
热门标签
热门文章
- 1自然语言处理(NLP)语义分析--文本分类、情感分析、意图识别_文本的语义识别、分割和分析
- 2第十三章:HBase的基本数据结构与数据模型
- 3浅谈生成式人工智能_浅谈生成式人工智能:原理、应用与发展2500字
- 4Leetcode 2520. 统计能整除数字的位数
- 5ijkplayer播放rtsp视频_ijkplayer 播放rtsp
- 6非功能性要求是什么?
- 7群晖linux ——设置短密码、免密码登录、多个群晖免密登录_群晖设置简单密码
- 8贪吃蛇的实现—C语言_c语言贪吃蛇怎么通过f1f2控制加速减速
- 9ubuntu 18.04 Build WebRTC_webrtc m100
- 10斐讯n1刷鸿蒙系统,斐讯N12.28成功刷机 方法分享给大家
当前位置: article > 正文
Python爬虫——关键字爬取百度图片_如何爬取百度的logo图片
作者:码创造者 | 2024-07-09 02:23:47
赞
踩
如何爬取百度的logo图片
在日常生活中,我们经常需要使用百度图片来搜索相关的图片资源。而如果需要大量获取特定关键字的图片资源,手动一个个下载无疑十分繁琐且费时费力。因此,本文将介绍如何通过Python爬虫技术,自动化地获取百度图片。
要爬取的是百度图片,大概的思路就是得到要爬取的url、拿到网页源码、得到图片链接、保存图片。在做这些工作之前,我们要先导入需要的第三方库requests、re和os。下面我将教你如何一步一步实现。
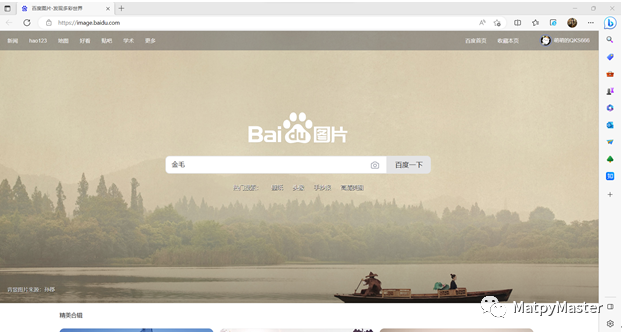
(1)打开百度图片首页百度图片-发现多彩世界 (baidu.com),输入金毛进行搜索:
(2)右键鼠标,选择检查,依次点击Network→Fetch/XHR,然后刷新一下网页:

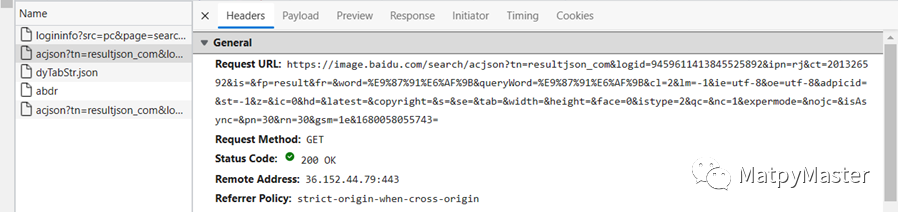
(3)点击以acjson开头的一行,查看Headers,可以看到Request URL信息如下:
(4)一直往下滑,在底部就是User-Agent:

完整的源代码如下:
- # -*- coding: utf-8 -*-
- """
- Created on Wed Mar 29 10:17:50 2023
- @author: MatpyMaster
- """
- import requests
- import os
- import re
-
- def get_images_from_baidu(keyword, page_num, save_dir):
- header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
- # 请求的 url
- url = 'https://image.baidu.com/search/acjson?'
- n = 0
- for pn in range(0, 30 * page_num, 30):
- # 请求参数
- param = {'tn': 'resultjson_com',
- 'logid': '7603311155072595725',
- 'ipn': 'rj',
- 'ct': 201326592,
- 'is': '',
- 'fp': 'result',
- 'queryWord': keyword,
- 'cl': 2,
- 'lm': -1,
- 'ie': 'utf-8',
- 'oe': 'utf-8',
- 'adpicid': '',
- 'st': -1,
- 'z': '',
- 'ic': '',
- 'hd': '',
- 'latest': '',
- 'copyright': '',
- 'word': keyword,
- 's': '',
- 'se': '',
- 'tab': '',
- 'width': '',
- 'height': '',
- 'face': 0,
- 'istype': 2,
- 'qc': '',
- 'nc': '1',
- 'fr': '',
- 'expermode': '',
- 'force': '',
- 'cg': '', # 这个参数没公开,但是不可少
- 'pn': pn, # 显示:30-60-90
- 'rn': '30', # 每页显示 30 条
- 'gsm': '1e',
- '1618827096642': ''
- }
- request = requests.get(url=url, headers=header, params=param)
- if request.status_code == 200:
- print('Request success.')
- request.encoding = 'utf-8'
- # 正则方式提取图片链接
- html = request.text
- image_url_list = re.findall('"thumbURL":"(.*?)",', html, re.S)
-
- if not os.path.exists(save_dir):
- os.makedirs(save_dir)
-
- for image_url in image_url_list:
- image_data = requests.get(url=image_url, headers=header).content
- with open(os.path.join(save_dir, f'{n:06d}.jpg'), 'wb') as fp:
- fp.write(image_data)
- n = n + 1
- if __name__ == "__main__":
- keyword = '金毛'
- page_num = 1
- page_num = int(page_num)
- save_dir = '.\\图片\\'+keyword
- get_images_from_baidu(keyword, page_num, save_dir)

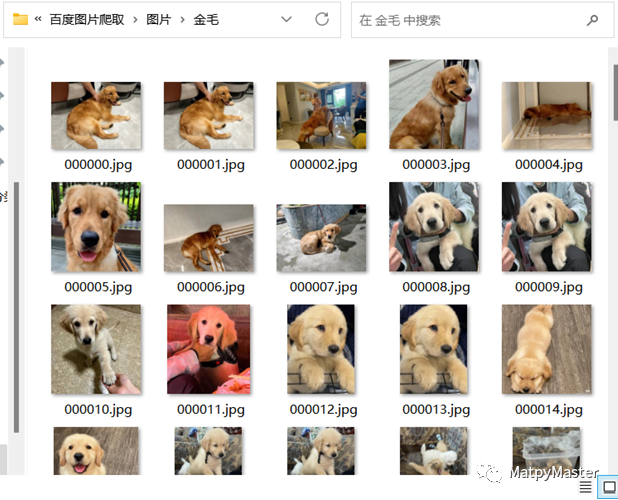
设置好关键字keyword和爬取页数page_num,运行代码就可以了,最后会在将爬取的图片以关键字为名创建一个文件夹保存至图片文件夹。
最后:
如果你想要进一步了解Python爬虫的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/801111
推荐阅读
相关标签

