
热门标签
热门文章
- 1语义分割论文翻译:Large Kernel Matters —— Improve Semantic Segmentation by Global Convolutional Network
- 2自然语言处理(NLP)和机器学习(ML)的应用领域_nlp+ml
- 3单片机毕设分享 基于stm32的人体健康监护系统 - 单片机 嵌入式 物联网_基于stm32的毕业设计 康复辅助类
- 4数据初步分析——房价的可视化1_安居客词云
- 525 行 Python 代码实现人脸识别——OpenCV_用python代码进行人脸识别完整代码
- 688页 | 2024人工智能发展白皮书(免费下载)_《2024人工智能发展白皮书》pdf
- 7手把手教你安装Kali Linux_kali linux安装教程 csdn,2024年最新泪目_虚拟机安装kali linux
- 8如何训练自己的ChatGPT?需要多少训练数据?_chatgpt sft、rm、ppo训练数据量
- 9VIIF:深度图像分解_tno数据集
- 10NLP深入学习(十四):TextRank算法
当前位置: article > 正文
本地离线模型搭建指南-中文大语言模型底座选择依据
作者:码创造者 | 2024-06-25 03:41:33
赞
踩
本地离线模型搭建指南-中文大语言模型底座选择依据
搭建一个本地中文大语言模型(LLM)涉及多个关键步骤,从选择模型底座,到运行机器和框架,再到具体的架构实现和训练方式。以下是一个详细的指南,帮助你从零开始构建和运行一个中文大语言模型。
本地离线模型搭建指南将按照以下四个部分展开
1 中文大语言模型底座选择依据
在选择中文大语言模型(LLM)的底座时,可以参考以下几个关键因素:
1.1 模型规模与参数
根据具体应用场景选择不同规模的模型。比如:
- ChatGLM系列:包含6B参数的模型,适合中小规模应用,且支持商业用途。
- LLaMA系列:提供7B、8B、13B、33B和70B等多种规模,部分版本可商用。
- Baichuan系列:提供7B和13B参数的模型,适合需要较大规模的应用。
- Qwen系列:提供7B、14B、72B和110B参数的模型,支持较长的上下文长度,适合复杂场景。
- BLOOM:从1B到176B-MT,多种规模选择。
- Aquila系列:包括7B和34B参数版本。
- InternLM系列:从7B到20B参数,支持代码应用。
- Mixtral、Yi、DeepSeek、XVERSE等:提供多种参数规模,适合不同应用需求。
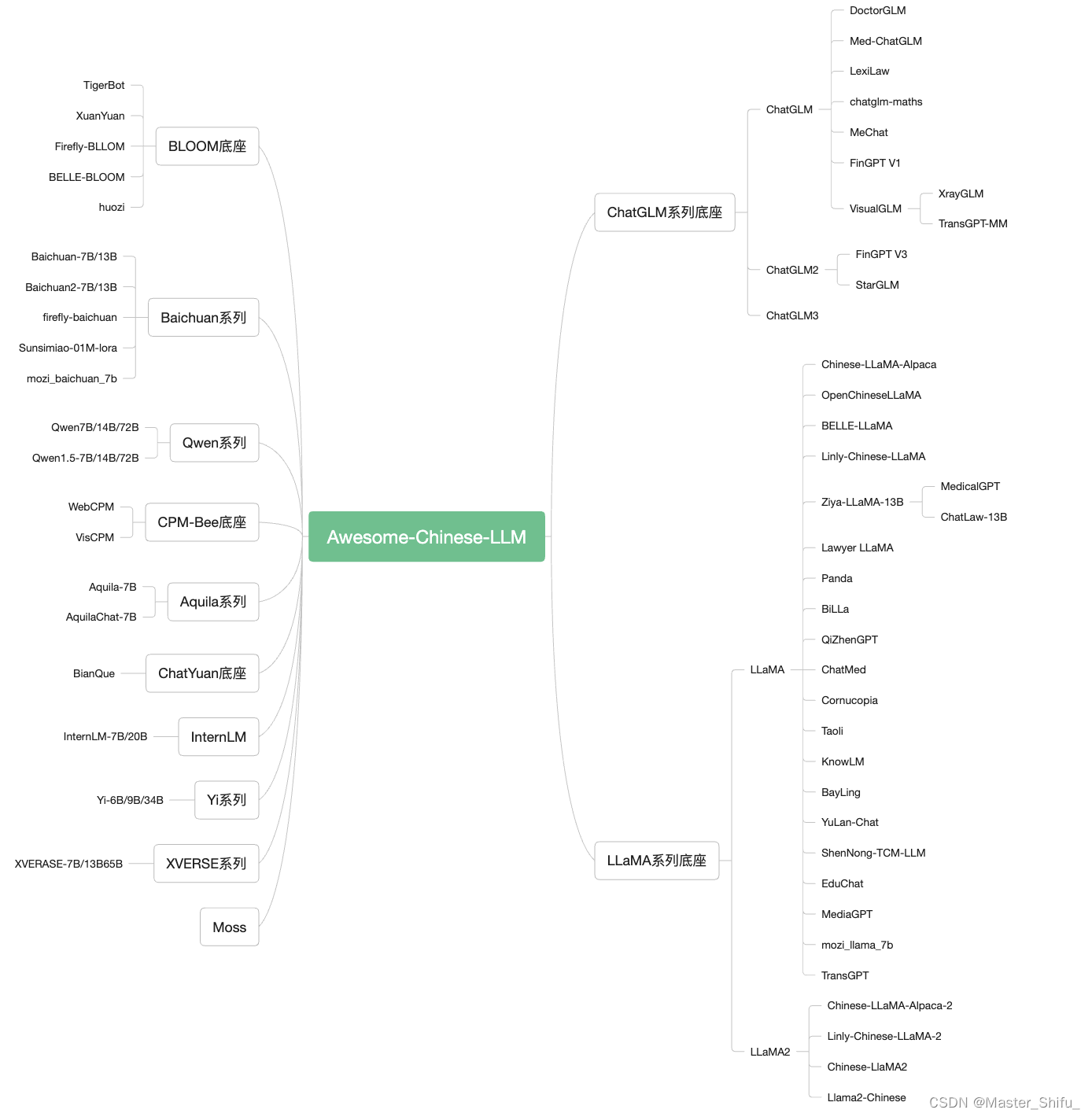
常见底座模型细节概览:
| 底座 | 包含模型 | 模型参数大小 | 训练token数 | 训练最大长度 | 是否可商用 |
|---|---|---|---|---|---|
| ChatGLM | ChatGLM/2/3 Base&Chat | 6B | 1T/1.4 | 2K/32K | 可商用 |
| LLaMA | LLaMA/2/3 Base&Chat | 7B/8B/13B/33B/70B | 1T/2T | 2k/4k | 部分可商用 |
| Baichuan | Baichuan/2 Base&Chat | 7B/13B | 1.2T/1.4T | 4k | 可商用 |
| Qwen | Qwen/1.5 Base&Chat | 7B/14B/72B/110B | 2.2T/3T | 8k/32k | 可商用 |
| BLOOM | BLOOM | 1B/7B/176B-MT | 1.5T | 2k | 可商用 |
| Aquila | Aquila/2 Base/Chat | 7B/34B | - | 2k | 可商用 |
| InternLM | InternLM/2 Base/Chat/Code | 7B/20B | - | 200k | 可商用 |
| Mixtral | Base&Chat | 8x7B | - | 32k | 可商用 |
| Yi | Base&Chat | 6B/9B/34B | 3T | 200k | 可商用 |
| DeepSeek | Base&Chat | 1.3B/7B/33B/67B | - | 4k | 可商用 |
| XVERSE | Base&Chat | 7B/13B/65B/A4.2B | 2.6T/3.2T | 8k/16k/256k | 可商用 |
1.2 训练数据与Token数
不同模型经过不同规模的数据训练,影响其在特定任务上的表现:
- ChatGLM:经过1到1.4T的中英文标识符训练,适合中文问答和对话。
- LLaMA:经过1T到2T的训练。
- Baichuan:训练数据在1.2T到1.4T之间。
- Qwen:训练数据量高达2.2T到3T,支持复杂任务。
- BLOOM:经过1.5T的训练。
- XVERSE:训练数据量达2.6T到3.2T。
1.3 上下文长度支持
根据应用需求选择支持较长上下文长度的模型:
- ChatGLM2-6B:上下文长度扩展到32K。
- Qwen:支持8K到32K的上下文长度。
- Mixtral、Yi、DeepSeek:支持200k到256k的上下文长度。
1.4 商业用途许可
确保所选模型允许商业用途:
- ChatGLM、LLaMA、Baichuan、Qwen、BLOOM、Aquila、InternLM、Mixtral、Yi、DeepSeek、XVERSE等模型均允许商业用途。
1.5 垂直领域微调与应用
考虑模型在特定领域的微调效果:
- 医疗、法律、金融、教育、科技、电商、网络安全、农业等领域的垂直应用。
1.6 具体模型推荐
以下是一些具体的模型推荐及其特点:
- ChatGLM系列:适合中文问答和对话,经过中英文双语训练,支持商业用途。
- LLaMA系列:提供多种规模,部分版本适合商用。
- Baichuan系列:适合需要较大规模训练的应用。
- Qwen系列:支持复杂任务和长上下文长度。
- InternLM系列:适合代码相关应用。
更多详细信息和具体模型的链接,请访问 Awesome-Chinese-LLM 项目。
下一篇介绍
本地离线模型搭建指南-本地运行显卡选择
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/754818
推荐阅读
相关标签

