
- 1scrapy框架-反爬虫与绕过方法+setting动态配置
- 2浅谈单元测试和JUnit4使用_还有人在用 junit4吗
- 3开源新纪元:ChatTTS——引领对话式文本转语音的新潮流_chattts特点
- 4pnpm安装成功但不能用_pnpm 安装没效果
- 5【Mysql】utf8与utf8mb4区别,utf8mb4_bin、utf8mb4_general_ci、utf8mb4_unicode_ci区别
- 6python2.7是什么_python2.7是什么
- 7PG302 QDMA Subsystem for PCI Express v4.0 Ch.2 Overview
- 8AIGC总体相似度是什么意思_aigc相似度
- 9记录docker-compose遇到的坑_dockercompose keyerror: 'containerconfig
- 10unity入门教程(非常详细)从零基础入门到精通,看完这一篇就够了_unity完全自学教程
Qwen-2-7B和GLM-4-9B:“大模型届的比亚迪秦L”_qwen2 glm4
赞
踩
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径:AI代理工作流
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 大模型RAG性能提升路径
- langchain的基本使用
- 结合基础模型的大模型多源信息应用开发
- COT:大模型的强化利器
- 多角色大模型问答性能提升策略(附代码)
- 大模型接入外部在线信息提升应用性能
- 从零开始的Dify大模型应用开发指南
- 基于dify开发的多模态大模型应用(附代码)
- 基于零一万物多模态大模型通过外接数据方案优化图像文字抽取系统
- 快速接入stable diffusion的文生图能力
- 多模态大模型通过外接数据方案实现电力智能巡检(设计方案)
- 大模型prompt实例:知识库信息质量校验模块
- 基于Dify的LLM-RAG多轮对话需求解决方案(附代码)
- Dify大模型开发技巧:约束大模型回答范围
- 以API形式调用Dify项目应用(附代码)
- 基于Dify的QA数据集构建(附代码)
- Qwen-2-7B和GLM-4-9B:大模型届的比亚迪秦L
自从去年参与大模型研发,有一定的感触,总的来说模型、开源模型能力越来越强了,作为应用开发者,应用性能水涨船高,乐。
需要注意的是,模型能力提升路径分为2种:
1.随着参数量增加模型能力不断增加。典型的如Qwen 1.5系列,7B 14B 32B 110B,随着模型参数量的提升,其效果也越来越强。实测下,7B到14B其性能是飞跃性的,实际体感上,Qwen-1.5-14B已经是非常好用的模型了。当然目前我们的应用开发工作往往是采用Qwen-1.5-32B,其性能强到在大量场景下我感觉不到和开源API的差距。
2.参数量不增加或不明显增加,但通过知识蒸馏等手段提高模型性能。典型如Qwen1.5系列升级为Qwen2系列;GLM升级到4系列。由于模型参数的扩大伴随的是算力资源的紧张,如果能够在有限的资源上实现更优质的问答,那无疑是好事。所以这类提升也是非常有意义的。
毕竟7-9B只需要一张4090,14B需要两张,32B就需要四张了。而且少量参属下微调的难度也大大降低。

https://modelscope.cn/organization/qwen
Qwen2今早发布,其优势如下:
-
5个尺寸的预训练和指令微调模型,
包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B; -
在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据;
-
多个评测基准上的领先表现;
-
代码和数学能力显著提升;
-
增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)

这里值得一提的是,阿里着重强调了72B和7B的Qwen2模型横向对比指标。
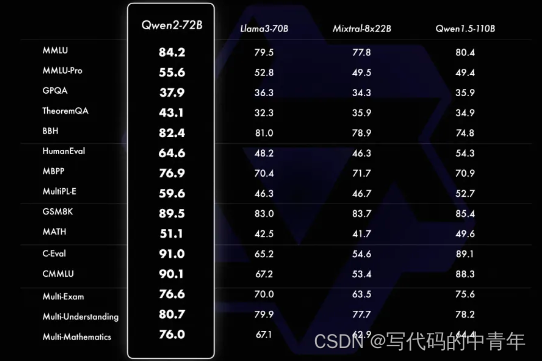
相较于自家产品Qwen1.5 110B毫不留情,Qwen-2-72B全面碾压。

这里是最搞笑的,毫无疑问同为10B以下的大语言模型,1天前引起热度的GLM-4-9B被拿来当作了比较竞品。Qwen-2-7B在参数少2B情况下,评测上的表现优于GLM-4-9B。
最后讲一下实际使用体感。
我们第一时间部署了GLM-4-9B到本地服务器,将之前的项目替换LLM引擎,在使用上GLM-4-9B表现较好,不如Qwen-1.5-32B,但也可以支撑起整个应用流程,大概到了Qwen-1.5-14B的水平。
感觉Qwen-2-7B和GLM-4-9B的接连发布,有点比亚迪秦L内卷能耗的感觉,入行一周年,深感这一年间大模型行业发展迅速。不论从模型能力上和应用开发体系上,都逐渐累加了更多的内容。
如今大模型应用已经可以初步落地,希望后续伴随着性能的提升,落地成本可以更低、模型可用性可以更高,行业具备更多的商业价值!

