
热门标签
热门文章
- 1性能优化之MQ问题分析及解决方案_activemq内存溢出处理方案
- 2【会议征稿,IEEE出版】第六届物联网、自动化和人工智能国际学术会议(IoTAAI 2024,7月26-28)_2024年7月计算机会议
- 3植物大战僵尸杂交版全新版v2.1解决全屏问题_c1a75e93ecb5
- 41年经验与零经验产品经理薪资相差居多,原因为何?
- 5centos 配置mysql环境变量_CentOS7 安装配置 MySQL
- 6MySQL事务基础知识_事务关键字
- 7OpenWRT 安装 PassWall_openwrt安装passwall
- 8华为OD机试C卷-- 亲子游戏(Java & JS & Python & C)
- 9一:Activiti6与Flowable的区别_activiti和flowable区别
- 10用Word统计文本出现次数(转)
当前位置: article > 正文
第九届信也科技杯全球AI算法大赛——语音深度鉴伪识别参赛A榜 0.968961分
作者:码创造者 | 2024-06-25 18:15:16
赞
踩
第九届信也科技杯全球AI算法大赛——语音深度鉴伪识别参赛A榜 0.968961分
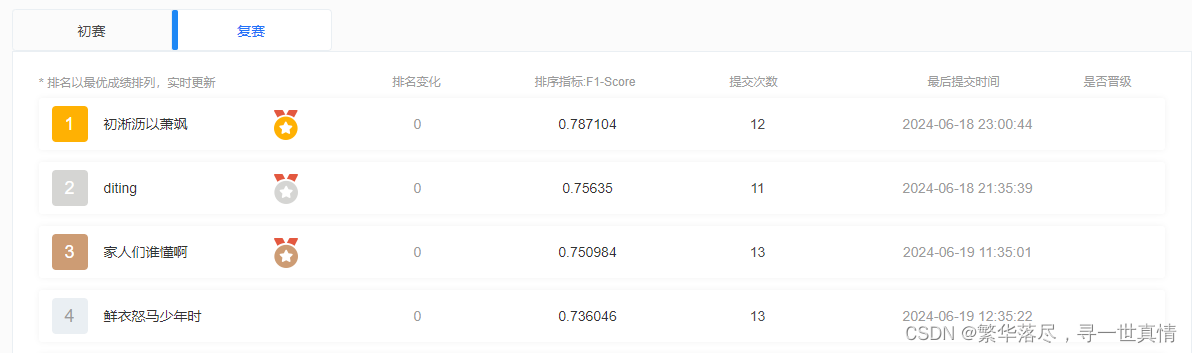
遗憾没有进复赛,只是第41名。先贴个A榜的成绩。A榜的前三十名晋级,个个都是99分的大佬,但是B榜的成绩就有点低了,应该是数据不同源的问题,第一名0.78分。官网链接:语音深度鉴伪识别

官方baselin:https://github.com/xinyebei/2024_finvcup_baseline
baseline源码:https://github.com/xieyuankun/Codecfake
实验的 源码:https://github.com/Shybert-AI/Codecfake_ResNet
任务描述:

简单的说一下本次比赛方案的想法,首先明确是语音深度鉴伪识别任务,于是发动互联网的强大的搜索功能,尽可能多的搜索到更多的语音深度鉴伪识别算法。也相应的搜索对应的数据集,在看到此帖子[深度伪造音频普遍检测的Codecfake数据集和对策],同时在github上找到相应的源码,因此方案基于Codecfake进行。通过将网络结构修改成ResNet等实验,提出Codecfake_ResNet模型,让语音鉴别模型的分类指标达到0.968961。(https://blog.csdn.net/robinfang2019/article/details/138673202)
模型架构:
 训练步骤:
训练步骤:
1.下载finvcup9th_1st_ds5数据集,解压到data目录下
2.执行data_prepare.py 脚本生成训练的csv文件,修改finvcup9th_1st_ds5_valid_data.csv为finvcup9th_1st_ds5_dev_data.csv
python data_prepare.py
3.执行提取特征文件
python preprocess.py
4.训练
python main_train.py --path_to_features preprocess_xls-r-5 -f1 preprocess_xls-r-5 --out_fold ./pretrained_model/codec_w2v2aasist_ResNet50_CSAM_xls-r-5_300m/ --CSAM True --train_task codecfake --num_epochs 50 --batch_size 16 --lr 0.001 --gpu 0 --seed 2024 --num_workers 1
5.预测
python predict.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
实验结果:
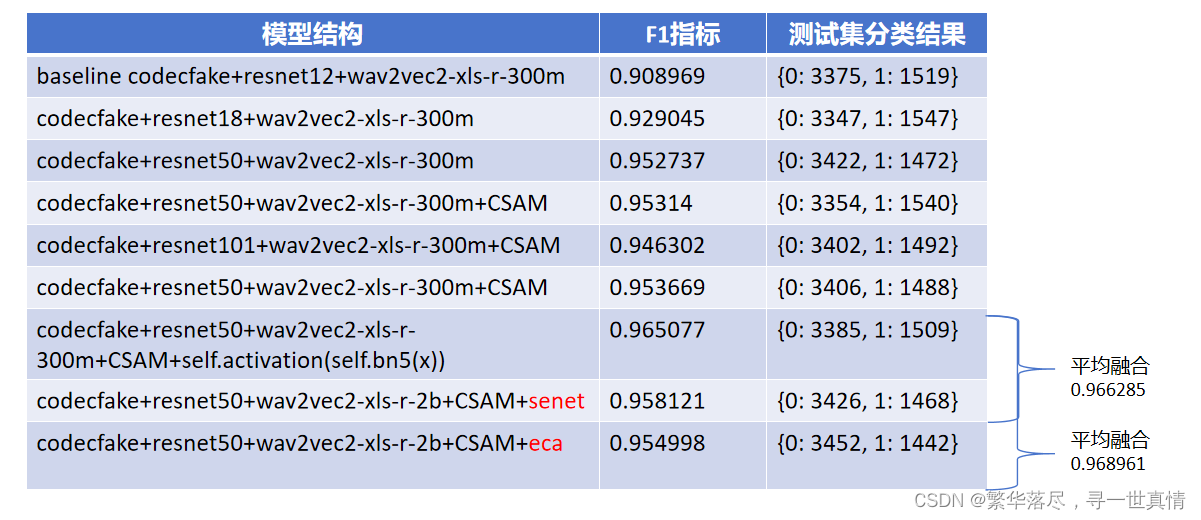
通过实验分析提升网络的层数和多模型融合可以提升。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/757020
推荐阅读
相关标签

