
- 1TOP 3大开源Python数据分析工具!_python数据分析开发工具
- 2Linux系统本地部署MongoDB数据库并实现远程访问方法指南_linux配置mongodb远程访问
- 3Java学习篇72-docker-Dockerfile_java dockerfile
- 4Linux下github的搭建_linux安装github
- 5创新引领未来,智慧水利在路上:数字孪生技术为水库管理开辟新机遇,带来新挑战,引领水利行业迈向智能化新纪元_水利数字孪生面临的机遇和挑战
- 6IBM在人工智能方面的新进展,理解谈话情景和感知情绪
- 7【原创】PHP程序员的技术成长规划_黑夜路人 博客
- 8十分钟快速搭建Pritunl并结合内网穿透工具实现无公网IP远程连接openvpn_无公网ip的内网穿透方案
- 9ECharts数据可视化项目-大屏数据可视化【持续更新中】_echarts可视化大屏开源项目_echarts数据可视化大屏
- 10apollo服务器集成java_SpringBoot 集成 Apollo 配置中心
自然语言处理(第13课 语义分析)_语义分析的任务是什么
赞
踩
一、学习目标
1.了解语义分析的任务是什么
2.认识什么是语义网络
3.了解词义消歧任务
4.掌握语义角色标注各种方法的工作流程
二、语义分析概述
1.任务目标与困难
语义分析的任务,就是解释自然语言的句子或者篇章各部分(词、词组、句子、段落、篇章)的含义。就相当于给一篇文章给gpt,然后再问他问题,得到相关回答。
语义分析的困难,在于三个点:

相关的例子如下:(明明表面上是不一样的表达,语义表达确实相同的)

2.其他的挑战

三、语义网络
1.概念
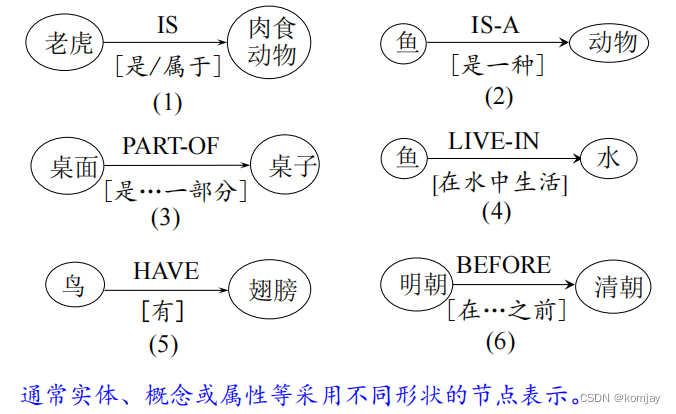
语义网络通过实体、概念或者动作、状态及语义关系组成的有向图来表达知识、描述语义。
在这个有向图中,结点表示实体,边表示实体之间的关系。由于关系的种类是多种多样的,边的类型也是多样的。例子如下:
2.事件的语义表示与知识图谱
有了语义网络的基础定义,对于特定的任务,可以用不同的语义网络来设置。
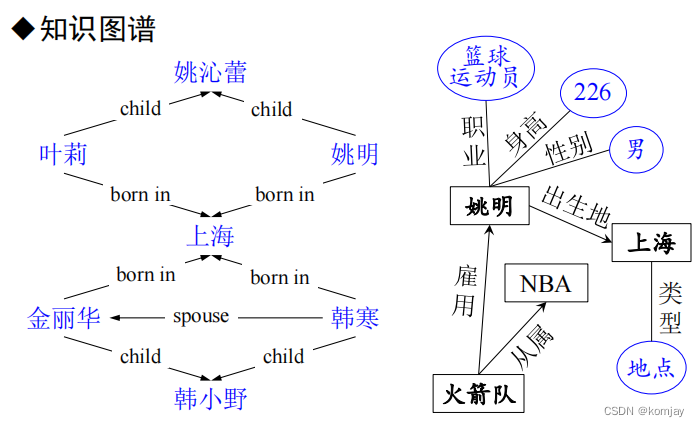
事件的语义表示是一个特定的任务,其语料库用一条句子去描述一个事件,模型需要标注事件的主体、客体等信息,构成一个语义网络。元素之间的关系和例子如下展示:

知识图谱则是另外一种任务,其需要广泛的语料信息,去构建一个知识图谱,这个图谱上保存着各种各样的事物以及其之间的关系。例子如下所示:
3.知网(Hownet)
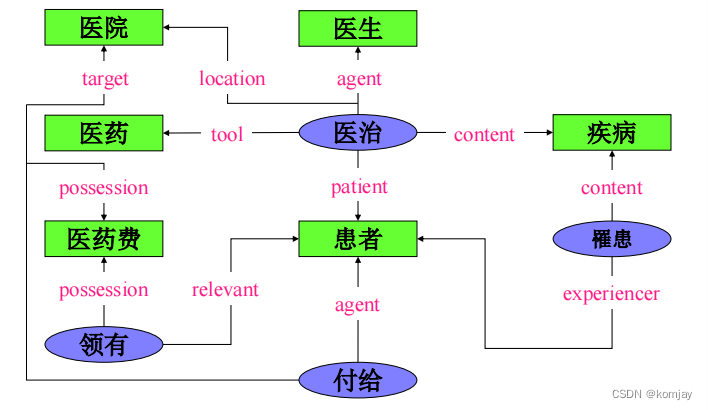
此知网非"中国知网"的知网,而是一个数据库概念,或者是一个百科全书,这个数据库由一个大网组成,其与NLP之间有着相关性,且有以下四个观点:(红色字是简单概要)

在知网中,其着力反映概念的共性和个性,例如:对于“医生”和“患者”,“人”是它们的共性。一个知网的例子如下:(只是一部分,看着跟前面的事件语义表示很像)
四、词义消歧
基本方法有:

词义消歧的方法在第二章有讲过,这里就不叙述了。
五、语义角色标注(SRL)
语义角色标注任务就是输入一个句子,正确分析出句子中各个词语的作用和成分。

1.各种数据库
用于SRL的训练数据主要有三种形式,也根据其形式不同分为三种数据库:

(1)PropBank指动词命题库,其在树库(描述句法结构信息)的基础上,添加了论元标记。(这里的论元指的是词级别,论元本身的范围就很宽泛,有的时候是句子,有的时候是词)例子如下:
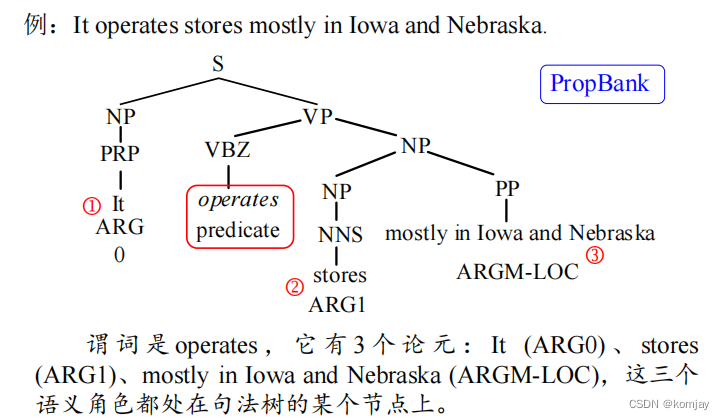
其就是在上几章的句法分析讲的句法树的基础上,在树的叶子节点加上了单词对应的论元标记。
(2)NomBank指名称命题库,其并不与PropBank对立,而是相辅相成,NomBank主要处理那些名词短语,对名词短语进行更细致的划分,相关例子如下:

(3)框架网没讲。
2.SRL的算法
SRL总体的流程图如下:
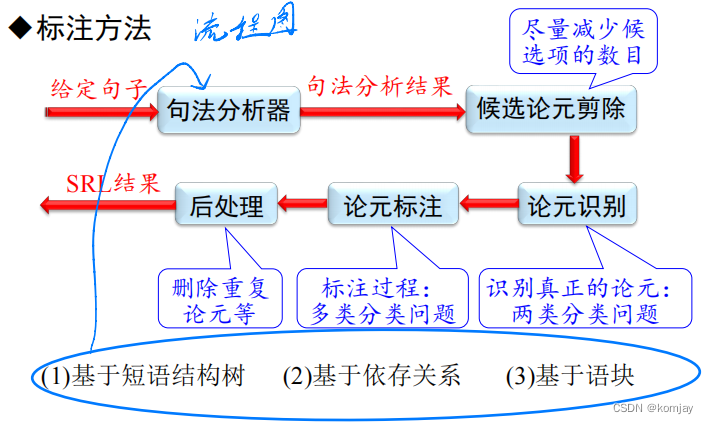
针对不同的句法分析器,我们有三种SRL算法:
(1)基于短语结构树的SRL
算法步骤如下:

例子如下:1、2、4步都标注在图中,第3步则是红框部分,由于三个节点分别是VP、PU、VP,PU是标点符号,不考虑,剩余两个是并列关系,所以不加。(底下的论元标注只是一个参考,这一步只是找到哪些论元需要标注)
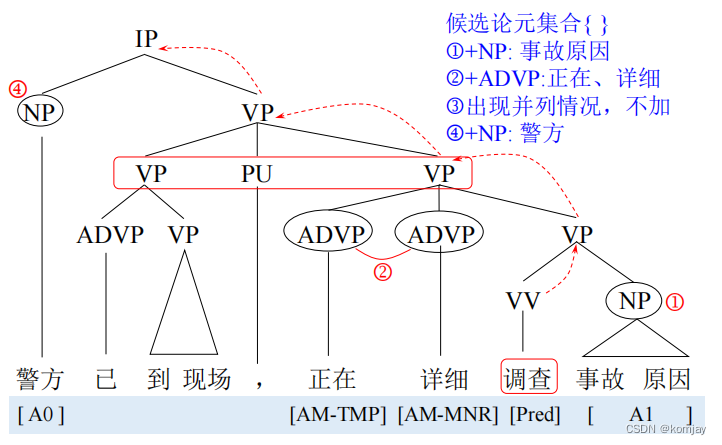
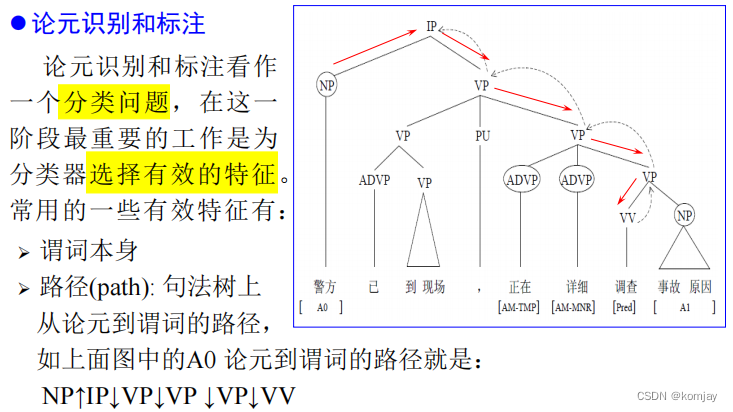
有了论元集合后,就需要进行识别与标注了:(就是这个任务看成一个分类任务,可用的特征有词语类型、位置、论元的中心词等,分类器则可以选择贝叶斯、SVM等)
(2)基于依存关系的SRL
首先也是确定候选论元:

以一个例子来说明:先找到谓词“调查”,其孩子为“警察”、“正在”、“详细”,“原因”。然后这些孩子中只有“原因”还有孩子,于是将“事故”加入。End。
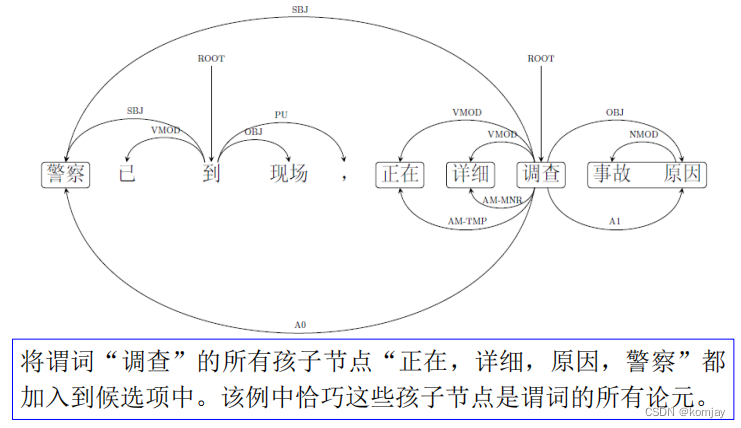
论元标记识别和标注的任务就跟(1)一样了。只是可以使用的特征会有些不同,如父节点的词和词性、依存路径等。
对比(1)与(2)的不同,可以发现就是论元获取的不同,从理论上分析,是其对一个大论元的表示方式不同:(1)中的一个大论元被表示为连续的词与一个语义角色的标签;(2)中的一个大论元被表示为一个中心词和一个语义角色标签。
(3)基于语块分析的SRL
这个方法就更简单了。因为它把SRL任务看成了一个序列标注任务,直接使用我们前面学习过的CRFs算法就能解决。基础思路如下:

举个例子就是:

(4)其他的SRL方法
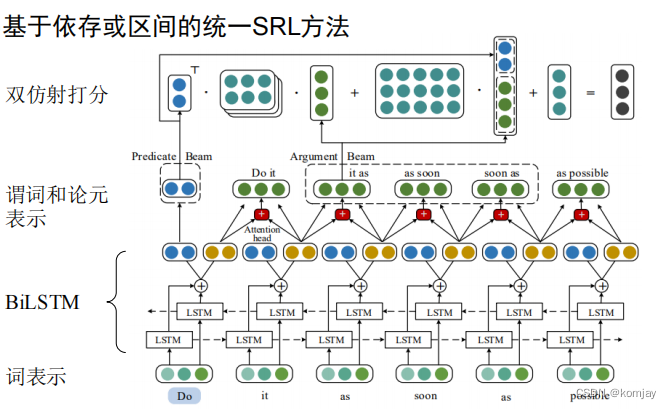
基于依存或区间的统一SRL方法。
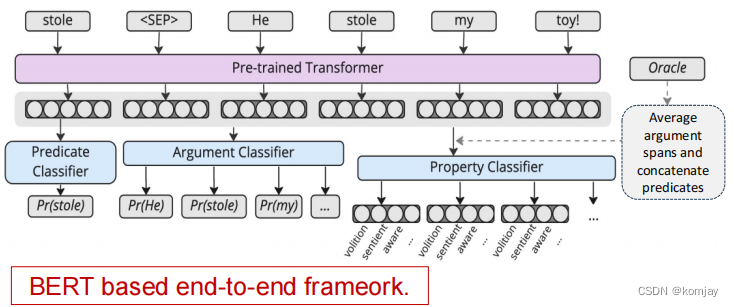
基于DL的SRL方法。
3.目前SRL的问题与效果

六、本章小结


