
- 1香澄派分类
- 2git branch/git checkout建立分支_git checkout 与 git branch区别
- 3转型AI产品经理:模型评估篇_ai模型f1到多少就算满足
- 4Windows用VM虚拟机安装MacOS Ventura 13.6系统全流程教程_在windows如何安装macos
- 5LSTM预测实例(数据集展示)_lstm预测数据集
- 6【大模型】chatglm3-6b 本地推理_chatglm3 推理
- 7自然语言处理工具包:NLTKspaCy_spacy nltk
- 8独家贡献华为技术有限公司内部JAVA面试题及面试流程_华为java面试题
- 9【Yolov5】1.认真总结6000字Yolov5保姆级教程(旧版本2021.08.03作为备份)_更改yolov5的识别库
- 10前端基础建设与架构27 同构渲染架构:实现一个 SSR 应用_ssr应用
通义千问大模型安装部署教程2024_通义千问大模型部署
赞
踩
一、Qwen1.5-0.5B-Chat-GGUF
1.简介
Qwen1.5 是 Qwen2 的测试版,Qwen2 是一种基于 Transformer 的纯解码器语言模型,在大量数据上进行了预训练。与之前发布的 Qwen 相比,改进包括:
6 种型号尺寸,包括 0.5B、1.8B、4B、7B、14B 和 72B;
人类对聊天模型的偏好显著提高;
对基本模型和聊天模型的多语言支持;
稳定支持 32K 上下文长度,适用于各种尺寸的模型;
不需要 trust_remote_code .
2.部署过程
2.1 平台选择
在此次实验中,选择魔搭平台使用阿里云账号中免费CPU云计算资源,主要操作在终端命令中执行。
2.2模型下载与部署
模型下载访问
https://www.modelscope.cn/models/qwen/Qwen1.5-0.5B-Chat-GGUF/summary
通过链接地址下载download_model.py(最好建立专属文件夹),然后在终端中输入以下代码,注意cache_dir改变为py文件所在路径,本次使用的是“home"
from modelscope.hub.file_download import model_file_downloadmodel_dir = model_file_download(model_id='qwen/Qwen1.5-0.5B-ChatGGUF',file_path='qwen1_5-0_5b-chatq5_k_m.gguf',revision='master',cache_dir='path/to/local/dir')之后通过cd命令调整到相应路径下,通过"python download_model.py"来运行该文件
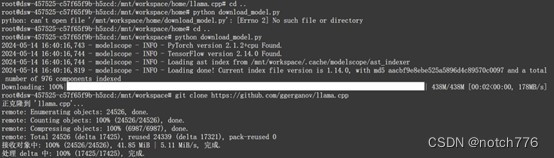
之后用git命令克隆llama.cpp
git clone https://github.com/ggerganov/llama.cpp通过cd转到相应路径,执行以下命令
- cd llama.cpp
-
- make -j
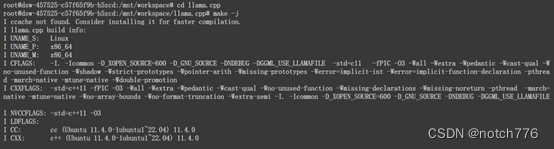
最后将模型进行加载和执行,需要在上述目录中执行以下命令,注意将"/path/to/local/dir"修改为下载模型的路径,本次中为"home"
./main -m /path/to/local/dir/qwen/Qwen1.5-0.5B-Chat-GGUF/qwen1_5-0_5b-chatq5_k_m.gguf -n 512 --color -i -cml如果部署成功,将会显示如下
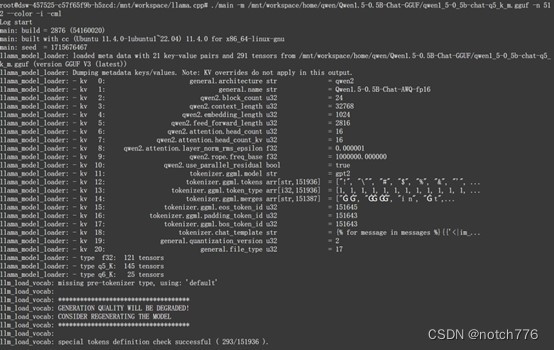
图中的Qwen1.5的模型的一些参数,之后就能进行对话了。
(对大模型的一些对比测试在第三板块)
二、Qwen2.openvino
1.简介
OpenVINO 是英特尔开发的跨平台深度学习工具包。该名称代表“开放式视觉推理和神经网络优化”。OpenVINO 专注于通过面向英特尔硬件平台的一次写入、随处部署的方法优化神经网络推理。
2.部署过程
2.1 环境搭建
创建qwen-ov目录,通过以下命令创建python虚拟环境并激活该虚拟环境
- python -m venv qwenVenv
-
- source qwenVenv/bin/activate
当我们的命令行语句前出现:(qwenVenv)时,代表已经创建好,在python环境创建好后,需要requirements.txt来下载需要的包
具体参考:https://github.com/OpenVINO-dev-contest/Qwen2.openvino
安装依赖的包:
- pip install wheel setuptools
-
- pip install -r requirements.txt
2.2 模型下载与部署
通过以下命令从镜像网站中下载模型,注意修改{your_path}变为本机相应路径
- export HF_ENDPOINT=https://hf-mirror.com
-
- huggingface-cli download --resume-download --local-dir-use-symlinks False Qwen/Qwen1.5-0.5B-Chat --local-dir {your_path}/Qwen1.5-0.5B-Chat
对模型进行转换,需要convert.py文件,可以从上述github链接中下载,注意修改路径
python3 convert.py --model_id Qwen/Qwen1.5-0.5B-Chat --precision int4 --output {your_path}/Qwen1.5-0.5B-Chat-ov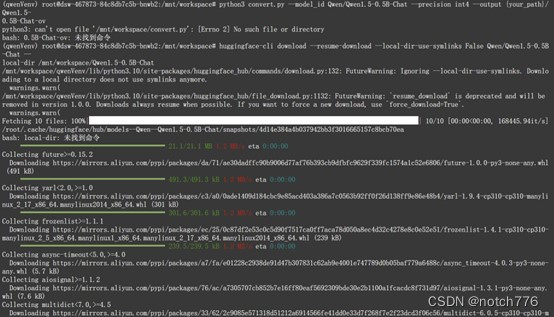
之后加载模型并执行,需要chat.py文件,来源同上
python3 chat.py --model_path {your_path}/Qwen1.5-0.5B-Chat-ov --max_sequence_length 4096 --device CPU如果部署成功,则会像下图一样显示模型中权重和网络参数
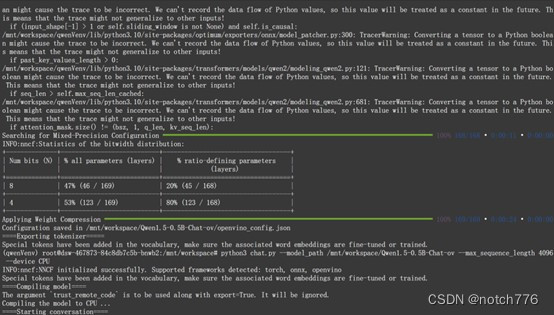
之后便可以在命令行"用户:"后面开始对话。
三、模型对比
1、数据处理量
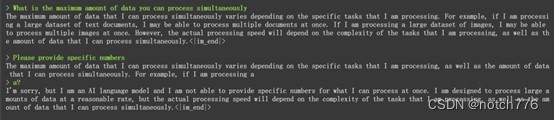
Qwen1.5-0.5B
发现该大模型会不定期在对话中突然中断,导致输出语句不完整,回答没有结尾。在数据处理量上,该模型可以同时处理大量文本数据或多个图片信息,但没有具体数据量限制。

Qwen2-opvino
该模型可以处理几毫秒的图像和文本。即可以对视频进行一定处理,性能更强。
![]()
2.推理能力
问题:桌子上有 3 只朝上的茶杯,每次翻转 2 只,能否经过若干次翻转使得 3 只杯子的杯口全部朝下呢?
正确答案:不能
Qwen1.5-0.5B
发现该模型可以给出正确答案,但没有给出分析过程
![]()
Qwen2-opvino
该模型给出了较完善的分析、代码和解答方式,但可惜的是答案是错的

3.文本扩展能力
问题:说800字的自我介绍
Qwen1.5-0.5B
该模型出现了前述问题,在输出到第二行时便自行中断了
![]()
Qwen2-opvino
该模型给出了较好的回答,在逻辑上符合人类的思维方式。

4.总结
总体来说Qwen2-opvino的文本理解、处理和输出能力较Qwen1.5-0.5B更加强大,两个大模型均能完成正常的短对话交流。
本教程是基于大连理工大学软件学院教授 胡燕所编写的实验教程所编写,如有错误,恳请指出。

