
- 1字节跳动安全工程师校招一面面经_字节跳动技术支持安全岗面试
- 2LLM推理部署(五):AirLLM使用4G显存即可在70B大模型上进行推理_airllm 部署
- 3在有向图中找出所有简单环--Johnson算法_有向图找环
- 4计算机体系结构——虚拟内存技术_虚拟存储技术
- 5java基础之数据类型_java,nextdouble什么意思
- 6从零开始:构建高效的 JMeter 集群压测环境
- 7MySQL英语不好能学吗_英语不好,我能学好编程语言吗
- 8使用NodeJs模拟接口联调_nodejs请求第三方接口
- 9signature=1a4f4cc2a4cb36682d90c0d4c84ca5da,dweb-mirror/yarn.lock at master · internetarchive/dweb-mi...
- 10com.netflix.discovery.DiscoveryClient - DiscoveryClient_UNKNOWN/_com.netflix.discovery.discoveryclient : discoveryc
YOLOv5 vs YOLOv8_yolov5和yolov8
赞
踩
1 概述
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本。
https://github.com/ultralytics/yolov5
https://github.com/ultralytics/ultralytics
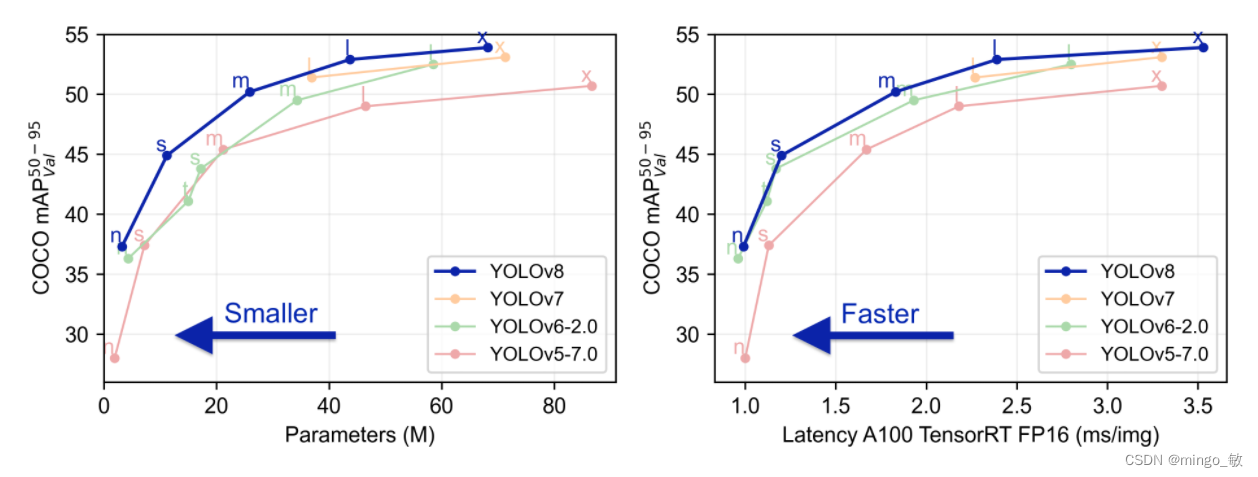
2 网络结构
YOLOv5 N/S/M/L/X 骨干网络的通道数设置使用同一套缩放系数;
YOLOv8 N/S/M/L/X 骨干网络的通道数设置不一样,使用不同的缩放系数。YOLOv7 网络设计也采用类似的方式作用于所有模型。
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
YOLOv5:

YOLOv8:

2-1 Backbone
a) 第一个卷积层的 kernel 从 6x6 变成了 3x3
b) 所有的 C3 结构换成了梯度流更丰富的 C2f 结构, C2f 比 C3 多了更多的跳层连接和额外的 Split 操作
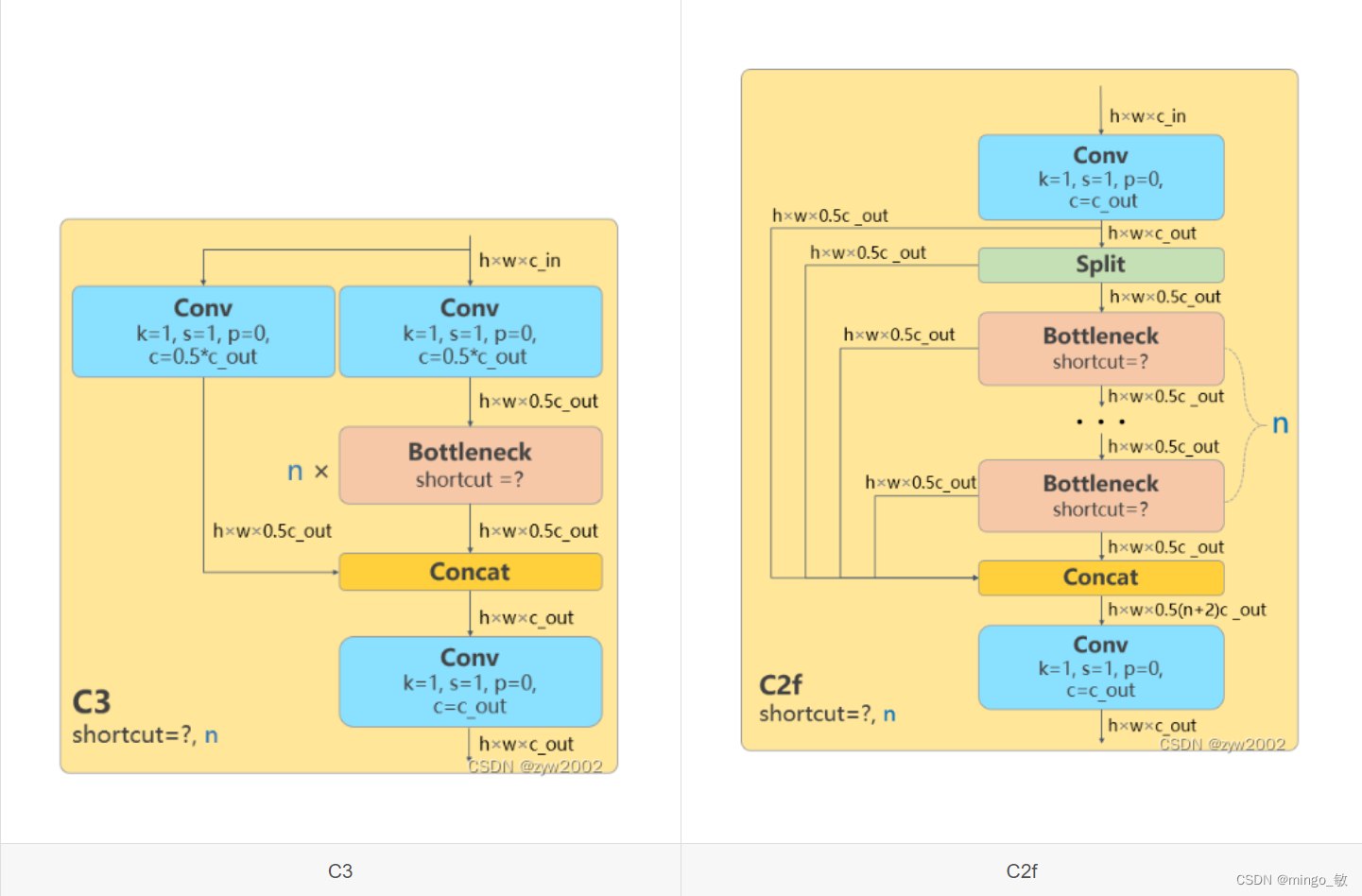
c) Backbone 中 C2f 的 block 数从 3-6-9-3 改成了 3-6-6-3
2-2 Neck
a) 所有的 C3 结构换成了梯度流更丰富的 C2f 结构, C2f 比 C3 多了更多的跳层连接和额外的 Split 操作
b) 去掉了 Neck 模块中的 2 个卷积连接层
2-3 Head
a)从原先的耦合头变成了解耦头
b) YOLOv5 的 Anchor-Based 变成了 Anchor-Free
c) 回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法
3 Loss
a)正负样本分配策略
YOLOX 使用 simOTA、TOOD 使用 TaskAlignedAssigner 和 RTMDet 使用 DynamicSoftLabelAssigner,
YOLOv5 采用的依然是静态分配策略,YOLOv8 直接使用 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
b) Loss计算
Loss 计算包括 2 个分支: 分类和回归分支,没有了yolov5的 objectness 分支。
分类分支依然采用 BCE Loss;
回归分支 Distribution Focal Loss;同时还使用了 CIoU Loss。
3 个 Loss 采用一定权重比例加权即可。
4 Data augmentation
a) 引入YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作
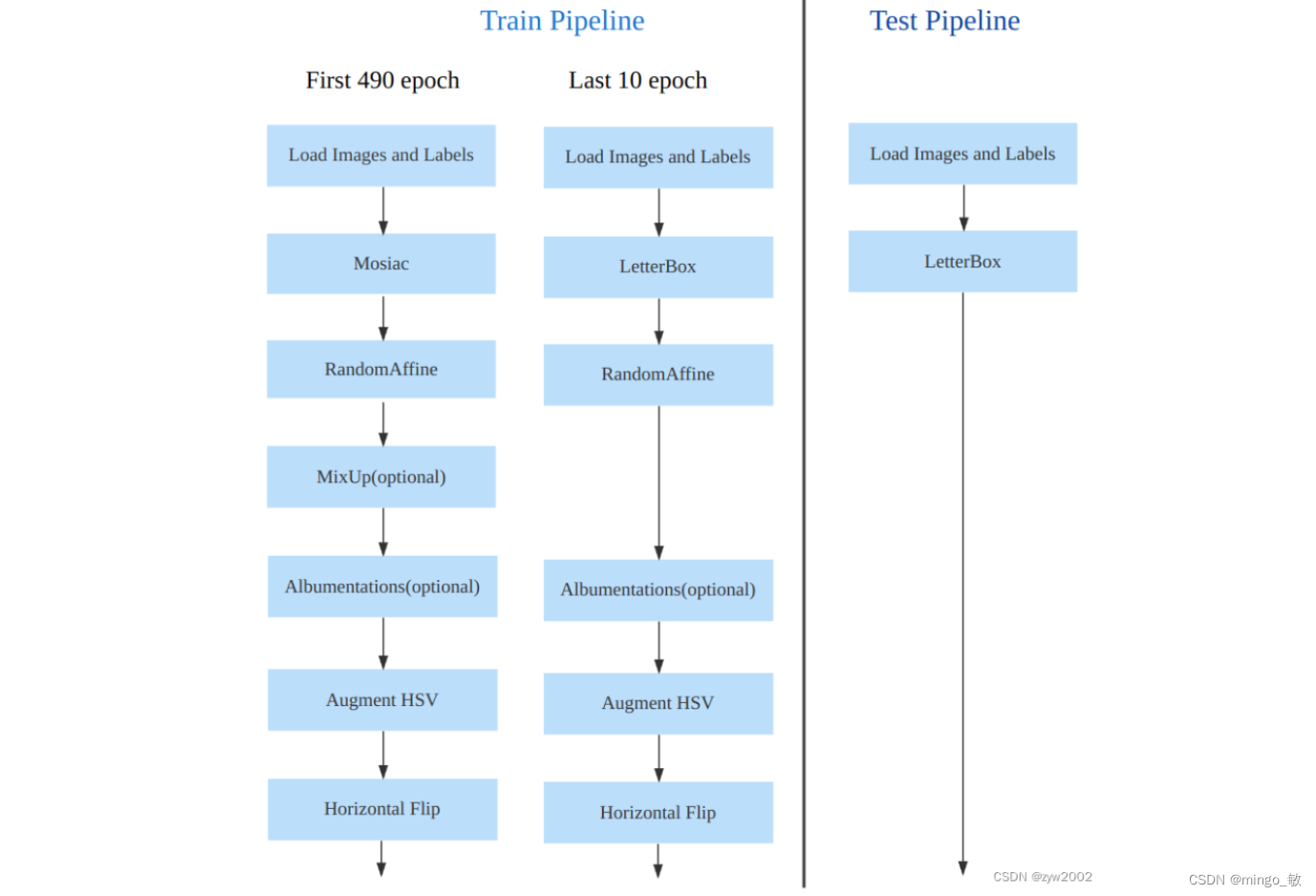
b) 对于不同大小模型,部分超参会进行修改,如大模型会开启 MixUp 和 CopyPaste。
5 Training strategy
a) 训练总 epoch 数从 300 提升到了 500
6 Inference
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox.

yolov8 推理和后处理过程为:
(1) bbox 积分形式转换为 4d bbox 格式
对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式
(2) 维度变换
YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
(3) 解码还原到原图尺度
分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
(4) 阈值过滤
遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。

