
热门标签
热门文章
- 1Kafka Tool--可视化监控管理工具
- 2接口自动化常见面试题1_java接口自动化测试面试题
- 3maven本地安装jar包install-file,解决没有pom的问题_pom was created from install:install-file
- 4Labwindows/CVI基础教程(1)
- 52.5.3 PCIe——物理电气子层——动态均衡_pcie preset p0到p10的区别
- 6机器学习与深度学习:区别与联系(含工作站硬件推荐)_7个pcie插槽 机箱 双路gpu
- 72024年全网最全Java面试总结及答案【建议收藏】,2024年最新4轮面试怎么安排的_java面试2024
- 8Python学习指南:6个步骤快速上手
- 9关于《Swift开发指南》背后的那些事_swift开发指南习题答案
- 10项目实战 | Python爬虫+PythonWeb+百度AI:前后端实现一个简单的“智能菜谱”网站
当前位置: article > 正文
【清华大学】《自然语言处理》(刘知远)课程笔记 ——NLP Basics_清华大学自然语言处理课程
作者:码创造者 | 2024-07-10 02:35:00
赞
踩
清华大学自然语言处理课程
自然语言处理基础(Natural Language Processing Basics, NLP Basics)
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
为什么NLP重要(Why is NLP Important?)
- Turing Test:A test of machine ability to exhibit intelligent behavior indistinguishable from a human
- Language is the communication tool in the test
艾伦图灵的最早版本:Imitation Game。
卷福也拍过这部电影Imitation Game,为了破解德军的军情信息,图灵和一群才华横溢的人研究如何破译密码,如果纯粹人工破解则几乎不可能,但是他们发明了最早的人工智能机器,通过大模型破译出原始信息,一开始该模型一直无法收敛,直到他们发现传递的信息中总会有“希特勒万岁”这句话之后,发现了大模型的初始条件,一举攻破该难题。

词的表达(Distributed Word Representation)
Word Representation
- Word representation: a process that transform the symbols to the machine understandable meanings
- Definition of meaning(Webster Dictionary)
-
- The thing one intends to convey especially by language
-
- The logical extension of a word
- How to represent the meaning so that the machine can understand?
Goal of Word Representation
- Compute word similarity,计算词的相似度
- Infer word relation,发现词的语义关系
Synonym and Hypernym
- Use a set of related words, such as synonyms and hypernyms to represent a word
用一组相关词(同义词/上位词)集合来表示它

Problems of Synonym/Hypernym Representation
- Missing nuance,有一些细微差异无法完成,比如proficient和good
- Missing new meanings of words,同义词/上位词出现新的词义会缺失实际含义,比如Apple(fruit —> IT company)
- Subjective,主观性问题
- Data sparsity,数据稀疏问题
- Requires human labor to create and adapt,需要大量人工构建和维护这个字典
One-Hot Representation
- Regard words as discrete symbols,把它看作独立的符号
- Word ID or one-hot representation,可以比较好的完成两个文档之间的相似的计算

Problems of One-Hot Representation
- similarity(star, sun) = (Vstar, Vsun) = 0,它的问题是假设词和词之间互相之间都是正交的,那么从而导致任意两个词进行相似度的计算都是零
- All the vectors are orthogonal.No natural notion of similarity for one-hot vectors.
Represent Word by Context
- The meaning of a word is given by the words that frequently appear close-by,一个词的词义经常跟这个词的上下文有密切关系。
- Use context words to represent stars,比如下图用上下文中的词表示stars这个词。

Co-Occurrence Counts
- Count-based distributional representation

- Term-Term matrix: How often a word occurs with another
- Term-Document matrix: How often a word occurs in a document
可以通过这个词出现次数得到的稠密向量算出两个词之间的相似度
Problems of Count-Based Representation
- Increase in size with vocabulary
- Require a lot of storage
- sparsity issues for those less frequent words
它的问题是当词表变得越来越大的时候,存储的需求就会越来越大。
而频次出现较少的词,它的上下文或者词的语境就会变得很稀疏。
Word Embedding,词嵌入
- Distributed Representation,分布式的表示
- Build a dense vector for each word learned from large-scale text corpora,建立起一个低维的一个稠密的向量空间,用这个空间里面的某一个位置所对应的那个向量来表示这个词。
- Learning method: Word2Vec(We will learn it in the next class)

Language Modeling
- Language Modeling is the task of predicting the upcoming word
语言模型的能力其实就是根据前面的词预测下面即将要出现的词- Compute conditional probability of an upcoming word Wn:
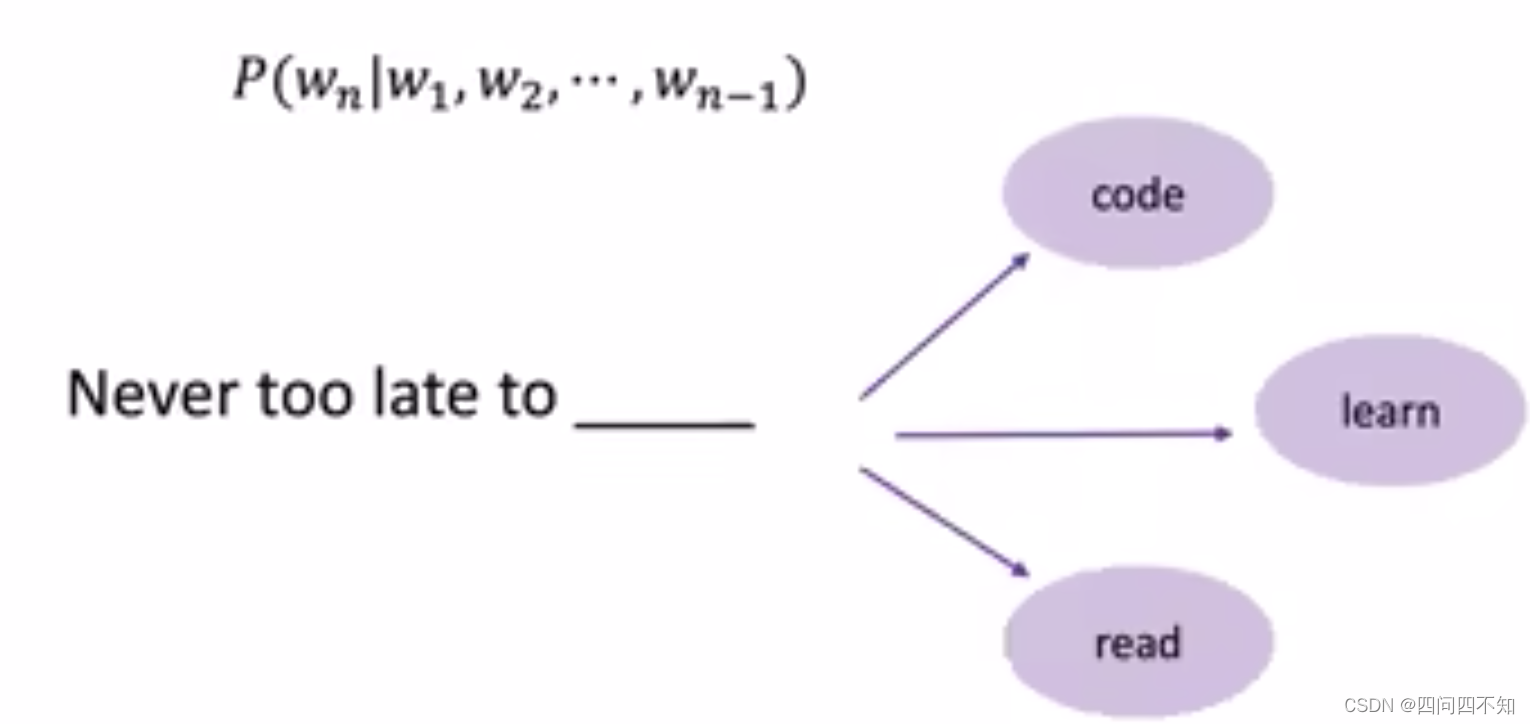
- Compute conditional probability of an upcoming word Wn:
- A language model is a probability distribution over a sequence of words
- Compute joint probability of a sequence of words:P(W) = P(w1,w2,…,wn) 它称为合法的一句话的概率,也即所有词的序列的联合概率
- Compute conditional probability of an upcoming words Wn:P(wn | w1,w2,…,wn-1),根据前面已经说过的词预测下一个词
- How to compute the sentence probability?
- Assumption:the probability of an upcoming word is only determined by all its previous words,未来的词它只会受到它前面的词的影响
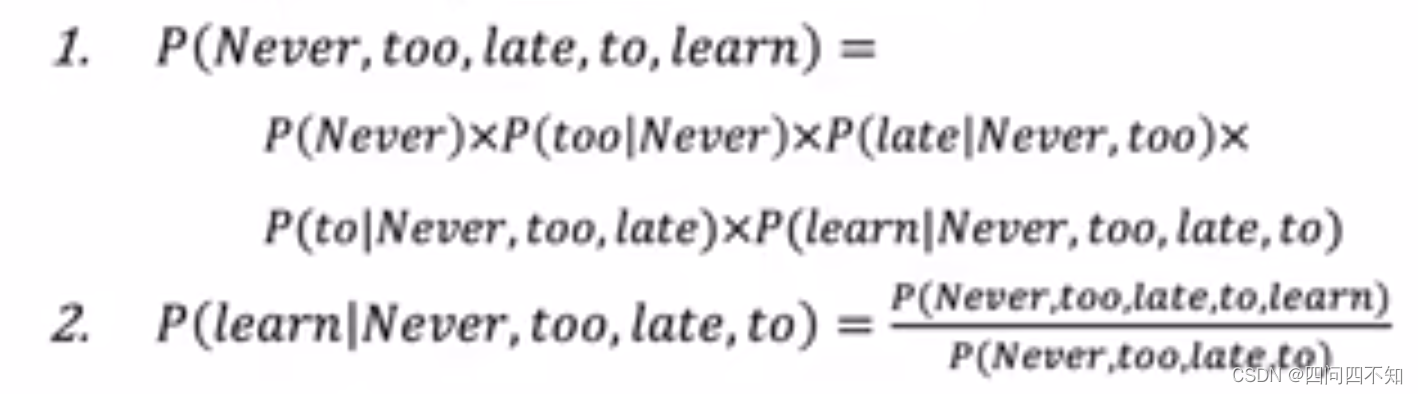
- Language Model
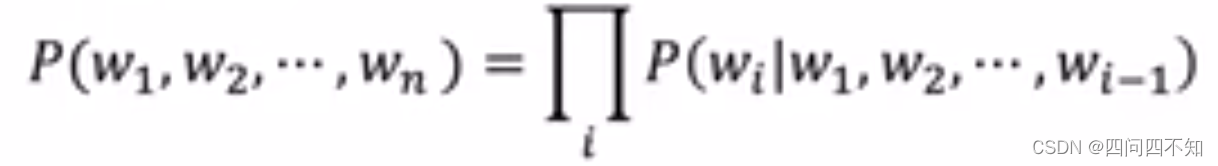
N-gram Model
- Collect statistics about how frequent different n-grams are, and use these to predict next word.
- E.g., 4-gram,比如4-gram,表达式如下,它会统计too late to wj的频次和too late to出现的频次的关系

-
Problem:
- Need to store count for all possible n-grams. So model size is O(exp(n))
-
Markov assumption,马尔可夫假设

- Simplifying Language Model
- Bigram(N-Gram,N=2)
- Trigram(N-Gram,N=3)
Problems of N-gram
- Not considering contexts farther than 1 or 2 words,很少考虑更多的历史,一般就用bigram或trigram,没有办法考虑较长的词的上下文。
- Not capturing the similarity between words,N-gram它的背后其实是一个典型的one-hot representation,它会假设所有的词都是相互独立的,它做统计的时候上下文其实都是基于符号来做统计的,它是没有办法理解这些词互相之间的相似度。
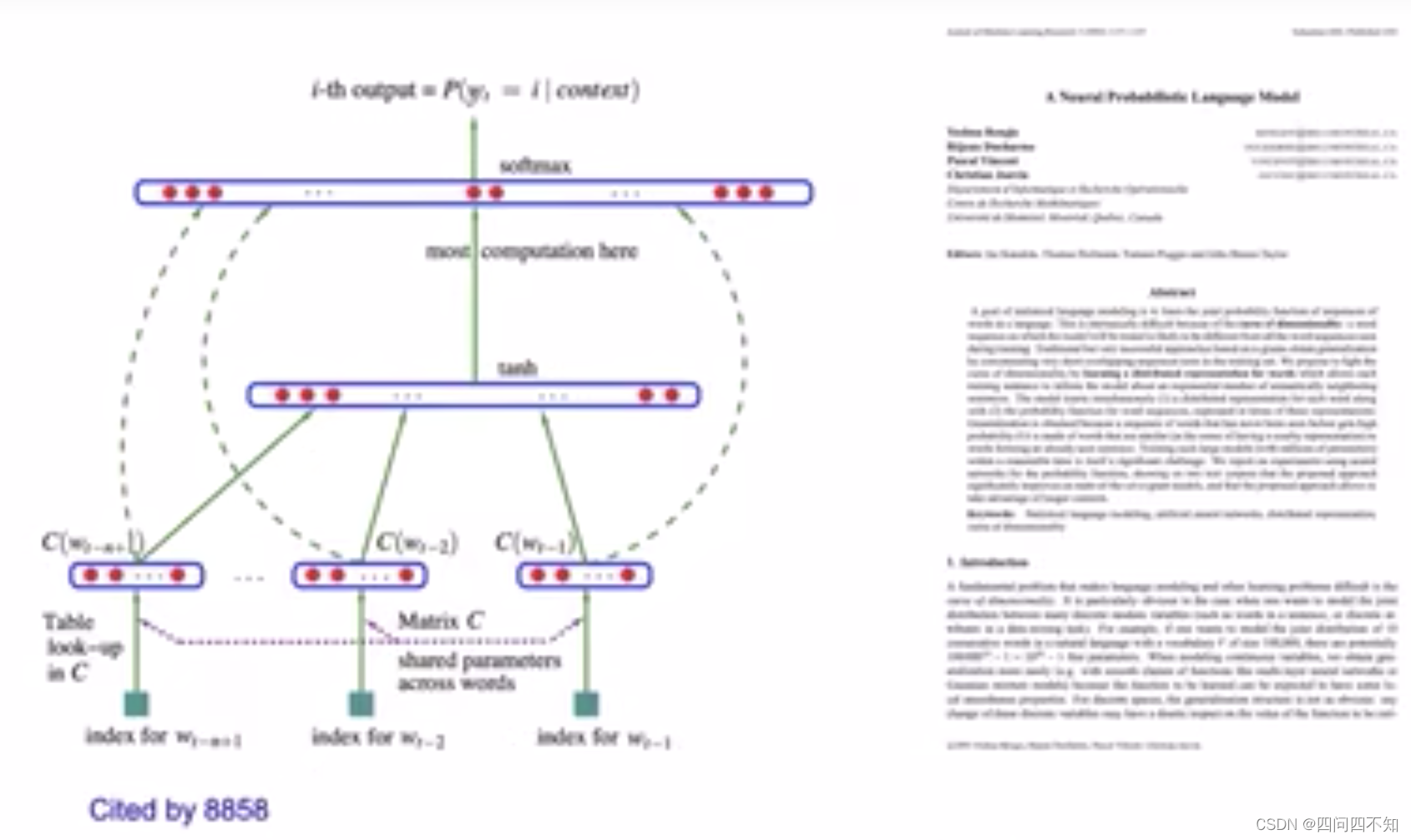
Neural Language Model
- A neural language model is a language model based on neural networks to learn distributed representations of words
分布式的表示建构前文和当前词的预测条件概率- Associate words with distributed vectors
- Compute the joint probability of word sequences in terms of the feature vectors
- Optimize the word feature vectors(embedding matrix E)and the parameters of the loss function(map matrix W)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/804511
推荐阅读
- 一、htmlHTML>
Home [详细] -->赞
踩
相关标签

