
- 1鸿蒙Next怎么升级,有便捷的方法?_怎么升级鸿蒙next
- 2优雅实现uniapp返回上一页传参_uniapp返回上一页并传参
- 3黑苹果/Mac如何升级 Mac 新系统 Sequoia Beta 版_macos更改beta版更新所用账号
- 4bip32-utils_python bip32utils
- 5阿里云最新重磅发布:通义千问2.5模型更强、5到10行代码搭建企业RAG应用、代码助手通义灵码推企业版_通义灵码和通义千问的区别
- 6stable diffusion学习笔记——文生图(一)_stablediffusion正向词和反向词的区分
- 7第二章:huggingface的TrainingArguments与Trainner参数_trainingarguments参数
- 8为什么要使用微服务架构?_简单描述为什么采用微服务架构,微服务架构能满足a~h那些需求
- 9Java xml出现错误 javax.xml.transform.TransformerException: java.lang.NullPointerException
- 10.net 使用Exchange Web Services (EWS) 获取电子邮件报错:The SSL connection could not be established_the ssl connection could not be established net
[深度学习]Semantic Segmentation语义分割之UNet(2)_unet with resblock for semantic segmentation
赞
踩
论文全称:《U-Net: Convolutional Networks for Biomedical Image Segmentation》
论文地址:https://arxiv.org/pdf/1505.04597v1.pdf
论文代码:https://github.com/jakeret/tf_unet
目录
提出动机
首先,以往的深度学习模型大部分都是分类模型,但是很多视觉任务,特别是医学影像的处理方面,需要的是语义分割,具体到每一个像素上的分类。
其次,很多任务没有imagenet那样大规模的数据集,收集的成本非常高。
最后,之前的方法太慢了,对于定位和使用图像中的上下文是一个tradeoff,最近很多方法都是利用多层features,本文也不例外。
综述
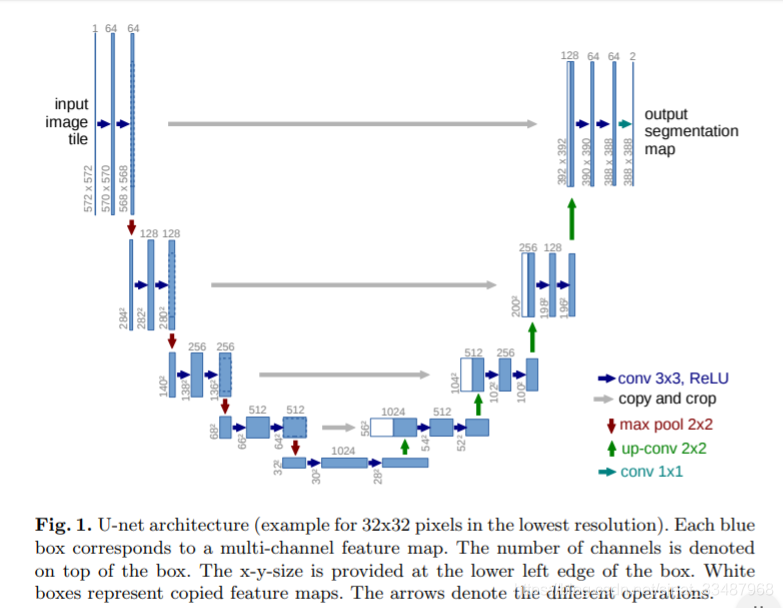
UNet是基于全卷积网络,可以参考[深度学习]Semantic Segmentation语义分割之FCN(1),UNet的主要思想就是在常规的卷积网络后面添加连续的层,这些层的目的是上采样。上采样提高了output的输出精度,但是为了更准确地定位,所以结合了上游的feature。Unet中一个比较重要的修改就是在上采样的部分依然保留大量的特征通道,这样一来便能将上下文信息传播到更高的分辨率层。所以整个Unet网络结构看上去就像一个“U”字形。与FCN一样,网络中没有使用全连接层,全是卷积层。
UNet这篇论文实现过程遇到一些challenge,包括数据太少以及粘连object的分离问题。前者使用elastic deformations弹性形变做了数据增强,这使得网络可以学习这种形变的不变性。后者作者提出了一种加权损失的方法,在这种方法中,接触细胞之间的背景标签的分离在损失函数中获得了较大的权重。
网络结构
网络架构如上图所示。它由收缩路径(左侧)和膨胀路径(右侧)组成。收缩路径遵循卷积网络的典型架构。它包括两个3x3卷积(unpadded)的重复应用,每个卷积后面是一个整流的线性单元(ReLU)和一个2x2 max pooling运算用于下采样。在每个下采样步骤中,将特征通道的数量增加一倍。扩展路径中的每一步都包含一个向上采样的feature map,然后是一个2x2卷积(“up-convolution”),该卷积将feature channel的数量减半,与收缩路径中相应裁剪的feature map进行连接,以及两个3x3卷积,每个卷积之后是一个ReLU。这种裁剪是必要的,因为在每次卷积中都会丢失边界像

