
- 1Java ArrayList 常用操作总结_arraylist类基本操作
- 2基于SpringBoot+Vue的养老院管理系统设计和实现(源码+lw+部署+讲解)
- 3Python实战案例分享:爬取当当网商品数据
- 4微服务Spring Cloud架构详解_springcloud微服务架构
- 5【linux高级IO(一)】理解五种IO模型
- 6关于oracle 11g 循环多判断+continue 用法例子_oracle 多个判定多次执行
- 7【数据结构】双链表_数据结构 双链表
- 8Linux中系统安全及应用_securelevel
- 9GIT和MAVEN基础向_maven git
- 10苹果iOS免签封装APP的原理,如何操作?_苹果网站一键免签打包
python爬虫之静态网页(以当当网图书畅销榜榜为例)_爬虫实例当当网
赞
踩
在编写爬虫代码时,将网页分为静态网页和动态网页两种,不同类型的网页数据有着不同的处理办法,这篇文章简述爬取静态网页的方法,以当当网的图书销量为例,使用爬虫技术可以获得网页的页面数据并且自动生成excel表格保存,下面开始讲解
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-1
首先我们判断一下当当网的页面数据加载是静态的还是动态的,有很多种方法,这里小编教大家一个,我们使用python中的requests库先对网页进行爬取,观察内容,如下图
- import requests
- '''User-Agent使代码伪装成浏览器进行网页访问,获取方法自行百度,不伪装可能无法获取数据'''
- head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36\
- (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
- '''创造一个字典,将我们需要的信息作为键,后接空列表作为值,等待写入'''
- dataset = {'图书排行': [], '图书名称': [], '图书作者': [], '出版社': [], '出版时间': [],'价钱': []}
- url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-{}'.format(1)
- data = requests.get(url=url,headers=head)#利用get进行请求
- data.encoding=data.apparent_encoding#设置编码格式
- content = data.text#将对网站访问的信息保存在content变量中
- print(content)
上述代码为最最最简单的爬虫,稍微学过的小伙伴看起来会很容易,这里不过多讲解。
我们将变量content打印出来看看,并且搜索任意一本书的内容,发现可以搜索到,这就说明网页是静态的,如果搜索不到,则说明是动态的。如下图
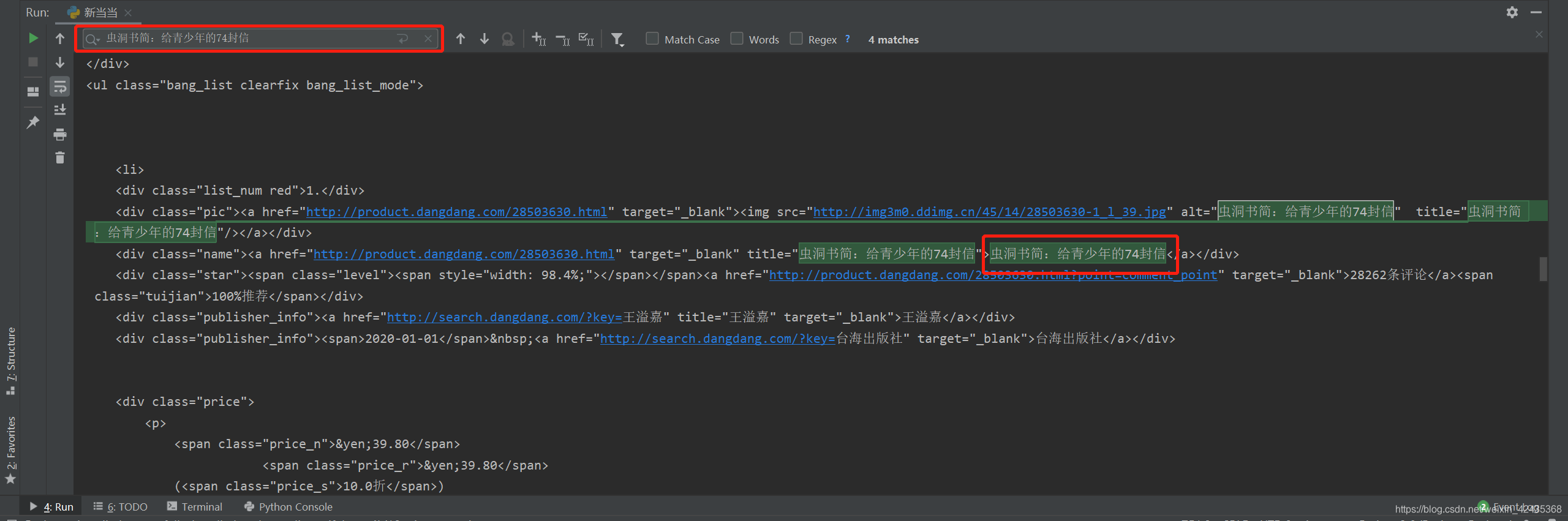
在爬取的网页信息内,可以找到页面上的数据。
针对静态网页,利用python中的requests,re库即可,如果需要生成excel表格,需要导入xlwings
另外大家也可以学习一下BeautifulSoup,它可以解析网页结构,更好地对数据进行抓取。
本文使用requests、re、xlwings三个库
我们先打印一页内容看看,找找数据都在什么位置,打开浏览器的F12,单击左上角的箭头,点击到图书的地方,这需要我们对html结构有所了解,不然到这里就一脸懵
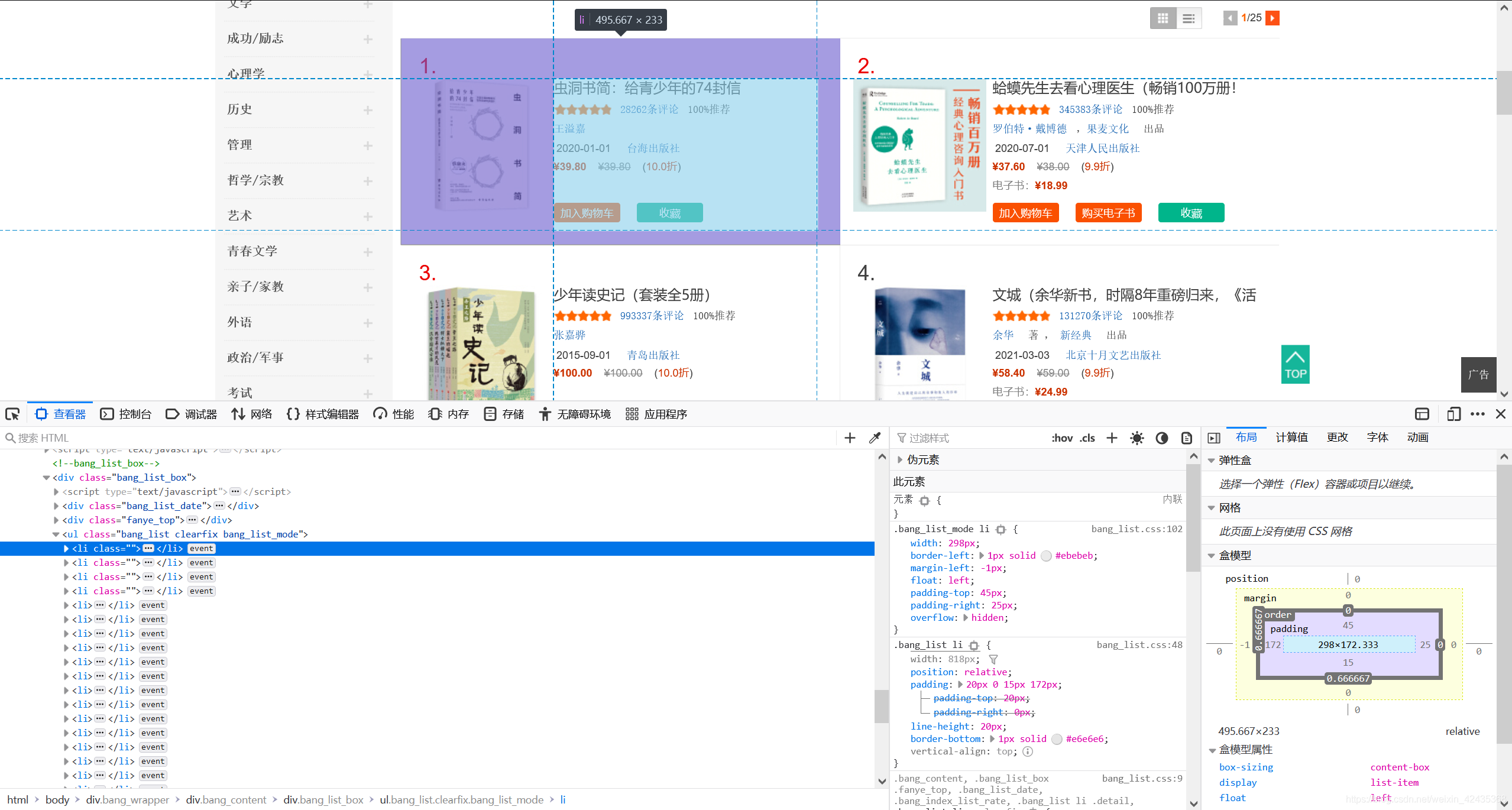
我们发现每个图书都是在class = ’bang_list clearfix bang_list_mode‘的ul标签下,并且每个图书块都在li标签中,我们打开一个li标签进行分析
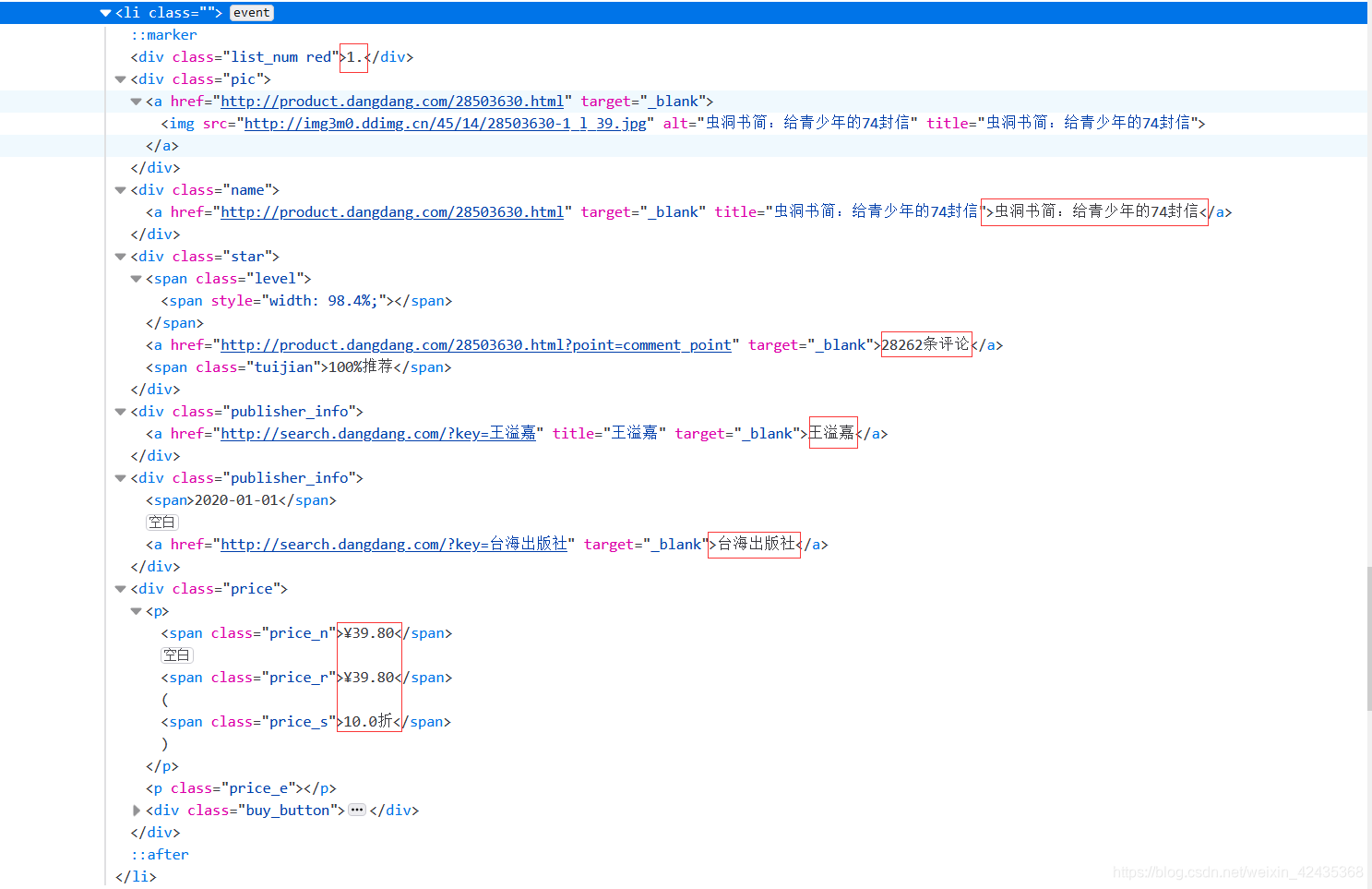
可以发现所有的页面信息都可以在这些代码中找到,我们爬虫爬取的信息也是这些东西
接下来我们需要将这些东西挑出来,这时候就需要我们使用re模块,正则表达式,它能够按照一定的规则匹配字符串,读者可以自行学习这部分
我们以图书名称为例,使用re模块主要使用其中的findall函数,该函数必须设置两个参数,第一个是匹配规则,第二个是需要匹配的字符串,并以列表的形式返回
![]()
我们观察到书名的html都是这样的,我们匹配红圈里的文字,编写规则设定一个变量p_name
- p_name = '<div class="name"><a href=".*?" target="_blank" title=".*?">(.*?)</a></div>'
- dataset['图书名称'] = re.findall(p_name,content)
p_name中的.*?表示任意内容,而加上 括号(.*?)则会被提取出来
dataset['图书名称']是列表,里面保存着提取出来的信息
findall函数中,p_name为第一个参数,content为第二个参数

上图是匹配的结果,存在两个问题,第一,有的字符串匹配出来<span class='dot'>...</span>,需要删除;第二有的书名太长,建议把左括号(后的内容删除,下面我们可以利用for循环解决此问题
我们发现每一个有<span class='dot'>...</span>的字符串都是在左括号(后 或者 冒号:后,所以我们将( 或者:前的内容提取出来, 就可以同时解决存在<span class='dot'>...</span>和书名太长两个问题
- for i in book_name:
- if '(' in i:
- i = re.findall('(.*?)(',i)#提取中文左括号前的内容
- if ':' in i:
- i = re.findall('(.*?):',i)#提取冒号前的内容
- if '(' in i:
- i = re.findall('(.*?)\(',i)#提取英文左括号前的内容
- i = ''.join(i)#将列表转变为字符串
- i = '《' + i + '》'#在字符串前后加上书名号
- dataset['图书名称'].append(i)#将处理后的书名添加到book_name_list中
- print(dataset['图书名称'])
接下来我们看看处理后的书名

可以看到,处理后的书名相比之前,即准确又简洁
此时,字典dataset中图书名称就爬取出来了。
其他的图书排行、图书作者、出版社、出版时间、价钱都可以使用此方法进行数据抓取。这里仅简要介绍
匹配图书排行
- p_num = '<div class="list_num.*?">(.*?).</div>'
- dataset['图书排行'] = re.findall(p_num,content)
- print(dataset['图书排行'])

匹配出版社
- p_publish = '<div class="publisher_info"><span>.*?</span> <a href=".*?" target="_blank">(.*?)</a></div>'
- dataset['出版社'] = re.findall(p_publish,content)
- print(dataset['出版社'])

匹配出版时间
- p_time = '<div class="publisher_info"><span>(.*?)</span> <a href=".*?" target="_blank">.*?</a></div>'
- dataset['出版时间'] = re.findall(p_time,content)
- print(dataset['出版时间'])

匹配现价
- p_price = ''' <span class="price_n">¥(.*?)</span>'''
- dataset['价钱'] = re.findall(p_price,content)
- print(dataset['价钱'])
![]()
匹配作者时,在页面有两种不同的格式,小编想了很久,没法利用正则表达式提取,原因是它会将不同的格式跳过,那小编就没有办法了吗??当然不是,我们还是使用以下BeautifulSoup吧
在代码最前端增加from bs4 import BeautifulSoup

- soup = BeautifulSoup(content,'html.parser')#将content解析,赋予变量soup
- li_list = soup.select('.bang_list li')#与前文中的class = ’bang_list clearfix bang_list_mode‘对应
- for li in li_list:
- '''下面的搜寻方法为BeautifulSoup的匹配规则'''
- try: # 因图书作者存在两种html标签格式,故采try和except方法
- author = li.select('.publisher_info')[0].select('a')[0].text
- except:
- author = li.select('.publisher_info')[0].text
- dataset['图书作者'].append(author)
- print(dataset['图书作者'])

到此我们的dataset中就保存了第一页网页的所有信息,将dataset打印看看

这是第一页的数据,如果获取所有页的数据,对网站进行for循环即可,这里不再叙述
接下来讲述,如何写入excel,代码如下
在代码最前端导入xlwings 即import xlwings as xw 将其简写为xw
- '''将上述内容写入excel'''
- import xlwings as xw
- app = xw.App(visible=False,add_book=False)#启动excel程序,不可见 不新增工作簿
- work_book = app.books.add()#新增工作簿
- work_sheet = work_book.sheets.add('当当网图书畅销榜')#新增名为当当网图书畅销榜的工作表
- work_sheet['A1'].value = '图书排行'#将A1到F1表头填写好
- work_sheet['B1'].value = '图书名称'
- work_sheet['C1'].value = '图书作者'
- work_sheet['D1'].value = '出版社'
- work_sheet['E1'].value = '出版时间'
- work_sheet['F1'].value = '价钱'
- '''以下5行代码是将dataset写入excel的关键 请读者尽量理解'''
- '''利用zip将键名与列数成对提取出来,共6列所以j取值1至6,对每一列共有500个数据,每列第一行已有数据,k取值2至502
- chr(64+j)表示将数字转换为大写字母,因为excel定位单元格需要,例如A1,B2等 '''
- for i,j in zip(dataset.keys(),range(1,7)):
- for k in range(2,502):
- cell = '{}{}'.format(chr(64+j),k)
- work_sheet[cell].value = dataset[i][k-2]
- print('第{}列已完成'.format(j))
-
- work_sheet.autofit()#单元格自适应大小
- work_book.save(r'C:\Users\admin\Desktop\当当网图书销量.xlsx')#保存至桌面
- work_book.close()#关闭工作簿
- app.quit()#退出excel

其中的5行关键代码,为小编想了好久的结晶,自己长时间不看的话也会忘记怎么写出来的,大家尽量理解吧!!
至此对静态网页的爬取(当当) 并进行excel保存就完成了!!!
小编再强调一下,还是非常建议大家使用BeautifulSoup来抓取信息,requests库有时会报错,不能保证每次都成功,而BeautifulSoup目前是可以成功的。
上面主要是利用requests的代码,下面我附上利用BeautifulSoup爬取图书畅销榜的全代码
供大家指出意见和学习!!
- import requests
- from bs4 import BeautifulSoup
- import re
- head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36\
- (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
- dataset = {'图书排行': [], '图书名称': [], '图书作者': [], '出版社': [], '出版时间': [],'价钱': []}
- for i in range(1,26):
- url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-{}'.format(i)
- data = requests.get(url=url,headers=head)
- data.encoding=data.apparent_encoding
- content = data.text
- soup = BeautifulSoup(content,'html.parser')
- li_list = soup.select('.bang_list li')
- for li in li_list:
- a = li.select('.list_num ')[0].text.replace('.','')
- dataset['图书排行'].append(a)
-
- b = li.select('.name')[0].text#因获取到的名称千奇百怪 用正则表达式进行筛选
- if ' (' in b :
- b = re.findall('(\S+) (',b)#正则表达式结果为列表形式 通过join函数连接字符串的形式将其变为字符串格式 列表连接为字符串
- b = (''.join(b))
- elif '(' in b :
- b = re.findall('(\S+)(',b)
- b = (''.join(b))
- if '-' in b:
- b = re.findall('(\S+)-', b)
- b = (''.join(b))
- if '・' in b:
- b = re.findall('(\S+)・', b)
- b = (''.join(b))
- if ',' in b:
- b = re.findall('(\S+),', b)
- b = (''.join(b))
- if ' ' in b:
- b = re.findall('(\S+) ', b)
- b = (''.join(b))
- if '·' in b:
- b = re.findall('(\S+)·')
- b = '《'+b+'》'
- dataset['图书名称'].append(b)
-
- try:#因图书作者存在两种html标签格式,故采用此方法
- c = li.select('.publisher_info')[0].select('a')[0].text
- except:
- c = li.select('.publisher_info')[0].text
- dataset['图书作者'].append(c)
- d = li.select('.publisher_info')[1].select('a')[0].text
- dataset['出版社'].append(d)
- e = li.select('.publisher_info')[1].select('span')[0].text
- dataset['出版时间'].append(e)
- f = li.select('.price_n')[0].text.replace('¥','')
- dataset['价钱'].append(f)
- print('第{}页爬取完成'.format(i))
- '''将上述内容写入excel'''
- import xlwings as xw
- app = xw.App(visible=False,add_book=False)#启动excel程序,不可见 不新增工作簿
- work_book = app.books.add()#新增工作簿
- work_sheet = work_book.sheets.add('当当网图书畅销榜')#新增名为当当网图书畅销榜的工作表
- work_sheet['A1'].value = '图书排行'#将A1到F1表头填写好
- work_sheet['B1'].value = '图书名称'
- work_sheet['C1'].value = '图书作者'
- work_sheet['D1'].value = '出版社'
- work_sheet['E1'].value = '出版时间'
- work_sheet['F1'].value = '价钱'
-
- for i,j in zip(dataset.keys(),range(1,7)):
- for k in range(2,502):
- cell = '{}{}'.format(chr(64+j),k)
- work_sheet[cell].value = dataset[i][k-2]
- print('第{}列已完成'.format(j))
- work_sheet.autofit()
- work_book.save(r'C:\Users\yzb\Desktop\当当网图书销量.xlsx')
- work_book.close()
- app.quit()
最后展示一下效果
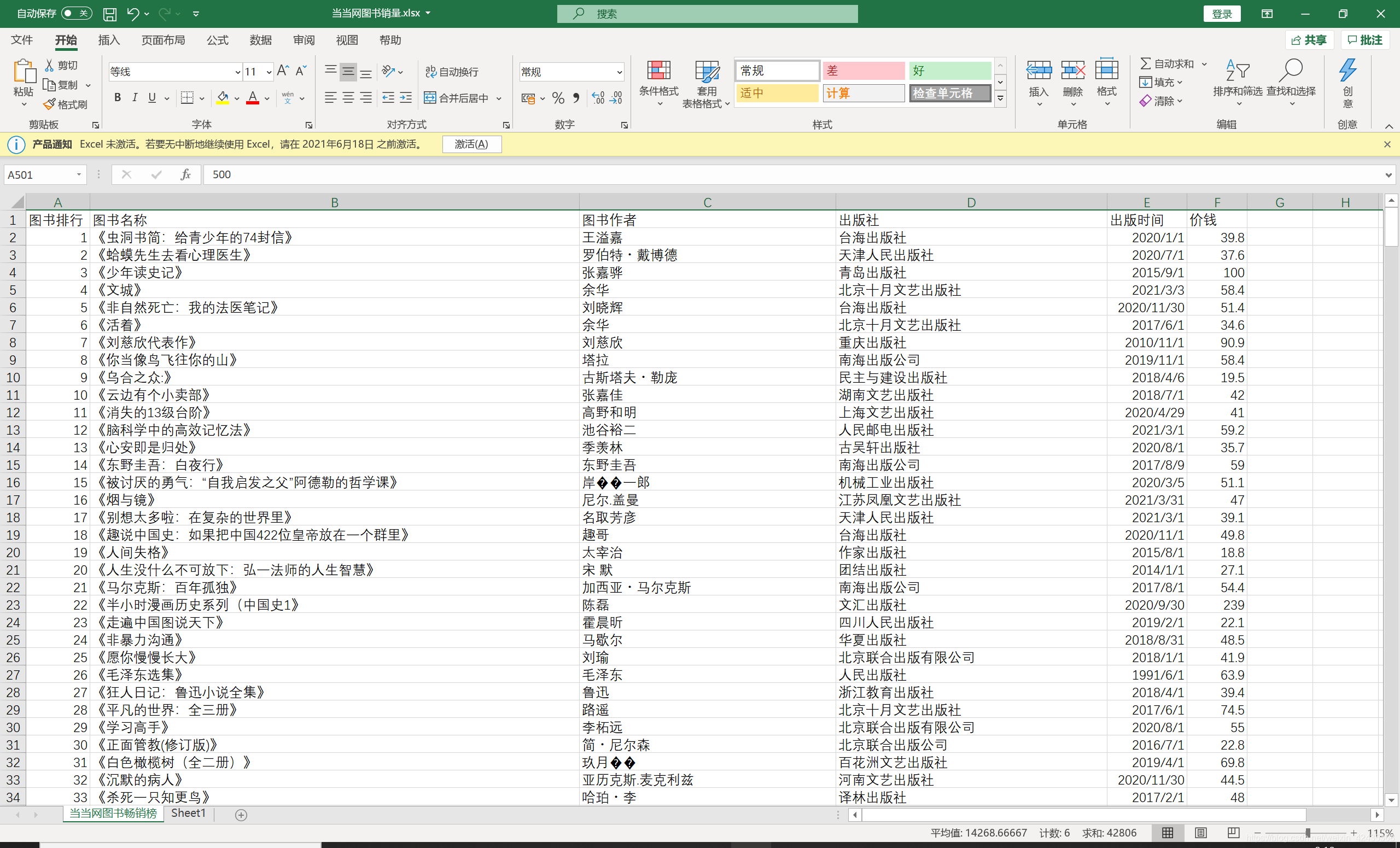
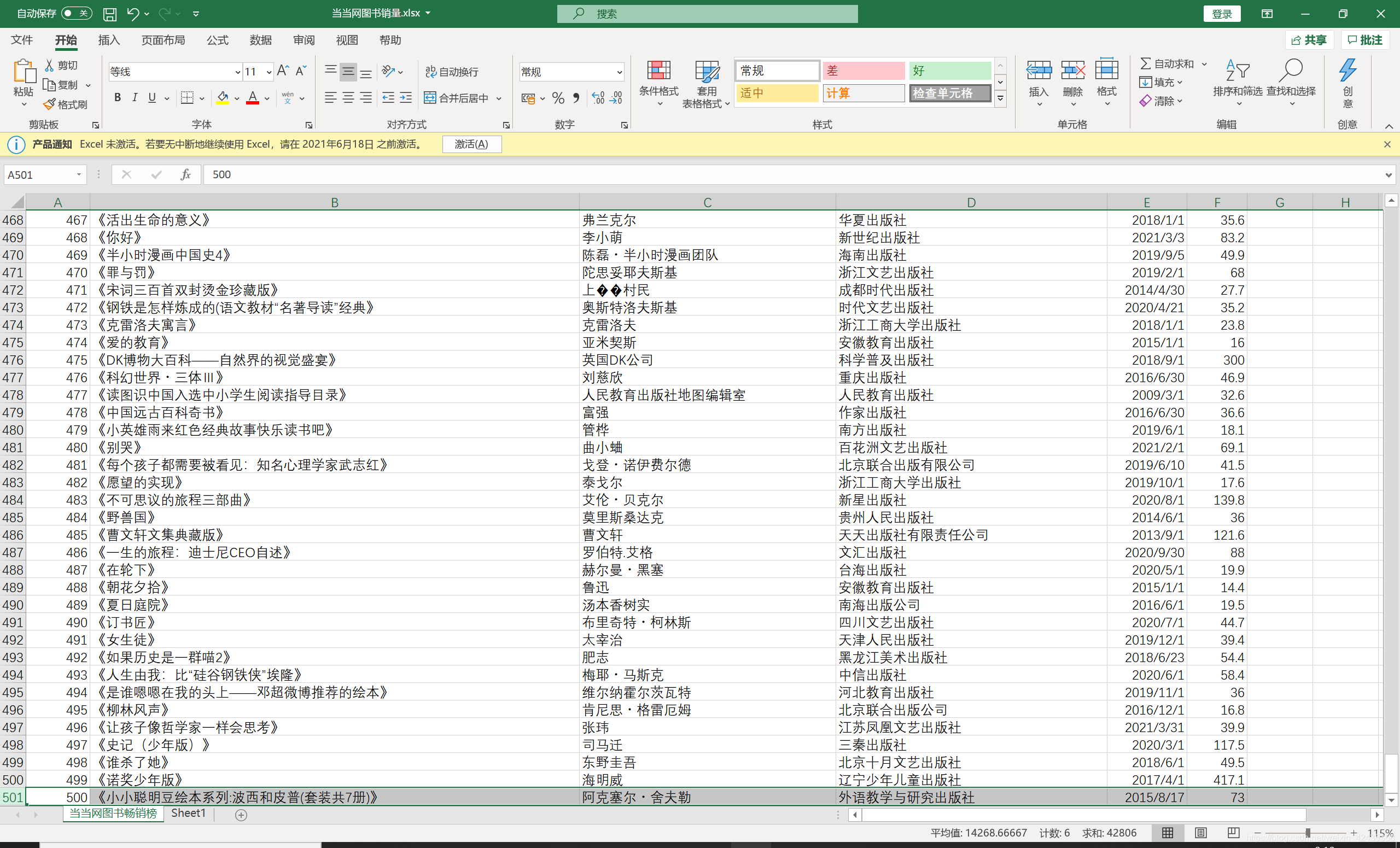
小编留下QQ:1097512301 有兴趣的小伙伴可以一起交流 共同进步

