
- 1Sublime 使用笔记(一):安装 & 配置编译环境(C++、Python、Java、JavaScript)_sublime如何下载c++ single file
- 2python自动化_Python自动化测试踩坑记录(企业中如何实施自动化测试)
- 3单片机学习笔记---AT24C02(I2C总线)
- 4Stone 3D教程:创建全景图云展览,只需要几分钟
- 5【数学建模】【2024年】【第40届】【MCM/ICM】【C题 网球运动中的“动量”】【解题思路】
- 6彻底弄懂ip掩码中的网络地址、广播地址、主机地址_网络地址和广播地址
- 7ai写作在线网页版如何获取?ai写论文免费_人工智能网页版免费
- 8JavaEE作业-实验四
- 9使用powerdesign制作数据库说明文档_powerdesigner导出数据库设计说明书
- 10关键点检测——直接回归法_关键点回归
深入浅出SSD--5.1PCIE基础知识_pcie2.0 x1速度
赞
踩
深入浅出SSD--5.1PCIE基础知识
1.关于PCIE的速度:
SSD使用PCIe接口比SATA快。
下面是PCIE1.0 2.0 3.0速度:

表中的带宽,比如PCIe3.0×1,带宽为2GB/s,是指双向带宽,即读写带宽。如果单指读或者写,该值应该减半,即1GB/s的读速度或者写速度。我们来看看表里面的带宽是怎么算出来的。
PCIE1.0 X1带宽计算:
PCIe是串行总线,PCIe1.0的线上比特传输速率为2.5Gbps,物理层使用8/10编码,即8bit的数据,实际在物理线路上是需要传输10bit的,多余的2bit用来校验。因此:PCIe1.0×1的带宽=(2.5Gbps×2(双向通道))/10 = 0.5GB/s
这是单条Lane的带宽,有几条Lane,那么整个带宽计算就是用0.5GB/s乘以Lane的数目。
PCIE2.0 X1带宽计算:
PCIe2.0的线上比特传输速率在PCIe1.0的基础上翻了一倍,为5Gbps,物理层同样使用8/10编码,所以:PCIe2.0×1的带宽=(5Gbps×2(双向通道))/ 10 = 1GB/s同样,有多少条Lane,带宽就是1GB/s乘以Lane的数目。
PCIE3.0 X1带宽计算:
PCIe3.0的线上比特传输速率没有在PCIe2.0的基础上翻倍,不是10Gbps,而是8Gbps,但物理层使用的是128/130编码进行数据传输,所以:PCIe3.0×1的带宽=(8Gbps×2(双向通道)×(128bit/130bit))/ 8 ≈2GB/s同样,有多少条Lane,带宽就是2GB/s乘以Lane的数目。由于采用了128/130编码,每128bit的数据,只额外增加了2bit的开销,有效数据传输比率增大,虽然线上比特传输率没有翻倍,但有效数据带宽还是在PCIe2.0的基础上实现翻倍。
从链接速度这一行我们看到×1、×2、×4…这是指PCIe连接的通道数(Lane)。就像高速公路一样,有单车道、2车道、4车道的,不过像8车道或者更多车道的公路不常见,但PCIe是可以最多有32个Lane的。
两个设备之间的PCIe连接,叫作一个Link
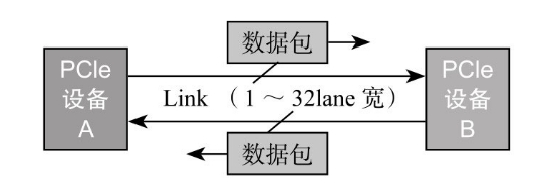
A与B之间是个双向连接,车可以从A驶向B,同时,车也可以从B驶向A,各行其道。两个PCIe设备之间,有专门的发送和接收通道,数据可以同时往两个方向传输,PCIe Spec称这种工作模式为双单工模式(Dual-Simplex),可以理解为全双工模式。
SATA是什么工作模式:
和PCIe一样,SATA也有独立的发送和接收通道,但与PCIe工作模式不一样,同一时间,只有一条通道可以进行数据传输。也就是说,你在一条通道上发送数据,在另外一条通道上就不能接收数据,反之亦然。这种工作模式称为半双工模式。
形象的比喻:
PCIe犹如我们的手机,双方可以同时讲话,而SATA就是对讲机了,一个人在说话,另外一个人就只能听不能说。
现有的PCIe SSD一般最多使用4通道,如PCIe3.0x4,双向带宽为8GB/s,读或者写带宽为4GB/s。

PCIe3.0×4理论上最大的4KB IOPS。PCIe3.0×4理论最大读或写的速度为4GB/s,不考虑协议开销,每秒可以传输4GB/4KB个4KB大小的IO,该值为1M,即理论上最大IOPS为1000k。因此,一个SSD,不管底层用什么介质,闪存还是3D XPoint,接口速度就这么快,最大IOPS是不可能超过这个值的。
因为PCIe在物理传输上,跟PCI有着本质的区别:PCI使用并口传输数据,而PCIe使用的是串口传输。
并行传输时序分析:

在发送端,数据在某个时钟沿传出去(左边时钟第一个上升沿),在接收端,数据在下个时钟沿(右边时钟第二个上升沿)接收。因此,要在接收端能正确采集到数据,要求时钟的周期必须大于数据传输的时间(从发送端到接收端的时间,Flight Time),受限于数据传输时间(该时间还随着数据线长度的增加而增加),因此时钟频率不能做得太高。另外,时钟信号在线上传输的时候,也会存在相位偏移(Clock Skew ),影响接收端的数据采集。由于采用并行传输,接收端必须等最慢的那个bit数据到了以后,才能锁住整个数据。
PCIe使用串行总线进行数据传输就没有这些问题。它没有外部时钟信号,它的时钟信息通过8/10编码或者128/130编码嵌入在数据流,接收端可以从数据流里面恢复时钟信息,因此,它不受数据在线上传输时间的限制,导线多长、数据传输频率多快都没有问题。没有外部时钟信号,自然就没有所谓的相位偏移问题。由于是串行传输,只有一个bit传输,所以不存在信号偏移(Signal Skew)问题。但是,如果使用多条Lane传输数据(串行中又有并行),这个问题又回来了,因为接收端同样要等最慢的那个Lane上的数据到达才能处理整个数据。不过,你不用担心,PCIe自己能解决好这个问题。
2.PCIe拓扑结构
计算机网络的拓扑结构是引用拓扑学中研究与大小、形状无关的点、线关系的方法,把网络中的计算机和通信设备抽象为一个点,把传输介质抽象为一条线,由点和线组成的几何图形就是计算机网络的拓扑结构。
计算机网络主要的拓扑结构有:
1.总线型拓扑、2.环形拓扑、3.树形拓扑、4.星形拓扑、5.混合型拓扑 6.以及网状拓扑。
这一节主要讲下面两件事(归纳):
a.PCI采用的是总线型拓扑结构,而PCIe则采用树形拓扑结构。
b.PCIe与采用总线共享式通信方式的PCI不同,PCIe采用点到点(Endpoint to Endpoint)的通信方式,每个设备独享通道带宽,速度和效率都比PCI好。(点对点-通常都是Endpoint与RC通信,或者Endpoint通过RC与另外一个Endpoint通信。)
1.PCI采用的是总线型拓扑结构,一条PCI总线上挂着若干个PCI终端设备或者PCI桥设备,大家共享该条PCI总线,哪个人想说话,必须获得总线使用权,然后才能发言。
如图所示是一个基于PCI的传统计算机系统:

北桥下面的那根PCI总线,挂载了以太网设备、SCSI设备、南桥以及其他设备,它们共享那条总线,某个设备只有获得总线使用权才能进行数据传输。
2.而PCIe则采用树形拓扑结构,一个简单而又典型的PCIe拓扑结构如图所示:

整个PCIe拓扑结构是一个树形结构。Root Complex(RC)是树的根,它为CPU代言,与整个计算机系统其他部分通信,比如CPU通过它访问内存,通过它访问PCIe系统中的设备。
RC的内部实现很复杂,PCIe Spec也没有规定RC该做什么,不该做什么。我们也不需要知道那么多,只需清楚:它一般实现了一条内部PCIe总线(BUS 0),以及通过若干个PCIe bridge,扩展出一些PCIe Port,如图所示:(RC的内部结构)

PCIe Endpoint,就是PCIe终端设备,比如PCIe SSD、PCIe网卡等,这些Endpoint可以直接连在RC上,也可以通过Switch连到PCIe总线上。Switch用于扩展链路,提供更多的端口用以连接Endpoint。拿USB打比方,计算机主板上提供的USB口有限,如果你要连接很多USB设备,比如无线网卡、无线鼠标、USB摄像头、USB打印机、U盘等,USB口不够用,我会上网买个USB HUB用以扩展接口。(Switch == USB HUB)(理解PCIe Endpoint概念)
Switch扩展了PCIe端口,靠近RC的那个端口,我们称为上游端口(UpstreamPort),而分出来的其他端口,我们称为下游端口(Downstream Port)。一个Switch只有一个上游端口,可以扩展出若干个下游端口。下游端口可以直接连接Endpoint,也可以连接Switch,扩展出更多的PCIe端口,如图所示。(理解PCIe 上游端口,下游端口概念以及跟Endpoint之间的关系)

对每个Switch来说,它下面的Endpoint或者Switch,都是归它管的。上游下来的数据,它需要甄别数据是传给它下面哪个设备的,然后进行转发;下面设备向RC传数据,也要通过Switch代为转发。因此,Switch的作用就是扩展PCIe端口,并为挂在它上面的设备(Endpoint或者Switch)提供路由和转发服务。(Switch的作用提供路由和转发服务)
每个Switch内部,也是有一根内部PCIe总线的,然后通过若干个Bridge,扩展出若干个下游端口,如图所示。(Switch内部结构)

最后小结一下:
PCIe采用的是树形拓扑结构,RC是树的根或主干,它为CPU代言,与PCIe系统其他部分通信,一般为通信的发起者。Switch是树枝,树枝上有叶子(Endpoint),也可节外生枝,Switch上连Switch,归根结底,是为了连接更多的Endpoint。Switch为它下面的Endpoint或Switch提供路由转发服务。Endpoint是树叶,诸如SSD、网卡、显卡等,实现某些特定功能(Function)。我们还看到有所谓的Bridge,用以将PCIe总线转换成PCI总线,或者反过来,不是我们要讲的重点,忽略之。PCIe与采用总线共享式通信方式的PCI不同,PCIe采用点到点(Endpoint to Endpoint)的通信方式,每个设备独享通道带宽,速度和效率都比PCI好。
需要指出的是,虽然PCIe采用点到点通信,即理论上任何两个Endpoint都可以直接通信,但实际中很少这样做,因为两个不同设备的数据格式不一样,除非这两个设备是同一个厂商的。通常都是Endpoint与RC通信,或者Endpoint通过RC与另外一个Endpoint通信。
3.PCIe分层结构
PCIe分层结构绝大多数的总线或者接口,都是采用分层实现的。PCIe也不例外,它的层次结构如图所示。
PCIe定义了下三层:事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer,包括逻辑子模块和电气子模块),每层职能是不同的,但下层总是为上层服务的。分层设计的一个好处是,如果层次分得够好,接口版本升级时,硬件设计可能只需要改动某一层,其他层可以保持不动。(分层易于硬件和软件的维护和更改)

PCIe传输的数据从上到下,都是以数据包(Packet)的形式传输的,每层数据包都是有其固定的格式。
1.事务层的主要职责是创建(发送)或者解析(接收)TLP(Transaction LayerPacket)、流量控制、QoS、事务排序等。(TLP创建(发送)或者解析(接收))
2.数据链路层的主要职责是创建(发送)或者解析(接收)DLLP(Data Link LayerPacket)、Ack/Nak协议(链路层检错和纠错)、流控、电源管理等。
3.物理层的主要职责是处理所有的Packet数据物理传输,发送端数据分发到各个Lane传输(Stripe),接收端把各个Lane上的数据汇总起来(De-stripe),每个Lane上加扰(Scramble,目的是让0和1分布均匀,去除信道的电磁干扰EMI)和去扰(De-scramble),以及8/10或者128/130编码解码等。

数据从上到下,一层层打包,上层打包完的数据,作为下层的原始数据,再打包。就像人穿衣服一样,穿了内衣穿衬衫,穿了衬衫穿外套。
Data是事务层上层(诸如命令层、NVMe层)给的数据,事务层给它头上加个Header,然后尾巴上再加个CRC校验,就构成了一个TLP。这个TLP下传到数据链路层,又被数据链路层在头上加了个包序列号(Sequence Number, SN),尾巴上再加个CRC校验,然后下传到物理层。物理层为其头上加个Start,尾巴上加个End符号,把这些数据分派到各个Lane上,然后在每个Lane上加扰码,经8/10或128/130编码,最后通过物理传输介质传输给接收方,如图所示。(数据封装过程,Data根据协议层层封装,最后传输)

接收方物理层是最先接收到这些数据的,掐头(Start)去尾(End),然后交由上层。在数据链路层,校验序列号和LCRC,如果没问题,剥掉序列号和LCRC,往事务层走;如果校验出差,通知对方重传。在事务层,校验ECRC,有错,数据抛弃;没错,去掉ECRC,获得数据。整个过程犹如脱衣睡觉,外套脱了,衬衫脱了,内衣也脱了,光溜溜钻进被窝,如图所示。(数据解离过程)

和PCI数据裸奔不同,PCIe的数据是穿衣服的。PCIe数据以Packet的形式传输,比起PCI冷冰冰的数据,PCIe的数据是鲜活有生命的。
每个Endpoint都需要实现这三层,每个Switch的Port也需要实现这三层。

如果RC要与EP1通信,中间要经历怎样的一个过程?
如果把前述的数据发送和接收过程叫作穿衣和脱衣,那么,RC与EP1数据传输过程中,则存在好几次这样穿衣脱衣的过程:RC帮数据穿好衣服,发送给Switch的上游端口,A为了知道该笔数据发送给谁,就需要脱掉该数据的衣服,找到里面的地址信息。衣服脱光后,Switch发现它是往EP1的,又帮它换了身新衣服,发送给端口B。B又不嫌麻烦的脱掉它的衣服,换上新衣服,最后发送给EP1,如图所示。(RC-->上游端口A-->下游端口B-->EP1)

Switch的主要功能是转发数据,为什么还需要实现事务层?Switch必须实现这三层,因为数据的目的地信息是在TLP中的,如果不实现这一层,就无法知道目的地址,也就无法实现数据寻址路由。
4.PCIe TLP类型
主机与PCIe设备之间,或者PCIe设备与设备之间,数据传输都是以Packet形式进行的。事务层根据上层(软件层或者应用层)请求(Request)的类型、目的地址和其他相关属性,把这些请求打包,产生TLP(Transaction Layer Packet,事务层数据包)。然后这些TLP往下,经历数据链路层、物理层,最终到达目标设备。(事务层产生TLP)
根据软件层的不同请求,事务层产生四种不同的TLP请求:
❏ Memory;
❏ IO;
❏ Configuration;
❏ Message。
前三种分别用于访问内存空间、IO空间、配置空间,这三种请求在PCI或者PCI-X时代就有了,最后的Message请求是PCIe新加的。在PCI或者PCI-X时代,像中断、错误以及电源管理相关信息,都是通过边带信号(Sideband Signal)进行传输的,但PCIe干掉了这些边带信号线,所有的通信都是走带内信号,即通过Packet传输,因此,过去一些由边带信号线传输的数据,比如中断信息、错误信息等,现在就交由Message来传输了。
我们知道,一个设备的物理空间,可以通过内存映射(Memory Map)的方式映射到主机的主存,有些空间还可以映射到主机的IO空间(如果主机存在IO空间的话)。但新的PCIe设备(区别于Legacy PCIe设备)只支持内存映射,之所以还存在访问IO空间的TLP,完全是为了照顾那些老设备。以后IO映射的方式会逐渐取消,为减轻学习压力,我们以后看到IO相关的东西,大可忽略掉。(主要看PCIE的内存映射)
所有配置空间(Configuration)的访问,都是主机发起的,确切地说是RC发起的,往往只在上电枚举和配置阶段会发起配置空间的访问,这样的TLP很重要,但不是常态;Message也是一样,只有在有中断或者有错误等情况下,才会有Message TLP,这是非主流的。PCIe线上主流传输的是Memory访问相关的TLP,主机与设备或者设备与设备之间,数据都是在彼此的Memory之间(抛掉IO)交互,因此,这种TLP是我们最常见的。(Configuration TLP由RC发起,在上电和配置阶段。Message TLP 在中断和错误阶段。Memory的TLP是最频繁的)
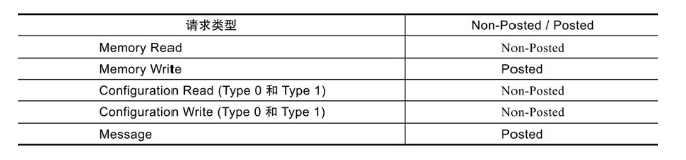
这四种请求,如果需要对方响应的,我们称之为Non-Posted TLP;如果不指望对方给响应的,我们称之为Posted TLP。Post,有“邮政”的意思,我们只管把信投到邮箱,能不能到达对方,就取决于邮递员了。Posted TLP,就是不指望对方回复(信能不能收到都是个问题); Non-Posted TLP,就是要求对方务必回复。(Non-Posted TLP需要响应,Posted TLP不需要响应)
Configuration和IO访问,无论读写,都是Non-Posted的,这样的请求必须得到设备的响应;(Configuration和IO访问 读写 Non-Posted 需要响应)
Memory Read必须是Non-Posted的,我读你数据,你不返回数据(返回数据也是响应),那肯定不行,所以Memory Read必须得到响应;(Memory Read Non-Posted需要响应)
Message TLP是Posted的,不需要响应;(Message Posted 不需要响应)
Memory Write是Posted的,我数据传给你,无须回复。(Memory Write Posted不需要响应)写操作失败丢数据的风险较小,数据链路层提供了ACK/NAK机制,一定程度上能保证TLP正确交互,因此能很大程度上减小了数据写失败的可能。

所以,只要记住只有Memory Write和Message两种TLP是Posted的就可以了,其他都是Non-Posted的。
在Configuration一栏,我们看到Type 0和Type 1。在之前的拓扑结构中,我们看到除了Endpoint之外,还有Switch,他们都是PCIe设备,但配置种类不同,因此用Type 0和Type 1区分。
对Non-Posted的Request,是一定需要对方响应的,对方需要通过返回一个Completion TLP来作为响应。对Read Request来说,响应者通过CompletionTLP返回请求者所需的数据,这种Completion TLP包含有效数据;对WriteRequest(现在只有Configuration Write了)来说,响应者通过Completion TLP告诉请求者执行状态,这样的Completion TLP不含有效数据。
因此,PCIe里面所有的TLP = Request TLP + Completion TLP(公式)。
Native PCIe请求和响应TLP类型,如下图:

看个Memory Read的例子,如图所示:

例子中,PCIe设备C想读主机内存的数据,因此,它在事务层上生成一个MemoryRead TLP,该MRd一路向上,到达RC。RC收到该Request,就到内存中取PCIe设备C所需的数据,RC通过Completion with Data TLP(CplD)返回数据,原路返回,直到PCIe设备C。
一个TLP最多只能携带4KB有效数据,因此,上例中,如果PCIe设备C需要读16KB的数据,则RC必须返回4个CplD给PCIe设备C。注意,PCIe设备C只需发1个MRd就可以了。(一个TLP最多只能携带4KB有效数据)
再看个Memory Write的例子,如图所示:

该例中,主机想往PCIe设备B中写入数据,因此RC在其事务层生成了一个MemoryWrite TLP(要写的数据在该TLP中),通过Switch直到目的地。前面说过Memory Write TLP是Posted的,因此,PCIe设备B收到数据后,不需要返回Completion TLP(如果这时返回Completion TLP,反而是画蛇添足)。同样的,由于一个TLP只能携带4KB数据,因此主机想往PCIe设备B上写入16KB数据,RC必须发送4个MWr TLP。
参考《深入浅出SSD:固态存储核心技术,原理与实战》


