
- 1AI在创造还是毁掉音乐?合作与辅助才是正道的光
- 2仓颉语言的编译和构建_仓颉编译器
- 3小爱图片翻译“大”“大”升级
- 4【跟我学RISC-V】(三)openEuler特别篇_obs risc-v openeuler
- 5探秘OneDev:自我托管的Git服务器,集Kanban与CI/CD于一身
- 6hive安装,启动失败错误及解决办法汇总_hive启动失败
- 7试卷扫描去掉痕迹,这个工具很好用
- 8OC桥接Swift学习记录_swiftui项目 oc框架 桥接文件 如何使用
- 9STM32F407HAL库-1.启动文件解析_下列哪个文件是stm32f407复位后最先执行的文件?
- 10MoneyPrinterPlus:AI自动短视频生成工具-微软云配置详解
redis之缓存_redis缓存
赞
踩
1. 前言
reids 是基于内存的数据库,它的特性之一就快,缓存是其最主要的应用场景,本文主要介绍 redis 的缓存特性,以及该如何正确的使用它。
2. 缓存类型
2.1 只读缓存
当写入数据时,直接操作后端数据库,进行增删改。删和改操作,如果 redis 已经缓存了对应的数据,则需要进行删除。当应用读取数据时,发生缓存缺失,则会从后端数据库读取到 redis 中使用。
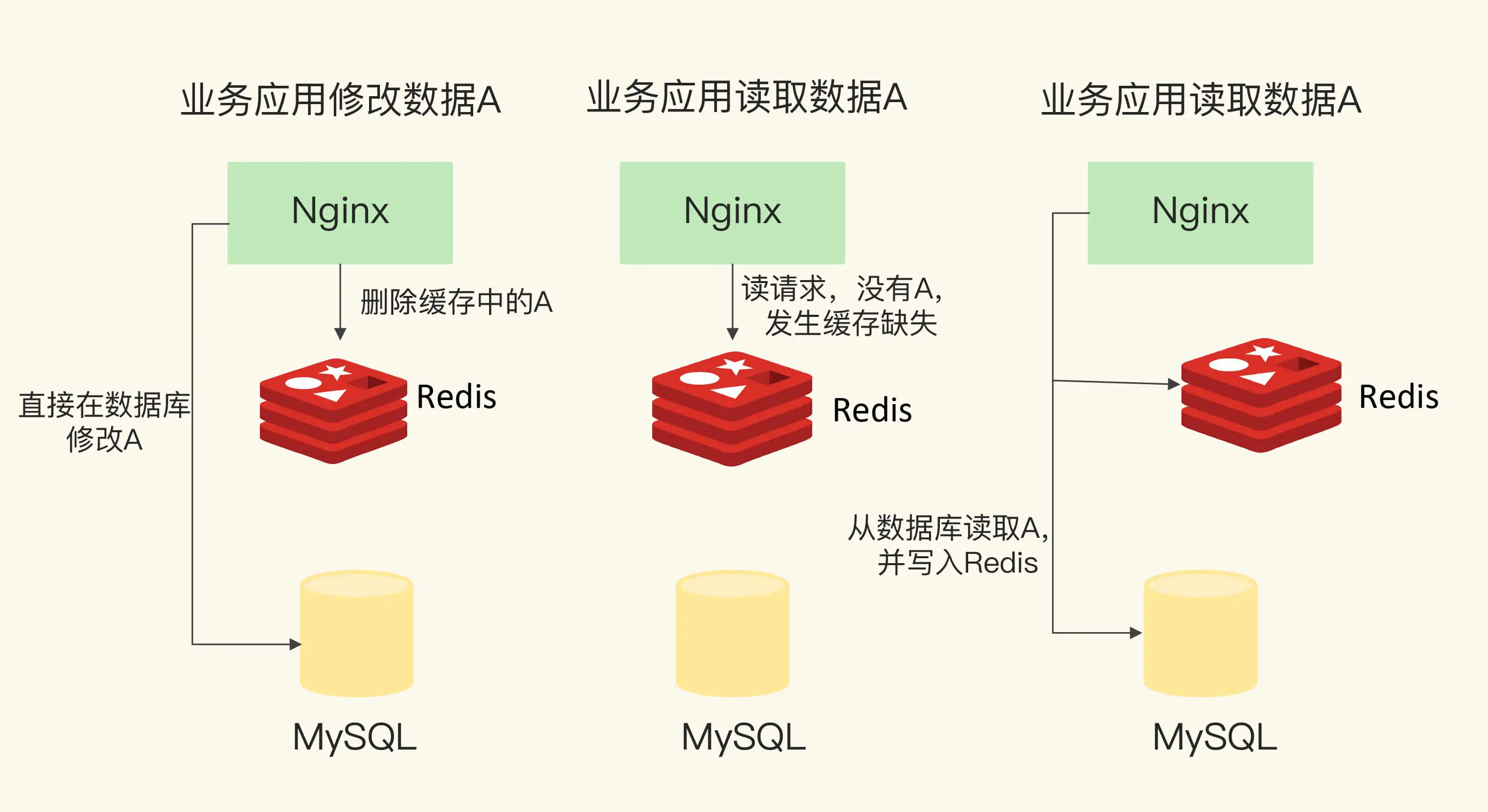
好处是所有的数据都在后端数据库中,而后端数据提供可靠性保障,不会有丢失数据的风险。
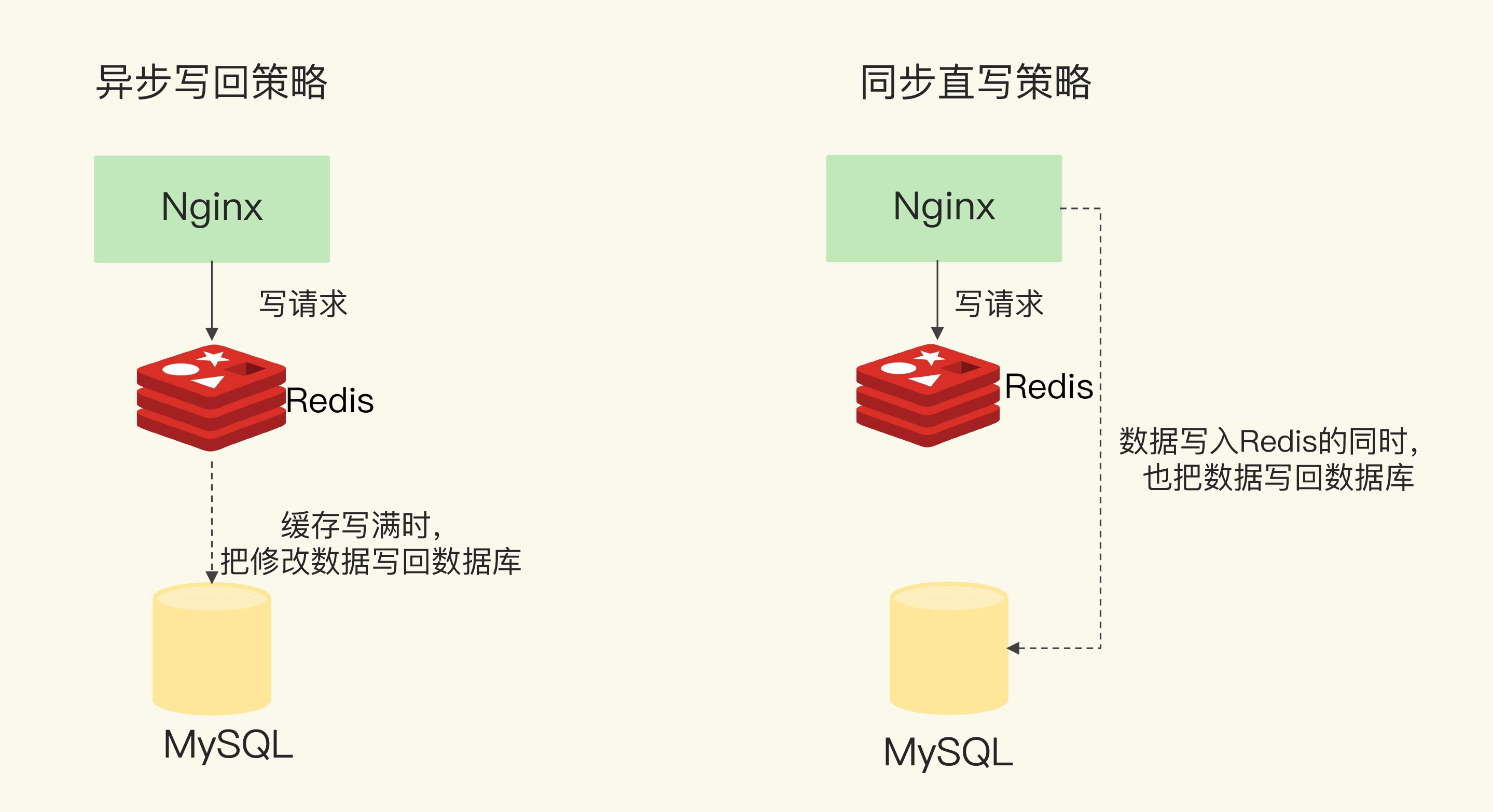
2.2 读写缓存
最新的数据在 redis 中。在写入数据时,优先写入到 redis,并且因为缓存的高性能访问,可以快速返回给业务应用。
但是由于 redis 是内存数据库存在数据丢失的风险,所以还是需要写入到后端数据库中保证可靠性。有两种写入策略:
- 同步直写:在写 redis 时,同步写入到后端数据库,完成后再返回给业务。会增加响应延迟。
- 异步直写:等待增改的数据要被从缓存淘汰时。再写回后端数据库。
2. 缓存和数据库的数据一致性
2.1 哪些情况会导致数据不一致 ?
-
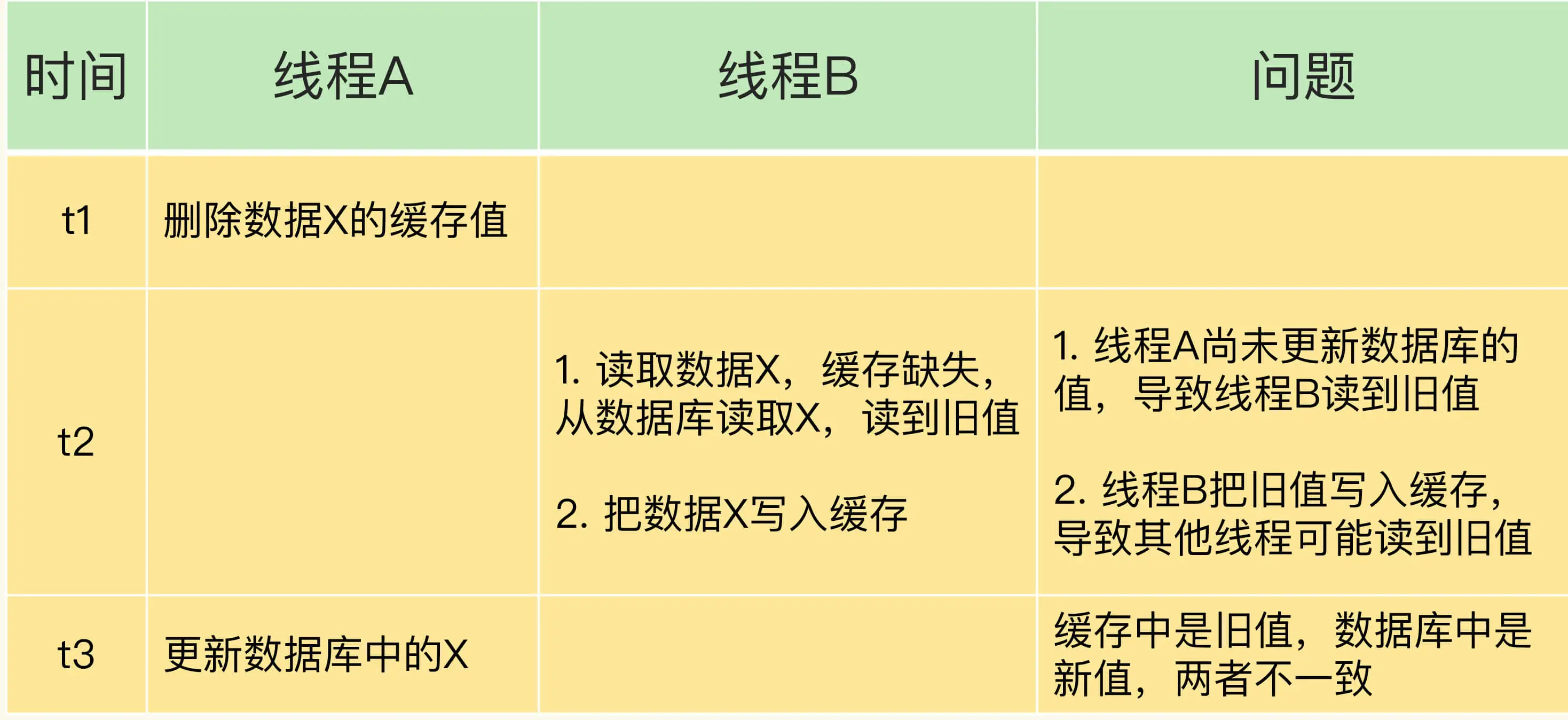
我们假设应用先删除缓存,再更新数据库,如果缓存删除成功,但是数据库更新失败,那么,应用再访问数据时,缓存中没有数据,就会发生缓存缺失。然后,应用再访问数据库,但是数据库中的值为旧值,应用就访问到旧值了。
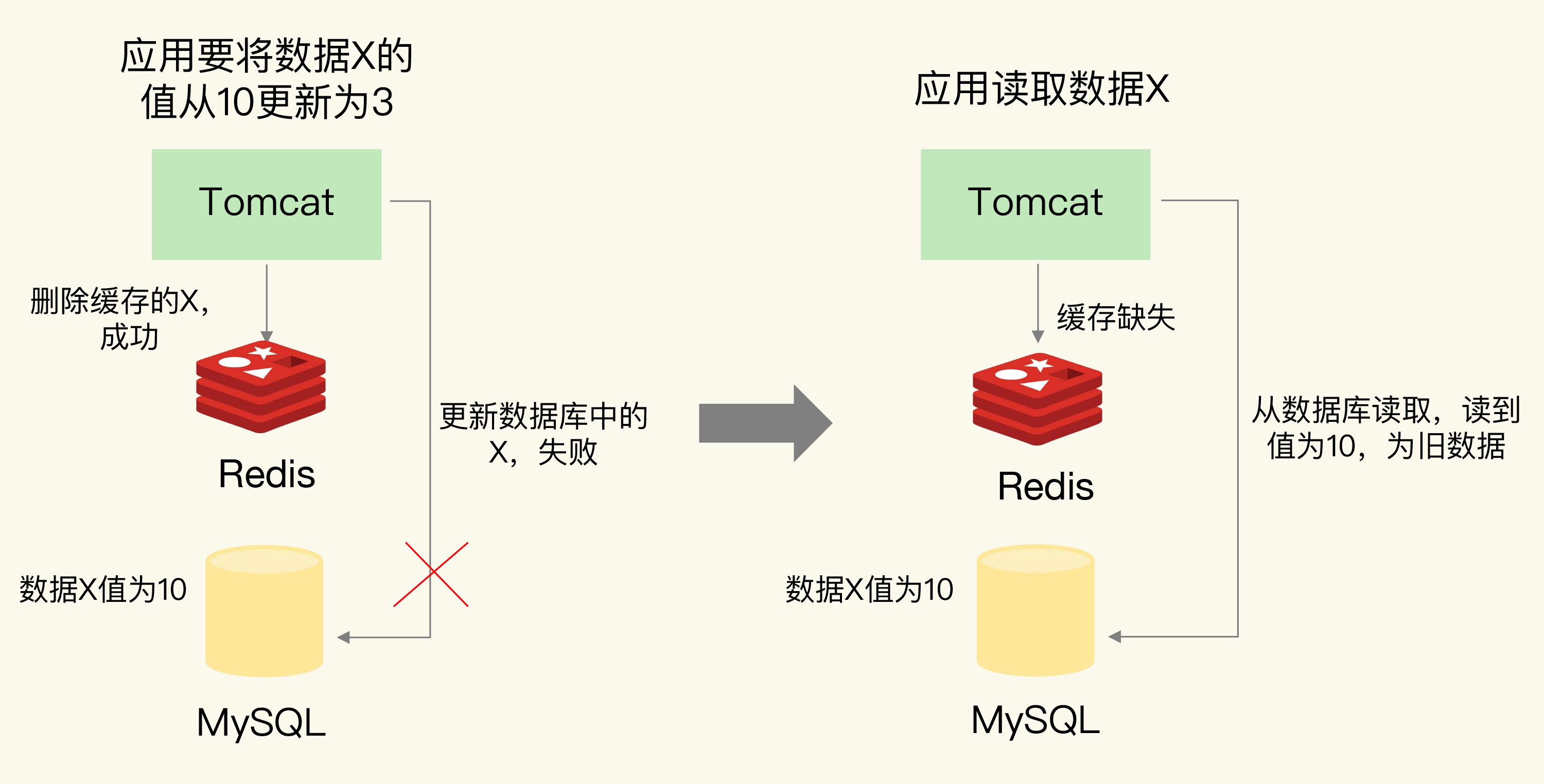
-
如果应用先完成了数据库的更新,但是,在删除缓存时失败了,那么,数据库中的值是新值,而缓存中的是旧值,这肯定是不一致的。这个时候,如果有其他的并发请求来访问数据,按照正常的缓存访问流程,就会先在缓存中查询,但此时,就会读到旧值了。
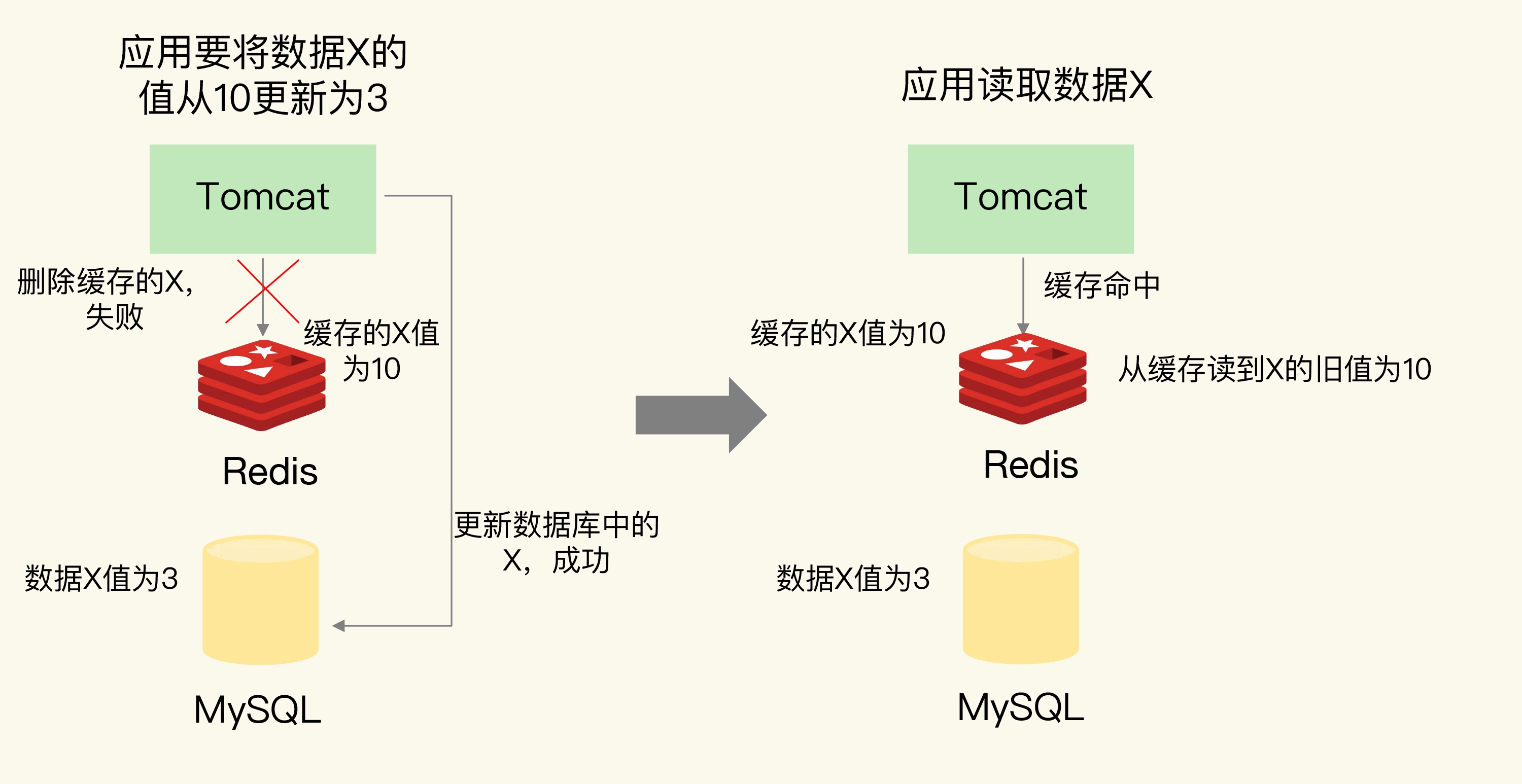
2.3 队列+重试机制
可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用 Kafka 消息队列)。当应用没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作
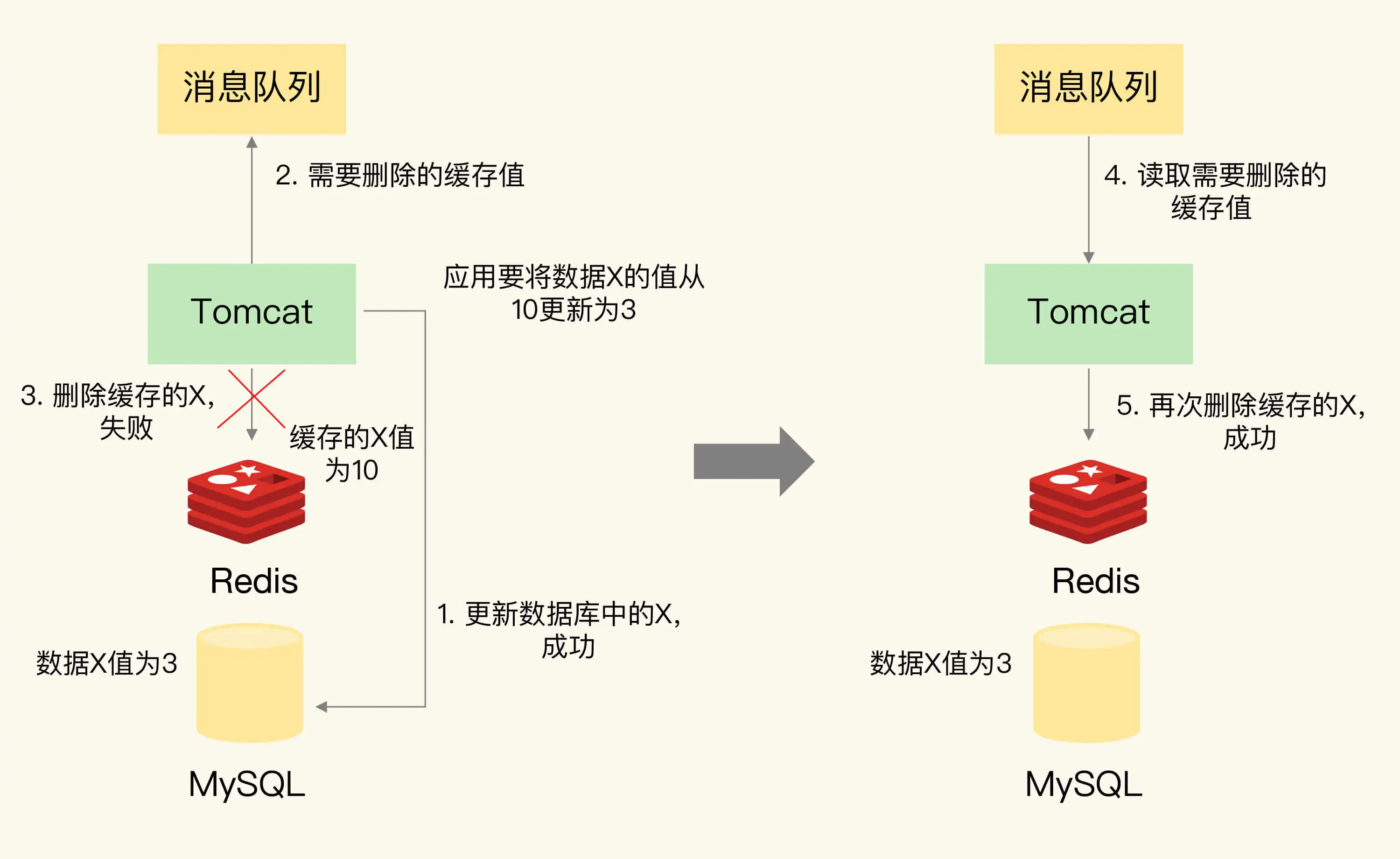
但是在并发情况下,无论是先删数据库还是先删缓存操作失败的情况下,还是会有读取到不一致数据的情况。
- 情况一,先删除缓存,再更新数据库。
在更新数据库失败的情况下,另一个线程进来读取数据,发现缓存缺失,查询数据库的数据,并更新到缓存中,最终缓存中存储的是旧的数据。
延迟双删
在线程 A 更新完数据库的值以后,再让它 sleep 一会儿,再删除缓存。目的是为了让线程 B 可以将数据库的值写入到缓存中,然后再删除它。
伪代码如下:
redis.delKey(X)
db.update(X)
Thread.sleep(N)
redis.delKey(X)
- 1
- 2
- 3
- 4
网上有使用这种方案来解决,个人是不推荐这种方案,在高并发的情况下,这个 sleep 时间不好确定,并不知道其他线程什么时候执行和结束。
- 情况二,先更新数据库值,再删除缓存值。
在删除缓存值失败的情况下,并发时,会有多个线程拿到旧的数据情况。

这两种并发场景,个人感觉唯一的办法就是使用同步来完成这两个操作,可以使用分布式锁或者其他。
3. 淘汰策略
缓存的容量是有限的,那么当缓存满了,可以是用淘汰策略来将部分数据淘汰。
缓存设置成多大比较合适?
按照二八原理,一般 20%数据会占用 80%的访问,所以建议将缓存的容量设置为总数据量的 15%或者 30%会比较合理。
淘汰策略有哪些?
- 不淘汰
- noeviction,如果缓存已满再有写请求,则返回错误
- 对设置过期时间的数据进行淘汰
- volatile-ttl 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random 就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru 会使用 LRU 算法筛选设置了过期时间的键值对。
- volatile-lfu 会使用 LFU 算法选择设置了过期时间的键值对。
- 对搜有数据进行淘汰
- allkeys-random 策略,从所有键值对中随机选择并删除数据;
- allkeys-lru 策略,使用 LRU 算法在所有数据中进行筛选。
- allkeys-lfu 策略,使用 LFU 算法在所有数据中进行筛选。
4. 缓存雪崩
缓存雪崩是指大量的应用请求无法在 Redis 缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。
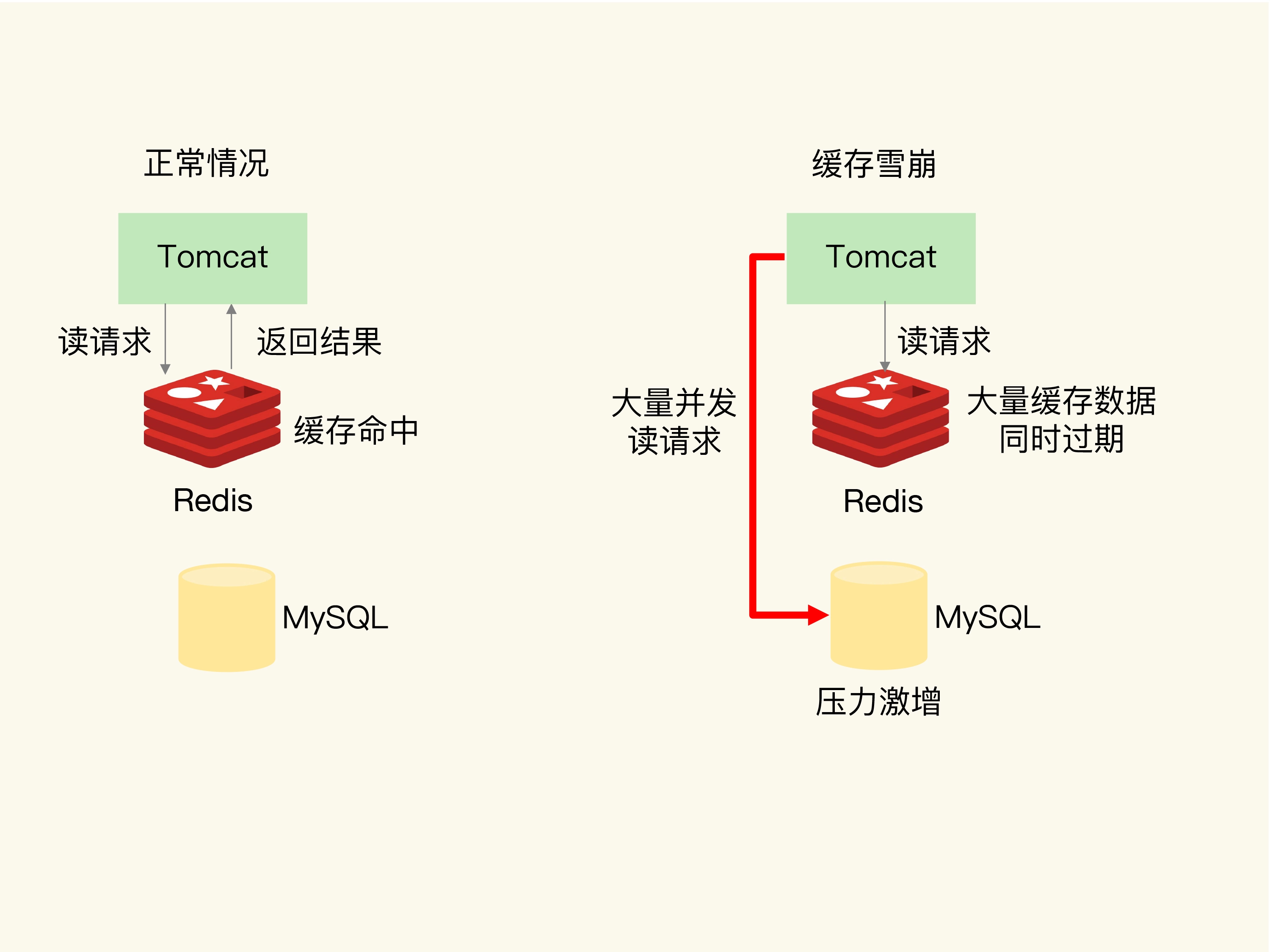
产生的原因
- 缓存中有大量数据同时过期,导致大量请求无法得到处理
- redis服务宕机
发生后有损解决办法
- 是在业务系统中实现服务熔断或请求限流机制。
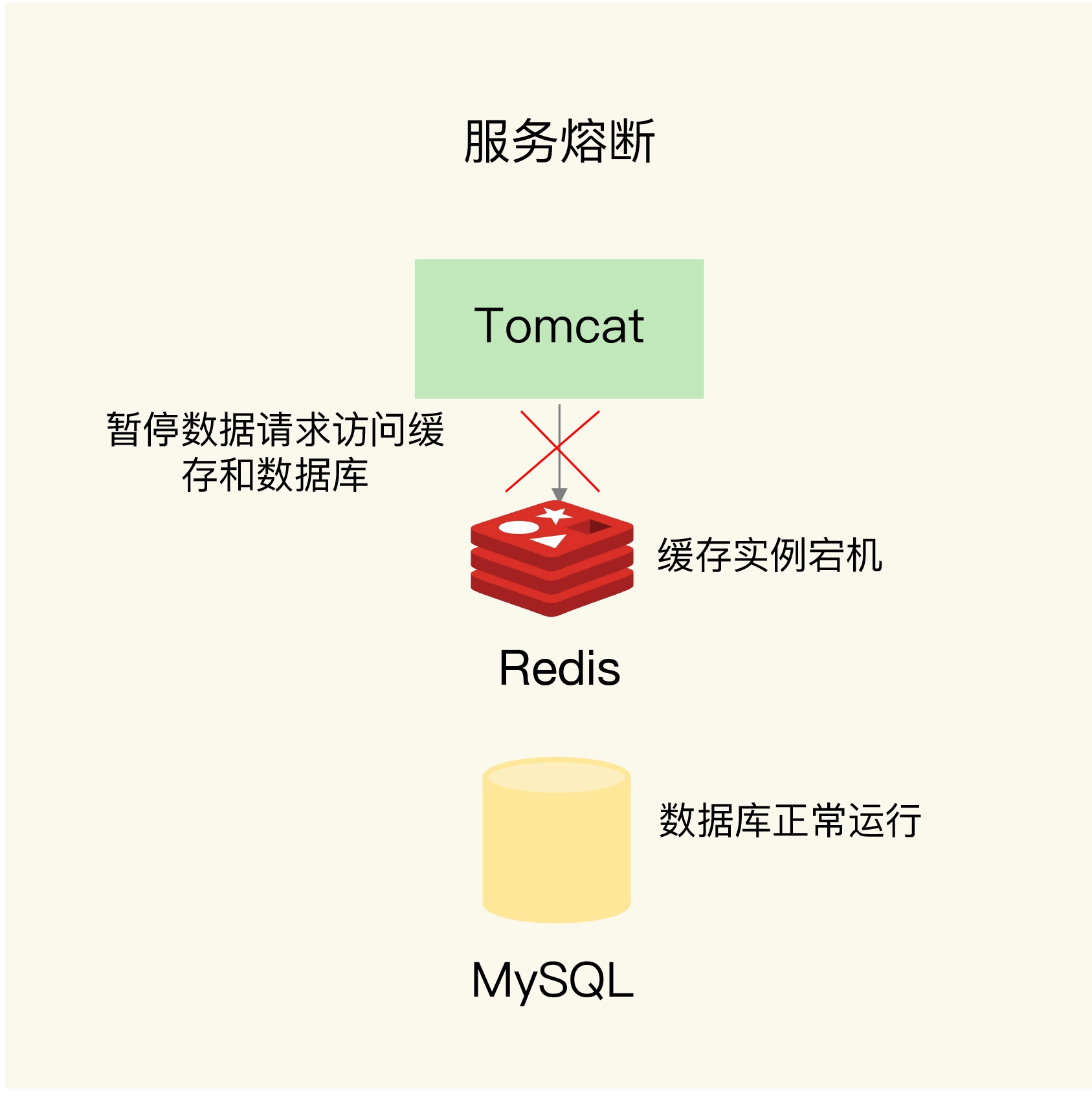
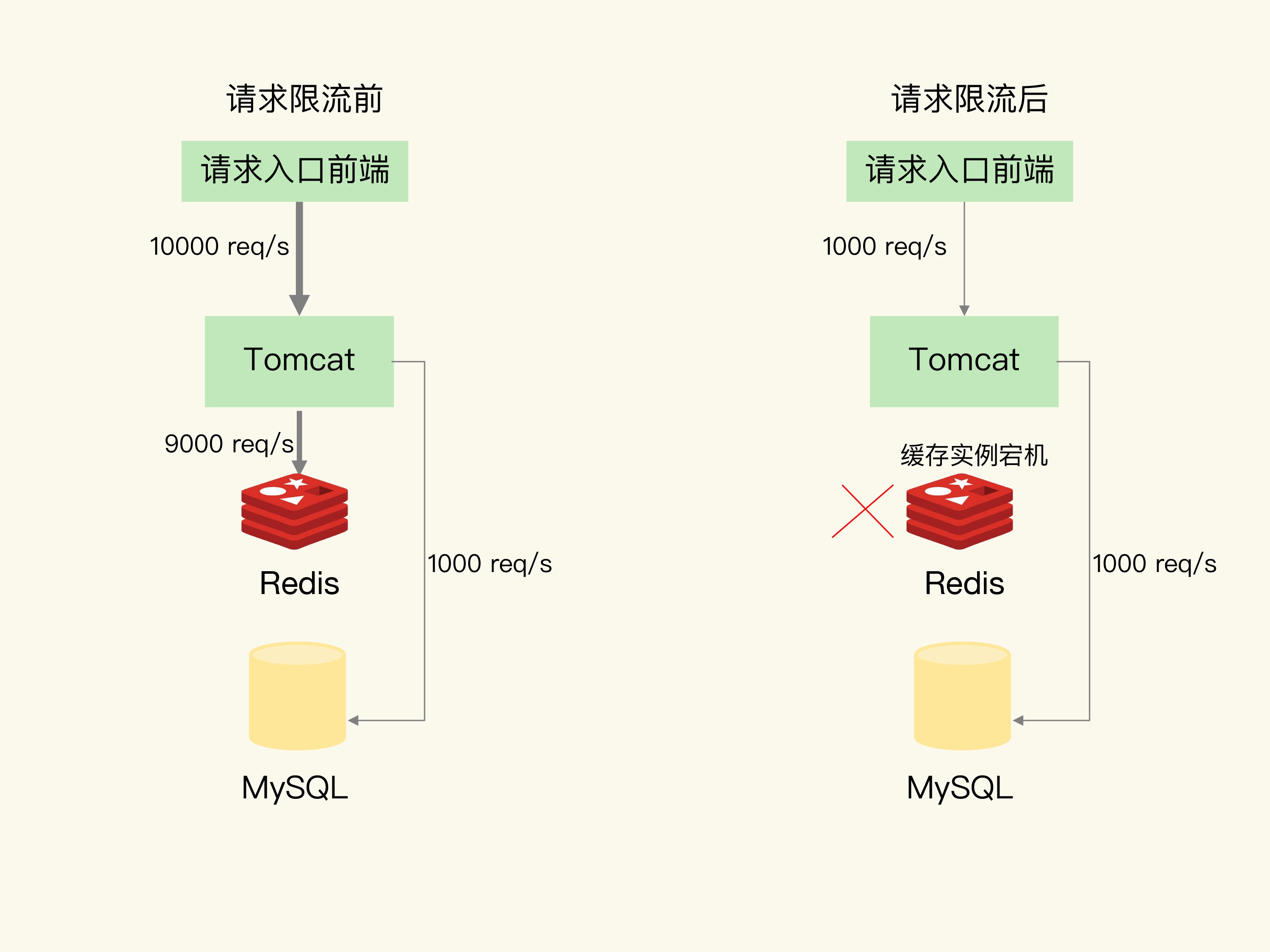
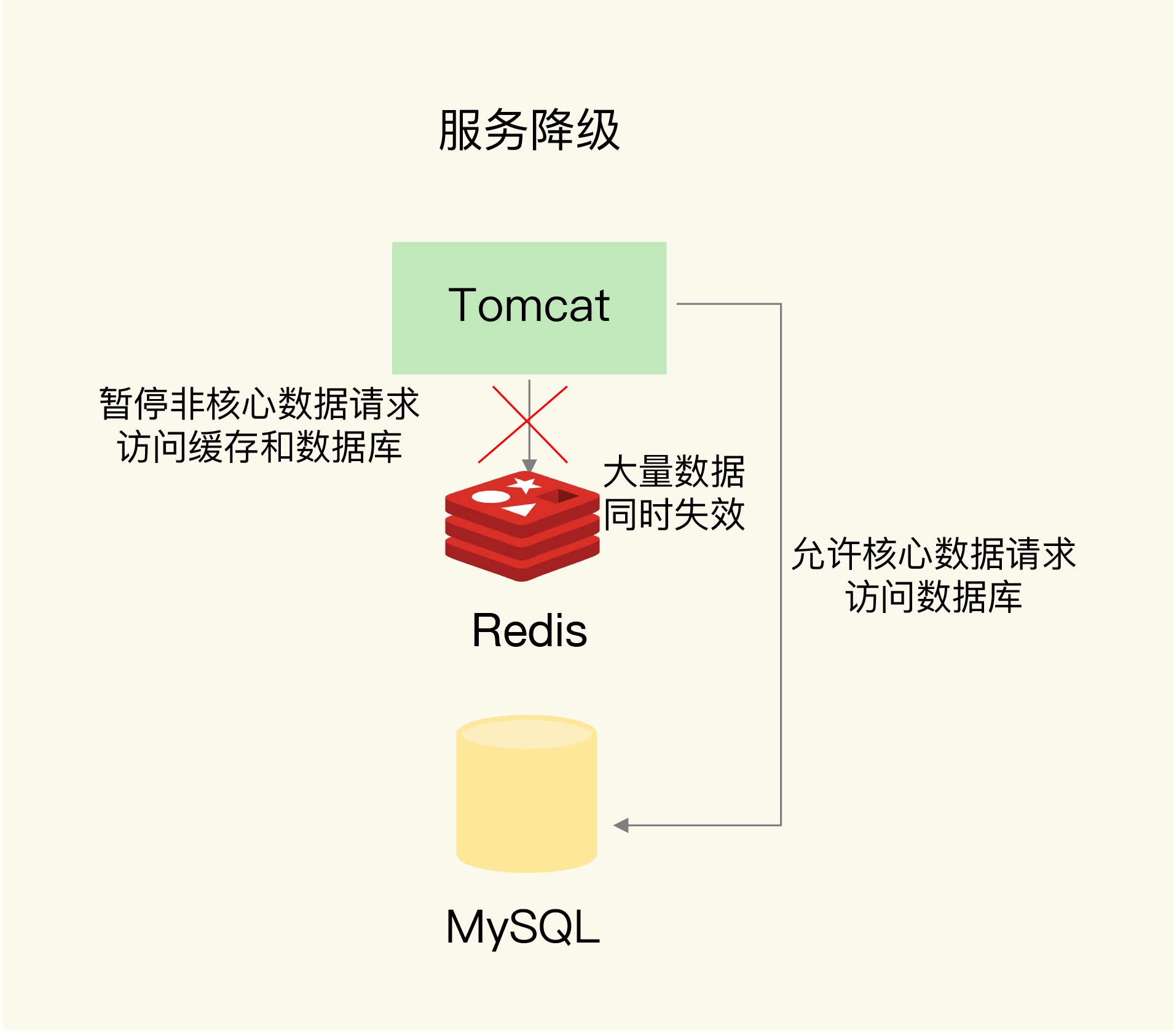
- 服务降级。非核心数据,直接返回预定义信息,错误或空值。核心业务仍然查询缓存。减少数据库压力
提前预防
上面的都是发生后有损的解决措施,所以最好的办法是提前预防,让它不要发生。
- 避免大量数据设置相同点额过期时间,如果有,可以加个随机数。
- 搭建高可用集群,主节点故障宕机,从节点可以切换成主节点,继续提供缓存服务。
5. 缓存击穿
缓存击穿是指,针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求,一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求。缓存击穿的情况,经常发生在热点数据过期失效时

产生的原因
- 热点数据发生过期被淘汰导致访问后端数据库
发生后有损的解决办法
- 接口限流与熔断,降级。
提前预防
- 设置热点数据永远不过期。
6. 缓存穿透
缓存穿透是指要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。
产生的原因
- 业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
- 恶意攻击:专门访问数据库中没有的数据。
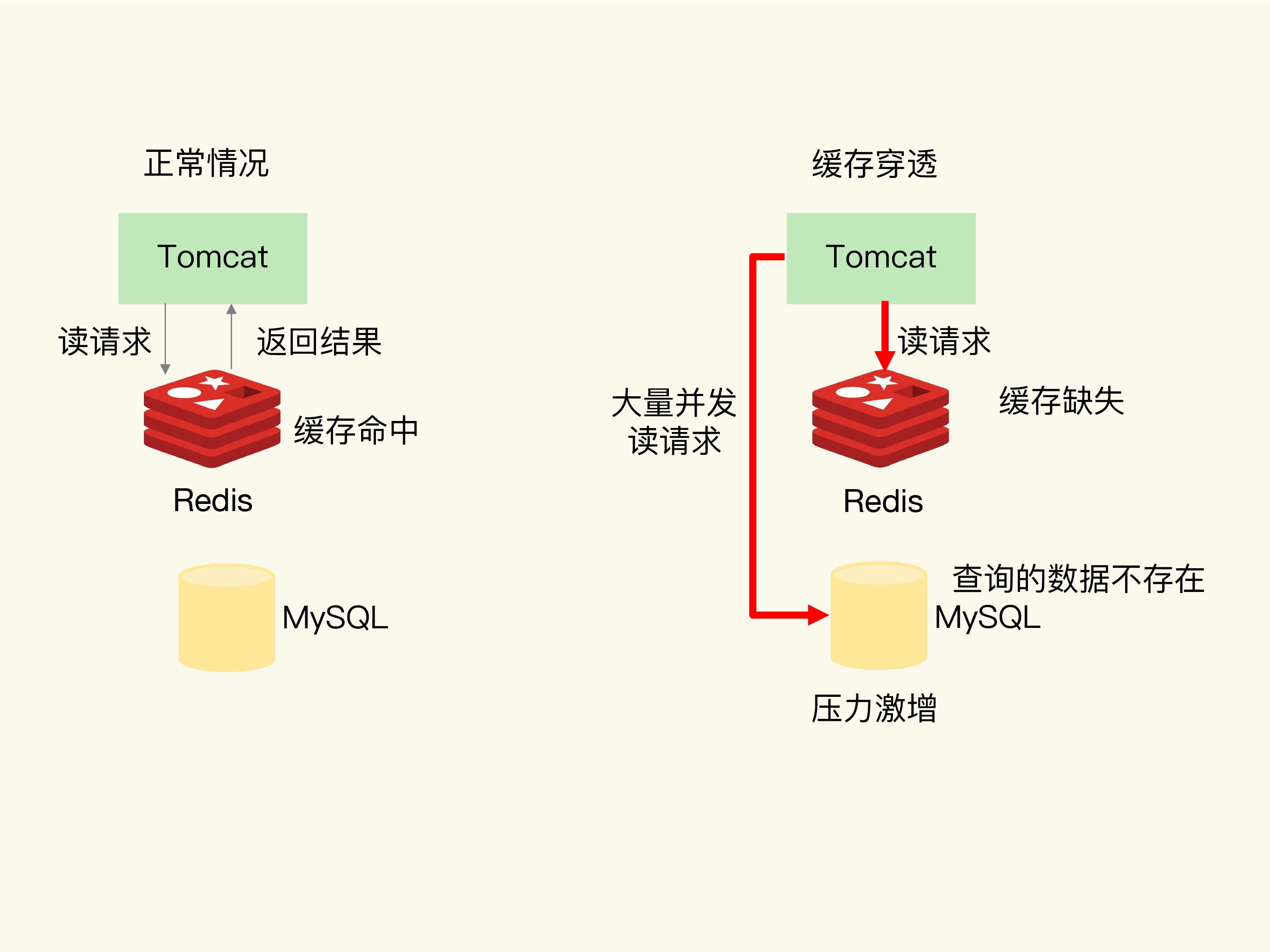
应对方案
- 在请求入口做合法性校验,把恶意请求过滤掉。
- 布隆过滤器,快速校验数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。
- 一旦发生数据不存在的情况,可以缓存一个缺省值,下次还使用该 ID 访问时,可以返回缺省值。
7. 参考文章
- 本文主要是学习《极客时间-redis 核心技术与实战》专栏总结而来

