
- 1欢迎参加SPDK线上中文讨论会议
- 2阿里开源高性能搜索引擎 Havenask - Ha3
- 3Windows10多显卡修改默认高性能卡_windows server 更改默认显卡
- 4Python爬虫常用哪些库?_python爬虫库
- 5FPGA编程语言--VHDL OR Verilog?_fpga语言
- 6机器人仿真论文阅读1_机器人仿真设计论文
- 7yolov8 多卡训练报错subprocess.CalledProcessError: Command‘[‘/home/... returned non-zero exit status 1._yolov8多卡训练报错
- 8JAVA 中 Switch引用Enum问题
- 9Spark内核架构剖析_spark sql内核剖析 下载
- 10js中的map和set_js map赋值set
大数据 BigData_大数据 csdn
赞
踩
大数据
大数据是指:在短时间内,无法用传统的IT技术和软硬件工具进行处理的数据集合。
这里传统的IT技术和软硬件工具是指单机计算模式和传统的数据分析算法。
因此实现大数据的分析通常需要从两个方面来着手:
①采用集群的方法来获取强大的数据分析能力;
②研究面向大数据的新的数据分析算法。
不同高性能系统之间的比较
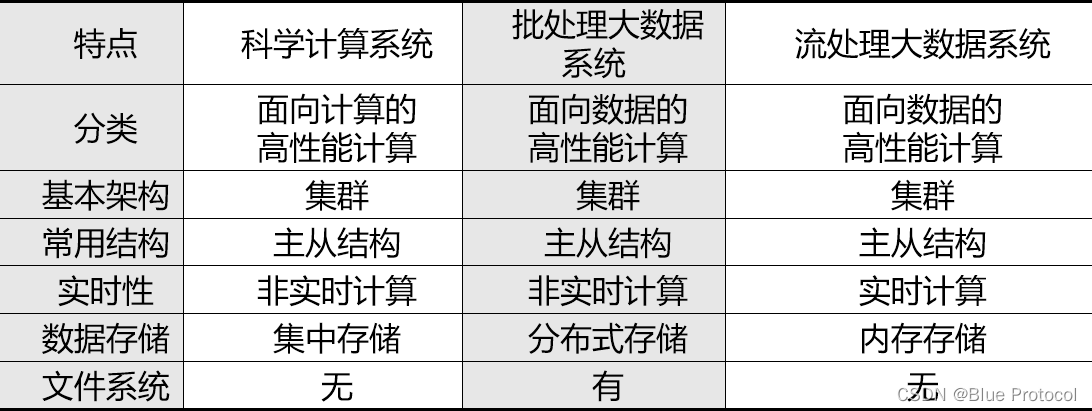
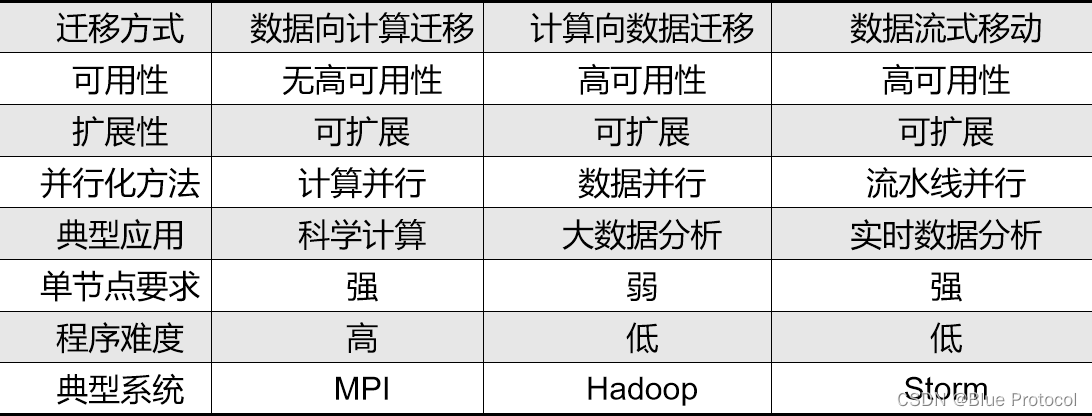
主要的大数据处理系统
- 1.数据查询分析计算系统
大数据时代,数据查询分析计算系统需要具备对大规模数据实时或准实时查询的能力,数据规模的增长已经超出了传统关系型数据库的承载和处理能力。目前主要的数据查询分析计算系统包括HBase、Hive、Shark、Hana、Cassandra、Dremel、等。
- 2.批处理系统
MapReduce是被广泛使用的批处理计算模式。MapReduce对具有简单数据关系、易于划分的大数据采用“分而治之”的并行处理思想,将数据记录的处理分为Map和Reduce两个简单的抽象操作,提供了一个统一的并行计算框架。批处理系统将并行计算的实现进行封装,大大降低开发人员的并行程序设计难度。Hadoop和Spark是典型的批处理系统。
3.流式计算系统
流式计算具有很强的实时性,需要对应用不断产生的数据实时进行处理,使数据不积压、不丢失,常用于处理电信、电力等行业应用以及互联网行业的访问日志等。Apache的Flume、Twitter的Storm、UCBerkeley的Spark Streaming、Facebook的Scribe、Yahoo的S4、是常用的流式计算系统。
4.迭代计算系统
针对MapReduce不支持迭代计算的缺陷,人们对Hadoop的MapReduce进行了大量改进,Haloop、Spark、iMapReduce、Twister、是典型的迭代计算系统。
5.图计算系统
社交网络、网页链接等包含具有复杂关系的图数据,这些图数据的规模巨大,可包含数十亿顶点和上百亿条边,图数据需要由专门的系统进行存储和计算。常用的图计算系统有Google公司的Pregel、Pregel的开源版本Giraph、微软的Trinity、Berkeley AMPLab的GraphX以及高速图数据处理系统PowerGraph。
6.内存计算系统
随着内存价格的不断下降和服务器可配置内存容量的不断增长,使用内存计算完成高速的大数据处理已成为大数据处理的重要发展方向。目前常用的内存计算系统有分布式内存计算系统Spark、全内存式分布式数据库系统HANA、Google的可扩展交互式查询系统Dremel。
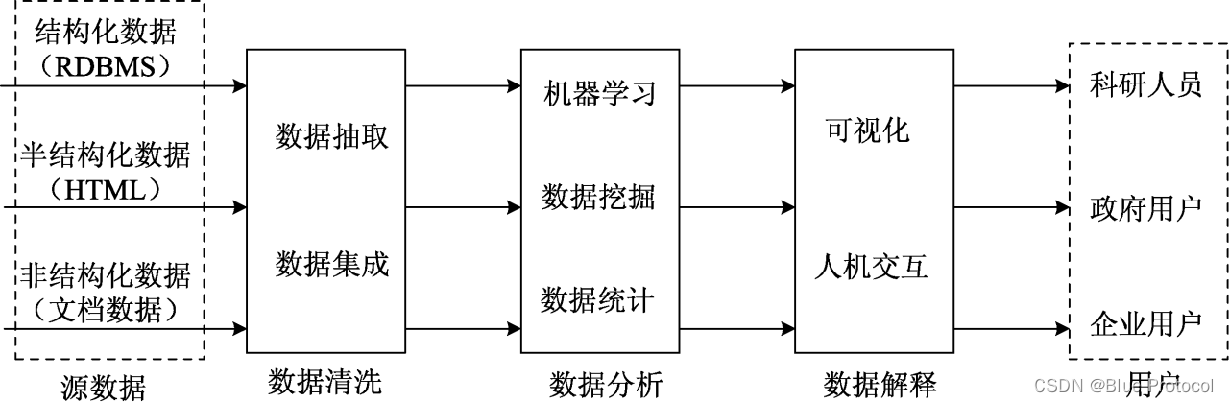
大数据处理的基本流程
分布式系统中计算和数据的协作机制:集群技术
集群技术的采用成为了应对大数据挑战最为直接的方法,在CPU计算速度无法满足数据增长的需要时通过增加计算节点来解决从技术的角度讲是最为简单的,所以目前我们所见到的大数据系统基本都采用了集群架构。
集群系统概述
集群系统是一个互相通过网络连接起来的计算机(节点)所构成的分布式系统,集群中的每一个节点都具有独立的存储系统,和共享存储系统相比集群是一种松耦合的系统。集群系统现在是实现高性能计算主要方法,集群系统不只是计算的聚集也是存储的聚集。这里所指的分布式系统包括分布式计算和分布式存储。
集群文件系统的基本概念
目前常用的HDFS、GFS、Lustre等文件系统都属于集群文件系统。
集群文件系统存储数据时并不是将数据放置于某一个节点存储设备上,而是将数据按一定的策略分布式地放置于不同物理节点的存储设备上。集群文件系统将系统中每个节点上的存储空间进行虚拟的整合,形成一个虚拟的全局逻辑目录,集群文件系统在进行文件存取时依据逻辑目录按文件系统内在的存储策略与物理存储位置对应,从而实现文件的定位。

