
热门标签
热门文章
- 1AI创作音乐引发的深思
- 2Flutter通过flutter_unity_widget嵌入Unity3D_flutter加载3d模型
- 3聊聊常见的分布式ID解决方案
- 4Apache配置与应用与日志管理_apache yingyongrizhi
- 5springboot导出word文档_springboot 导出word
- 6网络安全等级基本要求-安全通用要求的内容_简述安全通用要求
- 7最新最全 VSCODE 插件推荐(2024版)_vscode主题插件
- 8【AAAI 2021】全部接受论文列表(六)_decentralized policy gradient descent ascent for s
- 9Camunda快速入门(二):设计并执行第一个BPMN流程_camunda前端绘制流程图保存
- 10leetcode刷题记录:hot100强化训练2:二叉树+图论_hot100题解二叉树
当前位置: article > 正文
大数据平台实时数仓从0到1搭建之 - 10 阶段回顾_数仓搭建的进度
作者:知新_RL | 2024-07-16 04:02:24
赞
踩
数仓搭建的进度
概述
截止Flink安装完成,其实一个简单的架构已经可以用了,这里整理下现在集群上安装的各种服务
jpsall 目前所有进程
jpsall,展示出目前三台节点上所有的java进程
[root@server110 opt]# ./jpsall.sh ----------------jps server110 -------------------- 31744 QuorumPeerMain 32420 Jps 32182 Kafka 17387 NameNode 17916 NodeManager 17549 DataNode ----------------jps server111 -------------------- 17265 DataNode 1201 Jps 17540 NodeManager 532 QuorumPeerMain 17383 ResourceManager 18029 JobHistoryServer 975 Kafka ----------------jps server112 -------------------- 26338 QuorumPeerMain 26995 Jps 17207 DataNode 17289 SecondaryNameNode 26765 Kafka 17407 NodeManager

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
整体架构
| server110 | server111 | server112 | |
|---|---|---|---|
| Flink | JobManager TaskManager | TaskManager | TaskManager |
| kafka | broker.id.0 | broker.id.1 | broker.id.2 |
| zookeeper | zk.1 | zk.2 | zk.3 |
| hive | client | client | client |
| mariadb | mysql | ||
| HistoryServer | JobHistoryServer | ||
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
hdfs,做最底层的数据存储
yarn,做资源调度
JobHistoryServer记录job日志
mariadb为hive的资源库
hive作为离线数据存储的主要入口
zk支持kafka
kafka用来暂存实时数据
Flink 做实时计算
按下图的流程看来,还缺少数据采集部分和数据服务层部分
数据采集层:要求多数据源,实时监听数据变化,有待完善
数据服务层:要求快速响应,可操作数据,这部分使用Mysql和Hbase比较合适
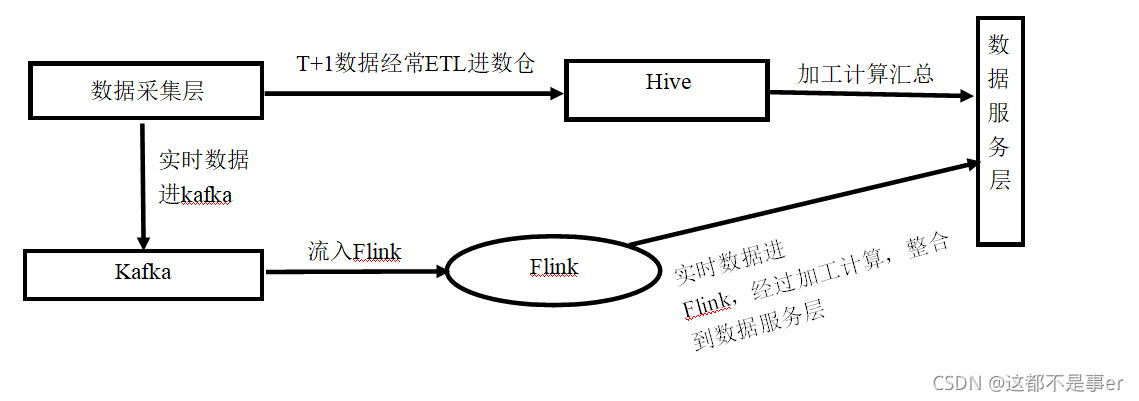
数据采集这部分,还希望路过的大佬可以给个思路。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/832225
推荐阅读
相关标签

