
神经网络模型u-net 、VGG_vggu
赞
踩
【理论】 神经网络模型u-net 、VGG
2019下第13周
一、人脑视觉处理机理人脑视觉机理
1981 年的诺贝尔医学奖,颁发给了 David Hubel(出生于加拿大的美国神经生物学家) 和TorstenWiesel,以及 Roger Sperry。前两位的主要贡献,是“发现了视觉系统的信息处理”:可视皮层是分级的:
- 1
我们看看他们做了什么。1958 年,DavidHubel 和Torsten Wiesel 在 JohnHopkins University,研究瞳孔区域与大脑皮层神经元的对应关系。他们在猫的后脑头骨上,开了一个3 毫米的小洞,向洞里插入电极,测量神经元的活跃程度。
然后,他们在小猫的眼前,展现各种形状、各种亮度的物体。并且,在展现每一件物体时,还改变物体放置的位置和角度。他们期望通过这个办法,让小猫瞳孔感受不同类型、不同强弱的刺激。
之所以做这个试验,目的是去证明一个猜测。位于后脑皮层的不同视觉神经元,与瞳孔所受刺激之间,存在某种对应关系。一旦瞳孔受到某一种刺激,后脑皮层的某一部分神经元就会活跃。经历了很多天反复的枯燥的试验,同时牺牲了若干只可怜的小猫,David Hubel 和Torsten Wiesel 发现了一种被称为
**方向选择性细胞(Orientation Selective Cell)”的神经元细胞。当瞳孔发现了眼前的物体的边缘,而且这个边缘指向某个方向时,这种神经元细胞就会活跃**
这个发现激发了人们对于神经系统的进一步思考。神经-中枢-大脑的工作过程,或许是一个不断迭代、不断抽象的过程。
这里的关键词有两个,一个是抽象,一个是迭代。从原始信号,做低级抽象,逐渐向高级抽象迭代。人类的逻辑思维,经常使用高度抽象的概念。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
二、U-net网络
1.定义
分割网络:U-Net:生物医学图像分割的卷积神经网络——U-Net: Convolutional Networks for Biomedical Image Segmentation
U-net 是基于FCN的一个语义分割网络,适合用来做医学图像的分割。
U-net是基于全卷积网络拓展和修改而来, 用于获得图像的边缘 。 一种编码器-解码器结构。编码器逐渐减少池化层的空间维度,解码器逐步修复物体的细节和空间维度。编码器和解码器之间通常存在快捷连接,因此能帮助解码器更好地修复目标的细节 。
编码解码结构
编解码结构提出的主要作用并不是分割,而是压缩图像和去噪声。输入是一幅图,经过下采样的编码,得到一串比原先图像更小的特征,相当于压缩,然后再经过一个解码,理想状况就是能还原到原来的图像。这样的话我们存一幅图的时候就只需要存一个特征和一个解码器即可。
上采样、下采样、长连接
上采样的特征:
升采样的最大的作用其实就是把抽象的特征再还原解码到原图的尺寸,最终得到分割结果
下采样的特征:
进行特征的提取,提取图像的位置、语义等信息
长连接:
U-Net中的长连接是有必要的,它联系了输入图像的很多信息,有助于还原降采样所带来的信息损失
2.构成
1.收缩部分(contracting path) 来获取上下文信息
收缩部分主要由典型的卷积网络组成,包括的unpadded的双层33卷积层,紧跟一个激活函数relu,以及22的最大池化层(步长为2)用于降采样;每次降采样后增加特征图数量为原来2倍;
2.扩展部分(expanding path)用以精确定位
每一步扩展部分包括使用一个2*2的“up-convolution”进行升采样,并会将特征图数量减半
3.网络结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8kKgaeLN-1574509666253)(F:\picture\unet.png)]
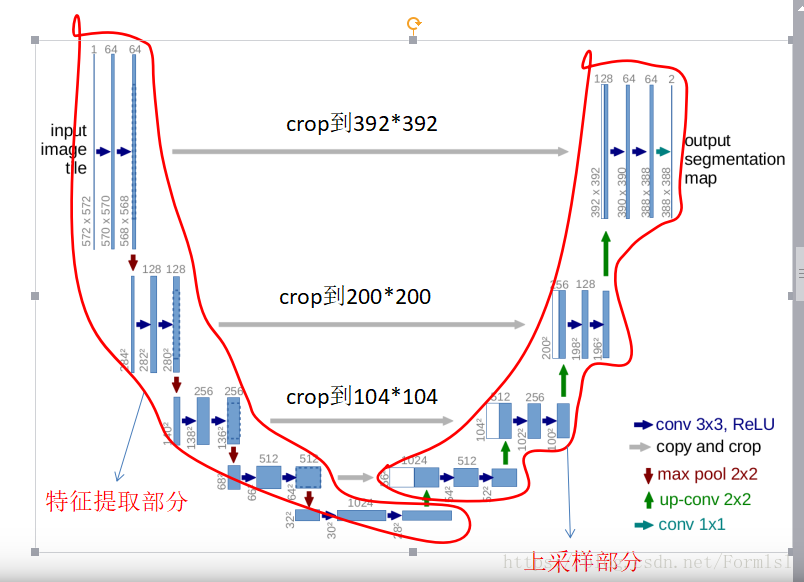
Fig.1为Olaf Ronneberger等人构建的u-net网络结构,整个模型因呈现“U”型,固因此得名。
整个网络有19次卷积操作,4次池化操作,4次上采样操作,4次裁剪和复制操作。卷积层使用的是“valid ,padding=0, stride=1”的模式进行卷积,所以最终得到的输出图像要小于原始图像。若想得到与原图像同样尺寸的输出图像,可以在卷积操作,时使用“same”模式。
用U-net分割眼底视网膜血管结果

参考链接:https://blog.csdn.net/TDhuso/article/details/79948494
4.优点
支持少量的数据训练模型
通过对每个像素点进行分类,获得更高的分割准确率
用训练好的模型分割图像,速度快
5.局限性
- 输入图像和输出图像大小并不一致。 由于采用nopadding的卷积层,每次卷积图像都会小一圈,所以downsample和upsample所还原的像素并不一致。(一般会采用加上padding方式来使图像size不变)
6.应用
语义分割需要判断图像每个像素点的类别,进行精确分割。语义分割目前在自动驾驶、自动抠图等领域有着比较广泛的应用
7.特点
U-net采用了完全不同的特征融合方式:拼接,U-net采用将特征在channel维度拼接在一起,形成更厚的特征。
FCN融合时使用的对应点相加,并不形成更厚的特征。
所以语义分割网络在特征融合时有两种办法:
-
FCN式的对应点相加,对应于TensorFlow中的tf.add()函数;
-
U-net式的channel维度拼接融合,对应于TensorFlow的tf.concat()函数,比较占显存。
参考链接:https://blog.csdn.net/wangdongwei0/article/details/82393275
三、VGG网络模型
1.定义
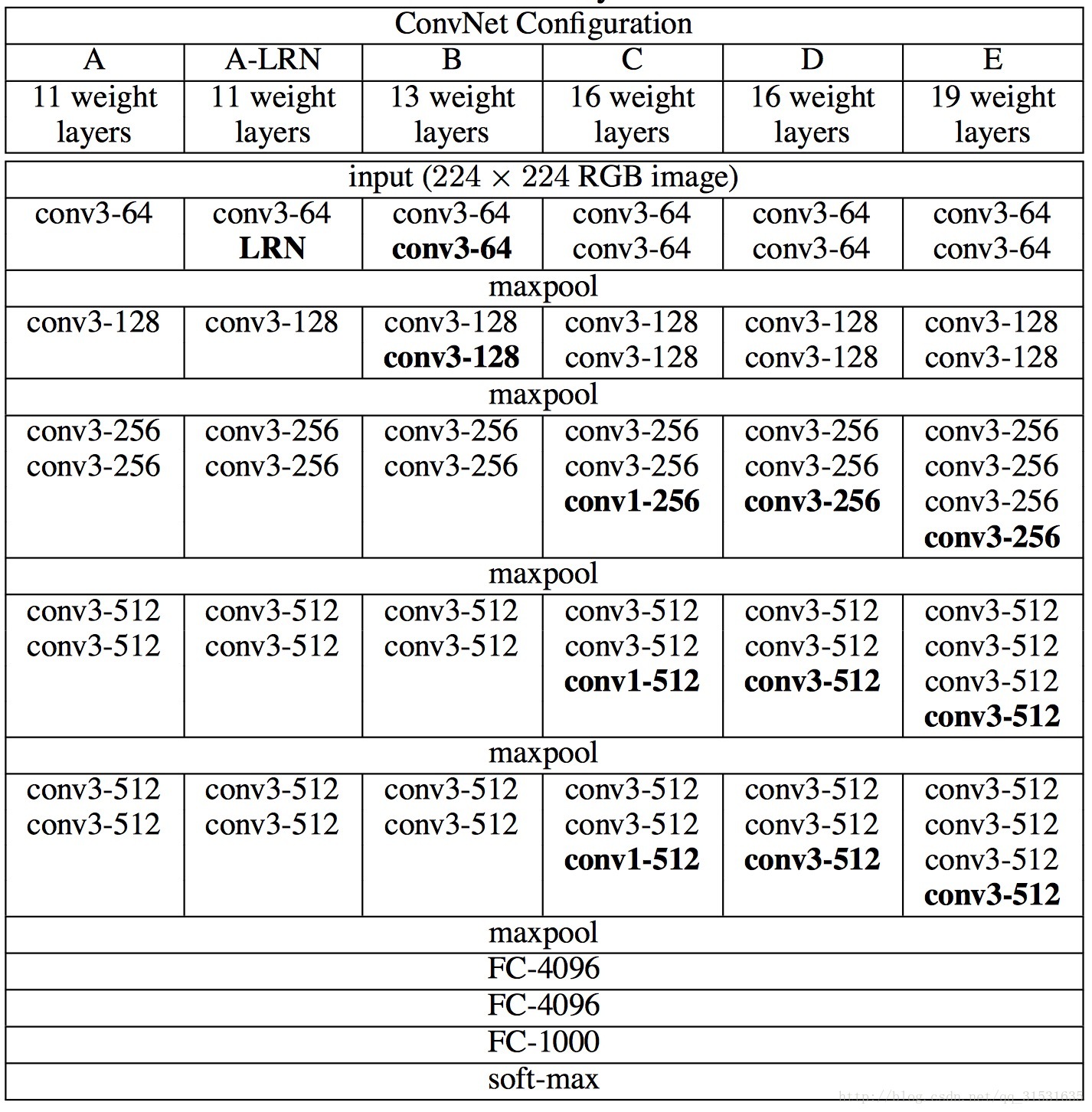
2网络结构
VGGNet包含很多级别的网络,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。
VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。

3.一些技巧
多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征 唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
在训练高级别的网络时,可以先训练低级别的网络,用前者获得的权重初始化高级别的网络,可以加速网络的收敛.
4.贡献
通过增加网络深度并且使用非常小的卷积核对网络效果有很大的改善 。它探索了卷积神经网络的深度和其性能之间的关系,通过反复的堆叠33的小型卷积核和22的最大池化层,成功的构建了16~19层深的卷积神经网络。
1.LRN(局部响应归一化)层无性能增益(A-LRN)
VGG作者通过网络A-LRN发现,AlexNet曾经用到的LRN层(local response normalization,局部响应归一化)并没有带来性能的提升,因此在其它组的网络中均没再出现LRN层。
- 1
2、随着深度增加,分类性能逐渐提高(A、B、C、D、E)
从11层的A到19层的E,网络深度增加对top1和top5的错误率下降很明显。
3、多个小卷积核比单个大卷积核性能好(B)
VGG作者做了实验用B和自己一个不在实验组里的较浅网络比较,较浅网络用conv5x5来代替B的两个conv3x3,结果显示多个小卷积核比单个大卷积核效果要好。
5缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。共三个全连接层。
6.SUMMARY PIPELINE(流水线)
GoogLeNet和VGG的Classification模型从原理上并没有与传统的CNN模型有太大不同。大家所用的Pipeline也都是:训练时候:各种数据Augmentation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Augmenting后在训练的不同模型上的结果再继续Averaging出最后的结果。”
ntation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Augmenting后在训练的不同模型上的结果再继续Averaging出最后的结果。”

