
- print(myset6, myset4, myset5)
-
- """
- 输出:
- {520, 1314} {1314} {520}
- """
⑧统计集合元素数量
len(集合)
- # 统计集合内元素数量
- myset2 = {211, "双一流"}
- print(len(myset2))
-
- # 输出: 2
3.集合的循环
集合支持使用for循环遍历,但因为不支持下标索引,所以也就不支持使用while循环。
- # for循环遍历集合
- myset = {1, 2, 3, 4, 5, 6}
- for i in myset:
- print(i, end=' ')
-
- # 输出:1 2 3 4 5 6
六、字典(dict)
字典可以提供基于Key检索Value的场景实现,就像查字典一样。
注意事项:
键值对的Key和Value可以是任意类型。(Key不可为字典)
字典内Key不允许重复,重复添加等同于覆盖原有数据。
字典不可用下标索引,而是通过Key检索Value。
1.字典的定义
字典的定义,同样使用{},不过存储的元素是一个个的:键值对
- # 字典定义
- mydict = {"浙江大学": 95, "同济大学": 90, "东南大学": 85, "重庆大学": 80}
- # 字典的获取
- print(mydict["重庆大学"])
-
-
- # 字典嵌套
- my_dict = {
- "zju": {"能动": 90, "海洋": 70},
- "tju": {"汽车": 90, "交通": 90},
- "seu": {"交通": 90, "汽车": 85},
- "cqu": {"卓工": 85, "汽车": 85}
- }
- print(my_dict["cqu"])
- print(my_dict["zju"]["海洋"])
- print(my_dict["seu"]["汽车"])
-
- """
- 输出:
- 80
- {'卓工': 85, '汽车': 85}
- 70
- 85
- """
2.字典的一些操作
①新增元素
字典[Key] = Value,结果:字典被修改,新增了元素
- # 字典定义
- mydict = {"浙江大学": 95, "同济大学": 90, "东南大学": 85, "重庆大学": 80}
-
- # 增加元素
- mydict["武汉大学"] = 85
- print(mydict)
-
- # 输出: {'浙江大学': 95, '同济大学': 90, '东南大学': 85, '重庆大学': 80, '武汉大学': 85}
②更新元素
字典[Key] = Value,结果:字典被修改,元素被更新
- # 字典定义
- mydict = {"浙江大学": 95, "同济大学": 90, "东南大学": 85, "重庆大学": 80}
-
- # 元素更新
- mydict["重庆大学"] = 90
- print(mydict)
-
- # 输出: {'浙江大学': 95, '同济大学': 90, '东南大学': 85, '重庆大学': 90, '武汉大学': 85}
③删除元素
字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
- # 字典定义
- mydict = {"浙江大学": 95, "同济大学": 90, "东南大学": 85, "重庆大学": 80}
-
- # 增加元素
- mydict["武汉大学"] = 85
- print(mydict)
-
- # 元素删除
- value = mydict.pop("武汉大学")
- print(value)
- print(mydict)
-
- """
- 输出:
- 85
- {'浙江大学': 95, '同济大学': 90, '东南大学': 85, '重庆大学': 90}
- """
④清空字典
字典.clear(),结果:字典被修改,元素被清空
- # 字典定义
- mydict = {"浙江大学": 95, "同济大学": 90, "东南大学": 85, "重庆大学": 80}
-
- # 元素清空
- mydict.clear()
- print(mydict)
-
- # 输出: {}
⑤获取全部key
字典.keys(),结果:得到字典中的全部Key
- # 定义字典
- my_dict = {
- "zju": {"能动": 90, "海洋": 70},
- "tju": {"汽车": 90, "交通": 90},
- "seu": {"交通": 90, "汽车": 85},
- "cqu": {"卓工": 85, "汽车": 85}
- }
-
- # 获取全部key
- keys = my_dict.keys()
- print(keys)
-
- # 输出:dict_keys(['zju', 'tju', 'seu', 'cqu'])
⑥统计字典元素个数
len(字典) 结果:得到一个整数,表示字典内元素(键值对)的数量
- # 字典定义
- my_dict = {
- "zju": {"能动": 90, "海洋": 70},
- "tju": {"汽车": 90, "交通": 90},
- "seu": {"交通": 90, "汽车": 85},
- "cqu": {"卓工": 85, "汽车": 85}
- }
-
- # 统计键值对数量
- n = len(my_dict)
- print(n)
-
- # 输出: 4
3.字典的遍历
字典不支持下标索引,所以同样不可以用while循环遍历
- # 字典嵌套
- my_dict = {
- "zju": {"能动": 90, "海洋": 70},
- "tju": {"汽车": 90, "交通": 90},
- "seu": {"交通": 90, "汽车": 85},
- "cqu": {"卓工": 85, "汽车": 85}
- }
-
- # 字典的遍历
- key = my_dict.keys()
- for key in my_dict:
- print(f"高校:{key}, 评估:{my_dict[key]}")
-
- """
- 输出:
- 高校:zju, 评估:{'能动': 90, '海洋': 70}
- 高校:tju, 评估:{'汽车': 90, '交通': 90}
- 高校:seu, 评估:{'交通': 90, '汽车': 85}
- 高校:cqu, 评估:{'卓工': 85, '汽车': 85}
- """

