
- 119 STM32标准库函数 之 通用定时器(TIM)-- A -- 所有函数的介绍及使用_开启通用定时器的函数
- 2Mybatis基础学习之使用注解开发_mybatis获取java静态属性
- 3小试牛刀-区块链WalletConnect协议数据解密_walletconnect文档
- 4FastAPI Python照片打马赛克API_马赛克拼图api
- 5第八章小程序总结
- 6STM32F1103C8T6综述_stm32f103c8t6rom的多少 csdn
- 7C++相关技术简介_c++ 技
- 8全网最详细【Mac终端改造计划】iTerm2 + Oh My Zsh,阿里内部资料_mac iterm2
- 9详解 | 大型分布式电商系统架构
- 10YOLOv8添加小目标检测层_yolov8增加小目标检测层
创建和探索VGG16模型_models.vgg16
赞
踩
PyTorch在torchvision库中提供了一组训练好的模型。这些模型大多数接受一个称为 pretrained 的参数,当这个参数为True 时,它会下载为ImageNet 分类问题调整好的权重。让我们看一下创建 VGG16模型的代码片段:
- from torchvision import models
- vgg = models.vggl6(pretrained=True)
现在有了所有权重已经预训练好且可马上使用的VGG16模型。当代码第一次运行时,可能需要几分钟,这取决于网络速度。权重的大小可能在500MB左右。我们可以通过打印快速查看下 VGG16模型。当使用现代架构时,理解这些网络的实现方式非常有用。我们来看看这个模型:
- VGG(
- (features): Sequential(
- (0):Conv2d(3,64,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (1):ReLU (inplace)
- (2):Conv2d(64,64,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (3):ReLU(inplace)
- (4):MaxPool2d(size=(2,2),stride=(2,2),dilation=(1,1))
- (5):Conv2d(64,128,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (6):ReLU(inplace)
- (7):Conv2d(128,128,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (8):ReLU(inplace)
- (9):MaxPool2d(size=(2,2),stride=(2,2),dilation=(1,1))
- (10):Conv2d(128,256,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (11):ReLU(inplace)
- (12):Conv2d(256,256,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (13):ReLU(inplace)
- (14):Conv2d(256,256,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (15):ReLU(inplace)
- (16):MaxPool2d(size=(2,2),stride=(2,2)dilation=(1,1))
- (17):Conv2d(256,512,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (18):ReLU(inplace)
- (19):Conv2d(512,512,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (20):ReLU(inplace)
- (21):Conv2d(512,512,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (22):ReLU(inplace)
- (23):MaxPool2d(size=(2,2),stride=(2,2),dilation=(1,1))
- (24):Conv2d(512,512,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (25):ReLU(inplace)
- (26):Conv2d(512,512,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (27):ReLU(inplace)
- (28):Conv2d(512,512,kernel_size=(3,3),stride=(1,1),padding=(1,1))
- (29):ReLU(inplace)
- (30):MaxPool2d(size=(2,2),stride=(2,2),dilation=(1,1))
- )
- (classifier):Sequential(
- (0):Linear(25088>4096)
- (1):ReLU(inplace)
- (2):Dropout(p=0.5)
- (3):Linear(4096->4096)
- (4):ReLU (inplace)
- (5):Dropout(p=0.5)
- (6):Linear(4096>1000)
- )
- )

模型摘要包含了两个序列模型:features和classifiers。features和sequentia1模型包含了将要冻结的层。
冻结层
下面冻结包含卷积块的features模型的所有层。冻结层中的权重将阻止更新这些卷积块的权重。由于模型的权重被训练用来识别许多重要的特征,因而我们的算法从第一个迭代开时就具有了这样的能力。使用最初为不同用例训练的模型权重的能力,被称为迁移学习。现在看一下如何冻结层的权重或参数:
for param in vgg.features.parameters():param.requires_grad = False该代码阻止优化器更新权重。
微调VGG16模型
VGG16模型被训练为针对1000个类别进行分类,但没有训练为针对狗和猫进行分类。因此,需要将最后一层的输出特征从1000改为2。以下代码片段执行此操作:
vgg.classifier[6].out_features = 2vgg.classifier可以访问序列模型中的所有层,第6个元素将包含最后一个层。当训练VGG16模型时,只需要训练分类器参数。因此,我们只将classifier.parameters传入优化器,如下所示:
- optimizer=
- optim.SGD(vgg.classifier.parameters(),lr=0.0001,momentum=0.5)
训练VGG16模型
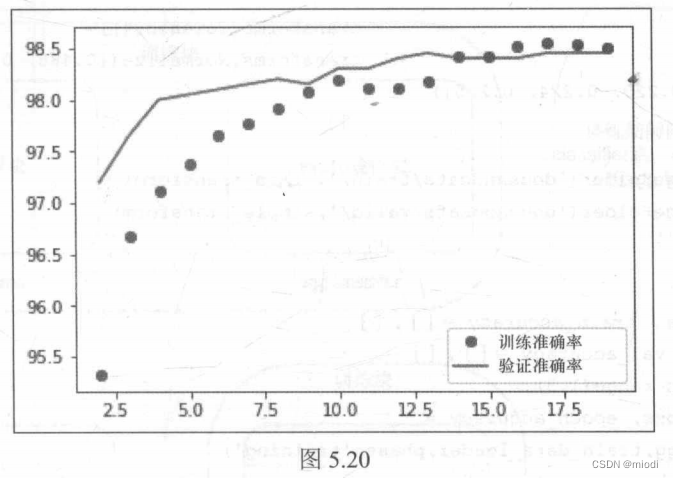
我们已经创建了模型和优化器。由于使用的是Dogs vs. Cats数据集,因此可以使用相同的数据加载器和train函数来训练模型。请记住,当训练模型时,只有分类器内的参数会发生变化。下面的代码片段对模型进行了20轮的训练,在验证集上达到了98.45%的准确率:
- train_losses, train_accuracy =[],[]
- val_losses, val_accuracy =[],[]
- for epoch in range(l,20):
- epoch_loss,epoch_accuracy=fit(epoch,vgg,train_data_loader,phase='training')
- val_epoch_loss,val_epoch_accuracy=
- fit(epoch,vgg,valid_data_loader,phase='validation')
- train_losses.append(epoch_loss)
- train_accuracy.append(epoch_accuracy)
- val_losses.append(val_epoch_loss)
- val_accuracy.append(val_epoch_accuracy)
将训练和验证的损失可视化,如图5.19所示。

将训练和验证的准确率可视化,如图5.20所示:
我们可以应用一些技巧,例如数据增强和使用不同的dropout值来改进模型的泛化能力。以下代码片段将 VGG分类器模块中的dropout值从0.5更改为0.2并训练模型:
- for layer in vgg.classifier.children():
- if(type(layer)== nn.Dropout):
- layer.p=0.2
- #训练
- train_losses,train_accuracy = [][]
- val_losses, val accuracy =[],[ ]
- for epoch in range(1,3):
- epoch_loss,epoch_accuracy=fit(epoch,vgg,train_data_loader,phase='training')
- val_epoch_loss,val_epoch_accuracy=
- fit(epoch,vgg,valid_data_loader,phase='validation')
- train_losses.append(epoch_loss)
- train_accuracy.append(epoch_accuracy)
- val_losses.append(val_epoch_loss)
- val_accuracy.append(val_epoch_accuracy)
通过几轮的训练,模型得到了些许改进。还可以尝试使用不同的dropout值。改进模型泛化能力的另一个重要技巧是添加更多数据或进行数据增强。我们将通过随机地水平翻转图像或以小角度旋转图像来进行数据增强。torchvision转换为数据增强提供了不同的功能,它们可以动态地进行,每轮都发生变化。我们使用以下代码实现数据增强:
- train transform =transforms.Compose([transforms,Resize((224,224)),
- transforms.RandomHorizontalFlip(),
- transforms.RandomRotation(0.2),
- transforms.ToTensor(),
- transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
- ])
- train = ImageFolder('dogsandcats/train/',train_transform)
- valid = ImageFolder('dogsandcats/valid/',simple_transform)
- #训练
- train_losses,train_accuracy=[][]
- val_losses,val_accuracy = [],[]
- for epoch in range(1,3):
- epoch_loss,epoch_accuracy=fit(epoch,vgg,train_data_loader,phase='training')
- val_epoch_loss,val_epoch_accuracy=
- fit(epoch,vgg,valid_data_loader,phase='validation')
- train_losses.append(epoch_loss)
- train_accuracy.append(epoch_accuracy)
- val_losses.append(val_epoch_loss)
- val_accuracy.append(val_epoch_accuracy)
前面的代码输出如下:
- #结果
- training loss is 0.041 and training accuracy is 22657/23000 98.51
- validation loss is 0.043 and validation accuracy is 1969/2000 98.45
- training loss is 0.04 and training accuracy is 22697/23000 98.68
- validation loss is 0.043 and validation accuracy is 1970/2000 98.5
使用增强数据训练模型仅运行两轮就将模型准确率提高了0.1%;可以再运行几轮以进一步改进模型。如果大家在阅读本书时一直在训练这些模型,将意识到每轮的训练可能需要几分钟,具体取决于运行的GPU。让我们看一下可以在几秒钟内训练一轮的技术。

