
- 1python之自动发送微信消息_python微信自动发消息
- 2Codeforces上几道神一般的数据结构题_codeforces 数据结构题单
- 3素数判断函数 c_在c++中if(mrun.currentfloor!=index)什么意思
- 4配置python环境变量_python添加环境变量path
- 5搭建自己的网站_csdn做一个自己的网站
- 6运行python程序用什么软件,python在什么软件上运行_python代码用什么打开
- 7leetcode-6135:图中的最长环_图上找最长环
- 8【综合评价分析】熵权算法确定权重 原理+完整MATLAB代码+详细注释+操作实列_熵权法matlab代码
- 9【LeetCode】142-环形链表II(含推理过程)_环形链表 ii推论
- 10蓝桥杯 Python B组-说明_蓝桥杯web组容易还是python组容易
大模型实战营第二期——2. 浦语大模型趣味Demo
赞
踩
文章目录
视频链接: 轻松玩转书生·浦语大模型趣味Demo
文档链接: InternLM/tutorial/helloworld/hello_world.md
Intern-Studio链接: Intern-Studio控制台
1. 大模型及InternLM模型介绍


- 大模型:参数规模大的模型,
- 这个大的量级指的是: 十亿甚至千亿以上的参数

2. InternLM-Chat-7B智能对话Demo

2.1 基本说明

- 7B(Billion, 10亿),70亿ca参数
- 8K token的上下文窗口长度
2.2 实际操作
2.2.1 创建开发机
在课程分配的InterStudio中,创建新的开发机,进行相应的选择,类似:
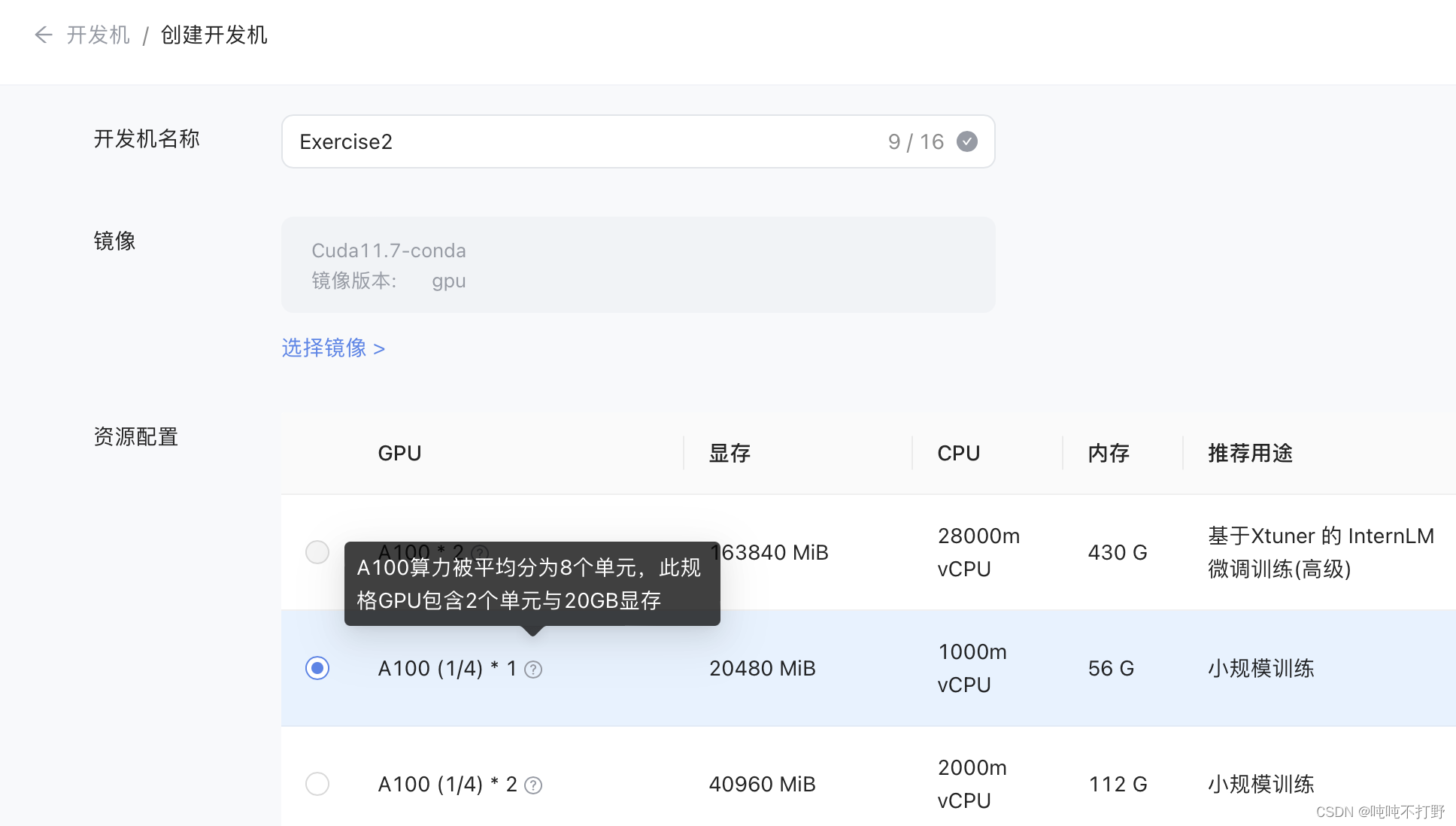
对于InternLM-Chat-7B的部署测试,使用A100(1/4)即可(1个A100的显存是80GB,四分之一就是20GB)
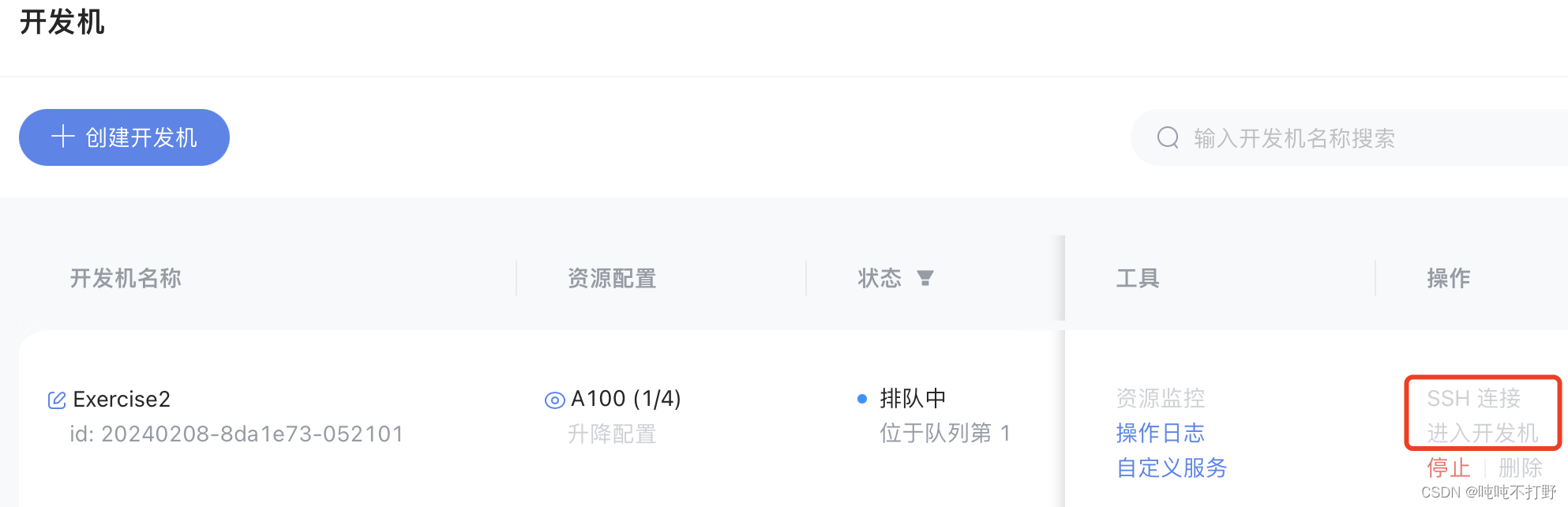
创建完成之后,刚开始会显示排队(其实是在为你分配资源),分配好之后,右侧的SSH连接和进入开发机就可以使用了
进入开发机会新打开一个页面,就是改了点界面的jupyter,那就不需要用vscode走ssh连接了,直接jupyter操作好了。
2.2.2 conda环境配置
接下来根据文档的提示,配置一些必要的环境
# 1. 请每次使用 jupyter lab 打开终端时务必先执行 bash 命令进入 bash 中 bash # 2. 执行该脚本文件来安装项目实验环境, 从本地克隆一个已有的 pytorch 2.0.1 的环境 bash /root/share/install_conda_env_internlm_base.sh internlm-demo # 这个要按一会的,等着吧 # 3. 检查conda环境 conda info -e # conda environments: # base * /root/.conda internlm-demo /root/.conda/envs/internlm-demo # 4.然后激活刚刚新建的环境 conda activate internlm-demo # 则conda环境从base变成了internlm-demo # 5.并在环境中安装运行 demo 所需要的依赖。 python -m pip install --upgrade pip # 升级pip pip install modelscope==1.9.5 # 其实安装modelscope的过程中,也会安装 huggingface-hub-0.20.3 包 pip install transformers==4.35.2 pip install streamlit==1.24.0 pip install sentencepiece==0.1.99 pip install accelerate==0.24.1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
一些探索:
# 其实本机使用的shell就是bash,也不需要切换
(base) root@intern-studio-052101:/opt/jupyterlab$ echo $SHELL
/bin/bash
(base) root@intern-studio-052101:/opt/jupyterlab$ cat /etc/shells
# /etc/shells: valid login shells
/bin/sh
/bin/bash
/usr/bin/bash
/bin/rbash
/usr/bin/rbash
/bin/dash
/usr/bin/dash
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
关于bash,之前写过macOS的terminal的zsh颜色主题设置及zsh和bash切换
2.2.3 模型下载
InternStudio 平台的 share 目录下已经为我们准备了全系列的 InternLM 模型,所以我们可以直接复制即可
# 注意,这里所说的share是/root/share/model_repos/目录 ls /root/share/model_repos/ > internlm-20b internlm-chat-7b internlm2-20b internlm2-base-7b internlm2-chat-20b-sft internlm2-chat-7b-sft internlm-7b internlm-chat-7b-8k internlm2-7b internlm2-chat-20b internlm2-chat-7b internlm-chat-20b internlm-chat-7b-v1_1 internlm2-base-20b internlm2-chat-20b-4bits internlm2-chat-7b-4bits # 而不是下面这个目录 ls /root/share/temp/model_repos > internlm-chat-7b internlm-xcomposer-7b # 复制是为了留个备份 mkdir -p /root/model/Shanghai_AI_Laboratory cp -r /root/share/temp/model_repos/internlm-chat-7b /root/model/Shanghai_AI_Laboratory # 复制好之后可以去看看文件内容,可以用jupyter左侧的目录看,也可以用命令行查看详情 ls -lh /root/model/Shanghai_AI_Laboratory/internlm-chat-7b total 14G -rw------- 1 root root 12K Feb 8 15:36 README.md -rw------- 1 root root 731 Feb 8 15:36 config.json -rw------- 1 root root 62 Feb 8 15:36 configuration.json -rw------- 1 root root 5.1K Feb 8 15:36 configuration_internlm.py -rw------- 1 root root 132 Feb 8 15:36 generation_config.json -rw------- 1 root root 43K Feb 8 15:36 modeling_internlm.py -rw------- 1 root root 1.9G Feb 8 15:36 pytorch_model-00001-of-00008.bin -rw------- 1 root root 1.9G Feb 8 15:36 pytorch_model-00002-of-00008.bin -rw------- 1 root root 1.9G Feb 8 15:36 pytorch_model-00003-of-00008.bin -rw------- 1 root root 1.9G Feb 8 15:36 pytorch_model-00004-of-00008.bin -rw------- 1 root root 1.9G Feb 8 15:36 pytorch_model-00005-of-00008.bin -rw------- 1 root root 1.9G Feb 8 15:36 pytorch_model-00006-of-00008.bin -rw------- 1 root root 1.9G Feb 8 15:36 pytorch_model-00007-of-00008.bin -rw------- 1 root root 807M Feb 8 15:36 pytorch_model-00008-of-00008.bin -rw------- 1 root root 37K Feb 8 15:36 pytorch_model.bin.index.json -rw------- 1 root root 95 Feb 8 15:36 special_tokens_map.json -rw------- 1 root root 8.8K Feb 8 15:36 tokenization_internlm.py -rw------- 1 root root 1.6M Feb 8 15:36 tokenizer.model -rw------- 1 root root 343 Feb 8 15:36 tokenizer_config.json
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
很明显,里面有8个bin文件夹是用来存放权重的,加起来大约是14GB左右。

如果使用的是非InterStudio平台进行训练部署,那么可以使用modelscope进行下载,模型大小为 14 GB,下载模型大概需要 10~20 分钟
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b', cache_dir='/root/model', revision='v1.0.3')
- 1
- 2
- 3
- 4
参考:
- modelscope模型库/internlm-chat-7b || 书生·浦语-对话-7B
- hugging face-internlm/internlm-chat-7b
- 这两个模型库里也都可以看到模型文件的详情
2.2.4 InternLM代码库下载和修改
mkdir /root/code
cd /root/code
git clone https://gitee.com/internlm/InternLM.git
# 切换到教程的分支,保证更好的复现效果
cd InternLM
git checkout 3028f07cb79e5b1d7342f4ad8d11efad3fd13d17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后将/root/code/InternLM/web_demo.py 中 29 行和 33 行的模型更换为本地的 /root/model/Shanghai_AI_Laboratory/internlm-chat-7b
2.2.5 cli运行
可以在 /root/code/InternLM 目录下新建一个 cli_demo.py 文件,将以下代码填入其中:
import torch from transformers import AutoTokenizer, AutoModelForCausalLM model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b" tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto') model = model.eval() system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语). - InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless. - InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文. """ messages = [(system_prompt, '')] print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============") while True: input_text = input("User >>> ") input_text = input_text.replace(' ', '') if input_text == "exit": break response, history = model.chat(tokenizer, input_text, history=messages) messages.append((input_text, response)) print(f"robot >>> {response}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
然后去运行上面的脚本(建议这里去vscode的终端运行下面的命令,看起来会比较好看。
另外因为使用的是绝对路径,所以不用担心cli的当前执行路径问题)
python /root/code/InternLM/cli_demo.py # 需要一些时间加载模型 > Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████| 8/8 [00:40<00:00, 5.02s/it] # 然后就会出现对话界面,等待输入对话,速度有点慢,等等就好。 =============Welcome to InternLM chatbot, type 'exit' to exit.============= User >>> 有什么好用的本地markdown编辑笔记软件吗 robot >>> 目前有许多好用的本地 Markdown 编辑软件供您选择。以下是一些常用的本地 Markdown 编辑器: 1. Typora - 一个简单易用的 Markdown 编辑器,具有实时预览功能。 2. Marked - 一个轻量级的 Markdown 编辑器,支持多种输出格式。 3. Marked2 - 另一个轻量级的 Markdown 编辑器,具有类似于 Typora 的实时预览功能。 4. Sublime Text - 一款功能强大的代码编辑器,也支持 Markdown 格式。 5. Atom - 由 GitHub 开发的一个开源文本编辑器,支持 Markdown 和许多其他编程语言。 6. Vim - 一款经典的文本编辑器,支持多种编程语言,包括 Markdown。 7. Nano - 一个轻量级的文本编辑器,支持 Markdown 和 Git。 8. Visual Studio Code - 一个免费的跨平台代码编辑器,支持 Markdown 和许多其他编程语言。 这些工具都具有不同的优点和缺点,您可以根据自己的需要选择最适合您的工具。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输入exit即可退出
2.2.6 web_demo运行
这个就切换到vscode里去运行吧。。
# 切换到vscode,就需要重新进入对应的conda和shell环境了
bash
conda activate internlm-demo # 首次进入 vscode 会默认是 base 环境,所以首先切换环境
cd /root/code/InternLM
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006
- 1
- 2
- 3
- 4
- 5
教程里说需要配置端口,其实不用。。。(6006默认是tensorboard的端口),
- 如果是jupyter的命令行,则不可以,
- 但是如果是vscode里的命令行运行,则就可以打开

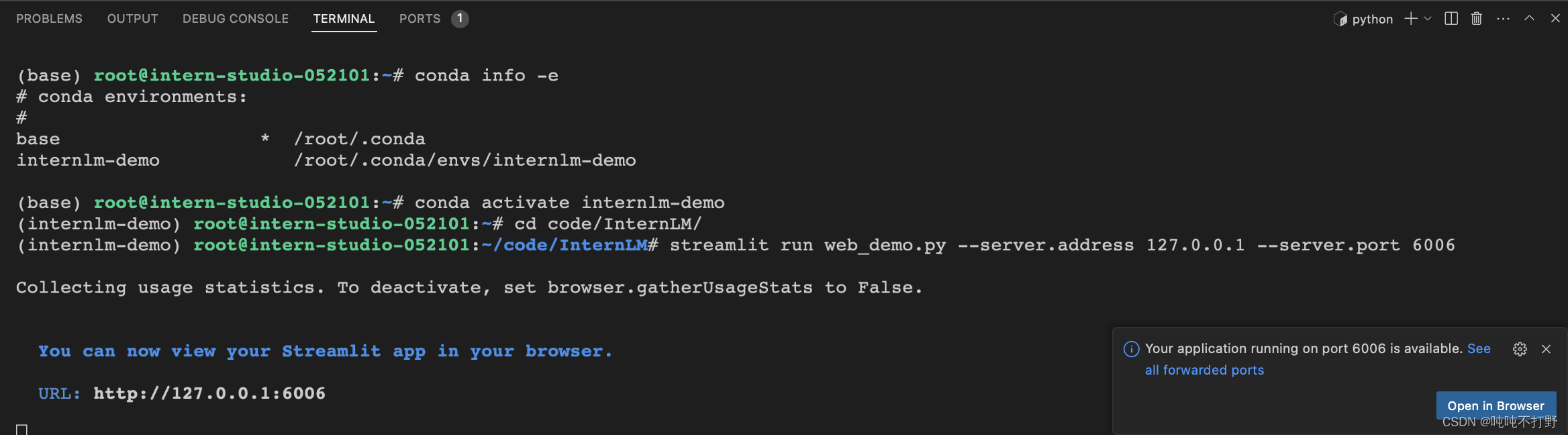
运行这个命令等待一会,然后就可以看到右侧弹出一个窗口,点击Open in Browser,就可以打开网页了。
打开网页链接之后,模型才会开始加载
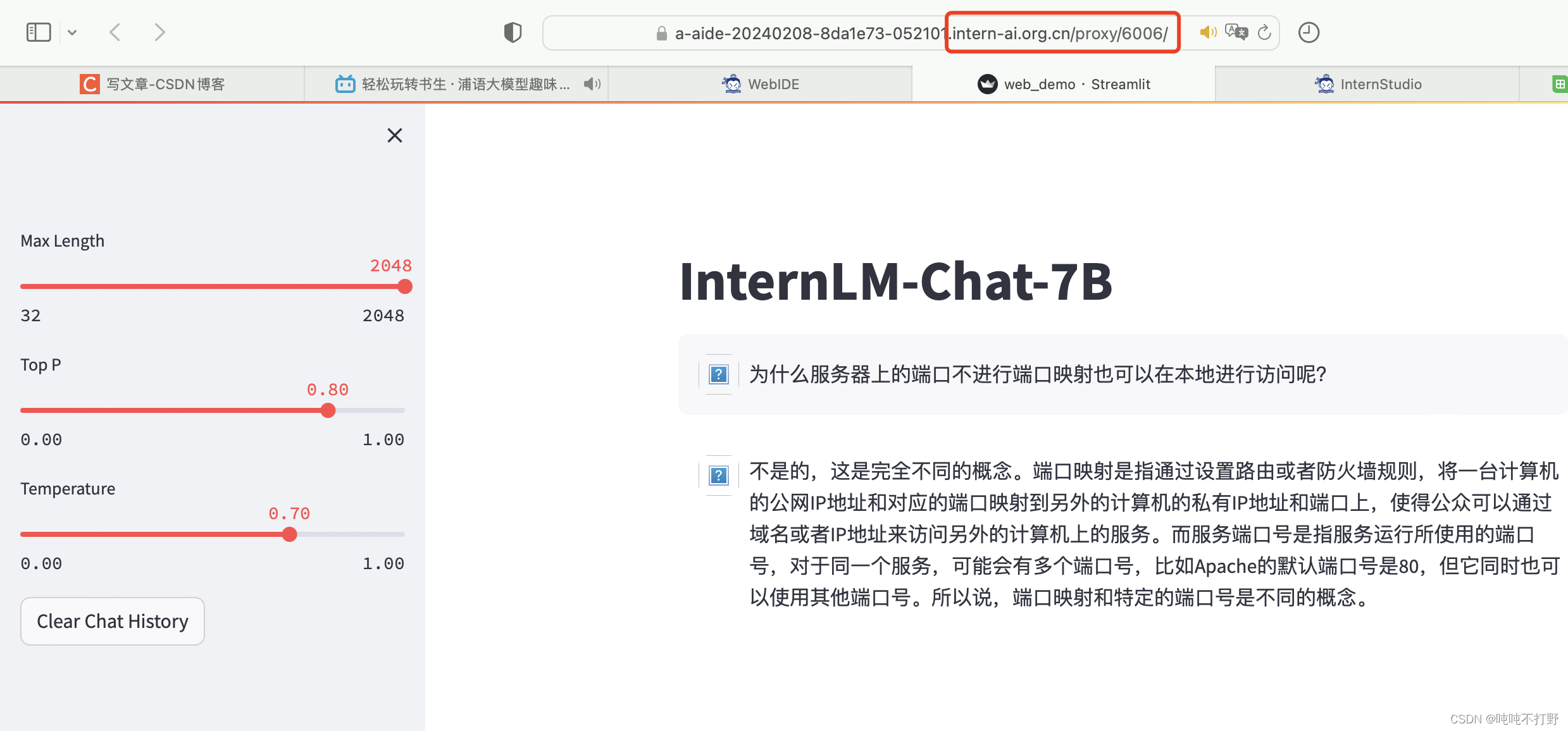
加载模型结束之后才会显示这个界面。
3. Lagent智能体工具调用Demo

3.1 基本说明
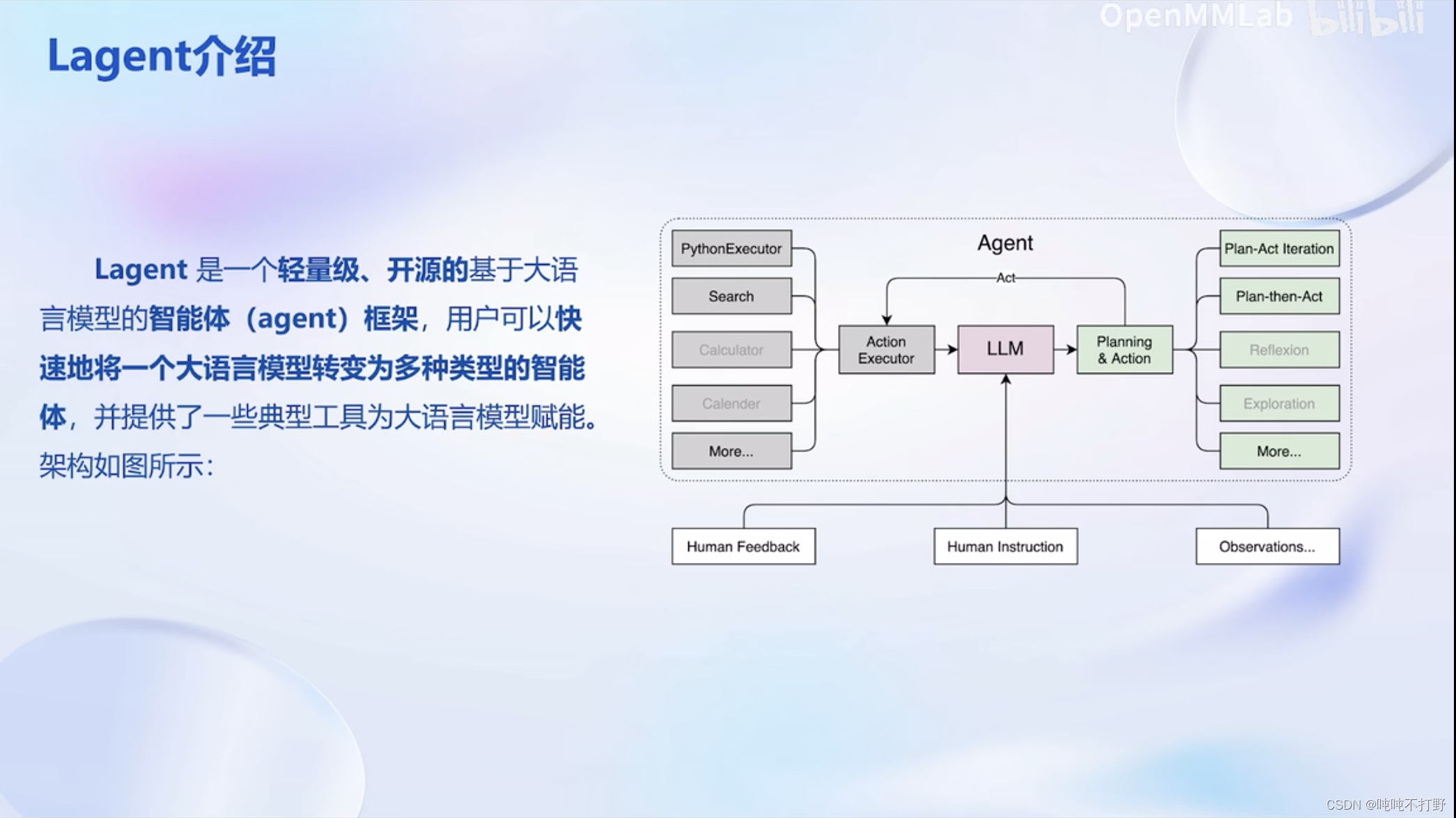
3.2 实际操作
3.2.1 准备操作
- 和上一个智能对话Demo需要的conda环境是一致的
- 需要下载的预训练模型也是
InternLM-Chat-7B
需要安装的代码库不是InternLM.git了,而是lagent.git,为了保证下载速度,这里用的都是gitee上的链接,而不是github。
与上面的操作类似,
cd /root/code
git clone https://gitee.com/internlm/lagent.git
cd /root/code/lagent
git checkout 511b03889010c4811b1701abb153e02b8e94fb5e # 尽量保证和教程commit版本一致
pip install -e . # 源码安装
- 1
- 2
- 3
- 4
- 5
3.2.2 修改代码
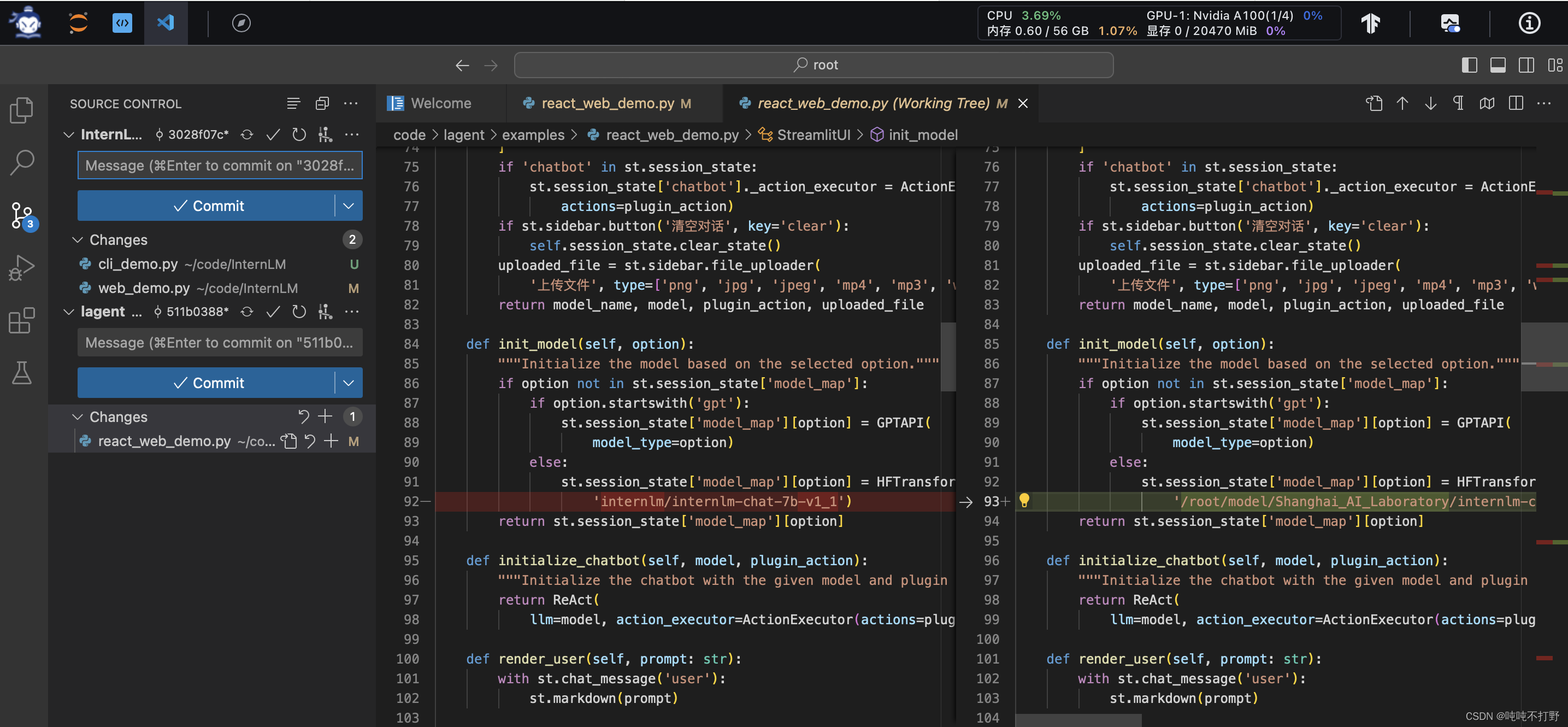
然后直接复制3.4 修改代码中的内容到/root/code/lagent/examples/react_web_demo.py中。
其实有意义的修改没几个,主要还是修改预训练模型的位置,其它就是注释掉一些页面显示元素,以及空格换行等格式
3.2.3 运行web_demo
和上面也是类似的
streamlit run /root/code/lagent/examples/react_web_demo.py --server.address 127.0.0.1 --server.port 6006
- 1
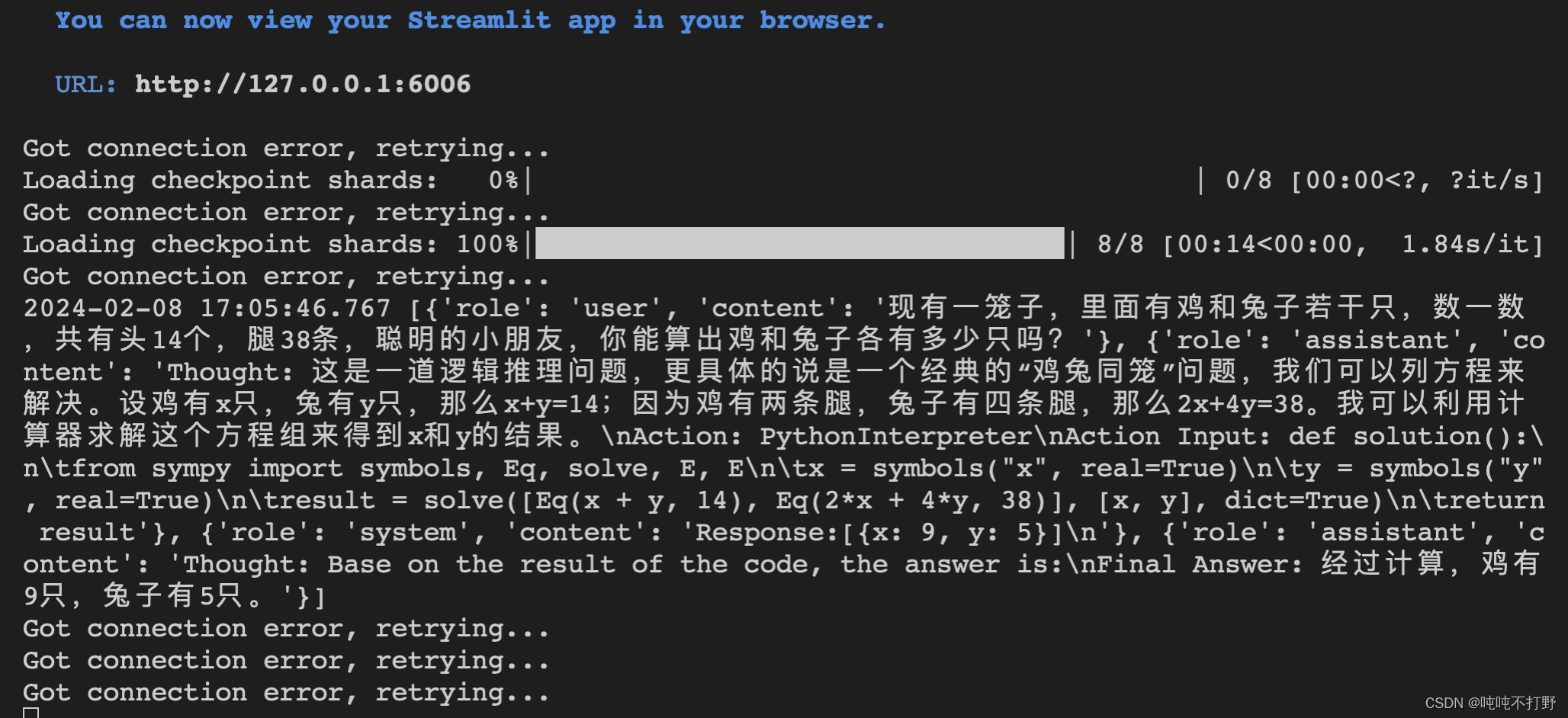
这里有了Lagent,就可以针对具体的场景,进行一些适配,比如求解数学问题。
试了一下经典的鸡兔同笼问题:
现有一笼子,里面有鸡和兔子若干只,数一数,共有头14个,腿38条,聪明的小朋友,你能算出鸡和兔子各有多少只吗?
反应比较慢,可以通过命令行查看模型加载情况:
效果还挺好的声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

