
- 1Flume的Source--KafkaSource
- 2Linux 内核 container_of 宏详解_containerof宏
- 3docker进阶篇,docker集群介绍_docker有哪些群组
- 4Ubuntu配置Docker深度学习环境_ubuntu 深度学习环境镜像
- 5监听ScrollView 的上下滑动_swiftui如何 监听 scrollview 滚动
- 6Java最常见的200+面试题_java面试200题
- 7十三款MySQL可视化管理工具_dbeaver和heidisql
- 8【OD统一考试(C卷)考生抽中题】悄悄话花费的时间,用 C++ 编码,速通_给定一个二叉树,每个节点上站一个人,节点数字表示父节点到该节点传递悄悄话需要花
- 9第二章 算法-程序的灵魂_nt main() int sign=1 double deno=20sum
- 10Docker 安装 nacos详细教程_docker安装nacos
CNN FPGA加速器实现(小型)CNN FPGA加速器实现(小型)_fpga加速cnn
赞
踩
CNN FPGA加速器实现(小型)CNN FPGA加速器实现(小型)
通过本工程可以学习深度学习cnn算法从软件到硬件fpga的部署。
网络软件部分基于tf2实现,通过python导出权值,硬件部分verilog实现,纯手写代码,可读性高,高度参数化配置,可以针对速度或面积要求设置不同加速效果。
参数量化后存储在片上ram,基于vivado开发。
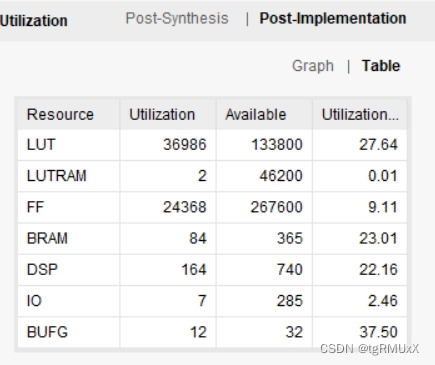
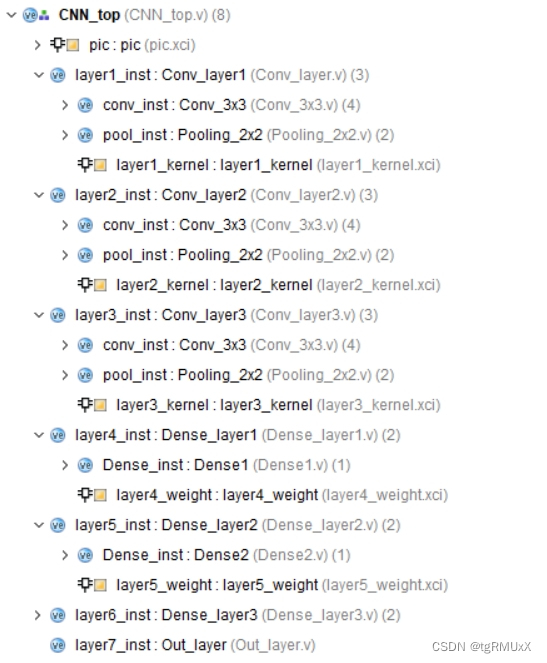
图一为工程结构图,提供基础的testbench,加速器输入存在ram上,图二为在artix7 fpga xc7a200t所占资源(资源和速度互相折中,可以用更多的资源换速度,也可以降速度减少资源消耗)。
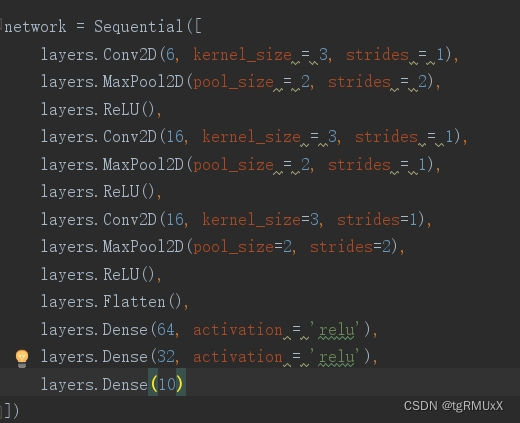
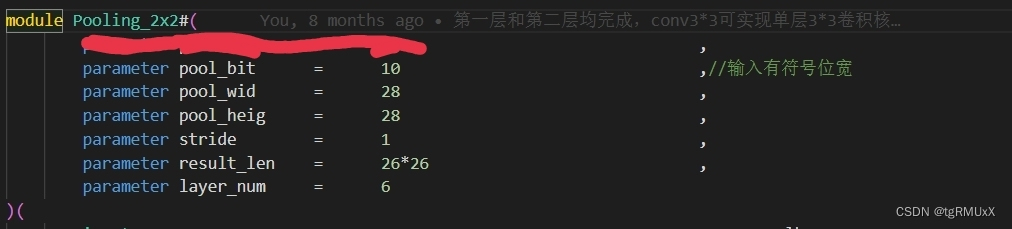
图三为网络结构图,demo所实现输入为28*28*1,图四五为卷积层和池化层可配置部分。
单张图片推理时间50us左右
提供本项目实现中所用的所有软件( python)和硬件代码( verilog)。

本文将围绕CNN FPGA加速器实现展开,介绍深度学习cnn算法从软件到硬件fpga的部署。通过本工程,我们可以学习如何基于tf2实现网络软件部分,将权值导出并在硬件部分verilog实现,实现高度参数化配置,以针对速度或面积要求设置不同的加速效果。同时,本文会详细介绍本工程的结构、资源占用和推理速度等相关参数,为读者提供深入了解该加速器实现的机会。
一、CNN FPGA加速器实现介绍
本文所介绍的CNN FPGA加速器实现是一个小型的加速器,旨在让读者通过本工程深入了解深度学习cnn算法从软件到硬件fpga的部署。该加速器的网络软件部分基于tf2实现,通过python导出权值,硬件部分verilog实现,并且是纯手写代码,可读性高且高度参数化配置。在本工程中,我们可以通过参数量化将数据存储在片上ram中,并且基于vivado开发以实现最佳的推理速度。
二、CNN FPGA加速器实现结构
如图一所示,CNN FPGA加速器实现的结构图清晰明了,提供了基础的testbench, 并且加速器输入存在ram上。具体来说,该加速器包含输入模块、卷积模块、池化模块和全连接模块。在卷积模块和池化模块中,我们还可以看到可配置的部分,如图四五所示。这种高度参数化的配置方式使得我们可以针对不同的速度和面积需求进行设置,从而实现不同的加速效果。
三、CNN FPGA加速器实现资源占用
本CNN FPGA加速器实现是基于artix7 fpga xc7a200t开发的,其资源占用情况如图二所示。可以看到,资源和速度之间是互相折中的,我们可以用更多的资源换取更高的速度,也可以通过降低速度以减少资源消耗。在实际应用中,我们可以根据不同的需求进行选择,以实现最优的加速效果。
四、CNN FPGA加速器实现推理速度
在本工程中,单张图片推理时间约为50us。这个推理速度非常快,对于实时性要求较高的场合非常适用。同时,该加速器实现中所涉及到的软件和硬件代码也已经提供,读者可以基于此进行二次开发或者进行针对性的调整,以实现更高的推理速度。
相关代码,程序地址:http://lanzouw.top/624043661539.html

