
- 1产品经理如何基于需求迭代产品(上篇):需求调研的四个步骤_拿到需求到最终这迭代交互完毕的过程
- 2每天学命令
Clock Property - 3目标检测(一)——目标检测综述(持续更新中)_object detection on coco test
- 4【Rust】——项目实例:——命令行实例(一)_rust 项目例子
- 5图像处理与计算机视觉相关的书籍_关于计算机视觉的著作
- 6UltraLight-VM-UNet_ultralight vm-unet
- 7Pycharm编辑器下自定义模块导入报错:no module named问题_python 自定义module no module named
- 8什么是自然语言处理?自然语言处理可以分为四大类?有哪些具体任务?_人工智能自然语言处理的分类
- 9不能“生成代码”的低代码平台,程序员不会用!那能生成可读可改代码的低代码平台你用吗?
- 10MindSpore Transformers套件教程_安装mindformers
TextIn文档解析方案:使用大模型文档问答,我们可以不再长时间等待吗?
赞
踩
最近,“多所高校规范大学生用AI写论文”的词条上了微博热搜。从一个侧面也说明,大模型已经深入高校学术群体的日常使用,成为学术规范方面不能回避的新趋势。对研究者来说,大模型能做的不只是根据指令生成文字,帮学生党完成写作,也能在更多方面充当一个不眠不休、陪伴价值拉满的助手。
以论文工作为例,大模型首先能够帮助快速梳理并总结大量文献,提供关键信息和趋势的概览,节省阅读归纳与整理时间;其次,在处理复杂数据集时,大模型能协助进行数据清洗、分类和模式识别;此外,在知识图谱构建、写作校对等方面,大模型都可以起到不错的辅助作用。而这些工作有一项必要的前提条件,即大模型不仅能对互联网公开信息进行检索归纳,也能有效利用定向给到的专业内容,如文献、专业书籍等材料。
从实际使用者的角度出发,在这个问题上,目前国内多家大模型的能力或许还不够完善。
一、漫长等待,但依旧解析失败
目前国内的头部大模型,笔者基本都试用过。受限于网速与算力,上传专业文档后长时间等待解析与答复生成是大模型们的常见状况,一般来说,短则十几秒,长则数分钟,都是使用过程中的常态。
而且,当文献材料里出现一些扫描档产业材料、专业书的时候,经常会超出大模型的文档大小限制,甚或是解析失败。
以一份产业合同为例,上传后等待大约1分钟,大模型显示解析失败。
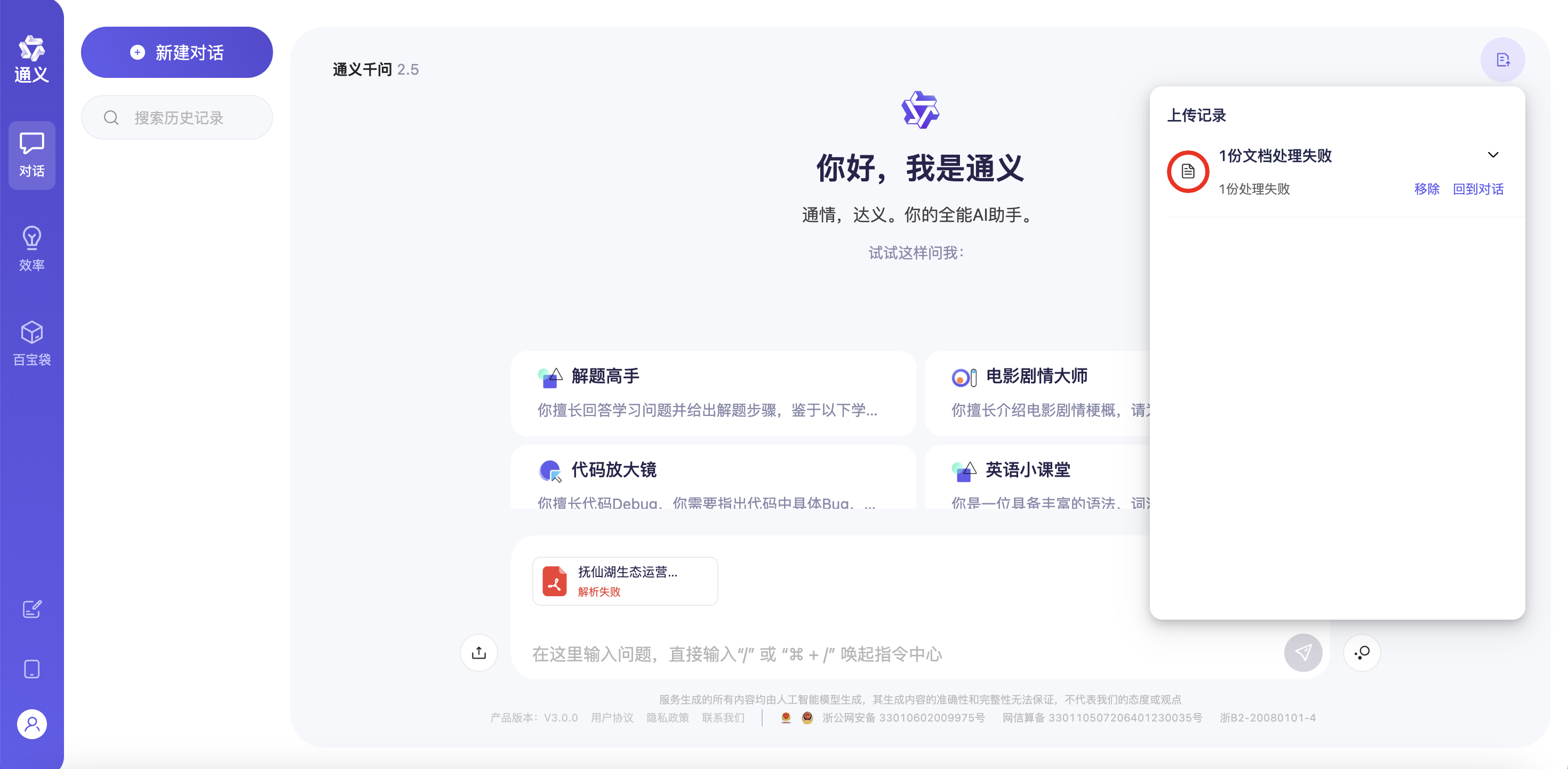
合同文件为扫描版,内容示例如下图。

在实际使用中,各家大模型在长文档方面的表现究竟如何呢?出于这样的好奇,针对长文档解析时间长、成功率不稳定的问题,笔者对市面上常用的几家大模型进行了测试。
二、来个测评:大模型长文档解析哪家强
本次测评选择了三款常用大模型。笔者准备了以下几类文档:100页电子档、200页电子档、100页扫描档、200页扫描档,其中每类文件各3个样本。
测试方案介绍
识别速度:在体验文档解析功能的过程中,笔者这几个大模型用网络监控来计算时间的方法都不够准确或无法使用,因此,本次关于识别速度的测试采用实时计时的方法。
A
选择好插件后就可以上传文档,上传中会在输入框有动效提示正在上传,上传完成后,手动点击发送,会在聊天框显示“开始文档解析”,完成后会显示“文档解析完成”。
 |  |  |  |
|
| (单位/s) | 100页 | 200页 | ||||
| 电子档 | 样本1 | 样本2 | 样本3 | 样本1 | 样本2 | 样本3 |
| 上传时间 | 6.017 | 2.733 | 3.811 | 超出文件大小限制 | 超出文件大小限制 | 超出文件大小限制 |
| 解析时间 | 7.85 | 5.499 | 7.65 | \ | \ | \ |
| 总计 | 13.867 | 8.232 | 11.461 | \ | \ | \ |
| (单位/s) | 100页 | 200页 | ||||
| 扫描档 | 样本1 | 样本2 | 样本3 | 样本1 | 样本2 | 样本3 |
| 上传时间 | 超出文件大小限制 | 超出文件大小限制 | 1.7 | 超出文件大小限制 | 超出文件大小限制 | 6.2 |
| 解析时间 | \ | \ | ❌ | \ | \ | ❌ |
| 总计 | \ | \ | \ | \ | \ | \ |
(❌:解析出现错误)
B
可以通过输入框左边的按钮选择文档直接上传,开始后会出现“正在上传”,“正在提交解析中”,“正在解析中”三种状态,完成后会展示文件类型和大小。
|
|
|
|
|
|

| (单位/s) | 100页 | 200页 | ||||
| 电子档 | 样本1 | 样本2 | 样本3 | 样本1 | 样本2 | 样本3 |
| 上传时间 | 6.217 | 2.4 | 3.45 | 10.8 | 7.7 | 11.4 |
| 解析时间 | 9.299 | 5.15 | 4.85 | 7.45 | 9.95 | 7.567 |
| 总计 | 15.516 | 7.55 | 8.3 | 18.25 | 17.65 | 18.967 |
| (单位/s) | 100页 | 200页 | ||||
| 扫描档 | 样本1 | 样本2 | 样本3 | 样本1 | 样本2 | 样本3 |
| 上传时间 | 13.649 | 10.75 | 1.75 | 17.117 | 6.916 | 4.65 |
| 解析时间 | ❌ | 7.667 | 4.849 | ❌ | ❌ | ❌ |
| 总计 | \ | 18.417 | 6.599 | \ | \ | \ |
(❌:解析出现错误)
C
可以点击输入框下方的文档按钮直接上传文件,过程中会显示“上传中”和“解析中”两种状态,完成后会展示文件的类型和大小。
|
|
|
|
|
| (单位/s) | 100页 | 200页 | ||||
| 电子档 | 样本1 | 样本2 | 样本3 | 样本1 | 样本2 | 样本3 |
| 上传时间 | 5.917 | 1.65 | 2.9 | 9.449 | 6.25 | 9.95 |
| 解析时间 | 6.999 | 13.316 | 6.85 | 5.883 | 5.8 | 5.95 |
| 总计 | 12.916 | 14.966 | 9.75 | 15.332 | 12.05 | 15.9 |
| (单位/s) | 100页 | 200页 | ||||
| 扫描档 | 样本1 | 样本2 | 样本3 | 样本1 | 样本2 | 样本3 |
| 上传时间 | 20.249 | 9.75 | 1.05 | 16.1 | 6.917 | 5.1 |
| 解析时间 | 74.899 | 6.75 | 4.967 | 35.949 | 89.377 | 48.266 |
| 总计 | 95.148 | 16.5 | 6.017 | 52.049 | 96.294 | 53.366 |
总体而言,大模型C的长文档解析能力相对具有优势,但如果遇到文档较大或版式复杂的扫描文件,也经常出现长达一分钟以上的解析时间。
那有没有能提升解析效率的方式呢?
三、有效外挂:专业文档解析工具
传统的PDF解析工具一般采用两种方式的结合:第一,如PyPDF等PDF提取解析库,对复杂版面、图表的解析能力较差,同时无法应对扫描版文件;第二,采用OCR技术加强识别能力,能正确获取扫描档信息,但一方面,OCR耗时较长,另一方面,它无法按人类阅读顺序(同样也是大模型阅读顺序)进行还原。
所以,要提升大模型应用的效率,我们需要的是一款LLM友好的专业文档解析工具。
它需要具有以下特点:首先,要有C端体验良好的解析速度;其次,对复杂版面、表格、图片都要有表现较好的识别能力;此外,还需要兼容各类PDF编码格式,并通过适合LLM处理的格式输出信息。
基于以上要求,笔者找到了一款适用的大模型“外挂”道具:合合信息的TextIn文档解析产品。综合评估其识别效率和准确度,均能实现令人满意的效果。
我们先来看一下它的解析速度。调用API接口,将与先前同样的测试文档上传解析,和大模型上传解析速度相比,提速至少在2倍以上。在某些扫描长文档测试中,速度差异甚至达到19倍。
| (单位/s) | 100页 | 200页 | ||||
| 电子档 | 样本1 | 样本2 | 样本3 | 样本1 | 样本2 | 样本3 |
| 上传时间 | 4.333 | 4.428 | 4.021 | 5.295 | 4.407 | 5.913 |
| 解析时间 | 1.127 | 1.147 | 1.213 | 2.251 | 2.351 | 2.257 |
| 总计 | 5.460 | 5.575 | 5.234 | 7.546 | 6.758 | 8.170 |
| (单位/s) | 100页 | 200页 | ||||
| 扫描档 | 样本1 | 样本2 | 样本3 | 样本1 | 样本2 | 样本3 |
| 上传时间 | 3.693 | 4.771 | 3.488 | 12.044 | 11.122 | 9.184 |
| 解析时间 | 1.291 | 1.006 | 1.075 | 1.921 | 1.962 | 1.957 |
| 总计 | 4.984 | 5.777 | 4.563 | 13.965 | 13.084 | 11.141 |
此前大模型解析失败的案例,通过TextIn文档解析也可以迅速输出Markdown格式文件。

将Markdown格式文件再次输入给大模型,尝试提问,这一次大模型清晰地给出了正确答案。
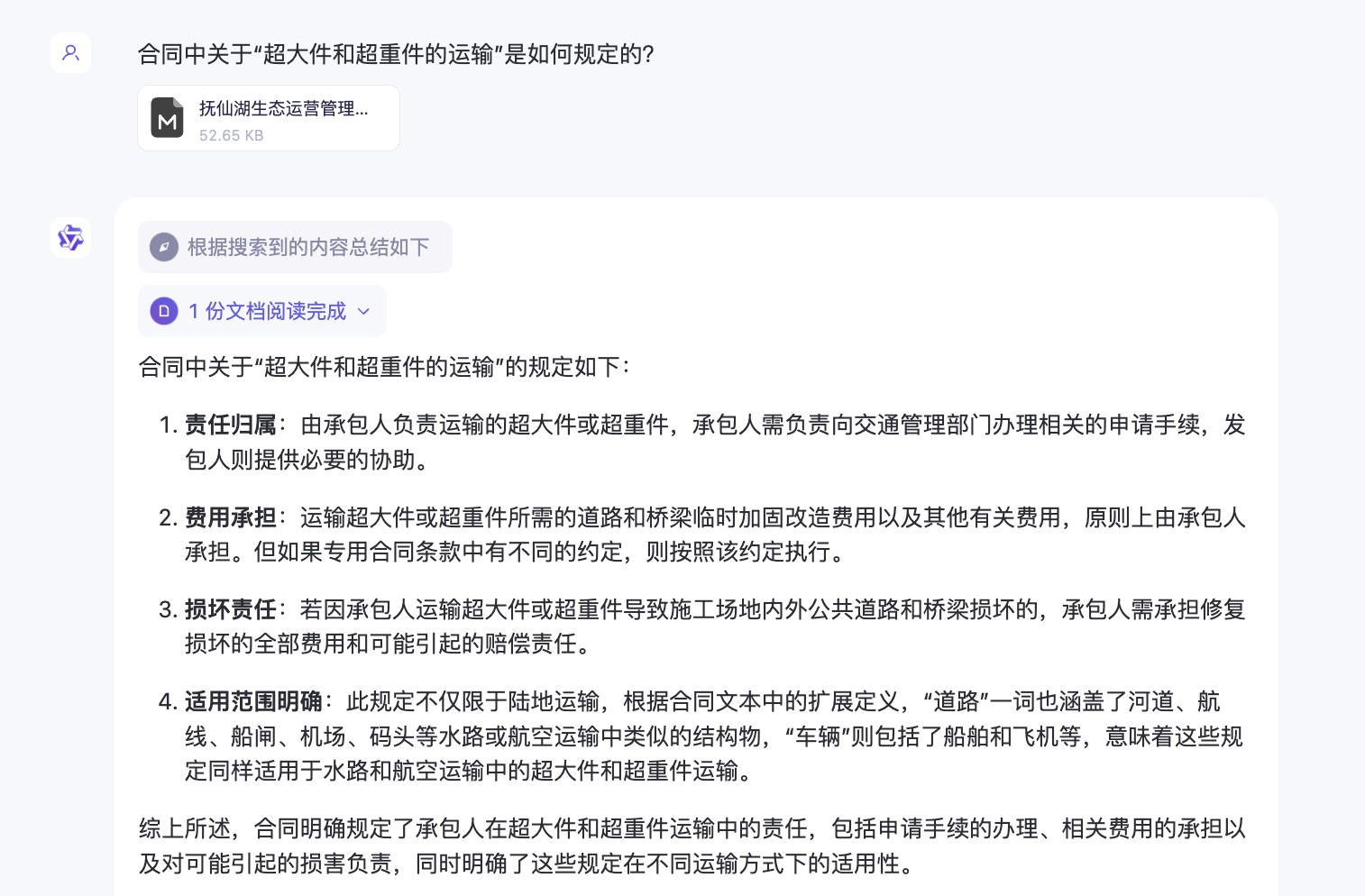
可见,在专业或学术领域的大模型使用中,优秀的文档解析工具可以作为一个相当有效的“外挂”。
四、一键开启“外挂”模式
目前TextIn文档解析工具的使用路径相当简单便捷。
产品官网链接:https://www.textin.com/market/detail/pdf_to_markdown
在TextIn平台注册账号,点击页面上的“免费体验”即可使用。

如果是更专业的开发小伙伴,也可以根据对应的接口文档内容进行代码调用:
https://www.textin.com/document/pdf_to_markdown
笔者加入了TextIn的用户交流群,了解到现在产品现在还在内测阶段,向用户赠送每周7000页的额度福利,有需要的可以在官网进入社群或公众号“合研社”领取。
希望大家都能找到合用的工具,让AI高效辅助工作,在AI时代玩转大模型。

